
在数据驱动的商业世界中,数据清洗是确保分析准确性的关键步骤。然而,数据清洗过程往往繁琐且容易出错。现在,有了ETLCloud,数据清洗变得简单、高效。本文将探讨数据清洗的常见问题,并展示ETLCloud如何成为解决这些问题的理想工具。
数据清洗的重要性
数据清洗,也称为数据预处理,是数据分析过程中不可或缺的一部分。它涉及到识别、修改、替换或删除不正确、不完整、不精确、不相关或缺失的数据。高质量的数据清洗可以显著提高数据分析的准确性和可靠性。
数据清洗常见问题
-
缺失值:数据集中的空白或缺失字段会影响分析结果的准确性。处理方法包括删除缺失值记录、使用均值/中位数填充或基于相似样本进行插值。
-
重复数据:多个相同或相似的记录会导致分析结果失真。可以通过唯一标识符识别并删除重复记录。
-
格式不一致:不同来源的数据可能采用不同的格式,如日期格式的多样性。统一格式转换工具能够有效解决该问题。
-
数据错误:手动录入错误或逻辑错误需要人工或自动化工具检查和修正。
ETLCloud实操案例
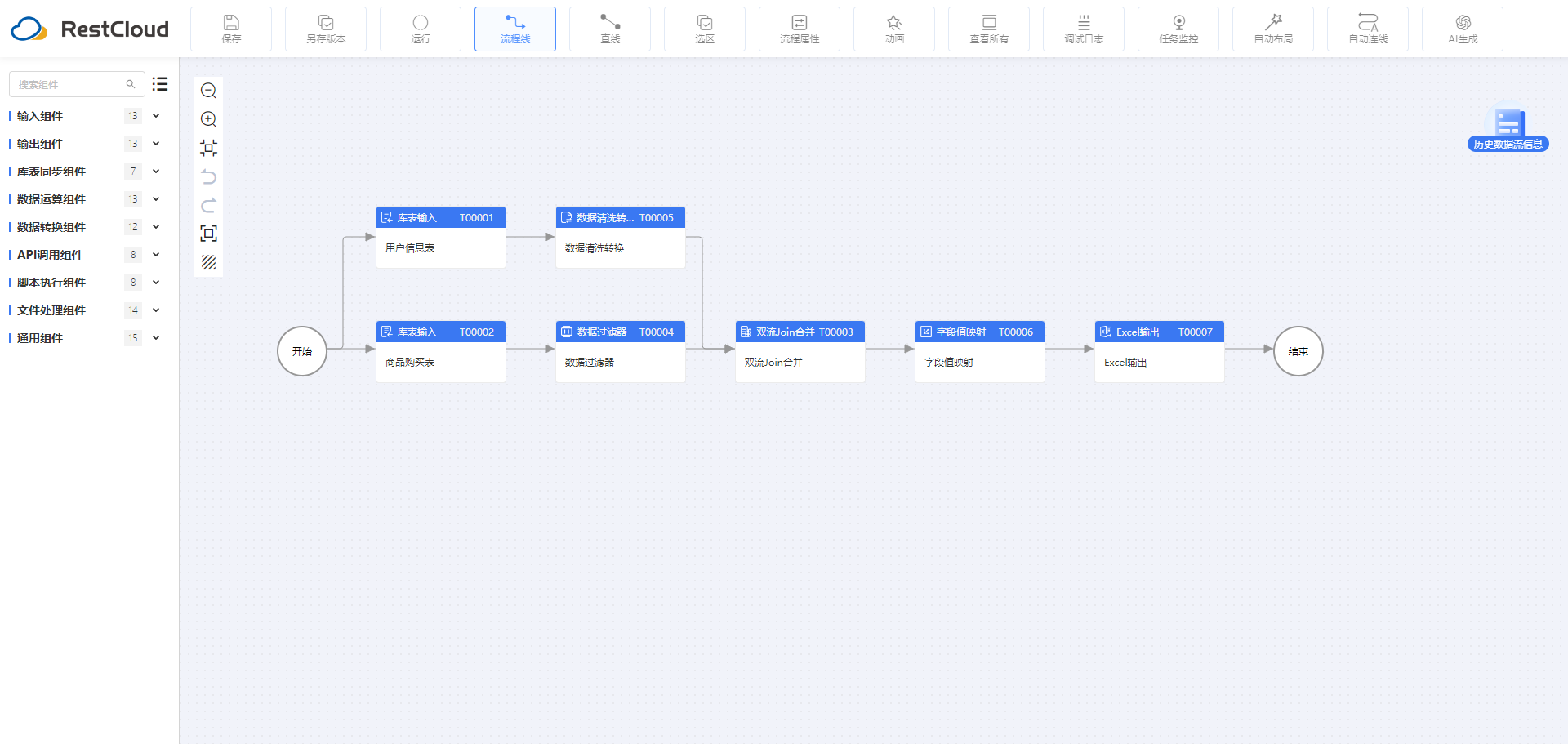
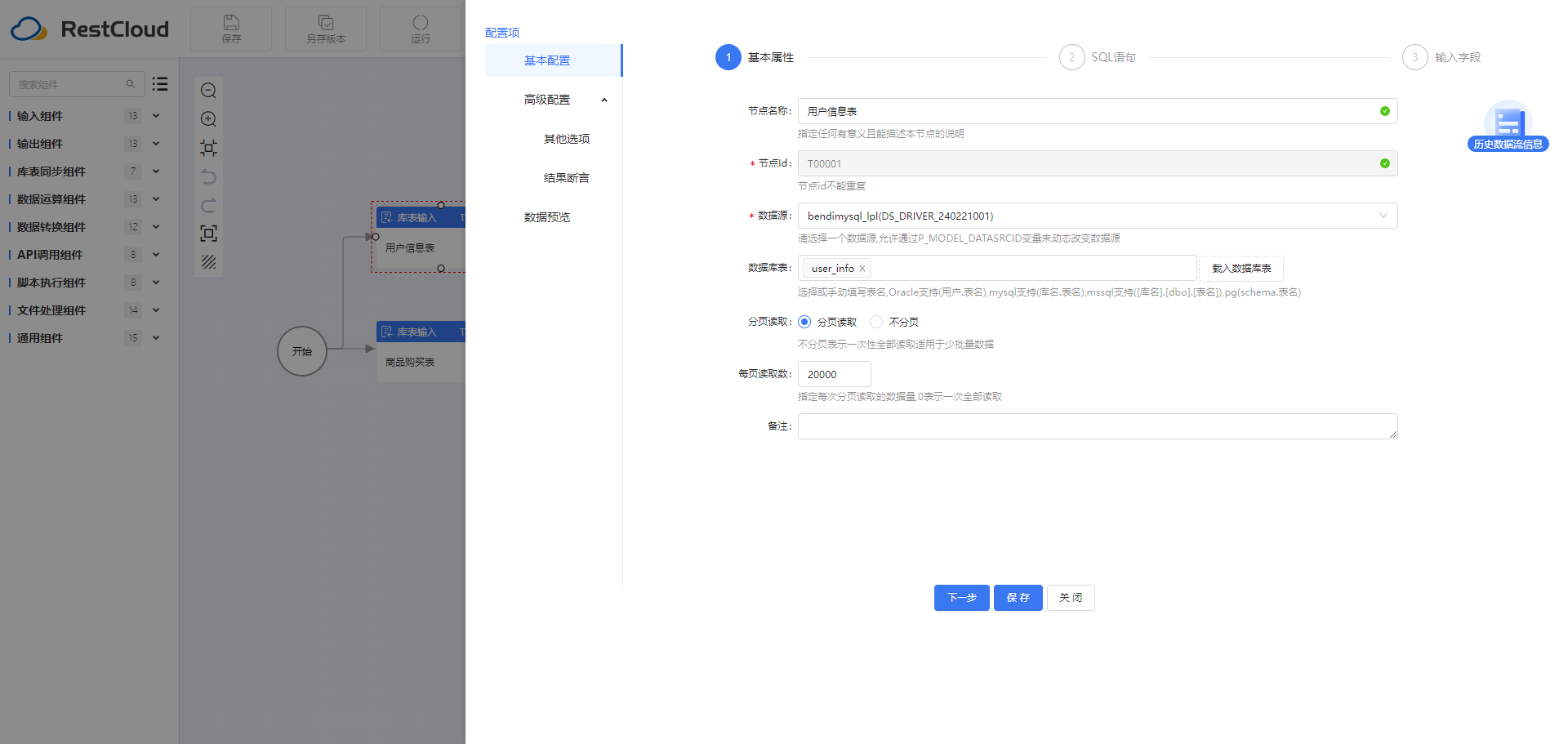
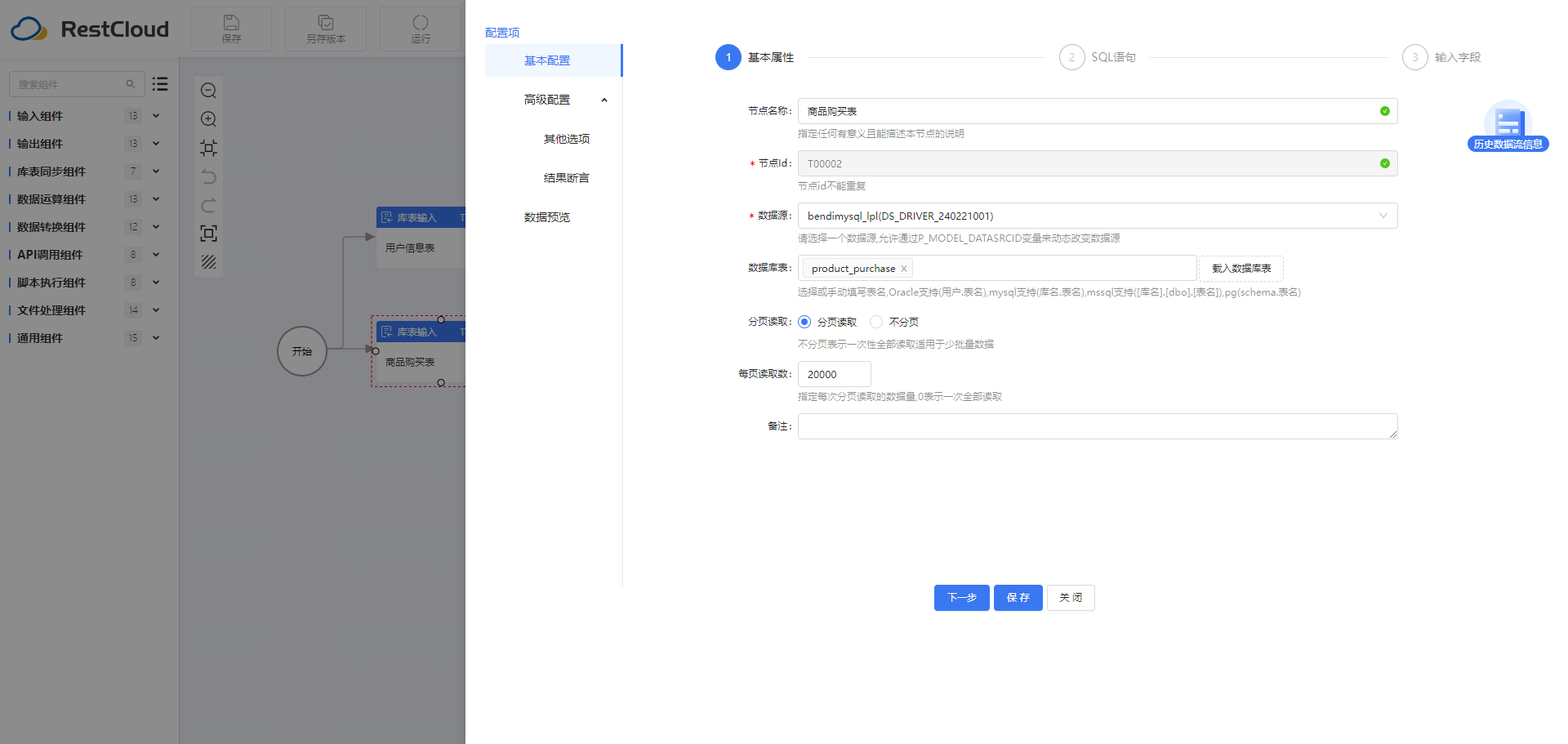
