Be More with Less: Hypergraph Attention Networks for Inductive Text Classification

一、摘要
文本分类是自然语言处理中一个重要的研究课题,有着广泛的应用。最近,图神经网络(gnn)在研究界得到了越来越多的关注,并在这一规范任务中展示了有前景的结果。
GNN 在文本分类表现能力受损:
因为:(1)无法捕捉单词之间的高阶相互作用;(2)处理大型数据集和新文档效率低下。
在本文中,提出了一个原则性模型-超图注意网络(HyperGAT),它可以在文本表示学习中以更少的计算消耗获得更强的表达能力。在各种基准数据集上的大量实验证明了所提出的方法在文本分类任务中的有效性。
二、在文本分类先前任务中的局限:
(i)表达能力。现有的基于gnn的方法主要集中于单词之间的成对交互(即二元关系)。然而,在自然语言中,单词交互并不一定是二元的,而可以是三元的、四元的或更高阶的。
因此,如何超越成对关系,进一步捕获高阶词的交互,对于高质量的文本表示学习至关重要,但仍有待探索
(ii)计算消耗。一方面,大多数使用GNN骨干的努力往往是内存效率低下的,因为构建和学习全局文档-字图上的会消耗大量的内存。另一方面,强制访问测试文件的培训使这些方法本质上是跨换成muti头+转换器(预训练)。这意味着,当新数据到达时,我们必须从头开始重新训练模型,以处理新添加的文档。
因此,有必要设计一种计算效率高的方法来求解基于图的文本分类。
设计新模型
由于传统的GNN模型不能用于超图,为了弥补这一差距,我们提出了一种名为HyperGAT的新模型,它能够捕获每个超图中编码的高阶词交互。同时,其内部的双重注意机制突出了学习高表达性文本表征的关键上下文信息。
三、贡献:
1.提出用文档级超图对文本文档进行建模,从而提高了模型的表达能力,降低了计算消耗。
2.提出了一种基于双注意机制的原则模型HyperGAT来支持文本超图上的表示学习。
3.我们在多个基准数据集上进行了大量的实验,以说明HyperGAT在文本分类任务上优于其他最先进的方法。
四、方法
在本节中,我们将介绍一个新的为归纳GNN模型分类开发的家族。通过回顾现有的基于gnn的努力,我们首先总结了它们需要解决的主要局限性。然后,我们将说明如何使用超图来建模文本文档,以实现这些目标。最后,我们提出了一种新的双注意机制和归纳文本分类的HyperGAT模型
4.1用于文本分类的GNN
GNN层定义:

hli是在第l层的节点i的节点表示(我们使用xi作为h0i),Ni是节点i的局部邻居集。AGGR是gnn的聚合函数,有一系列可能的实现
提高了模型的表达能力,降低了计算消耗方法
4.2建立文本超图:
1.定义超图

在一般情况下,超图中的每个节点都可以带有一个d维属性向量。因此,所有节点属性都可以表示为X = [x1,x2,…,xn]T∈×,为了简单,使用G =(A,×)来表示整个超图。
2.定义多关系超边
1.Sequential Hyperedges(序列超边)
描述单词间局部共现的语言属性
首先为语料库中的每个文档构造顺序超边。
将每个句子都视为一个超边,并将这个句子中的所有单词连接起来。使用句子作为顺序超边,使我们的模型能够同时捕获文档结构信息。
2.Semantic Hyperedges.(语义超边)
语义超边框来捕获单词之间与主题相关的高阶相关性
从文本文档中挖掘潜在的主题T,每个主题=(θ1,…,θw)(w表示词汇表大小)都可以用单词上的概率分布来表示。然后,对于每个主题,我们认为它是一个语义超边,它连接了文档中概率最大的前K个词。通过这些主题相关的超边,我们能够丰富每个文档中单词的高阶语义上下文。
五.定义超图注意力网络( Hypergraph Attention Networks—HyperGAT)
Hypergraph Attention Networks:
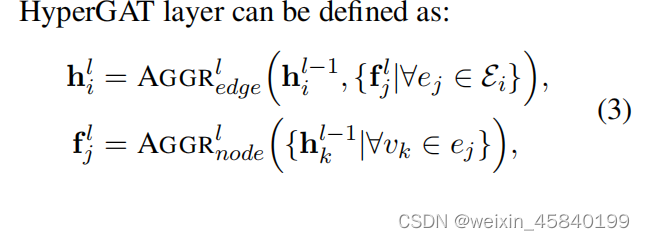
Ei为连接到节点vi的超边集,fjl为第l层中超边ej的表示。AGGRedge是一种聚合函数,而AGGRnode是另一个聚合节点特征的聚合函数。在这项工作中,我们建议基于双重注意机制来实现这两个功能
1.Node-level Attention
HyperGAT架构的单层l:
HyperGAT层首先学习它所有连接的超边Ei的表示。由于不是超边ej∈Ei中的所有节点都对超边的意义贡献相同,我们引入注意机制(即节点级注意)来突出那些对超边的意义很重要的节点,然后聚合它们来计算超边表示fjl
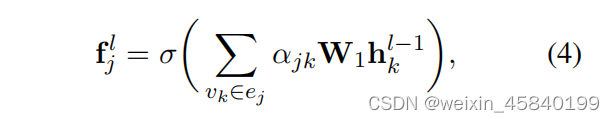
其中σ为非线性,如ReLU和W1是一个可训练的权重矩阵。αjk为超边ej中节点vk的注意系数

