转载至: http://blog.csdn.net/yinwenjie 并由个人筛选内容合并。
java.util.concurrent.ForkJoinPool由Java大师Doug Lea主持编写,它可以将一个大的任务拆分成多个子任务进行并行处理,最后将子任务结果合并成最后的计算结果,并进行输出。本文中对Fork/Join框架的讲解,基于JDK1.8+中的Fork/Join框架实现,参考的Fork/Join框架主要源代码也基于JDK1.8+。
这几篇文章将试图解释Fork/Join框架的知识点,以便对自己、对各位读者在并发程序的设计思路上进行一些启发。文章将首先讲解Fork/Join框架的基本使用,以及其中需要注意的使用要点;接着使用Fork/Join框架解决一些实际问题;最后再讲解Fork/Join框架的工作原理。
2. Fork/Join框架基本使用
这里是一个简单的Fork/Join框架使用示例,在这个示例中我们计算了1-1001累加后的值:
/**
* 这是一个简单的Join/Fork计算过程,将1—1001数字相加
*/
public class TestForkJoinPool {
private static final Integer MAX = 200;
static class MyForkJoinTask extends RecursiveTask<Integer> {
// 子任务开始计算的值
private Integer startValue;
// 子任务结束计算的值
private Integer endValue;
public MyForkJoinTask(Integer startValue , Integer endValue) {
this.startValue = startValue;
this.endValue = endValue;
}
@Override
protected Integer compute() {
// 如果条件成立,说明这个任务所需要计算的数值分为足够小了
// 可以正式进行累加计算了
if(endValue - startValue < MAX) {
System.out.println("开始计算的部分:startValue = " + startValue + ";endValue = " + endValue);
Integer totalValue = 0;
for(int index = this.startValue ; index <= this.endValue ; index++) {
totalValue += index;
}
return totalValue;
}
// 否则再进行任务拆分,拆分成两个任务
else {
MyForkJoinTask subTask1 = new MyForkJoinTask(startValue, (startValue + endValue) / 2);
subTask1.fork();
MyForkJoinTask subTask2 = new MyForkJoinTask((startValue + endValue) / 2 + 1 , endValue);
