MySQL 02
存储引擎
类型:MyISAM、InnoDB、Memory、CSV等9中
MyISAM和InoDB的主要区别:
| 名称 | 事务处理 | 数据行锁定 | 外键约束 | 全文索引 | 表空间大小 |
| InnoDB | 支持 | 支持 | 支持 | 不支持 | 较大,约为数据的二倍 |
| MyISAM | 不支持 | 不支持 | 不支持 | 支持 | 较小 |
适用场合
show variables like 'storage_engine%';
修改存储引擎:
default-storage-engine=存储引擎(改为其他存储引擎)
设置表的存储引擎:
create table 表名(......) engine=存储引擎;

MyISAM类型表文件:.frm :表结构定义文件
.MYD :数据文件
.MYI : 索引文件
InnoDB类型表文件:.frm :表结构定义文件
ibdata1 文件
存储位置:因操作系统而异。可查my.ini
datadir="C:/ProgramData/MySQL/MySQLServer 5.5/Data/"
innodb_data_home_dir="D:/MySQL Datafiles/"
在表中添加数据INSERT INTO 表名(字段名列表) VALUE (值列表);
INSERT INTO `student` (`studentNo`, `loginPwd`, `studentName`, `sex`, `gradeID`, `phone`, `address`, `bornDate`, `email`, `identityCard`) VALUES('10000','123','郭靖','男','1','13645667783','天津市河西区','1990-09-08 00:00:00',NULL,'123456');
INSERT INTO `student` (`studentNo`, `loginPwd`, `studentName`, `sex`, `gradeID`, `phone`, `address`, `bornDate`, `email`, `identityCard`) VALUES('10001','123','李文才','男','1','13645667890','地址不详','1994-04-12 00:00:00',NULL,'234567');
INSERT INTO `student` (`studentNo`, `loginPwd`, `studentName`, `sex`, `gradeID`, `phone`, `address`, `bornDate`, `email`, `identityCard`) VALUES('10002','123','李斯文','男','1','13645556793','河南洛阳','1993-07-23 00:00:00',NULL,'345678');
INSERT INTO `student` (`studentNo`, `loginPwd`, `studentName`, `sex`, `gradeID`, `phone`, `address`, `bornDate`, `email`, `identityCard`) VALUES('10003','123','张萍','女','1','13642345112','地址不详','1995-06-10 00:00:00',NULL,'456789');
INSERT INTO `student` (`studentNo`, `loginPwd`, `studentName`, `sex`, `gradeID`, `phone`, `address`, `bornDate`, `email`, `identityCard`) VALUES('10004','123','韩秋洁','女','1','13812344566','北京市海淀区','1995-07-15 00:00:00',NULL,'567890');
如上图所示,我们在上次创建的student列表中添加5条数据,注意的是数据值顺序必须与字段名顺序相同,若不写字段名,数据值则根据原表字段顺序注意匹配。
一次添加多条顺序:
INSERT INTO 新表(字段名列表) VALUES(值列表1),(值列表2),……,(值列表n);
INSERT INTO `student` (`studentNo`, `loginPwd`, `studentName`, `sex`, `gradeID`, `phone`, `address`, `bornDate`, `email`, `identityCard`)
VALUES ('10005','123','张秋丽','女','1','13567893246','北京市东城区','1994-01-17 00:00:00',NULL,'1'),
('10006','123','肖梅','女','1','13563456721','河北省石家庄市','1991-02-17 00:00:00',NULL,'2'),
('10007','123','秦洋','男','1','13056434411','上海市卢湾区','1992-04-18 00:00:00',NULL,'3');
为避免表结构发生变化引发的错误,建议插入数据时写明具体字段名!
将查询结果插入新表,有两种方法:
1.CREATE TABLE 新表(select字段1,字段2,... FROM 原表);
CREATE TABLE phonelist( SELECT studentName,phone FROM student);如上查询了student表中的学生姓名(studentName)和电话(phone),并将其存储到列表phonelist中,如果phonelist列表不存在则创建一个名为phonelist的列表, 存在在列表中添加如上数据。
2.INSERT INTO 新表(必须存在) SELECT (字段名1,字段名2....) FROM 旧表;
#phontlist 必须存在 且列表中数据必须与原表一致 INSERT INTO phontlist(studentName,phone) SELECT studentName,phone FROM student;
第二种中的phonelist列表必须存在,且列表中数据必须与原表student查询的数据一致。
数据更新
UPDATE 表名
SET 字段1=值1,字段2=值2,...,字段n=值n
[WHERE 条件];#匹配机制 逐行匹配
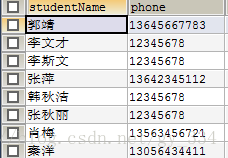
UPDATE phonelist SET phone='12345678' WHERE LENGTH(studentName)>6;
将刚刚创建的列表phonelist中名字长度大于6的电话值改为12345678(因为一个汉字占3个字节,所以取大于6即为汉字多于2的),执行代码后查询表如下:
删除数据记录
1. DELETE FROM 表名[WHERE 条件];
2. TRUNCATE TABLE 表名;
DELETE 语句删除后不重置自增列
TRUNCATE语句删除后将重置自增列,表结构及其字段、约束、索引保持不变,
#但执行得速度不快。而且还可以返回被删除的记录数。
#而TRUNCATE TABLE无法删除指定的记录,而且不能返回被删除的记录。但它执行得非常快。
查询
查询列表的所有行列:SELECT * FROM 表名;
查询语法:
SELECT 列名|表达式|函数|常量
FROM 表名
[WHERE 查询条件表达式]
[ORDER BY 排名 [ASC 或 DESC]]; #desc 降序
使用AS命名列,例如:
SELECT `studentNo` AS '学号',`studentName` AS '姓名',`gradeID` AS '年级',`bornDate` AS '出生日期',`phone` AS '电话' FROM student WHERE `gradeID`=1 ORDER BY bornDate DESC
上述代码查询了student列表中的的列,并另命名,将满足学号为1 的数据按照出生日期从大到小排列,如下

