摘要
我们对 Codex 语言模型的文本到 SQL 功能进行了实证评估。 我们发现,在没有任何微调的情况下,Codex 是 Spider 基准测试的强大基线; 我们还分析了 Codex 在此设置下的故障模式。 此外,我们在 GeoQuery 和 Scholar 基准测试中证明,提示中提供的少量域内示例使 Codex 的性能优于在此类少数示例上进行微调的最先进模型。
ChatGPT论文:Evaluating the Text-to-SQL Capabilities of Large Language Models 评估大语言模型的文本到 SQL 的功能 (一)
3 零样本结果
我们在表 1 中列出了不同模型大小的结果,在表 2 中列出了不同提示样式的结果。附录 B 中的表 4 提供了完整的结果。
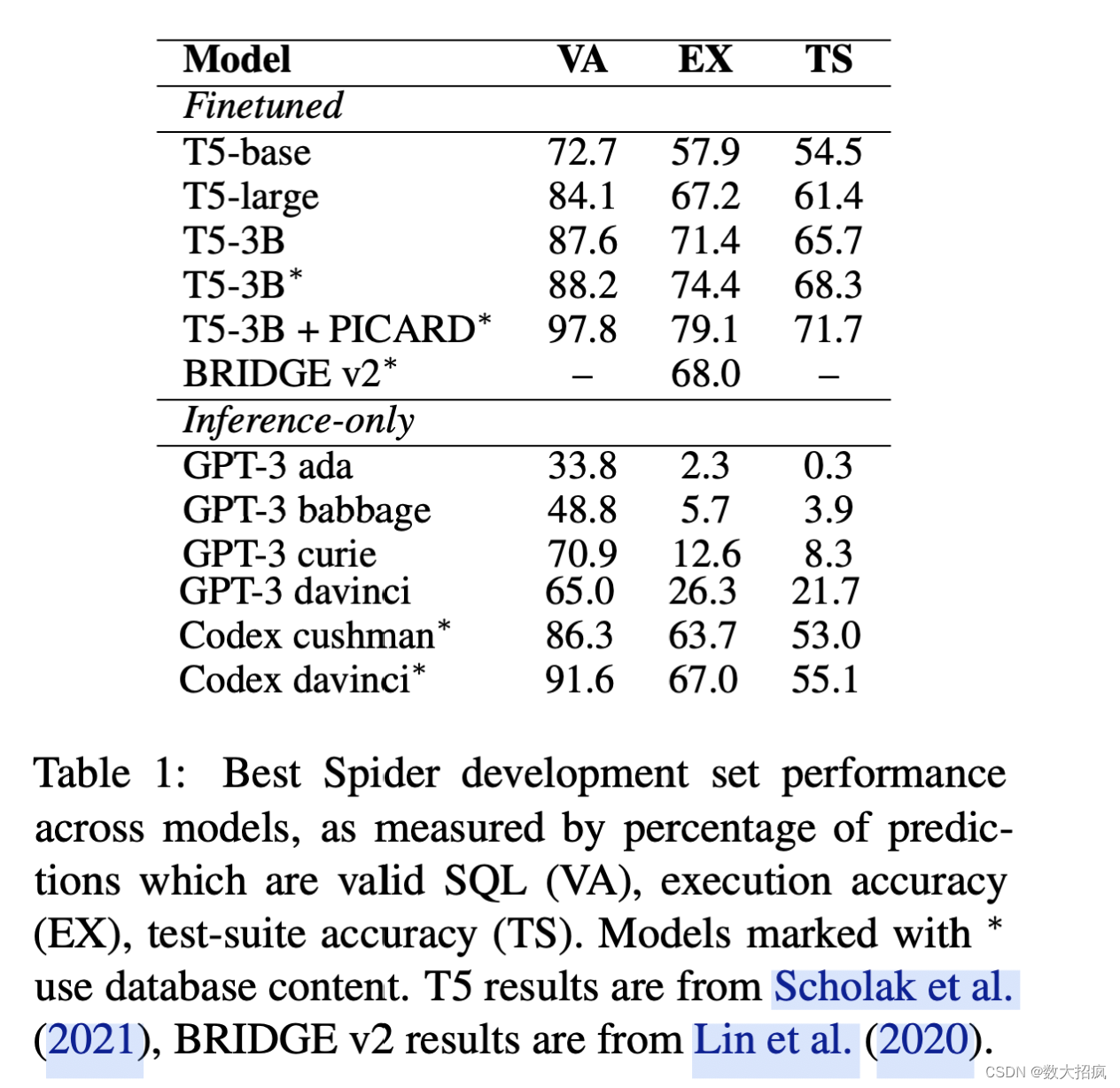
Codex 为文本到 SQL 任务提供了强大的基线
表 1 中表现最佳模型(davinci-codex,Create Table + Select 3)在Spider上实现了67%的执行准确率和56.5%的测试套件执行准确率。 这与 BRIDGE v2(Lin 等人,2020)模型的性能相当,该模型在 2020 年 12 月实现了(当时)最先进的 68% 执行精度。
提示设计对于性能至关重要