subTask2.fork();
return subTask1.join() + subTask2.join();
}
}
}
public static void main(String[] args) {
// 这是Fork/Join框架的线程池
ForkJoinPool pool = new ForkJoinPool();
ForkJoinTask<Integer> taskFuture = pool.submit(new MyForkJoinTask(1,1001));
try {
Integer result = taskFuture.get();
System.out.println("result = " + result);
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace(System.out);
}
}
}以上代码很简单,在关键的位置有相关的注释说明。这里本文再对以上示例中的要点进行说明。首先看看以上示例代码的可能执行结果:
开始计算的部分:startValue = 1;endValue = 126
开始计算的部分:startValue = 127;endValue = 251
开始计算的部分:startValue = 252;endValue = 376
开始计算的部分:startValue = 377;endValue = 501
开始计算的部分:startValue = 502;endValue = 626
开始计算的部分:startValue = 627;endValue = 751
开始计算的部分:startValue = 752;endValue = 876
开始计算的部分:startValue = 877;endValue = 1001
result = 5015012-1. 工作顺序图
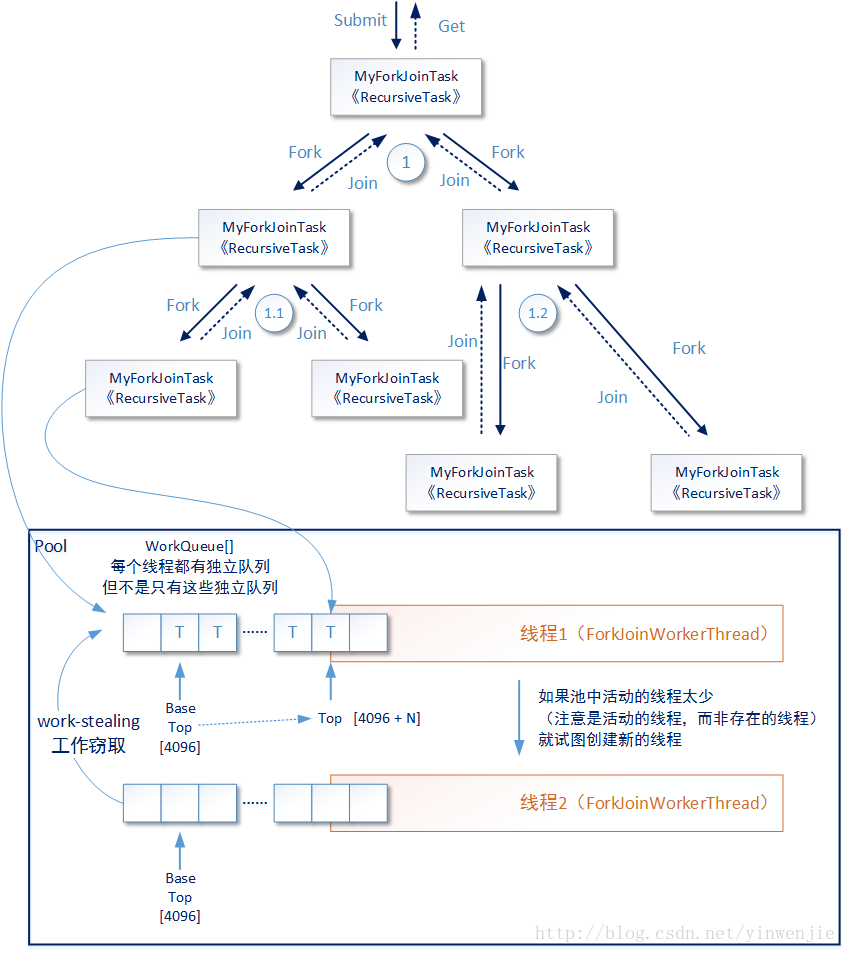
下图展示了以上代码的工作过程概要,但实际上Fork/Join框架的内部工作过程要比这张图复杂得多,例如如何决定某一个recursive task是使用哪条线程进行运行;再例如如何决定当一个任务/子任务提交到Fork/Join框架内部后,是创建一个新的线程去运行还是让它进行队列等待。
所以如果不深入理解Fork/Join框架的运行原理,只是根据之上最简单的使用例子观察运行效果,那么我们只能知道子任务在Fork/Join框架中被拆分得足够小后,并且其内部使用多线程并行完成这些小任务的计算后再进行结果向上的合并动作,最终形成顶层结果。不急,一步一步来,我们先从这张概要的过程图开始讨论。
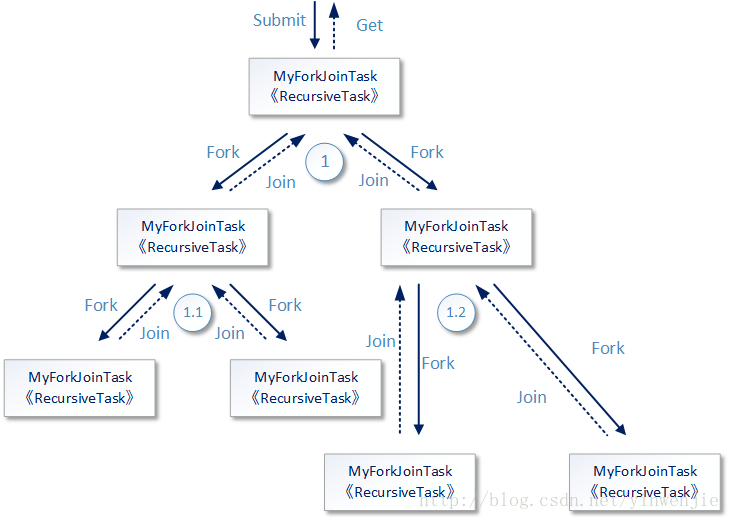
图中最顶层的任务使用submit方式被提交到Fork/Join框架中,后者将前者放入到某个线程中运行,工作任务中的compute方法的代码开始对这个任务T1进行分析。如果当前任务需要累加的数字范围过大(代码中设定的是大于200),则将这个计算任务拆分成两个子任务(T1.1和T1.2),每个子任务各自负责计算一半的数据累加,请参见代码中的fork方法。如果当前子任务中需要累加的数字范围足够小(小于等于200),就进行累加然后返回到上层任务中。
