
数据接入
数据接入,作为现代信息技术架构中的一个关键环节,指的是将来自不同源头的数据整合到统一的数据平台或系统中。这一过程不仅是技术上的挑战,也涉及到组织结构、业务流程等多个层面的协调与优化。通过有效的数据接入,企业能够实现跨部门、跨系统的数据共享,为决策支持、业务分析等提供坚实的基础。
在实践中,数据接入通常包括以下几个步骤:首先是对源数据的理解与准备,这一步骤要求对各种数据格式(如CSV、JSON、XML等)、存储方式(如关系型数据库、NoSQL数据库)有深入的认识;其次是选择合适的工具和技术来执行数据迁移或同步操作,常见的解决方案包括ETL(Extract, Transform, Load)工具、API接口调用以及消息队列服务等;最后则是确保整个过程中数据质量得到保障,即完成清洗、转换后,目标系统中的数据应当准确无误地反映原始信息,并且具备良好的一致性、完整性和时效性。
今天借助ETL工具来演示一下Mysql同步至SQLserver的流程设置和数据接入。
数据接入场景演示
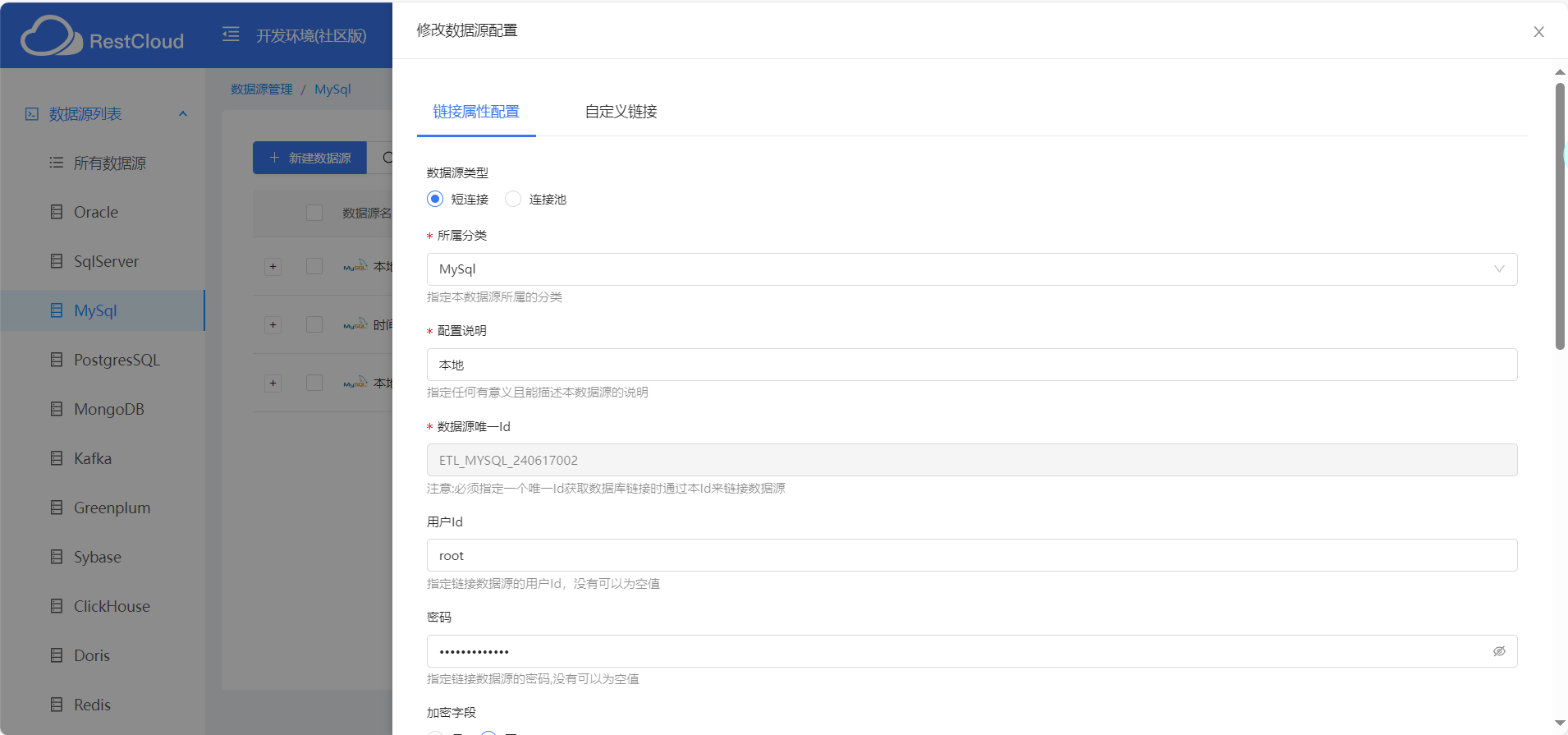