其中aT1是一个权重向量(也就是上下文向量)。
2.Edge-level Attention.
对于所有的超边表示{fjl |∀ej∈Ei},我们再次应用边缘级注意机制来突出信息性的超边,用于学习节点vi的下一层表示
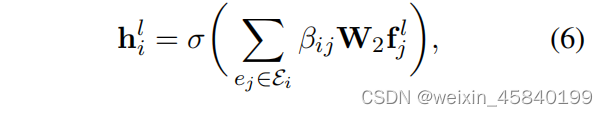
hli为节点vi的输出表示,W2为权值矩阵。βij为节点vi上超边ej的注意系数

aT2是另一个度量超边边重要性的权重(上下文)向量,而||是连接操作
所提出的双重注意机制使HyperGAT层不仅能够捕获高阶单词的交互,而且能够在节点表示学习过程中突出不同粒度上的关键信息。
Inductive Text Classification:
对于每个文档,在经过L个HyperGAT层后,我们就能够计算出所构造的文本超图上的所有节点表示。然后对学习到的节点表示HL进行平均池操作,得到文档表示z,并将其输入一个softmax层进行文本分类。
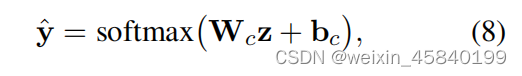
Wc是一个将文档表示映射到输出空间的参数矩阵,bc是偏差。ˆy表示预测的标签分数。
损失函数:
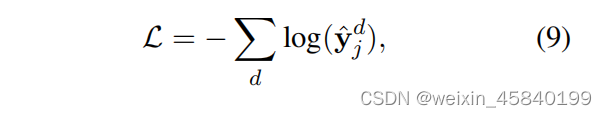
j为文档d的地面真实标签。因此,可以通过最小化所有标记文档上的上述损失函数来学习HyperGAT
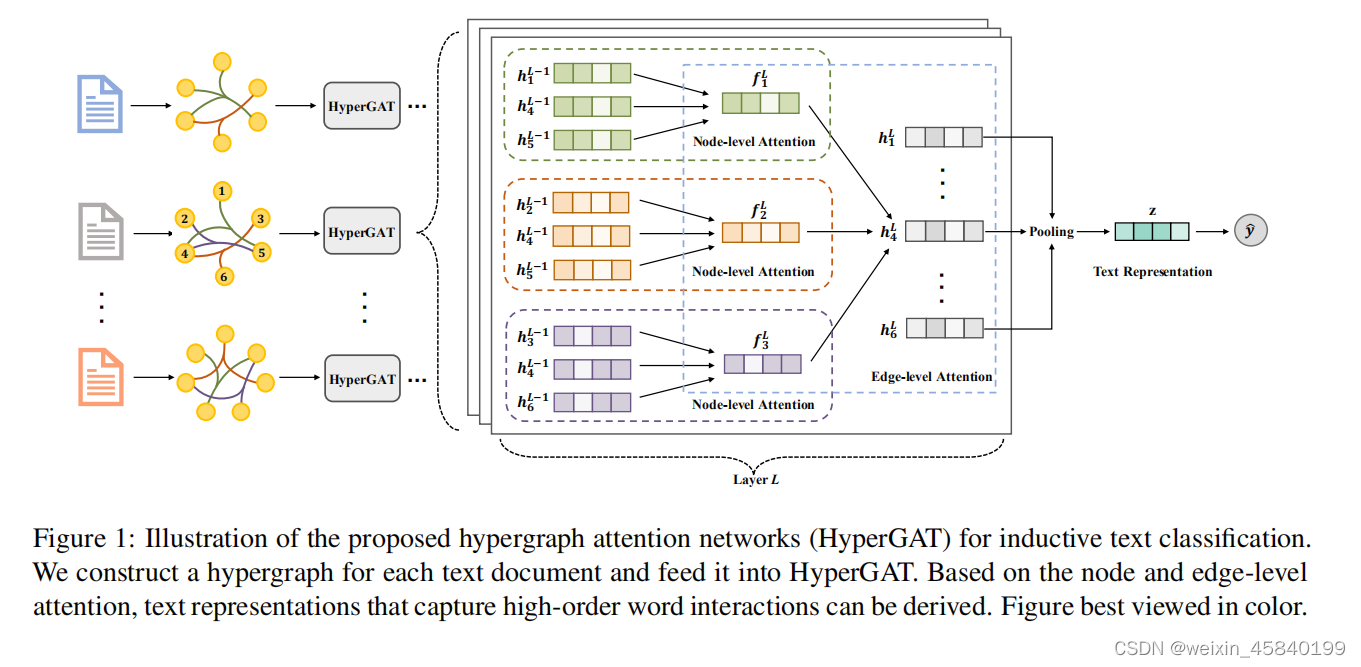
模型图:
六、实验
(1)Evaluation Datasets:

我们在实验中遵循(Yao et al.,2019)中相同的训练/测试分割和数据预处理程序。在每次运行中,我们随机抽取90%的训练样本来训练模型,并使用剩下的10%的数据进行验证。
(2) Compared Methods:

(3) Implementation Details.
HyperGAT由PyTorch实现,并使用Adam优化器进行了优化。我们在一个12 GB的泰坦Xp GPU上训练和测试了这个模型。具体来说,我们的HyperGAT模型分别由两层300个和100个嵌入维度组成。我们使用一个热向量作为节点属性,并且对所有数据集的批处理大小都设置为8。当模型对验证样本的精度最高时,选择超参数的最优值。Mr的优化学习率α设置为0.0005,其他数据集设置为0.001。L2正则化率为100 6,辍学率为0.3。为了学习HyperGAT,我们使用早期停止策略对该模型进行了100个时代的训练。为了构建语义超边长,我们使用训练文档为每个数据集训练一个LDA模型,并从每个主题中选择前10个单词。主题编号被设置为相同数量的类。
(4)Experimental Results
1. Classification Performance

我们首先进行了全面的实验来评估模型的文本分类性能,结果如表2所示。总的来说,我们的模型HyperGAT在5个评估数据集上优于所有基线,这证明了它在文本分类方面的优越能力。此外,我们还可以进行以下深入的观察和分析:基于图的方法,特别是基于gnn的模型,能够在前四个数据集上实现优于其他两类基线的性能。这表明,通过捕获长距离的单词交互,可以直接提高文本分类性能。而对于Mr数据集,基于序列的方法(cnn和lstm)比大多数基于图的基线显示出更强的分类能力。一个潜在的原因是,顺序上下文信息在情绪分类中起着关键作用,而大多数现有的基于图的方法无法明确捕获。
