1.Druid介绍
参考文章:链接地址
Druid是一个为在大数据集之上做实时统计分析而设计的开源数据存储。这个系统集合了一个面向列存储的层,一个分布式、shared-nothing的架构,和一个高级的索引结构,来达成在秒级以内对十亿行级别的表进行任意的探索分析。
特性
为分析而设计——Druid是为OLAP工作流的探索性分析而构建。它支持各种filter、aggregator和查询类型,并为添加新功能提供了一个框架。用户已经利用Druid的基础设施开发了高级K查询和直方图功能。
交互式查询——Druid的低延迟数据摄取架构允许事件在它们创建后毫秒内查询,因为Druid的查询延时通过只读取和扫描优必要的元素被优化。Aggregate和 filter没有坐等结果。
高可用性——Druid是用来支持需要一直在线的SaaS的实现。你的数据在系统更新时依然可用、可查询。规模的扩大和缩小不会造成数据丢失。
可伸缩——现有的Druid部署每天处理数十亿事件和TB级数据。Druid被设计成PB级别。
使用场景:
第一:适用于清洗好的记录实时录入,但不需要更新操作
第二:支持宽表,不用join的方式(换句话说就是一张单表)
第三:可以总结出基础的统计指标,可以用一个字段表示
第四:对时区和时间维度(year、month、week、day、hour等)要求高的(甚至到分钟级别)
第五:实时性很重要
第六:对数据质量的敏感度不高
第七:用于定位效果分析和策略决策参考
架构
它的架构如图所示:
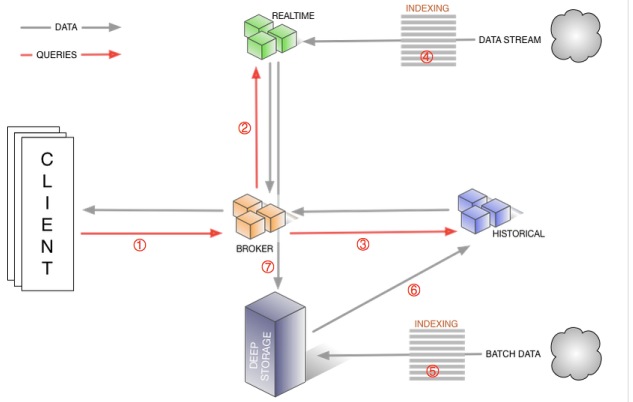
- 查询路径:红色箭头:①客户端向Broker发起请求,Broker会将请求路由到②实时节点和③历史节点
- Druid数据流转:黑色箭头:数据源包括实时流和批量数据. ④实时流经过索引直接写到实时节点,⑤批量数据通过IndexService存储到DeepStorage,⑥再由历史节点加载. ⑦实时节点也可以将数据转存到DeepStorage
Druid的整体架构中目前包括以下节点类型:
Historical节点是对“historical”数据(非实时)进行处理存储和查询的地方。historical节点响应从broker节点发来的查询,并将结果返回给broker节点。它们在Zookeeper的管理下提供服务,并使用Zookeeper监视信号加载或删除新数据段.。
Realtime节点实时摄取数据,它们负责监听输入数据流并让其在内部的Druid系统立即获取,Kafka中的同一个partition只允许被一个实时节点消费,Realtime节点同样只响应broker节点的查询请求,返回查询结果到broker节点。旧数据会被从Realtime节点转存至Historical节点。
Coordinator节点负责历史节点的数据负载均衡,监控historical节点组,以确保数据可用、可复制,并且在一般的“最佳”配置。它们通过从MySQL读取数据段的元数据信息,来决定哪些数据段应该在集群中被加载,使用Zookeeper来确定哪个historical节点存在,并且创建Zookeeper条目告诉historical节点加载和删除新数据段。
Broker节点接收来自外部客户端的查询,并将这些查询转发到Realtime和Historical节点。当Broker节点收到结果,它们将合并这些结果并将它们返回给调用者。由于了解拓扑,Broker节点使用Zookeeper来确定哪些Realtime和Historical节点的存在。
Indexer节点会形成一个加载批处理和实时数据到系统中的集群,同时会对存储在系统中的数据变更(也称为索引服务)做出响应。
这种分离让每个节点只关心自身的最优操作。通过将Historical 和Realtime分离,将对进入系统的实时流数据监控和处理的内存分离。通过将Coordinator和Broker分离,把查询操作和维持集群上的“好的”数据分布的操作分离。
除了这些节点,系统还有3个外部依赖:
一个运行的ZooKeeper集群,为集群服务发现和维持当前的数据拓扑而服务;
一个MySQL实例,用来维持系统服务所需的数据段的元数据;
一个LOB存储系统,保存“冷数据”
高可用性
实时节点:实时节点会将消费进度同步到zookeeper,当一个实时节点不可用时,kafka消费组会在组内的节点中进行partitiong的重新分配,但是已经消费的数据就不能再被消费了,这时候,需要想办法将不可用的实时节点重新回到集群变成可用节点。
历史节点:新的历史节点添加后,会通过zookeeper被协调节点发现,然后协调节点会自动分配相关的segment给他;原有的历史节点被移除集群后,同样会被协调节点发现,然后协调节点会将原来分配给他的segment重新分配给其他节点。
查询节点:集群可以有多个查询节点,都能获得相同的结果;
协调节点:集群中有多个协调节点,当某个协调节点退出后,其他节点仍然可以正常工作。如果没协调节点在运行,然后数据拓扑将停止变化,但该系统将继续运行。
深度存储:实时节点的数据会先存入深度存储,然后再由协调节点分配给历史节点,如果文件系统如果不可用,新数据将无法进入集群,但集群将继续按原来方式操作。
MySQL:如果不可用,协调节点将无法找出系统中的新segment,但原有的数据仍然可以被查询到。
ZooKeeper:如果不可用,数据拓扑结构改变将不能进行,但Broker将相应的保持它们最新的数据拓扑视图和持续服务请求。
2.安装
安装环境
本文使用Imply套件安装,该套件提供了稳定的druid和web访问接口,在安装之前需要先安装node,
node下载地址:https://nodejs.org/en/download/
imply下载地址:http://imply.io/download
node安装完成后使用下列命令检查:
node --version安装过程
参考wiki:https://imply.io/docs/latest/quickstart
1.解压Imply
tar -xzf imply-2.0.0.tar
2.启动服务
nohup bin/supervise -c conf/supervise/quickstart.conf > test.log &log日志记录:
-
[Sun Apr 2 23:32:09 2017] Running command[zk], logging to[/Users/ball/Downloads/imply-2.0.0/var/sv/zk.log]: bin/run-zk conf-quickstart -
[Sun Apr 2 23:32:09 2017] Running command[coordinator], logging to[/Users/ball/Downloads/imply-2.0.0/var/sv/coordinator.log]: bin/run-druid coordinator conf-quickstart -