配置mysql数据源
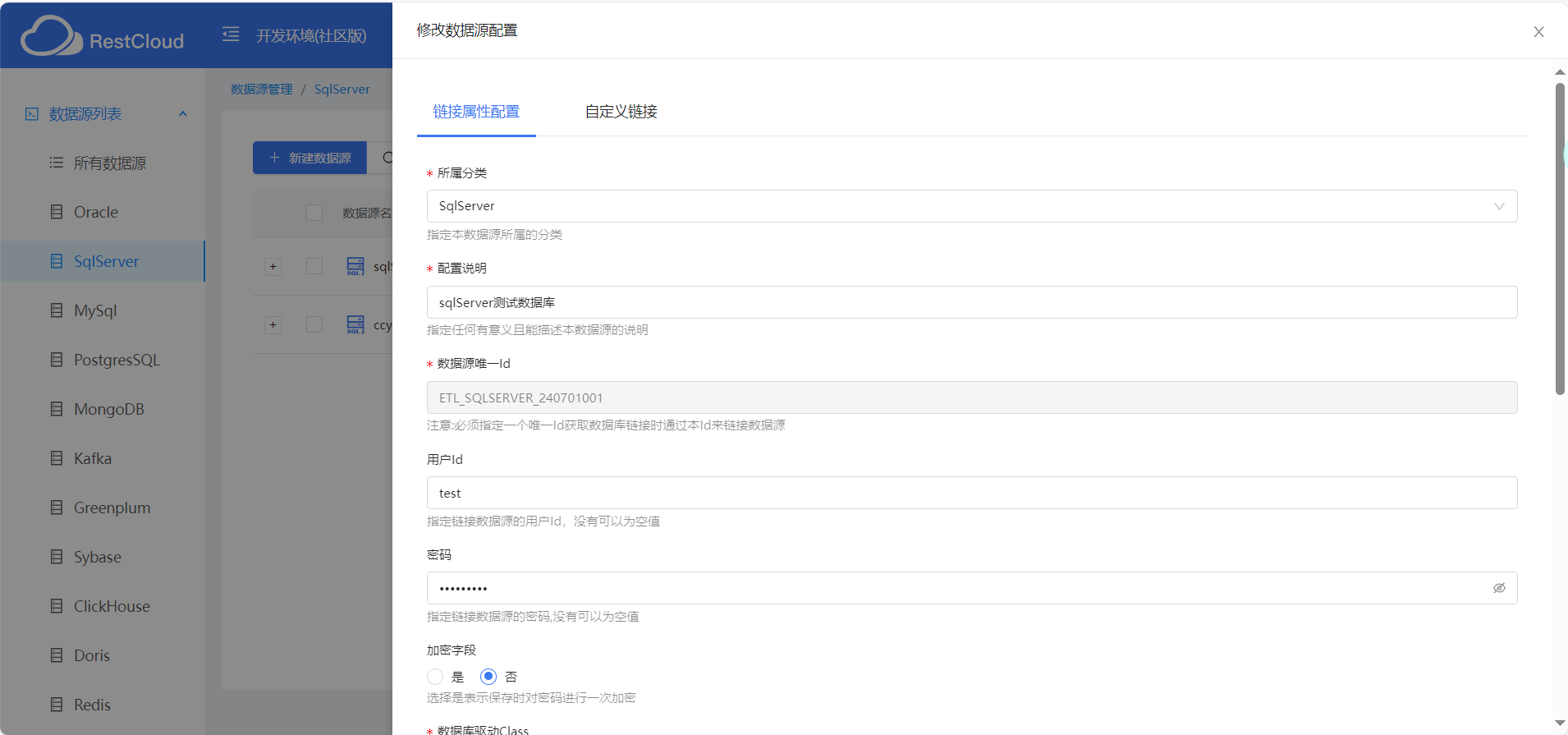
配置sqlserver数据源
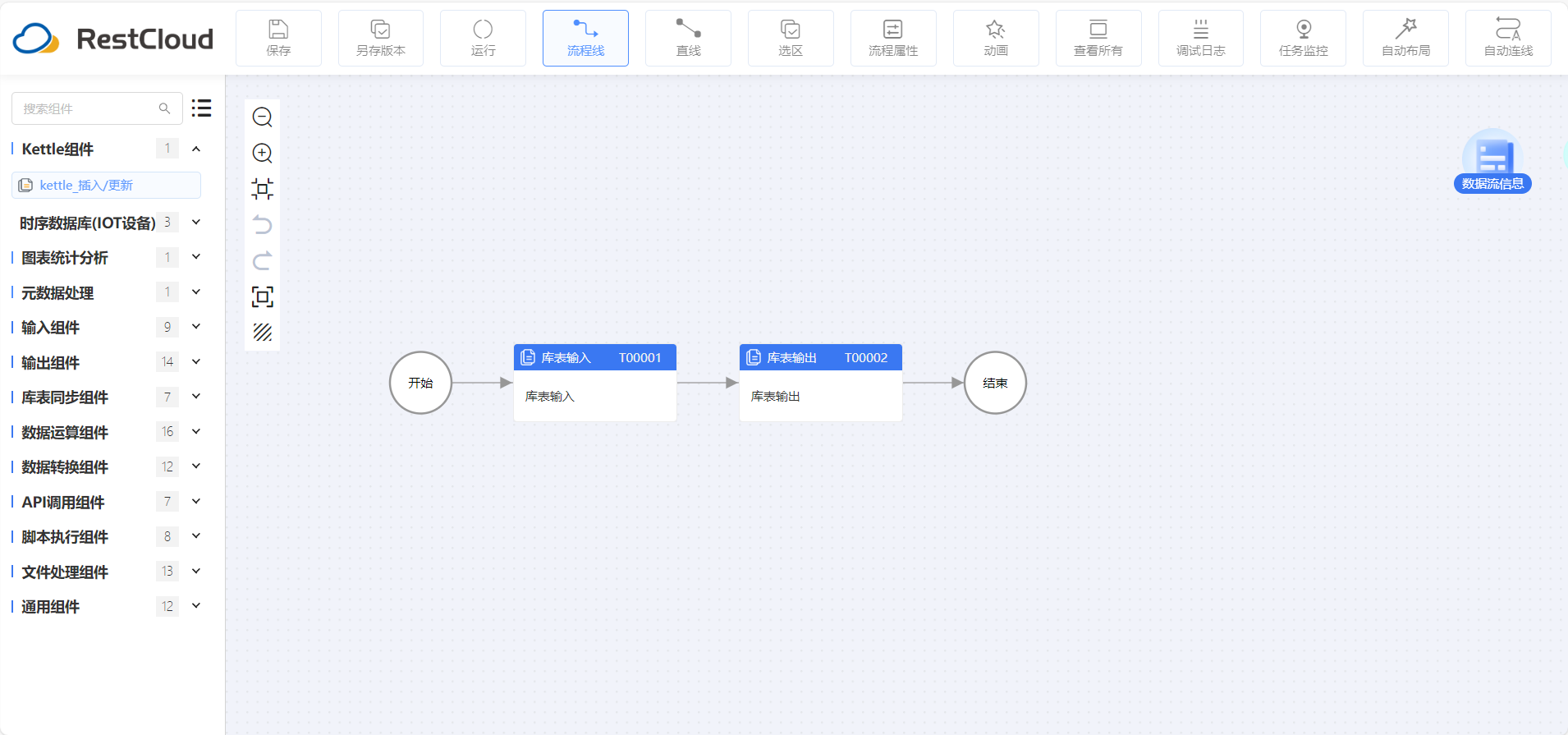
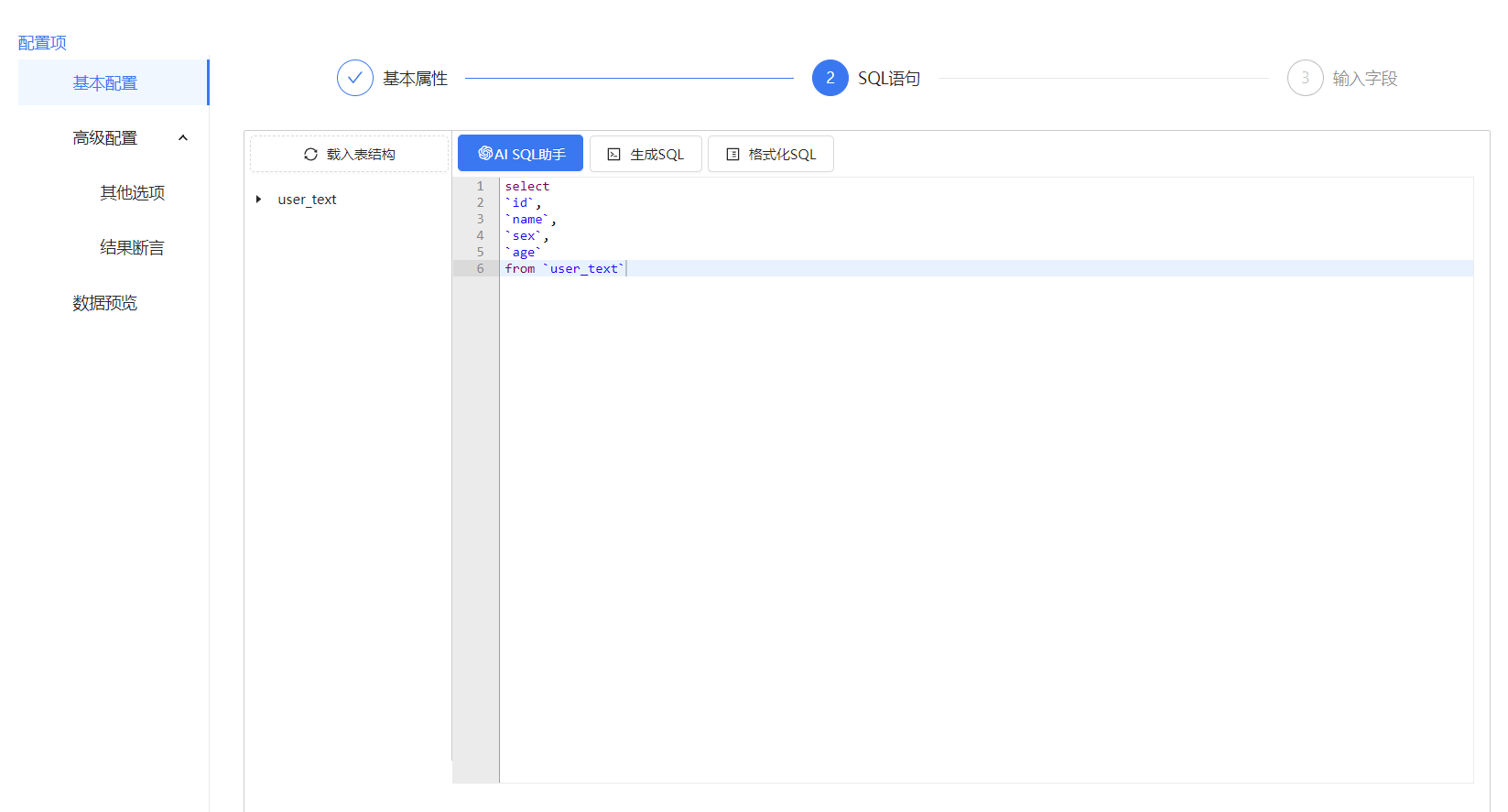
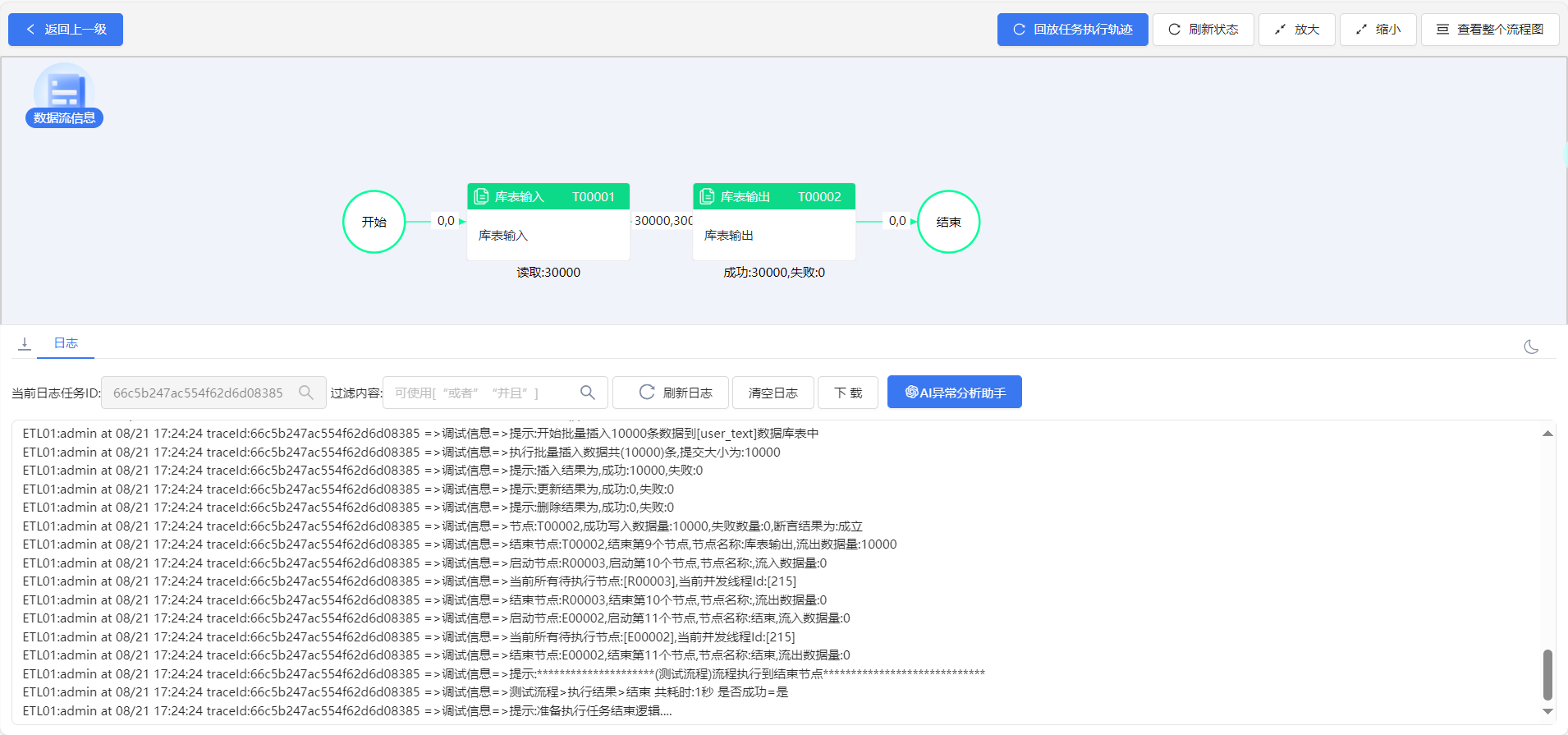
整体流程很简单就库表输入和库表输出组件
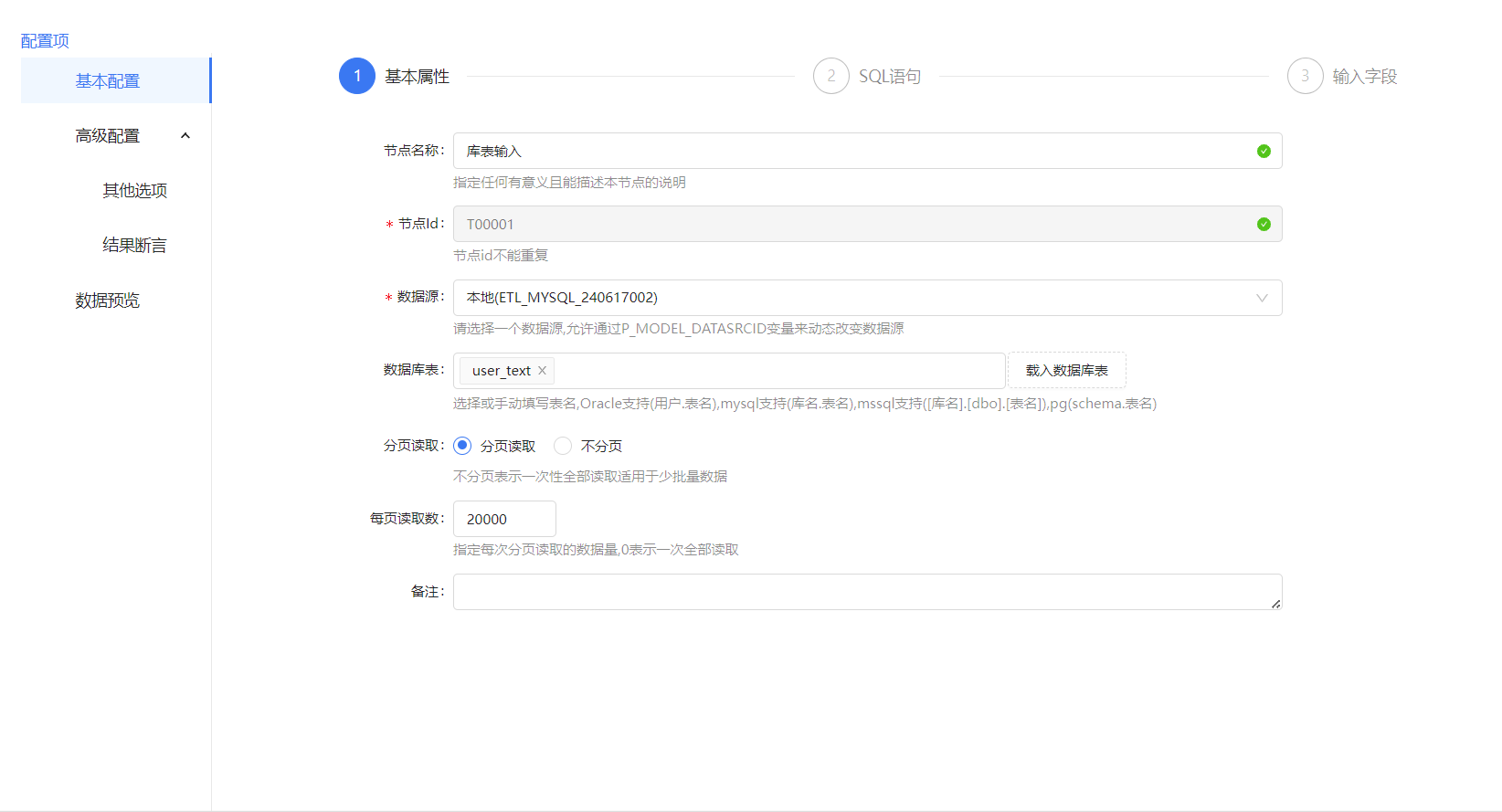