假设业务场景需要将商品购买表和用户信息表数据进行过滤清洗,根据唯一id进行整合,映射后输出为Excel文件。使用ETLCloud工具实现的步骤包括:
-
数据过滤:过滤出已支付订单。
-
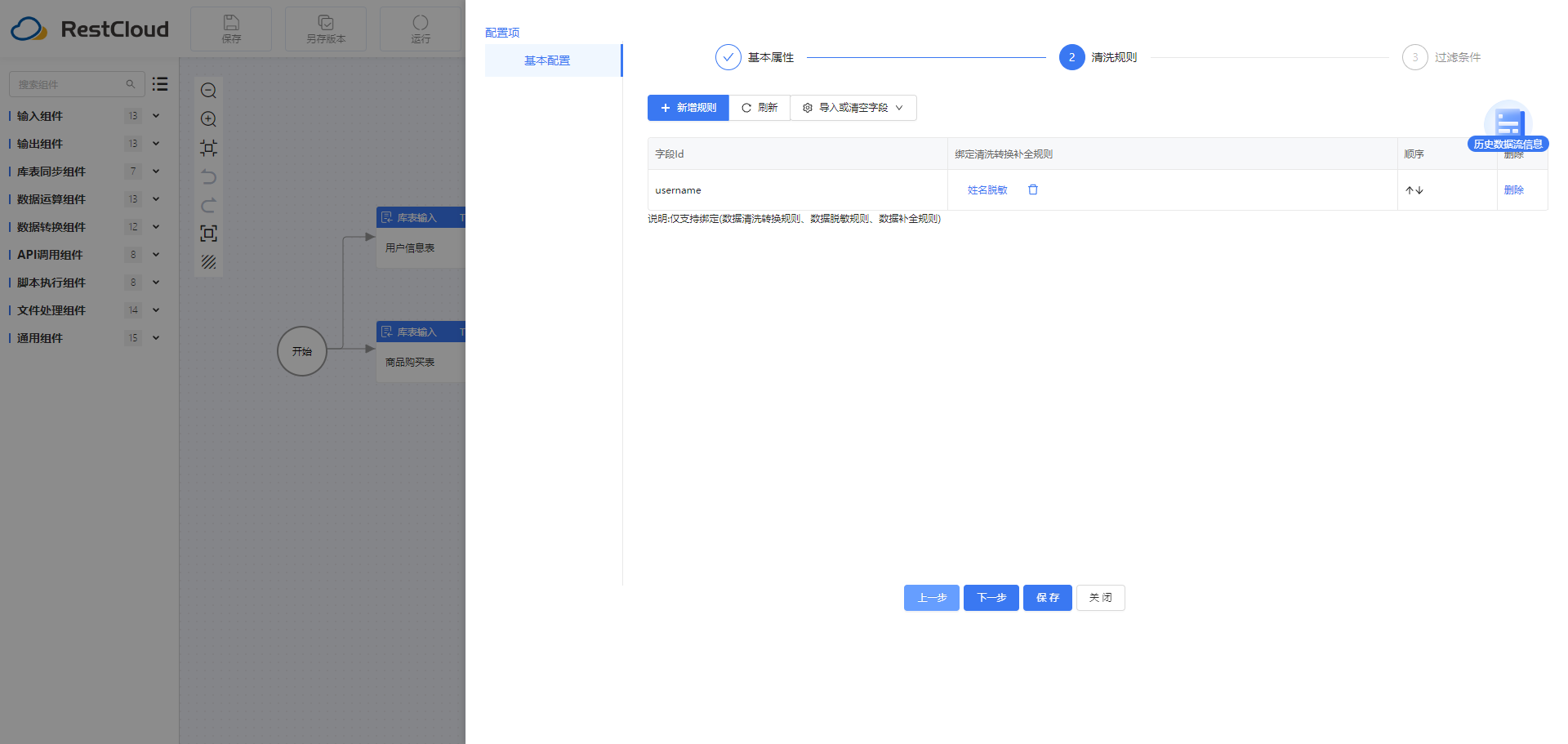
数据清洗转换:对用户姓名数据进行脱敏处理。
-
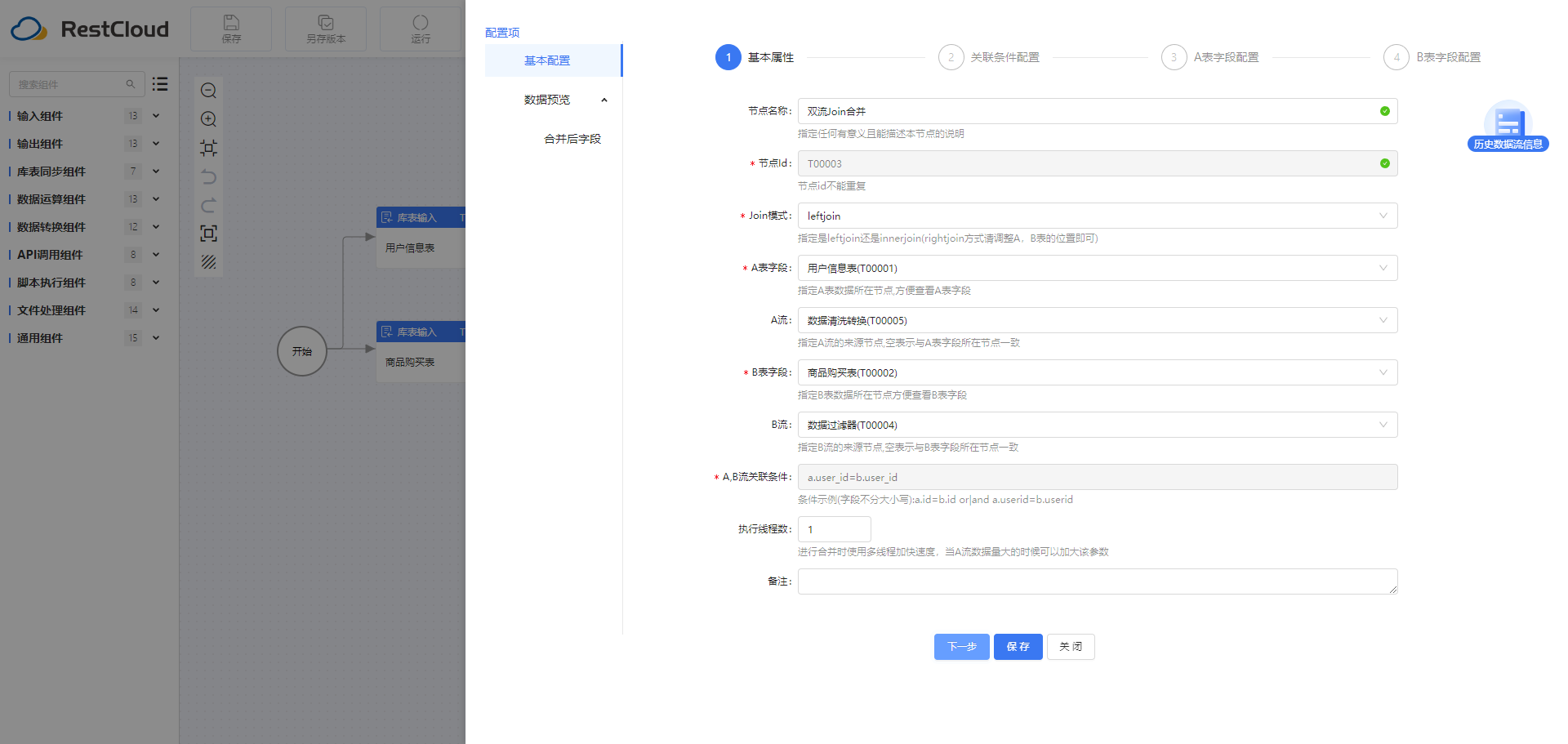
数据合并:根据商品购买表和用户表的id字段进行数据合并。