2-2. ForkJoinPool构造函数
ForkJoinPool有四个构造函数,其中参数最全的那个构造函数如下所示:

public ForkJoinPool(int parallelism,
ForkJoinWorkerThreadFactory factory,
UncaughtExceptionHandler handler,
boolean asyncMode)-
parallelism:可并行级别,Fork/Join框架将依据这个并行级别的设定,决定框架内并行执行的线程数量。并行的每一个任务都会有一个线程进行处理,但是千万不要将这个属性理解成Fork/Join框架中最多存在的线程数量,也不要将这个属性和ThreadPoolExecutor线程池中的corePoolSize、maximumPoolSize属性进行比较,因为ForkJoinPool的组织结构和工作方式与后者完全不一样。而后续的讨论中,读者还可以发现Fork/Join框架中可存在的线程数量和这个参数值的关系并不是绝对的关联(有依据但并不全由它决定)。
-
factory:当Fork/Join框架创建一个新的线程时,同样会用到线程创建工厂。只不过这个线程工厂不再需要实现ThreadFactory接口,而是需要实现ForkJoinWorkerThreadFactory接口。后者是一个函数式接口,只需要实现一个名叫newThread的方法。在Fork/Join框架中有一个默认的ForkJoinWorkerThreadFactory接口实现:DefaultForkJoinWorkerThreadFactory。
-
handler:异常捕获处理器。当执行的任务中出现异常,并从任务中被抛出时,就会被handler捕获。
-
asyncMode:这个参数也非常重要,从字面意思来看是指的异步模式,它并不是说Fork/Join框架是采用同步模式还是采用异步模式工作。Fork/Join框架中为每一个独立工作的线程准备了对应的待执行任务队列,这个任务队列是使用数组进行组合的双向队列。即是说存在于队列中的待执行任务,即可以使用先进先出的工作模式,也可以使用后进先出的工作模式。
当asyncMode设置为ture的时候,队列采用先进先出方式工作;反之则是采用后进先出的方式工作,该值默认为false:
...... asyncMode ? FIFO_QUEUE : LIFO_QUEUE, ......
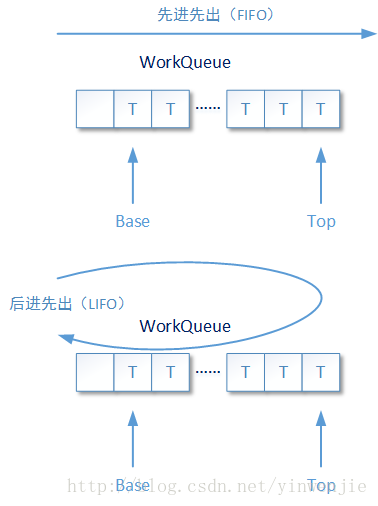
ForkJoinPool还有另外两个构造函数,一个构造函数只带有parallelism参数,既是可以设定Fork/Join框架的最大并行任务数量;另一个构造函数则不带有任何参数,对于最大并行任务数量也只是一个默认值——当前操作系统可以使用的CPU内核数量(Runtime.getRuntime().availableProcessors())。实际上ForkJoinPool还有一个私有的、原生构造函数,之上提到的三个构造函数都是对这个私有的、原生构造函数的调用。
......