使用AS命名列 别名
SELECT `firstName` + '.' + `lastName` AS 姓名
FROM `employees`;
#1. + 连接的数据类型必须兼容
#2. 如果 + 连接字符型数据,结果为字符串数据的连接
#3. 如果 + 连接数值型数据,结果为数值的和
查询空行:
SELECT `studentName` FROM `student` WHERE `email` IS NULL;
如上查询了student列表中email为空的学生姓名
常量列:
SELECT *,'北京信息中心' AS '学校名称' FROM student
WHERE email IS NULL
如上代码意为查询student列表中email为空的数据都添加一份学校名称为北京信息中心的列。
limit 语句 主要用于做分页
SELECT <字段名列表>
FROM <表名或视图>
[WHERE <查询条件>]
[GROUP BY <分组的字段名>]
[ORDER BY <排序的列名>[ASC 或 DESC]]
[LIMIT [位置偏移量],行数];
这里需注意:limit起始位置为1开始
常用函数:
聚合函数
| 函数名 | 作用 |
| AVG() | 返回某字段的平均值 |
| COUNT() | 返回某字段的行数 |
MAX() |
返回某字段的最大值 |
| MIN() | 返回某字段的最小值 |
| SUM() | 返回某字段的和 |
举个例子,我们查询result列表中学生成绩的平均,参加人数,最高分,最低分,所有成绩总和:
SELECT AVG(`studentResult`)AS '平均成绩', COUNT(*) AS '参加人数', MAX(`studentResult`) AS '最高分', MIN(`studentResult`) AS '最低分', SUM(`studentResult`) AS '总和' FROM result
查询结果如下:

字符串函数:
| 函数名 | 作用 | 举例 |
| CONCAT(str1, str1...strn) | 字符串连接 | SELECT CONCAT('My','S','QL'); 返回:MySQL |
| INSERT(str,pos,len,newstr) | 字符串替换 | SELECT INSERT('这是SQL Server数据库',3,10,'MySQL'); 返回:这是MySQL数据库 #pos 从哪开始(从1开始算) len(替换的长度) |
| LOWER(str) | 将字符串转为小写 | SELECT LOWER('MySQL'); 返回:mysql |
| UPPER(str) | 将字符串转为大写 | SELECT UPPER('MySQL'); 返回:MYSQL |
| SUBSTRING(str,num,len) | 字符串提取 | SELECT SUBSTRING('JavaMySQLOracle',5,5); 返回:MySQL |
时间日期函数:
| 函数名 | 作用 |
| CURDATA() | 截取当前日期 |
| CURTIME() | 截取当前时间 |
| NOW() | 截取当前日期和时间 |
| WEEK(DATE) | 返回日期date为一年中的第几周 |
| YEAR(date) | 返回日期date的年份 |
| HOUR(time) | 返回时间time的小时值 |
| MINUTE(time) | 返回时间的分钟值 |
| DATEDIFF(date1,date2) | 返回日期参数date1和date2之间相隔的天数 |
| ADDDATE(date,n) | 计算日期参数date加上n天后的日期 |
数学函数:
| 函数名 | 作用 | 举例 |
| CEIL(x) | 返回大于或等于数值x的最小整数 | SELECT CEIL(2.3) 返回3 |
| FLOOR(x) | 返回小于或等于数值x的最大整数 | SELECT FLOOR(2.3) 返回2 |
| RAND() | 返回0~1间的随机数 | SELECT RAND() 随机返回一个0~1之间的饿数 |