库表输入配置,库表输入的使用很简单,只需选择数据源和需要读取的数据表,后面的配置保持默认就好。
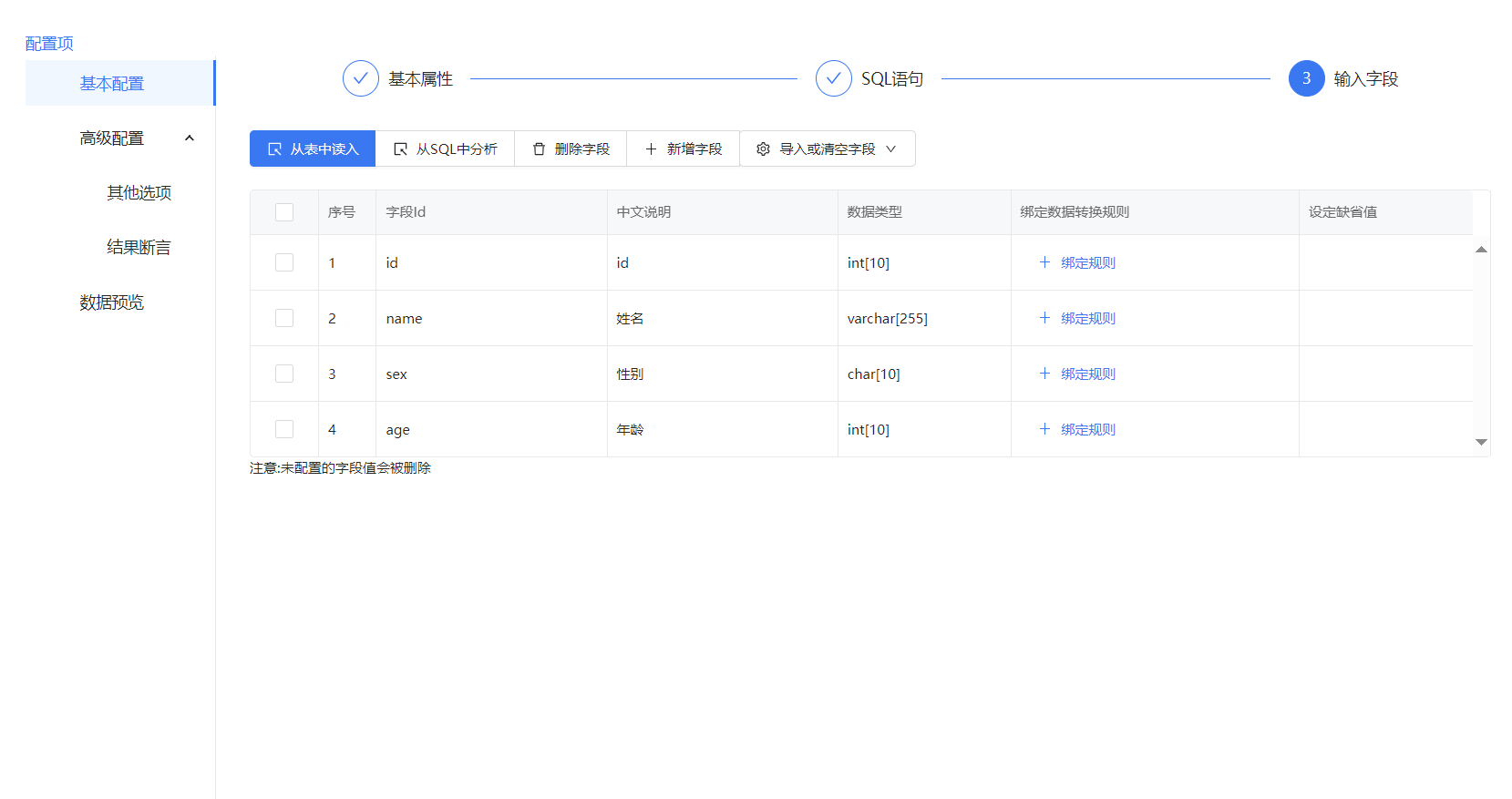
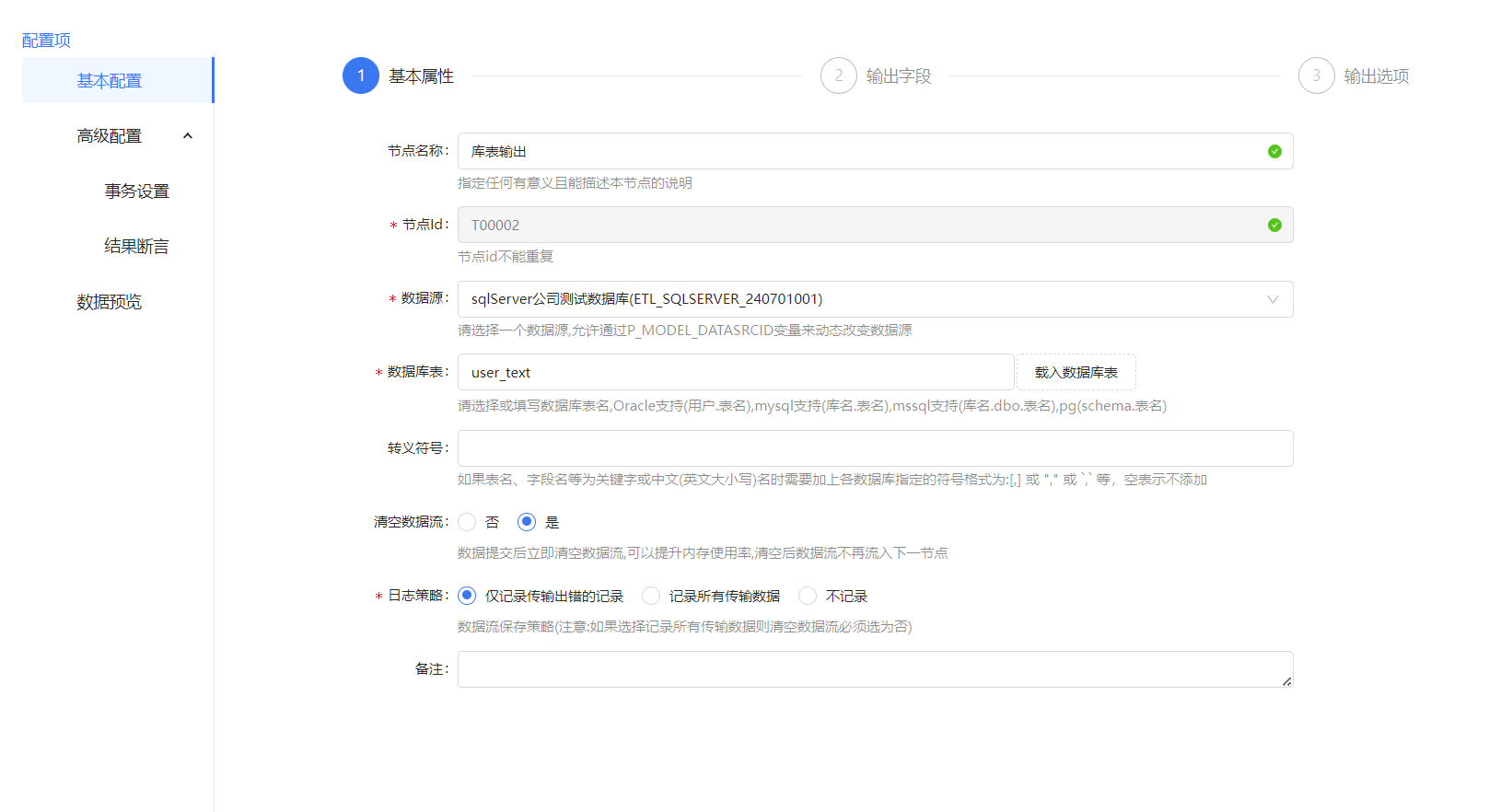
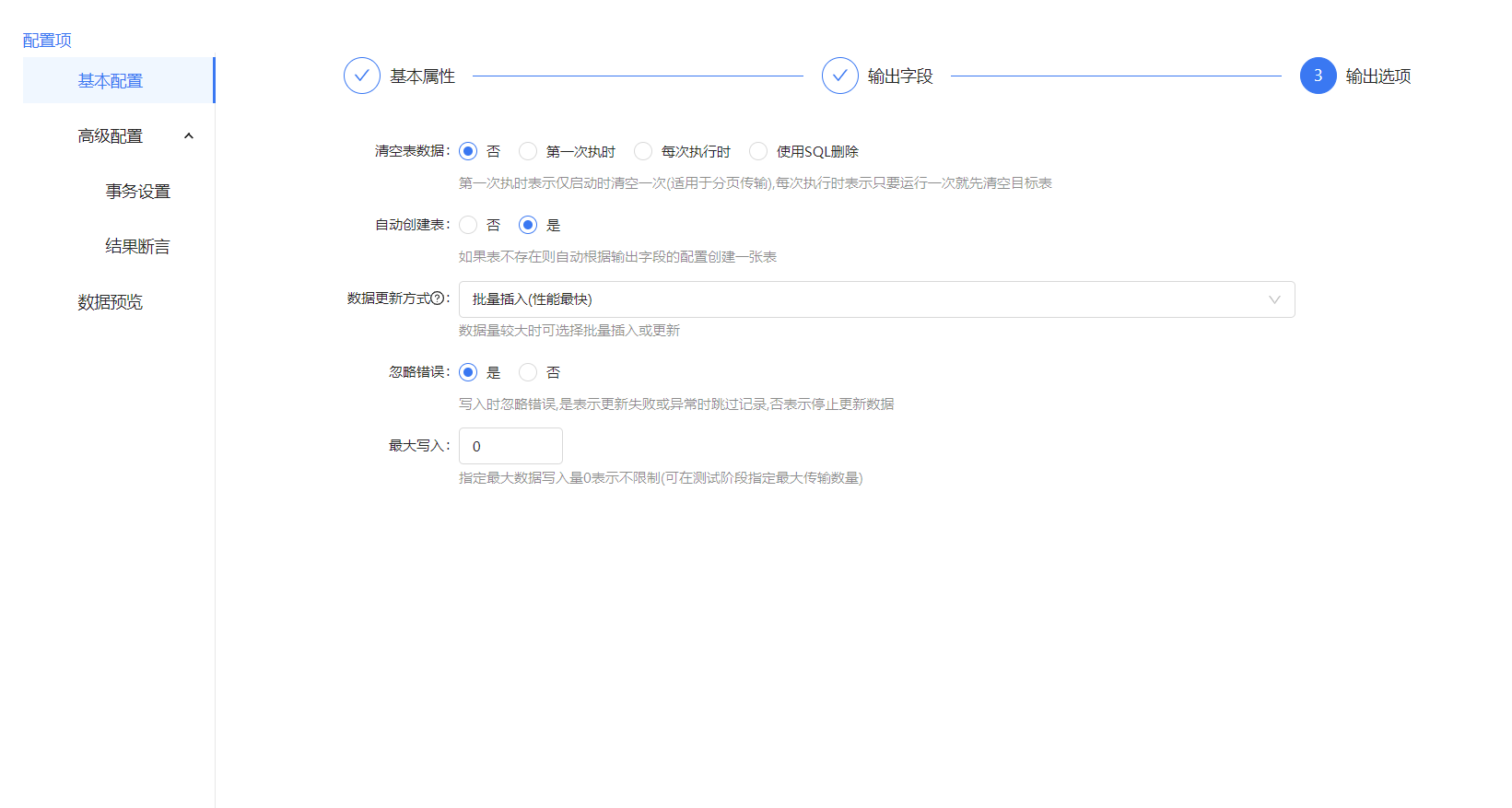
库表输出配置,库表输出如果没有选择批量输出的话就需要在字段配置那里选择关键字段,关键字段是用于更新,插入的条件,一般是表的主键。