private ForkJoinPool(int parallelism,
ForkJoinWorkerThreadFactory factory,
UncaughtExceptionHandler handler,
int mode,
String workerNamePrefix) {
this.workerNamePrefix = workerNamePrefix;
this.factory = factory;
this.ueh = handler;
this.config = (parallelism & SMASK) | mode;
long np = (long)(-parallelism); // offset ctl counts
this.ctl = ((np << AC_SHIFT) & AC_MASK) | ((np << TC_SHIFT) & TC_MASK);
}
......如果你对Fork/Join框架没有特定的执行要求,可以直接使用不带有任何参数的构造函数。也就是说推荐基于当前操作系统可以使用的CPU内核数作为Fork/Join框架内最大并行任务数量,这样可以保证CPU在处理并行任务时,尽量少发生任务线程间的运行状态切换(实际上单个CPU内核上的线程间状态切换基本上无法避免,因为操作系统同时运行多个线程和多个进程)。
2-3. fork方法和join方法
Fork/Join框架中提供的fork方法和join方法,可以说是该框架中提供的最重要的两个方法,它们和parallelism“可并行任务数量”配合工作,可以导致拆分的子任务T1.1、T1.2甚至TX在Fork/Join框架中不同的运行效果。例如TX子任务或等待其它已存在的线程运行关联的子任务,或在运行TX的线程中“递归”执行其它任务,又或者启动一个新的线程运行子任务……
fork方法用于将新创建的子任务放入当前线程的work queue队列中,Fork/Join框架将根据当前正在并发执行ForkJoinTask任务的ForkJoinWorkerThread线程状态,决定是让这个任务在队列中等待,还是创建一个新的ForkJoinWorkerThread线程运行它,又或者是唤起其它正在等待任务的ForkJoinWorkerThread线程运行它。
这里面有几个元素概念需要注意,ForkJoinTask任务是一种能在Fork/Join框架中运行的特定任务,也只有这种类型的任务可以在Fork/Join框架中被拆分运行和合并运行。ForkJoinWorkerThread线程是一种在Fork/Join框架中运行的特性线程,它除了具有普通线程的特性外,最主要的特点是每一个ForkJoinWorkerThread线程都具有一个独立的任务等待队列(work queue),这个任务队列用于存储在本线程中被拆分的若干子任务。
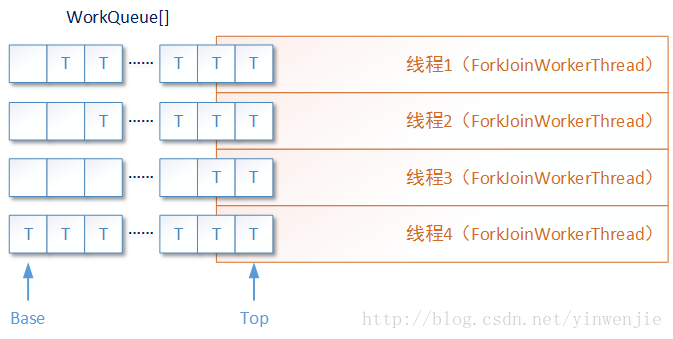
join方法用于让当前线程阻塞,直到对应的子任务完成运行并返回执行结果。或者,如果这个子任务存在于当前线程的任务等待队列(work queue)中,则取出这个子任务进行“递归”执行。其目的是尽快得到当前子任务的运行结果,然后继续执行。
3. 使用Fork/Join解决实际问题
之前文章讲解Fork/Join框架的基本使用时,所举的的例子是使用Fork/Join框架完成1-1000的整数累加。这个示例如果只是演示Fork/Join框架的使用,那还行,但这种例子和实际工作中所面对的问题还有一定差距。本篇文章我们使用Fork/Join框架解决一个实际问题,就是高效排序的问题。
3-1. 使用归并算法解决排序问题
排序问题是我们工作中的常见问题。目前也有很多现成算法是为了解决这个问题而被发明的,例如多种插值排序算法、多种交换排序算法。而并归排序算法是目前所有排序算法中,平均时间复杂度较好(O(nlgn)),算法稳定性较好的一种排序算法。它的核心算法思路将大的问题分解成多个小问题,并将结果进行合并。
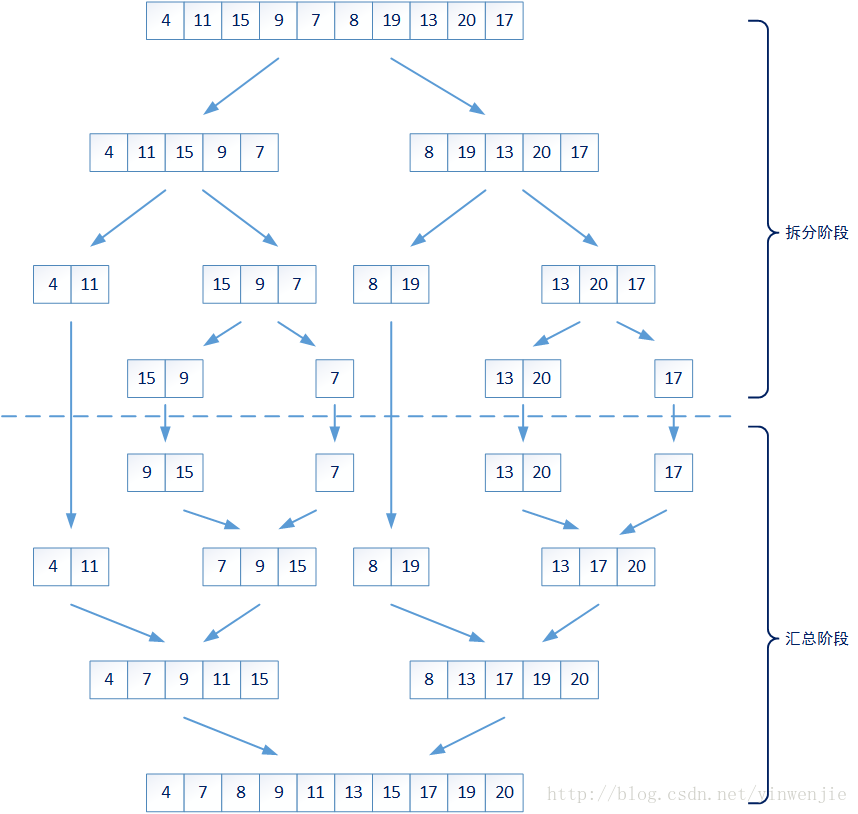