如表 2 所示提示设计对于性能至关重要 ,仅提供问题会导致执行准确度仅为 8.3%。 当 API 文档中引入架构信息时,逐步提高到 56.8%;当在创建表中使用有效 SQL 和外键信息时,提高到 59.9%;当通过Create Table + Select 3引入数据库内容时,提高到 67.0%。
Codex 模型大小的收益递减
虽然 GPT-3 性能因模型大小的增加而显着受益,但 davinci-codex 模型的性能并不比 cushman-codex 好得多。 附录 B 表 4 中的完整结果显示,对于相同的提示风格,cushman-codex 与 davinci-codex 的差距通常在 1 个百分点以内; 对于“创建表”提示,它的性能甚至提高了 3 个百分点。 这些结果表明,与增加参数数量相比,davinci-codex 较长的上下文窗口对其峰值性能的贡献更大。
3.1 误差分析
我们通过 Create Table + Select 3 提示将错误分析重点放在 davinci-codex 模型上,并在表 3 中显示预测类型的细分,在图 1 中显示错误示例。我们选择错误类别来显示最有趣的 Codex -我们在所犯错误中观察到的具体行为。 我们随机选择并注释了 100 个预测,这些预测是有效的 SQL,但通过测试套件评估被判断为不正确。
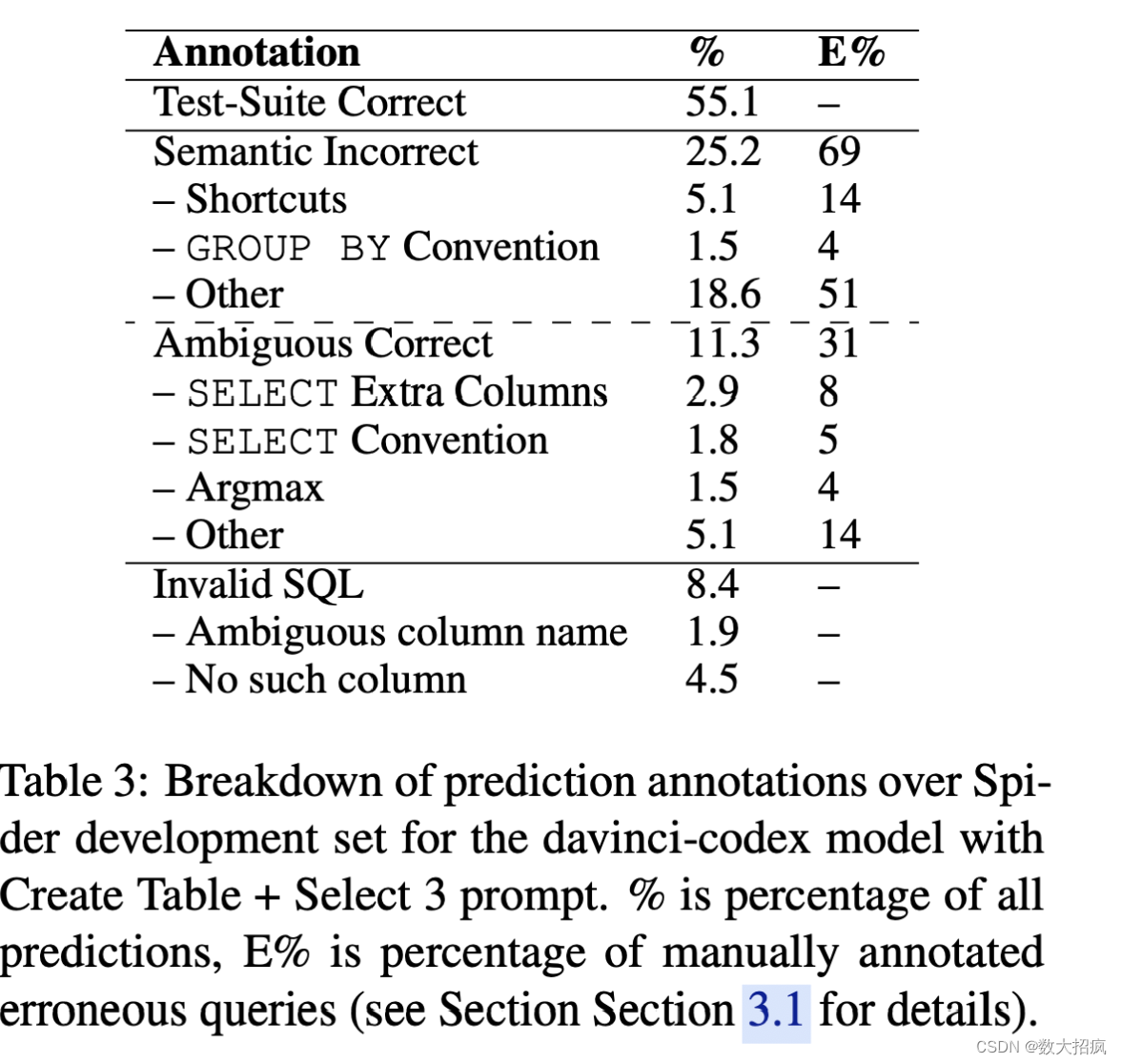