-
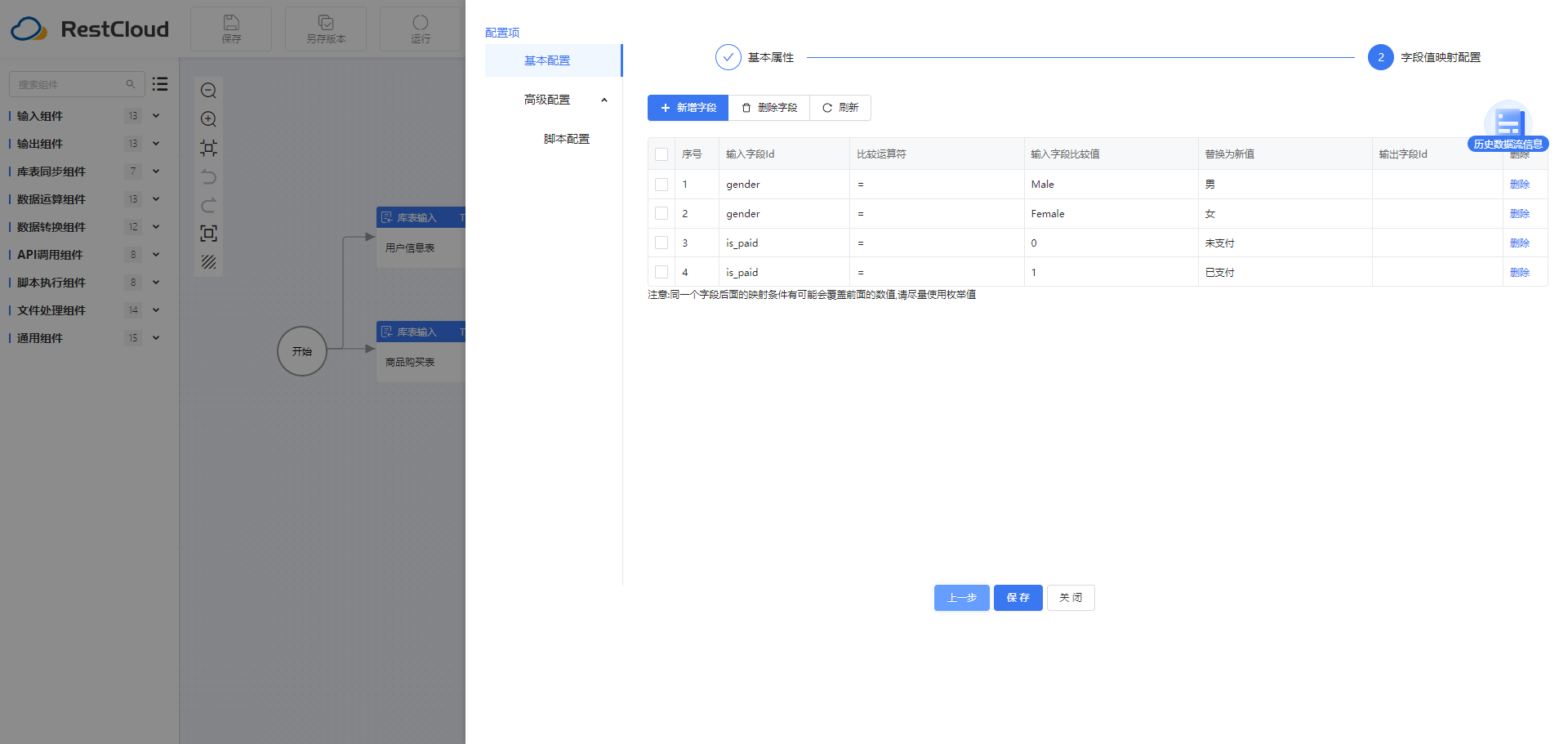
字段值映射:将性别、支付状态信息映射成中文。
-
Excel输出:配置输出信息,生成Excel文件。
1.流程设计
2.组件配置
2.1库表输入组件配置
2.2数据清洗转换组件
2.3数据过滤器组件
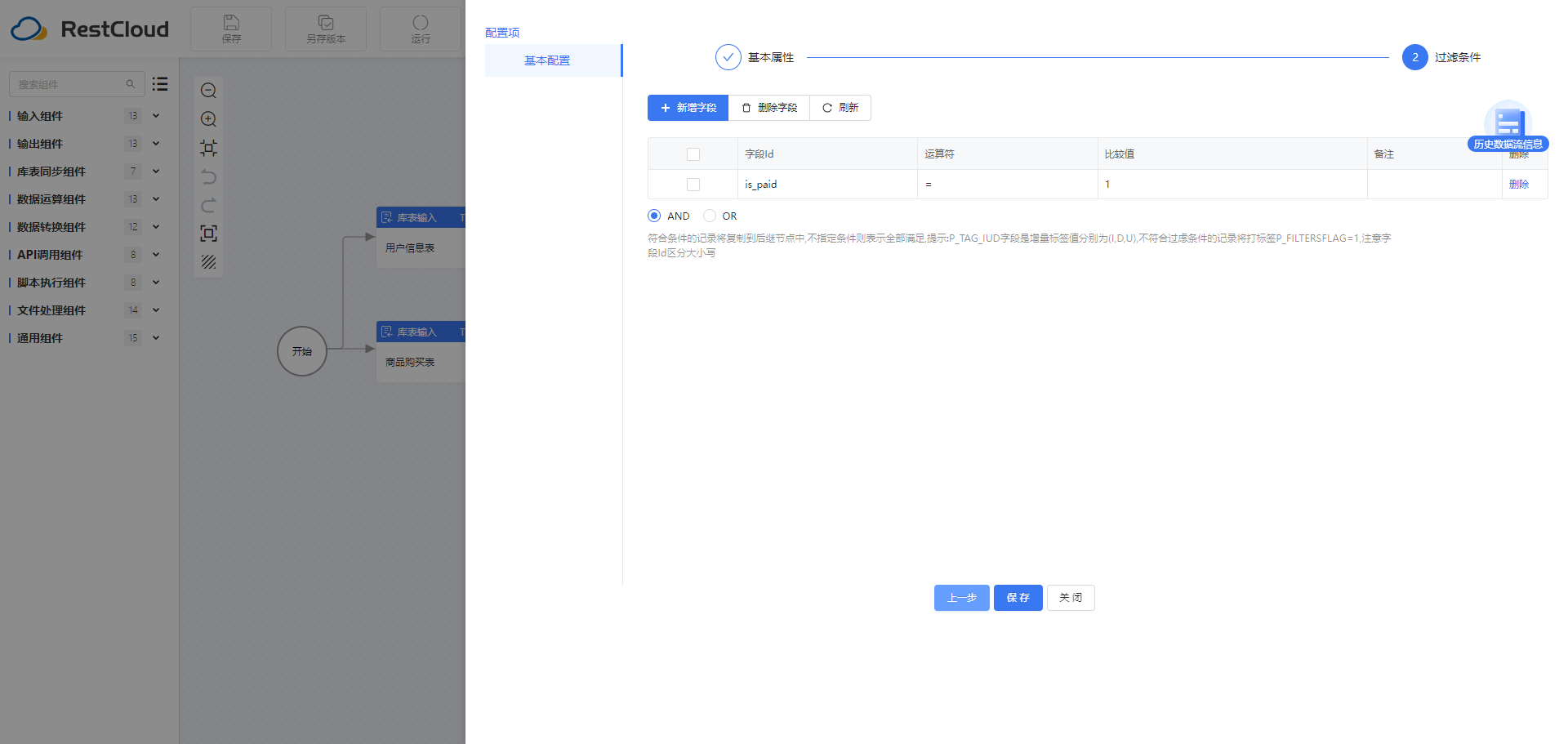
2.4双流Join合并组件