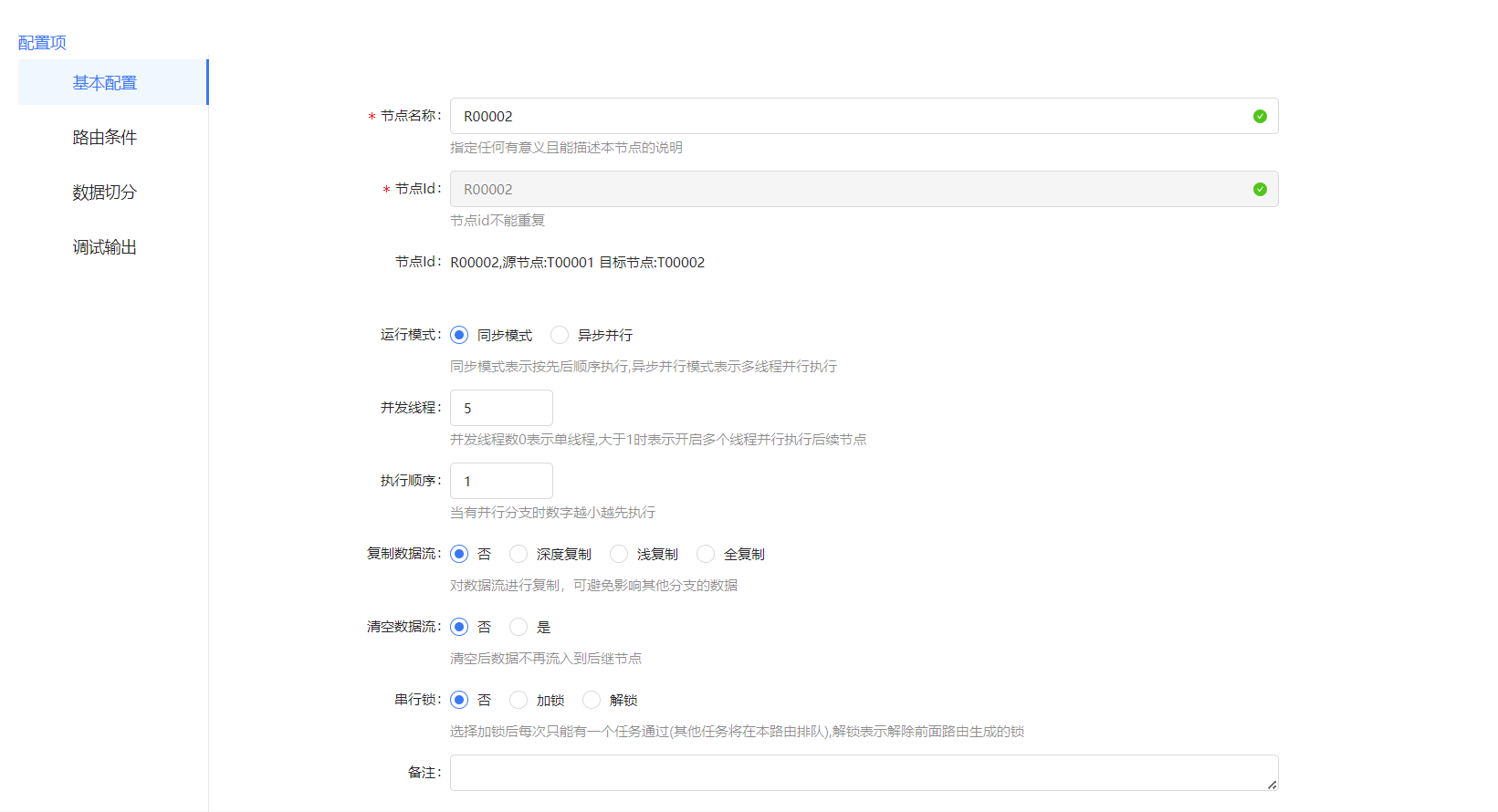
路由线,在路由线的属性中有个并发线程配置,调整并发线程数量,可以多线程执行后续节点,同时这里有个小细节路由线上会显示并发数。注意并发数越大,所要的内存也相应增加
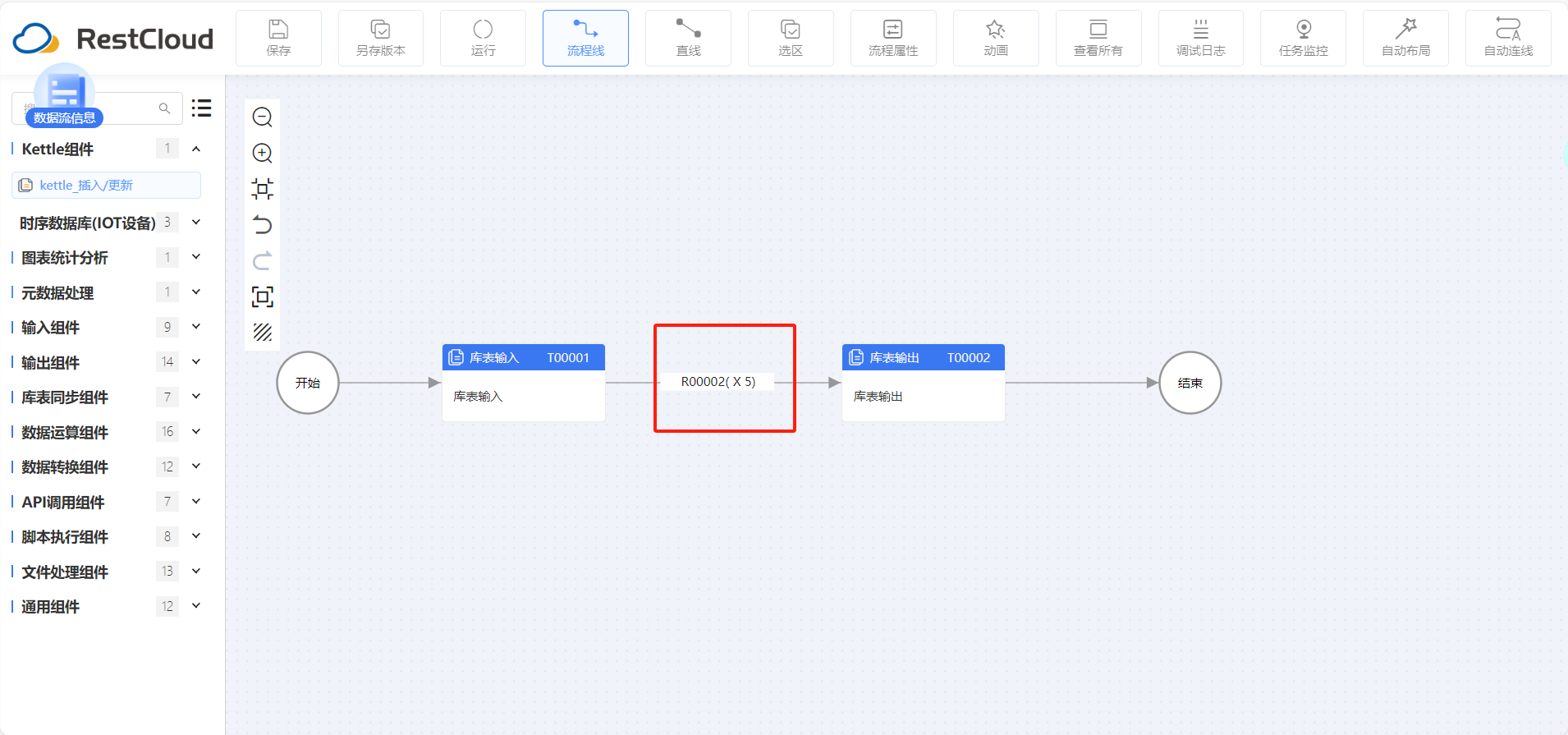
组件配置好后点击运行
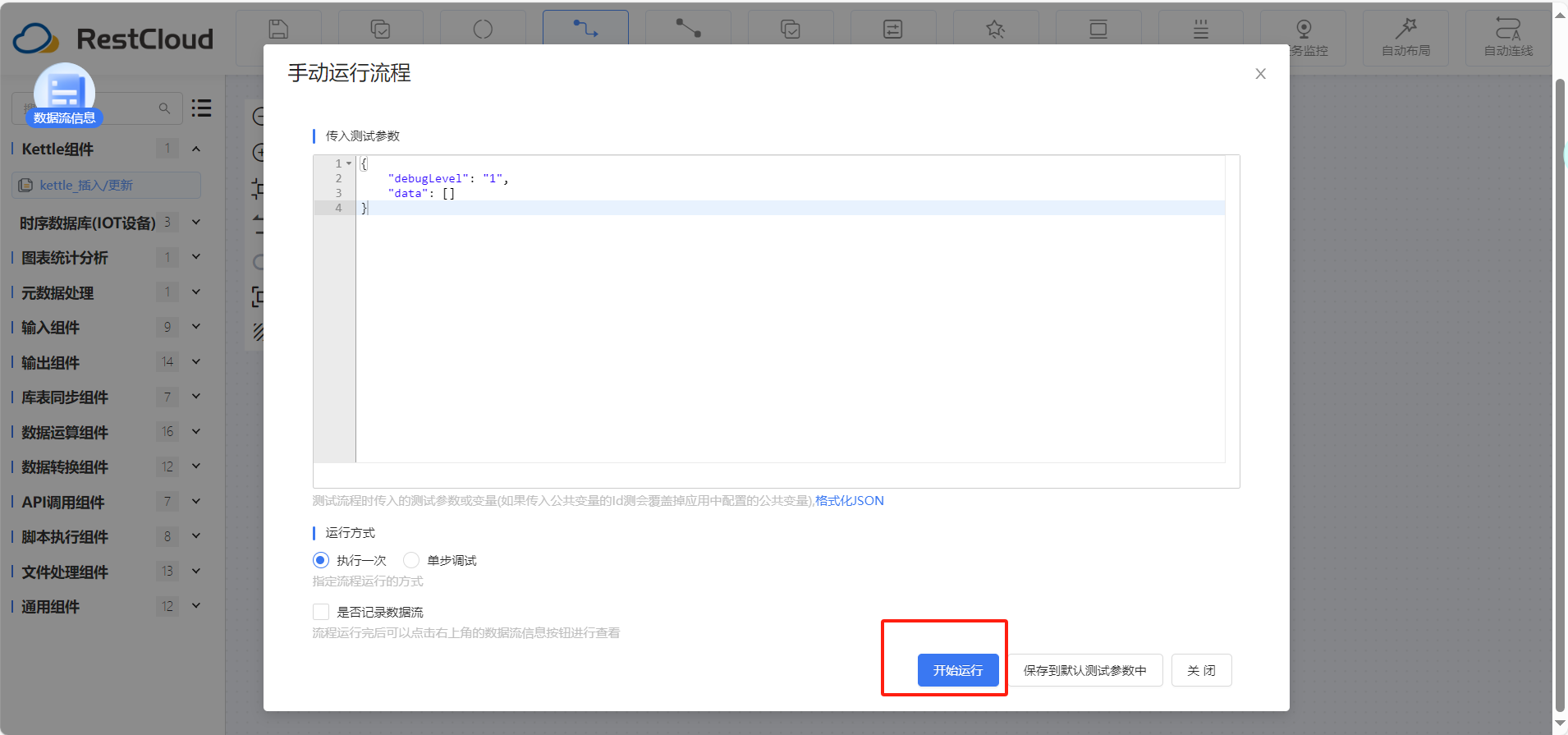
查看运行结果,数据同步成功
最后