我们首先考虑语义不正确的行为,Spider评估和人类注释者都将其视为不正确的预测。 快捷方式错误是 Codex 使用特定表值或 GPT-3 预训练中的“世界知识”,而真实查询包含问题中的确切文字。 GROUP BY 约定错误是 Codex 对非主键列(例如名称或标题列)进行错误分组的情况。
我们还考虑模糊正确的行为,这些行为在语义上与黄金查询不同,因此被 Spider 评估判断为不正确,但人类注释者将其视为给定问题的可接受的 SQL 翻译。 SELECT 约定错误是 Codex 选择与黄金查询的每个数据库约定不同的列(例如名称而不是 ID)。 SELECT Extra Columns 错误是 Codex 在其查询中包含超出黄金查询包含的其他有用列的情况。 Argmax 错误是 Codex 与黄金查询的不同之处在于如何处理平局的最小/最大分辨率(例如“最年轻的歌手”)。
我们在表 3 中观察到,尽管人类注释者将其视为可接受的解决方案,但有 31% 的有效但错误的预测被 Spider 评估视为不正确而受到惩罚。 未来的工作可能是调查人们可以在多大程度上控制 Codex 的行为。 这可以通过提示设计或使用一些示例来修复这些不明确的错误。
4.Few-Shot
我们研究 Codex 是否可以执行少量文本到 SQL。 如第 2 节所述,我们在Few-Shot设置中重新利用了 GeoQuery 和 Sholar 数据集。 众所周知,在 Spider 上训练的模型在零样本设置下很难迁移到其他单数据库文本到 SQL 数据集(Suhr 等人,2020)。 研究 GeoQuery 和 Scholar 上的少量文本到 SQL 应该可以表明模型能够在多大程度上利用少量示例来有效地适应新领域。
基线
基线是在 Spider 上进行微调的 T5-3B 模型,在 Spider 验证集上达到 71% 的精确匹配精度。 然后,该模型在新领域(GeoQuery 或 Scholar)上进一步微调。 基于 300 步后的最佳验证集性能,在20-shot设置中选择了特定领域微调的学习率,范围为 [0.1, 0.2, 0.5, 1, 2] ·10−5 。 我们使用批量大小 1024,以便所有小样本示例都适合同一批次。

Codex 在“创建表 + 选择 X”提示的基础上构建,我们将 n 个问题查询示例附加到 n-shot 设置中的输入。 图 11 提供了此提示的示例。所有样本均使用贪婪解码生成,温度为 0。 请注意,对于给定的 n-shot 设置,基线和 Codex 使用同一组支持示例。 这些示例位于 Codex 的提示中,用于微调新域的基线。 考虑到 API 模型的窗口大小有限,在 GeoQuery 上,我们可以向 davinci-codex 提供最多 40 个支持示例,向 cushman-codex 和 GPT-3 模型提供最多 10 个示例。 在 Scholar 上,查询更长,模式更复杂——我们在 davinci-codex 的提示中只放置了 10 个示例,为 cushman-codex 放置了 5 个示例,对于 GPT-3 模型根本没有放置任何示例。

4.1 结果
图 2 显示了 Scholar 和 GeoQuery 数据集上的测试套件准确性。 在完整的 GeoQuery 训练集(549 个示例)上进行训练时,基线达到 85.7% 的测试集性能。 在整个 Scholar 训练集(499 个示例)上进行训练时,其测试准确率分别达到 87.2%。 考虑整个数据集时,这个简单的基线是一个非常有竞争力的模型。 然而图 2 显示,它在少量样本设置中很大程度上被 Codex 击败。 在零样本设置中,davinci-codex 和 cushman-codex 都已经超过了 GeoQuery 的基线。 我们推测 Codex 在这里表现良好,因为它使用与 GeoQuery 数据集相同的 argmax 约定,这与 Spider 中使用的约定不同。 提示中包含多达 40 个示例,davinci-codex 的性能大大优于在这些相同示例上进行微调的 T5-3B 模型,而 GPT-3 davinci 在这项任务上的表现相当差。 另一方面,T5 模型在 Scholar 上的零样本设置中优于 Codex。 在 5 次和 10 次射击设置中,Codex 对这几个样本表现出更好的适应能力,并超越了 T5 基线。

5 结论
我们证明了在代码上训练的生成语言模型为文本到 SQL 提供了强大的基线。 我们还提供了这些模型的故障模式分析,我们希望这些分析能够指导在此设置中的进一步提示设计(无论是少数样本还是通过自然语言指令)。 最后,我们证明了这些模型的基于提示的小样本学习与较小模型的基于微调的小样本学习具有竞争性。 未来工作的一个明确方向是评估使用 Codex 模型进行微调的好处。