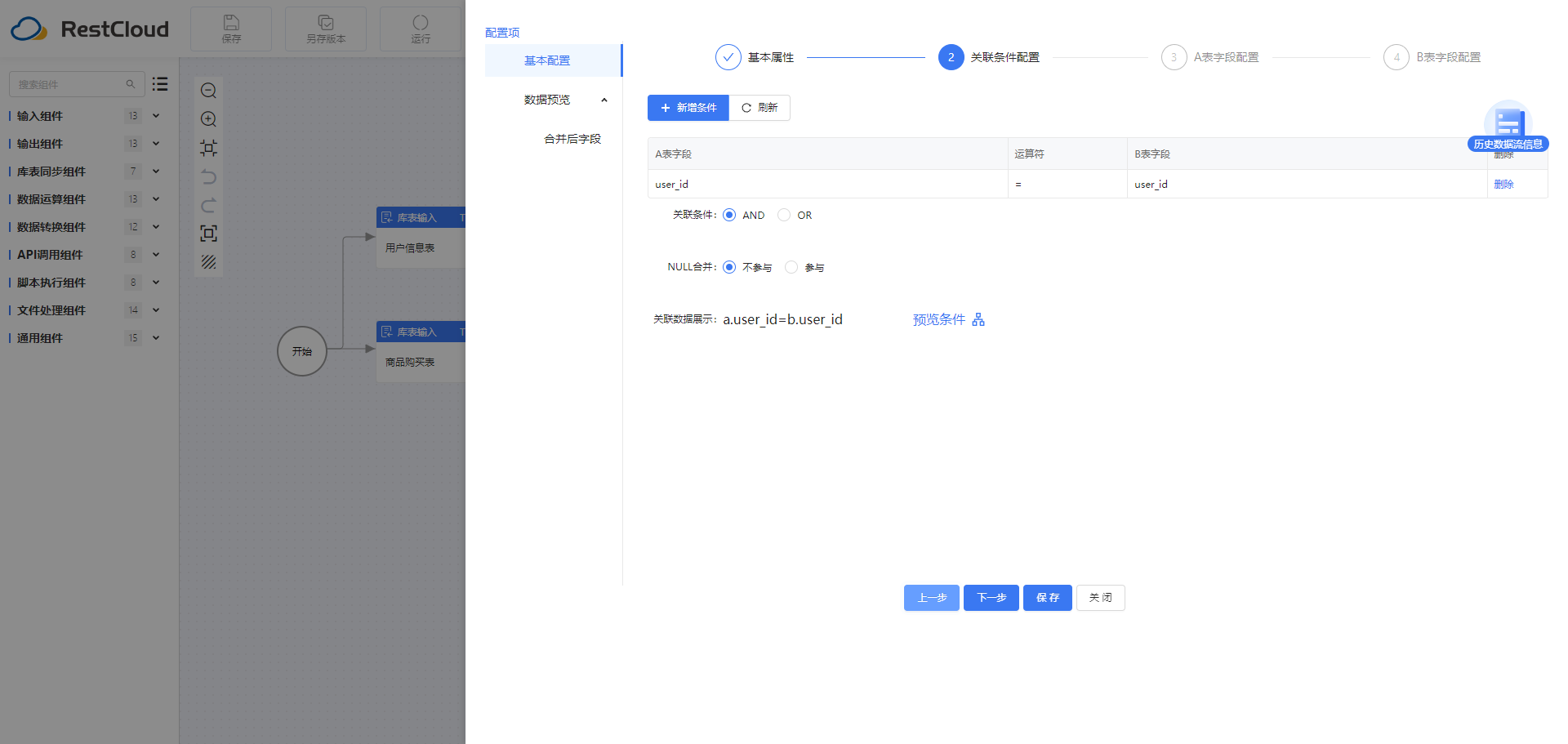
2.5字段值映射组件
2.6Execl输出组件
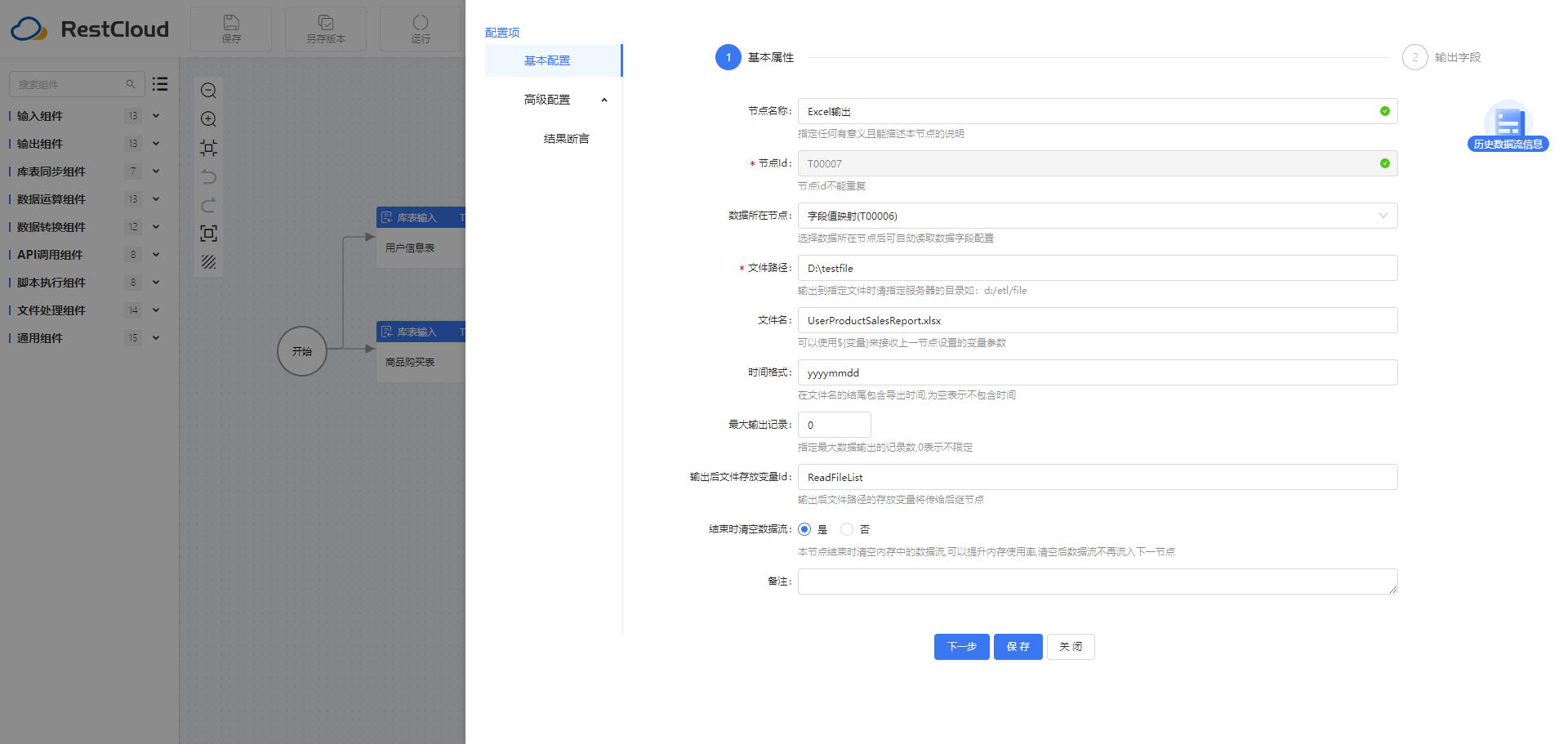
3.流程运行结果
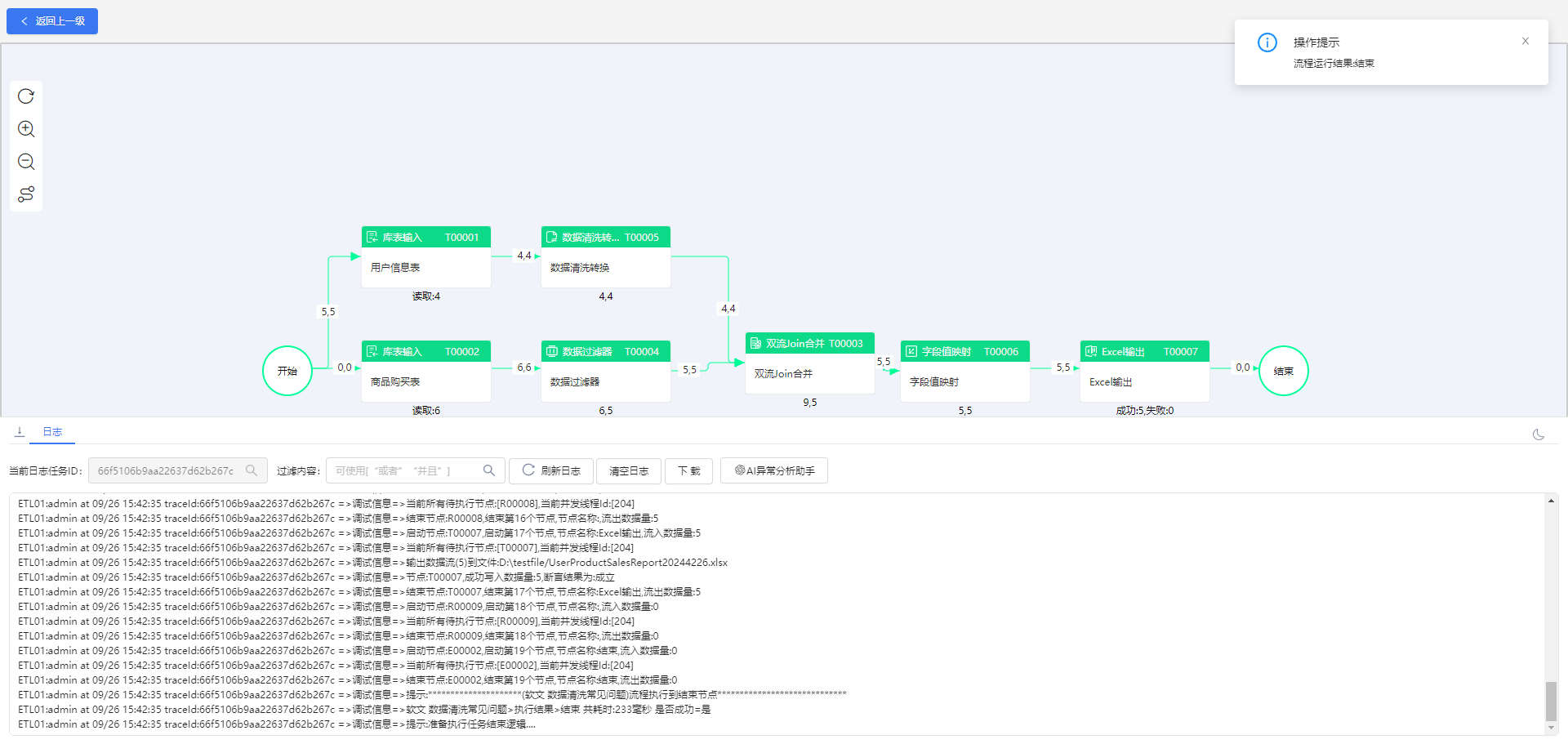
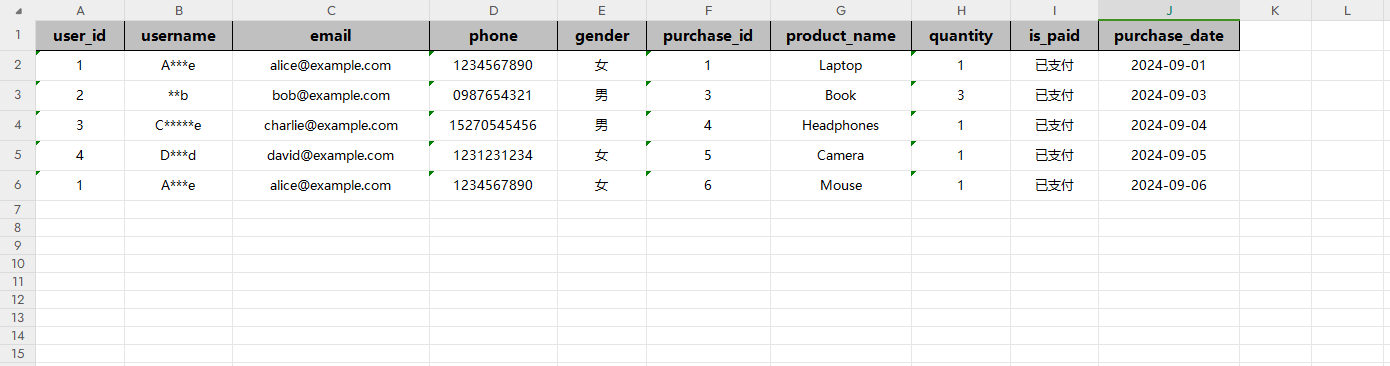
ETLCloud通过自动化数据转换和集成,帮助企业快速获取准确的数据信息,提高数据处理效率和准确性。利用ETL工具,用户可以摆脱传统方式繁琐的数据清洗转换步骤,实现数据处理流程的可控和可管理。
微软开源基于 Rust 的 OpenHCL 字节跳动商业化团队模型训练被“投毒”,内部人士称未影响豆包大模型 华为正式发布原生鸿蒙系统 OpenJDK 新提案:将 JDK 大小减少约 25% Node.js 23 正式发布,不再支持 32 位 Windows 系统 Linux 大规模移除疑似俄开发者,开源药丸? QUIC 在高速网络下不够快 RustDesk 远程桌面 Web 客户端 V2 预览 前端开发框架 Svelte 5 发布,历史上最重要的版本 开源日报 | 北大实习生攻击字节AI训练集群;Bitwarden进一步脱离开源;新一代MoE架构;给手机装Linux;英伟达真正的护城河是什么?