值得注意的是,在当今大数据时代背景下,随着物联网(IoT)设备的普及以及社交媒体等非传统数据来源的增加,数据接入面临着前所未有的复杂度和规模挑战。因此,除了传统的批量加载模式外,越来越多的企业开始采用实时流处理技术来应对海量、高速变化的数据流。例如Apache Kafka作为一种分布式流处理平台,在许多场景下被广泛应用于构建高效可靠的数据管道。
此外,考虑到隐私保护及合规性的要求日益严格,如何在保证个人信息安全的前提下进行合法合规的数据收集与使用也成为了一个重要课题。对此,GDPR(General Data Protection Regulation)等国际标准提供了指导框架,强调了透明度原则、最小化原则以及用户控制权的重要性,促使企业在设计实施数据接入方案时必须充分考虑这些因素。
随着信息技术的发展和社会需求的变化,数据接入不仅关乎技术实现本身,更是一个涉及多方面考量的综合性工程。只有不断探索创新方法,才能更好地适应未来发展的需要,为企业创造更大的价值。
微软开源基于 Rust 的 OpenHCL 字节跳动商业化团队模型训练被“投毒”,内部人士称未影响豆包大模型 华为正式发布原生鸿蒙系统 OpenJDK 新提案:将 JDK 大小减少约 25% Node.js 23 正式发布,不再支持 32 位 Windows 系统 Linux 大规模移除疑似俄开发者,开源药丸? QUIC 在高速网络下不够快 RustDesk 远程桌面 Web 客户端 V2 预览 前端开发框架 Svelte 5 发布,历史上最重要的版本 开源日报 | 北大实习生攻击字节AI训练集群;Bitwarden进一步脱离开源;新一代MoE架构;给手机装Linux;英伟达真正的护城河是什么?