整个算法的拆分阶段,是将未排序的数字集合,从一个较大集合递归拆分成若干较小的集合,这些较小的集合要么包含最多两个元素,要么就认为不够小需要继续进行拆分。
那么对于一个集合中元素的排序问题就变成了两个问题:1、较小集合中最多两个元素的大小排序;2、如何将两个有序集合合并成一个新的有序集合。第一个问题很好解决,那么第二个问题是否会很复杂呢?实际上第二个问题也很简单,只需要将两个集合同时进行一次遍历即可完成——比较当前集合中最小的元素,将最小元素放入新的集合,它的时间复杂度为O(n):
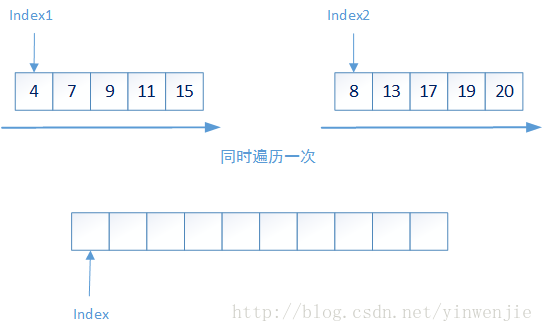
3-2. 使用Fork/Join运行归并算法
但是随着待排序集合中数据规模继续增大,以上归并算法的代码实现就有一些力不从心了,例如以上算法对1亿条随机数集合进行排序时,耗时为27秒左右。
接着我们可以使用Fork/Join框架来优化归并算法的执行性能,将拆分后的子任务实例化成多个ForkJoinTask任务放入待执行队列,并由Fork/Join框架在多个ForkJoinWorkerThread线程间调度这些任务。如下图所示:
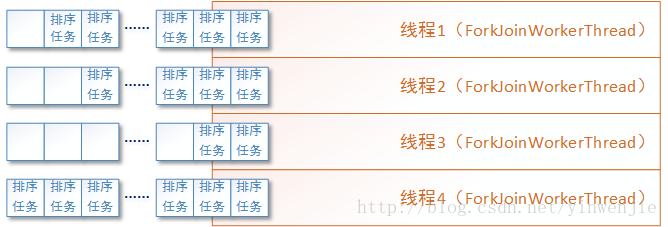
以下为使用Fork/Join框架后的归并算法代码
import java.util.Arrays;
import java.util.Random;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.ForkJoinTask;
import java.util.concurrent.RecursiveTask;
/**
* 使用Fork/Join框架的归并排序算法
*
* @author yinwenjie
*/
public class TestMerge {
private static int MAX = 1000000;
private static int inits[] = new int[MAX];
// 同样进行随机队列初始化,这里就不再赘述了
static {
Random r = new Random();
for (int index = 1; index <= MAX; index++) {
inits[index - 1] = r.nextInt(10000000);
}
}
public static void main(String[] args) throws Exception {
// 正式开始
long beginTime = System.currentTimeMillis();
ForkJoinPool pool = new ForkJoinPool();
MyTask task = new MyTask(inits);
ForkJoinTask<int[]> taskResult = pool.submit(task);
try {
int[] ints = taskResult.get();
// System.out.println(Arrays.toString(ints));
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace(System.out);
}
long endTime = System.currentTimeMillis();
System.out.println("耗时=" + (endTime - beginTime));
}
/**
* 单个排序的子任务
*
* @author yinwenjie
*/
static class MyTask extends RecursiveTask<int[]> {
private int source[];
public MyTask(int source[]) {
this.source = source;
}
/* (non-Javadoc)
* @see java.util.concurrent.RecursiveTask#compute()
