原本以为我能深入解析,源码,发现我还是太native了,,,有很多深入的方法和设计我发现并不是短时间内能理解了,所以还是改为浅析算了。
ArrayList

transient Object[] elementData; // non-private to simplify nested class access
/**
* The size of the ArrayList (the number of elements it contains).
*
* @serial
*/
private int size;
这里transient 有点意思,可以参见这篇博客Java transient关键字使用小记
首先它的底层是数组,添加元素的时候如果超出当前数组的length就会扩展数组长度,保证add操作的均摊是
的这个在算法导论中有分析,与数据结构有关。不过它的扩展策略并不是简单的加倍,而是扩展
倍,看源码
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
private void ensureCapacityInternal(int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
// overflow-conscious code//??
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);//3*oldCap
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}首句 很有意思,作者说它的代码是 overflow-conscious code 这里留个坑
第二个地方是 toArray
toArray
public Object[] toArray() {
return Arrays.copyOf(elementData, size);
}
@SuppressWarnings("unchecked")
public <T> T[] toArray(T[] a) {
if (a.length < size)
// Make a new array of a's runtime type, but my contents:
return (T[]) Arrays.copyOf(elementData, size, a.getClass());
System.arraycopy(elementData, 0, a, 0, size);
if (a.length > size)
a[size] = null;
return a;
}这点在接口中就讲到了,不过当时不涉及它的底层实现,这里可以看到它的具体实现了。也说明了为什么toArray() 方法强制转化会出错,因为 返回的实体类型是: Object[], 然而后者不是;不过还是需要说明的是,前者一个一个强制转化类型还是可以的。看下面的代码
List<String> list = new ArrayList<>(Arrays.asList("123","234","ok"));
Object[] tmp = list.toArray();
String[] aStrings= new String[tmp.length];
for(int i=0; i<tmp.length; ++i)
aStrings[i] = (String) tmp[i];//ok
String[] xStrings=(String[]) list.toArray();//exceptionsublist
public List<E> subList(int fromIndex, int toIndex) {
subListRangeCheck(fromIndex, toIndex, size);
return new SubList(this, 0, fromIndex, toIndex);
}
private class SubList extends AbstractList<E> implements RandomAccess {
private final AbstractList<E> parent;
private final int parentOffset;
private final int offset;
int size;
SubList(AbstractList<E> parent,
int offset, int fromIndex, int toIndex) {
this.parent = parent;
this.parentOffset = fromIndex;
this.offset = offset + fromIndex;
this.size = toIndex - fromIndex;
this.modCount = ArrayList.this.modCount;
}
子列表视图,所谓视图 view 数组还是原来的,不会重新建一个,也就是说,用sublist方法返回的子列表所有操作都是基于ArrayList.this.elementData的,这点可以从上面的方法和Sublist类的构造方法中看出Sublist没有任何持有data的手段。
至此介绍完毕,剩余JDK 8 的内容等以后搬砖用到再说了
LinkedList
这个没有什么好说的,他的底层实现是一个双向链表,并且是没有头结点(国内教材的说法)的双向链表。实现了List和Deque的功能可以说非常强大了。
关于给定index查找那个给定index的元素,这里有一个小小的优化
Node<E> node(int index) {
// assert isElementIndex(index);
//优化,常数优化
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}即只用 的查找时间,这是一个常数优化。
ArrayDeque
双端队列的数组实现,(JDK 1.6 才有的,作者都变了。。。。) 这和本科数据结构教材中讲的循环队列实现方式一样。简单的说就是
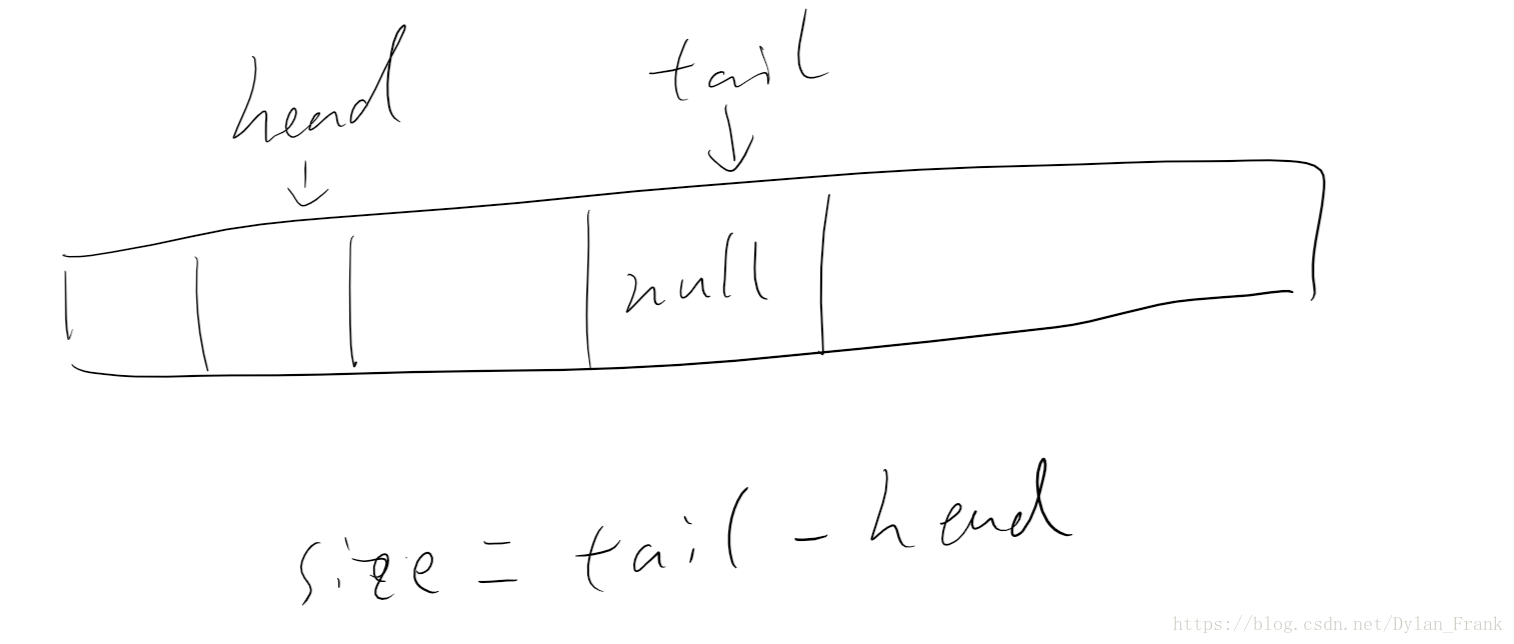
用数组来做底层实现,并且 head 和 tail 两端都可以进队或者出队。语义上类似
tail = (tail+1) % n
head = (head-1) % n用作进队操作。不过实际实现中做了一个模运算的优化,后面我们会谈。整个队列始终保持这样的不变性:
private void checkInvariants() {
assert elements[tail] == null;
assert head == tail ? elements[head] == null :
(elements[head] != null &&
elements[(tail - 1) & (elements.length - 1)] != null);