[Sun Apr 2 23:32:09 2017] Running command[broker], logging to[/Users/ball/Downloads/imply-2.0.0/var/sv/broker.log]: bin/run-druid broker conf-quickstart -
[Sun Apr 2 23:32:09 2017] Running command[historical], logging to[/Users/ball/Downloads/imply-2.0.0/var/sv/historical.log]: bin/run-druid historical conf-quickstart -
[Sun Apr 2 23:32:09 2017] Running command[overlord], logging to[/Users/ball/Downloads/imply-2.0.0/var/sv/overlord.log]: bin/run-druid overlord conf-quickstart -
[Sun Apr 2 23:32:09 2017] Running command[middleManager], logging to[/Users/ball/Downloads/imply-2.0.0/var/sv/middleManager.log]: bin/run-druid middleManager conf-quickstart -
[Sun Apr 2 23:32:09 2017] Running command[pivot], logging to[/Users/ball/Downloads/imply-2.0.0/var/sv/pivot.log]: bin/run-pivot-quickstart conf-quickstart
服务停止与启动命令
-
./server --down 关闭 -
./server --restart ${服务名称} 重启
3.数据导入
quickstart/wikiticker-2016-06-27-sampled.json 维奇百科网站日志数据
数据格式:
{"isRobot":true,"channel":"#pl.wikipedia","timestamp":"2016-06-27T00:00:58.599Z","flags":"NB","isUnpatrolled":false,"page":"Kategoria:Dyskusje nad usunięciem artykułu zakończone bez konsensusu − lipiec 2016","diffUrl":"https://pl.wikipedia.org/w/index.php?oldid=46204477&rcid=68522573","added":270,"comment":"utworzenie kategorii","commentLength":20,"isNew":true,"isMinor":false,"delta":270,"isAnonymous":false,"user":"Beau.bot","deltaBucket":200.0,"deleted":0,"namespace":"Kategoria"}
quickstart/wikiticker-index.json定义了任务的数据源,时间信息,维度信息,指标信息,内容如下:
-
{ -
"type" : "index_hadoop", -
"spec" : { -
"ioConfig" : { -
"type" : "hadoop", -
"inputSpec" : { -
"type" : "static", -
"paths" : "quickstart/wikiticker-2016-06-27-sampled.json" -
} -
}, -
"dataSchema" : { -
"dataSource" : "wikiticker", -
"granularitySpec" : { -
"type" : "uniform", -
"segmentGranularity" : "day", -
"queryGranularity" : "none", -
"intervals" : ["2016-06-27/2016-06-28"] -
}, -
"parser" : { -
"type" : "hadoopyString", -
"parseSpec" : { -
"format" : "json", -
"dimensionsSpec" : { -
"dimensions" : [ -
"channel", -
"cityName", -
"comment", -
"countryIsoCode", -
"countryName", -
"isAnonymous", -
"isMinor", -
"isNew", -
"isRobot", -
"isUnpatrolled", -
"metroCode", -
"namespace", -
"page", -
"regionIsoCode", -
"regionName", -
"user", -
"commentLength", -
"deltaBucket", -
"flags", -
"diffUrl" -
] -
}, -
"timestampSpec" : { -
"format" : "auto", -
"column" : "timestamp" -
} -
} -
}, -
"metricsSpec" : [ -
{ -
"name" : "count", -
"type" : "count" -
}, -
{ -
"name" : "added", -
"type" : "longSum", -
"fieldName" : "added" -
}, -
{ -
"name" : "deleted", -
"type" : "longSum", -
"fieldName" : "deleted" -
}, -
{ -
"name" : "delta", -
"type" : "longSum", -
"fieldName" : "delta" -
}, -
{ -
"name" : "user_unique", -
"type" : "hyperUnique", -
"fieldName" : "user" -
} -
] -
}, -
"tuningConfig" : { -
"type" : "hadoop", -
"partitionsSpec" : { -
"type" : "hashed", -
"targetPartitionSize" : 5000000 -
}, -
"jobProperties" : {} -