*/
@Override
protected int[] compute() {
int sourceLen = source.length;
// 如果条件成立,说明任务中要进行排序的集合还不够小
if (sourceLen > 2) {
int midIndex = sourceLen / 2;
// 拆分成两个子任务
MyTask task1 = new MyTask(Arrays.copyOf(source, midIndex));
task1.fork();
MyTask task2 = new MyTask(Arrays.copyOfRange(source, midIndex, sourceLen));
task2.fork();
// 将两个有序的数组,合并成一个有序的数组
int result1[] = task1.join();
int result2[] = task2.join();
int mer[] = joinInts(result1, result2);
System.out.println("-------"+Thread.currentThread().getName());
return mer;
}
// 否则说明集合中只有一个或者两个元素,可以进行这两个元素的比较排序了
else {
// 如果条件成立,说明数组中只有一个元素,或者是数组中的元素都已经排列好位置了
if (sourceLen == 1
|| source[0] <= source[1]) {
return source;
} else {
int targetp[] = new int[sourceLen];
targetp[0] = source[1];
targetp[1] = source[0];
return targetp;
}
}
}
/**
* 这个方法用于合并两个有序集合
*
* @param array1
* @param array2
*/
private static int[] joinInts(int array1[], int array2[]) {
int destInts[] = new int[array1.length + array2.length];
int array1Len = array1.length;
int array2Len = array2.length;
int destLen = destInts.length;
// 只需要以新的集合destInts的长度为标准,遍历一次即可
for (int index = 0, array1Index = 0, array2Index = 0; index < destLen; index++) {
int value1 = array1Index >= array1Len ? Integer.MAX_VALUE : array1[array1Index];
int value2 = array2Index >= array2Len ? Integer.MAX_VALUE : array2[array2Index];
// 如果条件成立,说明应该取数组array1中的值
if (value1 < value2) {
array1Index++;
destInts[index] = value1;
}
// 否则取数组array2中的值
else {
array2Index++;
destInts[index] = value2;
}
}
return destInts;
}
}
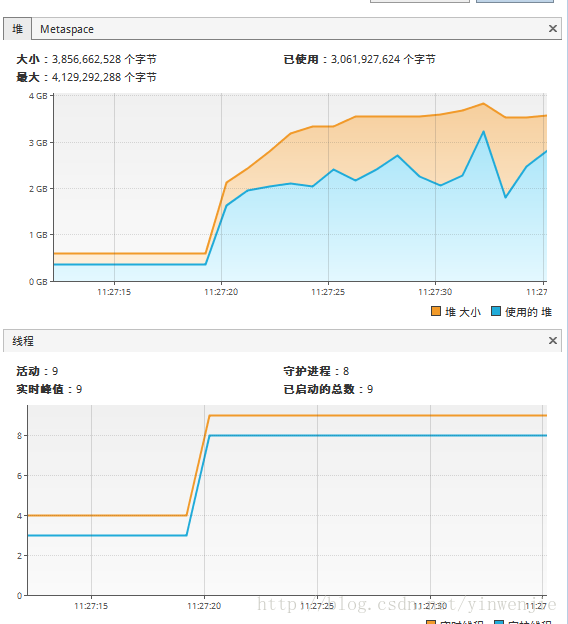
}使用Fork/Join框架优化后,同样执行1亿条随机数的排序处理时间大约在14秒左右,当然这还和待排序集合本身的凌乱程度、CPU性能等有关系。但总体上这样的方式比不使用Fork/Join框架的归并排序算法在性能上有30%左右的性能提升。以下为执行时观察到的CPU状态和线程状态:
-
JMX中的内存、线程状态:
-
CPU使用情况:
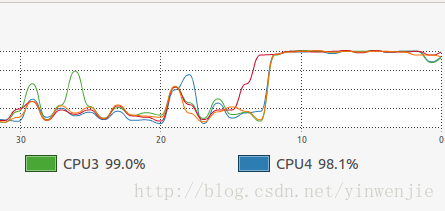
除了归并算法代码实现内部可优化的细节处,使用Fork/Join框架后,我们基本上在保证操作系统线程规模的情况下,将每一个CPU内核的运算资源同时发挥了出来。
1、工作过程概要
在开篇前,首先回答一个上篇文章中的一个问题。在上篇文章给出的第一个归并算法实例中提到,归并算法的算法效率和算法稳定性都是已知的排序算法中较好的,但是如果我们只是采用单线程的应用程序来运行它,那么算法性能还是不能全部发挥出来。文章还给了一张单线程运行归并排序算法时操作系统CPU的运行状态,如下图所示:
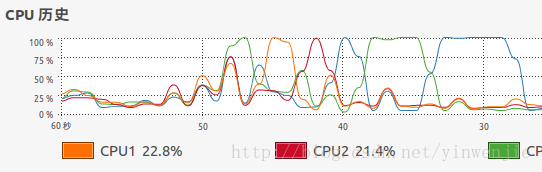
有的读者就询问,为什么单线程运行排序算法时,出现的效果是CPU1工作一段时间,然后CPU2又工作一段时间,接着其它CPU内核再分别工作一段时间的情况呢?不应该是某一个CPU内核连续工作直到运算过程完成吗?这是因为CPU计算资源完全由操作系统掌握,虽然应用程序中是一个线程在运行计算任务,且线程私有数据存储在CPU共享缓存中,而单线程任务工作时并不是一直连续占用CPU计算资源,而是会在操作系统协调下在挂起、就绪、运行状态下进行切换,而从上一次运行状态切换到下一次运行状态时,负责运行这个线程任务的CPU内核就可能会不同,所以就出现了类似上图所示的CPU切换效果。
Fork/Join Pool采用优良的设计、代码实现和硬件原子操作机制等多种思路保证其执行性能。其中包括(但不限于):计算资源共享、高性能队列、避免伪共享、工作窃取机制等。本文(以及后续文章)试图和读者一起分析JDK1.8中Fork/Join Pool的源代码实现,去理解Fork/Join Pool是怎样工作的。当然这里要说明一下,起初本人在决定阅读Fork/Join归并计算相关类的源代码时(ForkJoinPool、WorkQueue、ForkJoinTask、RecursiveTask、ForkJoinWorkerThread等),并不觉得这部分代码比起LinkedList这样的类来说有多少难度, 但其中大量使用位运算和位运算技巧,有大量Unsafe原子操作。博主能力有限,确实不能在短时间内将所有代码一一详细解读,所以也希望各位读者能帮助笔者一同完善。
2、工作要点
2-1. Fork/Join Pool实例化
实际上在之前文章中给出的Fork/Join Pool使用实例中,我们使用的new ForkJoinPool()或者new ForkJoinPool(N)这些方式来进行操作,这并不是ForkJoinPool作者Doug Lea推荐的使用方式。在ForkJoinPool主类的注释说明中,有这样一句话:
A static commonPool() is available and appropriate for most applications. The common pool is used by any ForkJoinTask that is not explicitly submitted to a specified pool.
Using the common pool normally reduces resource usage (its threads are slowly reclaimed during periods of non-use, and reinstated upon subsequent use).
以上描述大致的中文解释是:ForkJoinPools类有一个静态方法commonPool(),这个静态方法所获得的ForkJoinPools实例是由整个应用进程共享的,并且它适合绝大多数的应用系统场景。使用commonPool通常可以帮助应用程序中多种需要进行归并计算的任务共享计算资源,从而使后者发挥最大作用(ForkJoinPools中的工作线程在闲置时会被缓慢回收,并在随后需要使用时被恢复),而这种获取ForkJoinPools实例的方式,才是Doug Lea推荐的使用方式。代码如下:
......