assert elements[(head - 1) & (elements.length - 1)] == null;
}以及 elementData.length = 2^k, 这点在后优化的时候显得尤为重要。 接下来谈谈是实现者在模运算上做的优化。
模运算的优化
首先来看看这个数组长度始终维持在 这里所做的事情
public ArrayDeque() {
elements = new Object[16];
}
public ArrayDeque(int numElements) {
allocateElements(numElements);
}
public ArrayDeque(Collection<? extends E> c) {
allocateElements(c.size());
addAll(c);
}
private void allocateElements(int numElements) {
int initialCapacity = MIN_INITIAL_CAPACITY;
// Find the best power of two to hold elements.
// Tests "<=" because arrays aren't kept full.
//倍增, O(logn) 解决,由于总共32位,这样最多5次移位就ok
if (numElements >= initialCapacity) {
initialCapacity = numElements;
initialCapacity |= (initialCapacity >>> 1);
initialCapacity |= (initialCapacity >>> 2);
initialCapacity |= (initialCapacity >>> 4);
initialCapacity |= (initialCapacity >>> 8);
initialCapacity |= (initialCapacity >>> 16);
initialCapacity++;
if (initialCapacity < 0) // Too many elements, must back off
initialCapacity >>>= 1;// Good luck allocating 2 ^ 30 elements
}
elements = new Object[initialCapacity];
}
private void doubleCapacity() {
assert head == tail;
int p = head;
int n = elements.length;
int r = n - p; // number of elements to the right of p
int newCapacity = n << 1;
if (newCapacity < 0)
throw new IllegalStateException("Sorry, deque too big");
Object[] a = new Object[newCapacity];
System.arraycopy(elements, p, a, 0, r);
System.arraycopy(elements, 0, a, r, p);
elements = a;
head = 0;
tail = n;
}
上面几个函数是数组大小改变的唯一入口,核心的是这个 allocateElements 这里他做了一个优化,用倍增策略在常数时间找到一个数的最小二次幂,这一点我在这篇博文中分析过了 : [java 源码思考] O(1)时间找到一个数的最小二次幂(Find the best power of two)–ArrayDeque 。
那么为什么要用二次幂来作为数组长度呢?
请看队头,队尾的增加策略
public void addFirst(E e) {
if (e == null)
throw new NullPointerException();
elements[head = (head - 1) & (elements.length - 1)] = e;// 优化模运算带来的开销, head = (head-1) % (length -1)
if (head == tail)
doubleCapacity();
}
public void addLast(E e) {
if (e == null)
throw new NullPointerException();
elements[tail] = e;
if ( (tail = (tail + 1) & (elements.length - 1)) == head)// 难怪用2的幂次
doubleCapacity();
}
public E pollFirst() {
int h = head;
@SuppressWarnings("unchecked")
E result = (E) elements[h];
// Element is null if deque empty
if (result == null)
return null;
elements[h] = null; // Must null out slot
head = (h + 1) & (elements.length - 1);
return result;
}
public E pollLast() {
int t = (tail - 1) & (elements.length - 1);
@SuppressWarnings("unchecked")
E result = (E) elements[t];
if (result == null)
return null;
elements[t] = null;
tail = t;
return result;
}
进队出队核心就是上面这4个方法了,其他都是对他的包装。 我们可以看到他用位运算代替了模运算。重点看着4句话
1. elements[head = (head - 1) & (elements.length - 1)] = e;// 优化模运算带来的开销, head = (head-1) % (length -1)
2. if ( (tail = (tail + 1) & (elements.length - 1)) == head)// 难怪用2的幂次
doubleCapacity();
3. head = (h + 1) & (elements.length - 1);
4. int t = (tail - 1) & (elements.length - 1);我们知道模运算( )真正 起作用仅在 : , 前者结果为 0后者结果为 , 第二句 当 时起作用, 这时相当于 & , 由于 -1 的补码表示是 全一,所以结果为 与 ele的长度无关,不过后者就有关系了;
当 时,此时相当于做了 & 由于 所以结果正好为0。