TextGCN(感应)在很大程度上落后于它原来的转换版本。虽然文本级GNN能够通过在单词之间添加可训练的边权值来实现性能改进,但它的性能仍然受到使用成对简单图的信息损失的限制。特别是,我们的模型与其他基于gnn的模型相比,HyperGAT取得了相当大的改进,证明了高阶上下文信息在学习单词表示方面的重要性。
2.Computational Efficiency.
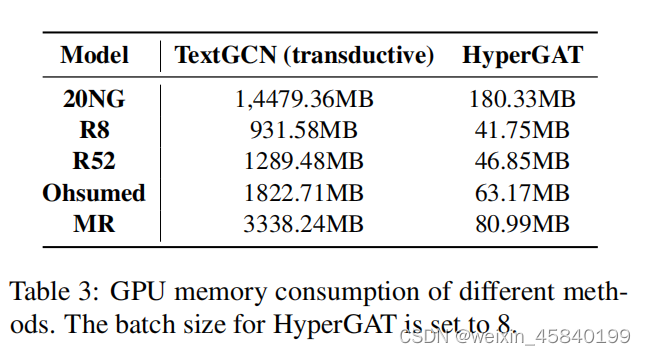
表3显示了最具代表性的传感器基线TextGCN和我们的方法之间的计算成本比较。从报告的结果中,我们可以清楚地发现,HyperGAT在内存消耗方面具有显著的计算优势。主要原因是HyperGAT在文档级进行文本表示学习,并且在训练过程中它只需要存储一批小的文本超图。相反,TextGCN需要同时使用训练文档和测试文档来构建一个大型的文档字图,这不可避免地会消耗大量的内存。我们的模型的另一个计算优势是,HyperGAT是一个归纳模型,可以推广到不可见的文档。因此,我们不需要为新添加的文档重新训练整个模型。
3.Model Sensitivity
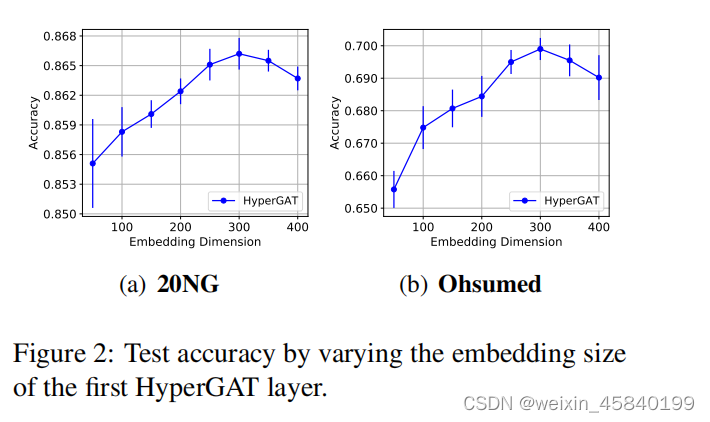
图2报告了具有不同第一层嵌入维数的20NG和Ohsumed上的模型性能,由于可以观察到类似的结果,因此我们忽略了其他数据集上的结果。值得注意的是,当第一层嵌入大小设置为300时,HyperGAT的性能最好。这说明,如果嵌入尺寸较小,可能会使模型的表现力降低,而如果嵌入尺寸太大,模型可能会出现过拟合。
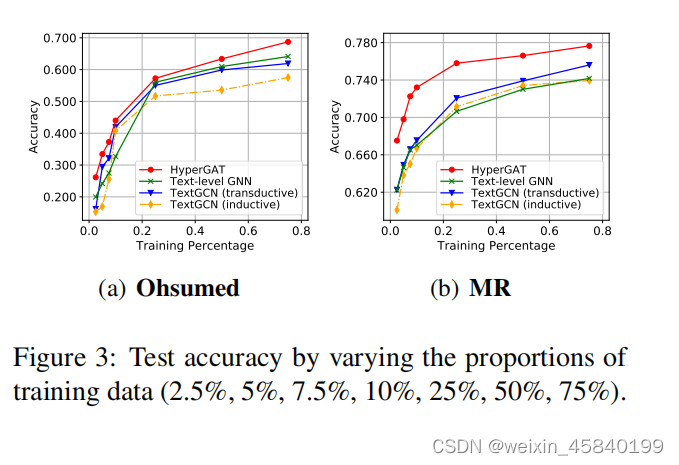
评估标记训练数据精度,我们比较了几个具有不同比例的训练数据的最佳性能模型,并在图3中报告了Ohsumed和Mr的结果。一般来说,随着标记训练数据的增长,所有的评估方法都能实现性能的提高。更值得注意的是,在有限的标记数据下,HyperGAT可以显著优于其他基线,显示了它在现实场景中的有效性。
(5) Ablation Analysis