} -
} -
}
使用离线导入:
./bin/post-index-task --file quickstart/wikiticker-index.json
-
Task started: index_hadoop_wikiticker_2017-04-02T15:44:23.464Z -
Task log: http://localhost:8090/druid/indexer/v1/task/index_hadoop_wikiticker_2017-04-02T15:44:23.464Z/log -
Task status: http://localhost:8090/druid/indexer/v1/task/index_hadoop_wikiticker_2017-04-02T15:44:23.464Z/status -
Task index_hadoop_wikiticker_2017-04-02T15:44:23.464Z still running... -
Task index_hadoop_wikiticker_2017-04-02T15:44:23.464Z still running... -
Task index_hadoop_wikiticker_2017-04-02T15:44:23.464Z still running... -
Task index_hadoop_wikiticker_2017-04-02T15:44:23.464Z still running... -
Task index_hadoop_wikiticker_2017-04-02T15:44:23.464Z still running... -
Task index_hadoop_wikiticker_2017-04-02T15:44:23.464Z still running... -
Task index_hadoop_wikiticker_2017-04-02T15:44:23.464Z still running... -
Task index_hadoop_wikiticker_2017-04-02T15:44:23.464Z still running... -
Task finished with status: SUCCESS
4.访问web地址
http://localhost:9095/,
查看刚刚导入数据
5.使用查询语句查询
/quickstart/wikiticker-top-pages.json
-
{ -
"queryType" : "topN", -
"dataSource" : "wikiticker", -
"intervals" : ["2016-06-27/2016-06-28"], -
"granularity" : "all", -
"dimension" : "page", -
"metric" : "edits", -
"threshold" : 25, -
"aggregations" : [ -
{ -
"type" : "longSum", -
"name" : "edits", -
"fieldName" : "count" -
} -
] -
}
查询语句:
curl -L -H'Content-Type: application/json' -XPOST --data-binary @quickstart/wikiticker-top-pages.json http://localhost:8082/druid/v2/结果数据:
[{"timestamp":"2016-06-27T00:00:11.080Z","result":[{"page":"Copa América Centenario","edits":29},{"page":"User:Cyde/List of candidates for speedy deletion/Subpage","edits":16},{"page":"Wikipedia:Administrators' noticeboard/Incidents","edits":16},{"page":"2016 Wimbledon Championships – Men's Singles","edits":15},{"page":"Wikipedia:Administrator intervention against vandalism","edits":15},{"page":"Wikipedia:Vandalismusmeldung","edits":15},{"page":"The Winds of Winter (Game of Thrones)","edits":12},{"page":"ولاية الجزائر","edits":12},{"page":"Copa América","edits":10},{"page":"Lionel Messi","edits":10},{"page":"Wikipedia:Requests for page protection","edits":10},{"page":"Wikipedia:Usernames for administrator attention","edits":10},{"page":"Википедия:Опросы/Унификация шаблонов «Не переведено»","edits":10},{"page":"Bailando 2015","edits":9},{"page":"Bud Spencer","edits":9},{"page":"User:Osterb/sandbox","edits":9},{"page":"Wikipédia:Le Bistro/27 juin 2016","edits":9},{"page":"Ветра зимы (Игра престолов)","edits":9},{"page":"Användare:Lsjbot/Namnkonflikter-PRIVAT","edits":8},{"page":"Eurocopa 2016","edits":8},{"page":"Mistrzostwa Europy w Piłce Nożnej 2016","edits":8},{"page":"Usuario:Carmen González C/Science and technology in China","edits":8},{"page":"Wikipedia:Administrators' noticeboard","edits":8},{"page":"Wikipédia:Demande de suppression immédiate","edits":8},{"page":"World Deaf Championships","edits":8}]}]