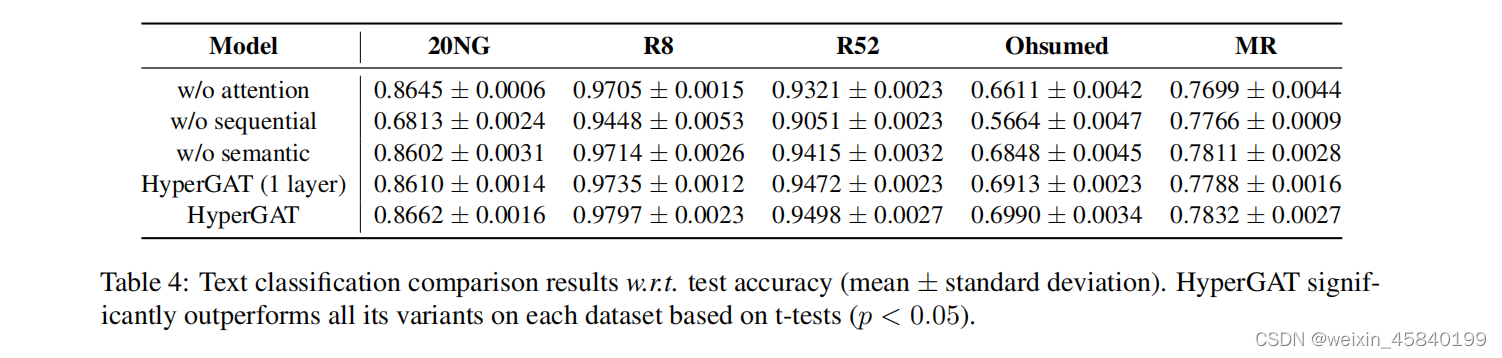
为了研究每个模块在HyperGAT中的作用,我们进行了消融分析,并将结果报告在表4中。具体来说,w/o注意是HyperGAT的变体,用卷积取代了双重注意。w/o顺序和w/o语义是另外两个排除顺序和语义超的变量。从报告的结果中,我们可以了解到,HyperGAT可以通过堆叠更多的层来获得更好的性能。这一观察结果可以验证远程单词交互对文本表示学习的有效性。此外,w/o注意和HyperGAT之间的表现差异显示了双注意机制对学习更具表现性的单词表征的有效性。通过比较顺序和语义的结果,我们可以了解到上下文信息通过顺序的超边更重要,但是添加语义超边可以增强模型的表达性。这也表明,异构的高阶上下文信息可以相互补充,我们可以研究更有意义的超边线,以进一步提高我们的方法的性能。
(6)Case Study
1.Embedding Visualization
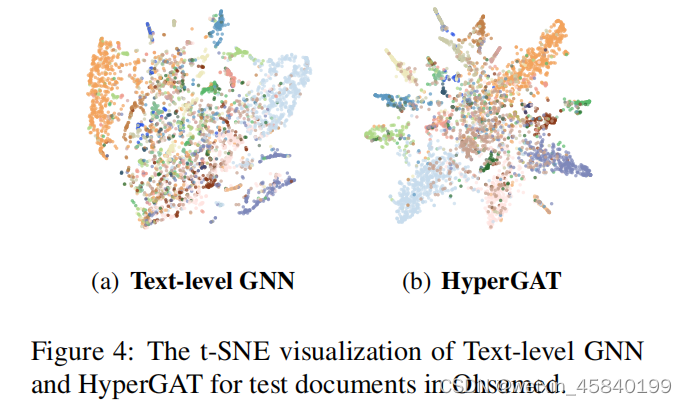
为了展示HyperGAT优于其他方法的嵌入质量,我们使用t-SNE(Maaten and Hinton,2008)来可视化学习到的文档表示以进行比较。具体来说,图4显示了在Ohsumed的测试文档上性能最好的基线文本级GNN和HymerGAT的可视化结果。请注意,节点的颜色对应于它的标签,它用于验证模型在23个文档类上的表达能力。从嵌入可视化中,我们可以观察到HyperGAT可以通过最先进的文本级GNN方法学习更有表现力的文档表示。
2. Attention Visualization.

为了更好地说明所提出的双重注意机制的学习过程,我们从20NG(标记为运动。棒球正确)中获取一个文本文档,并将为单词玩家计算的注意权重可视化。如图5所示
player is connected to four hyperedges within the constructed document-level hypergraphs
以句点结尾的前三行表示连续的超边,而没有句点的最后一行表示语义超边。注意,我们使用橙色表示节点级注意权重,而使用蓝色表示边缘级注意权重。颜色越深,代表更大的注意力权重
一方面,节点级的注意力( node-level attention)能够在同一超边缘上选择那些携带信息上下文的节点(单词)。例如,在第三个超边缘的胜利和团队获得了更大的注意力权重,因为他们比在同一个句子中的其他单词更有表现力。另一方面,边缘级的注意力( edge-level attention)也可以分配细粒度的权重来突出显示有意义的超边。正如我们所看到的,最后一个连接玩家与棒球和胜利的超边缘获得了更高的关注权重,因为它可以更好地描述文档中玩家的意义。综上所述,本案例研究表明,我们提出的双注意可以捕获不同粒度的关键信息,以学习表达性文本表示。
七、结论
在本研究中,我们提出了一种新的基于图的方法来解决归纳文本分类的问题。除了现有的努力之外,我们建议用文档级超图对文本文档进行建模,并进一步开发一个新的GNN模型家族HyperGAT,用于学习有区别的文本表示。具体来说,我们的方法能够获得更少的计算消耗和更多的文本表示学习。通过进行广泛的实验,结果证明了所提出的模型优于最先进的方法。
[1]https://github.com/kaize0409/HyperGAT.