ForkJoinPool commonPool = ForkJoinPool.commonPool();
......通过阅读ForkJoinPool的代码我们可以发现ForkJoinPool中如何完成commonPool的初始化:
static {
......
common = java.security.AccessController.doPrivileged
(new java.security.PrivilegedAction<ForkJoinPool>() {
public ForkJoinPool run() { return makeCommonPool(); }});
// report 1 even if threads disabled
int par = common.config & SMASK;
commonParallelism = par > 0 ? par : 1;
......
}
......
// 这是主要的创建过程
private static ForkJoinPool makeCommonPool() {
int parallelism = -1;
ForkJoinWorkerThreadFactory factory = null;
UncaughtExceptionHandler handler = null;
// 可以通过在java程序启动时,指定这些参数的方式
// 来完成并行等级,线程工厂,异常处理类的指定工作
try {
// 首先确认技术人员在启动应用程序时,是否指定了这些参数,来控制CommonPool的创建过程
// ignore exceptions in accessing/parsing properties
String pp =
System.getProperty("java.util.concurrent.ForkJoinPool.common.parallelism");
String fp =
System.getProperty("java.util.concurrent.ForkJoinPool.common.threadFactory");
String hp =
System.getProperty("java.util.concurrent.ForkJoinPool.common.exceptionHandler");
if (pp != null)
parallelism = Integer.parseInt(pp);
if (fp != null)
factory = ((ForkJoinWorkerThreadFactory)ClassLoader.getSystemClassLoader().loadClass(fp).newInstance());
if (hp != null)
handler = ((UncaughtExceptionHandler)ClassLoader.getSystemClassLoader().loadClass(hp).newInstance());
} catch (Exception ignore) {
}
// 没有在启动时指定以上参数也没关系,java会启动默认参数
if (factory == null) {
// 如果当前没有启动SecurityManager,安全策略管理器
// 这时使用defaultForkJoinWorkerThreadFactory这个工厂对象
// 它是java.util.concurrent.ForkJoinPool.DefaultForkJoinWorkerThreadFactory这个类的实例
if (System.getSecurityManager() == null)
factory = defaultForkJoinWorkerThreadFactory;
else
// use security-managed default
factory = new InnocuousForkJoinWorkerThreadFactory();
}
// 如果并行等级小于0,并且当前应用程序可用CPU内核数为1
// 那么设定parallelism并行等级为1
if (parallelism < 0 && // default 1 less than #cores
(parallelism = Runtime.getRuntime().availableProcessors() - 1) <= 0)
parallelism = 1;
if (parallelism > MAX_CAP)
parallelism = MAX_CAP;
// 最后使用这个构造函数初始化commonPool
return new ForkJoinPool(parallelism, factory, handler, LIFO_QUEUE, "ForkJoinPool.commonPool-worker-");
}以上代码片段中的中文注释是笔者加的,而英文注释是源代码自带的。对commonPool的初始化过程有Java security安全策略框架参与,doPrivileged方法为排除Java security安全策略框架的权限检查,而SecurityManager是Java security安全策略框架的管理器。一般情况下Java应用程序不会自动启动安全管理器,不过读者可以在Java应用程序启动时,使用-Djava.security.manager参数启动SecurityManager,或者在你的代码中通过System.setSecurityManager()方法显式设定一个。
当然,除了使用ForkJoinPool提供的commpool对象外,读者也可以直接通过ForkJoinPool提供的三种构造函数直接完成实例化,这三个可以同的构造分别是(以上构造函数的使用意义已经在之前的文章中讨论过了,这里就不再赘述了):
public ForkJoinPool() {
......
}
public ForkJoinPool(int parallelism) {
......
}
public ForkJoinPool(int parallelism, ForkJoinWorkerThreadFactory factory,
UncaughtExceptionHandler handler, boolean asyncMode) {
......
}1、概述
在之前的一篇文章《线程基础:多任务处理(13)——Fork/Join框架(解决排序问题)》中,我们使用了fork/join框架提高归并排序的性 能。那篇文章发布后,有的读者联系我,觉得单就归并排序的优化并不太能够说明fork/join框架对性能的提升,也不能说明多个典型排序算法的性能区别。所以本篇文章从单线程快速排序到多线程归并排序、再到多线程桶排序的方式,依次分析它的执行性能。
本篇文章并不侧重于算法详细过程的讲解,关于快速排序、桶排序、归并排序等排序算法的详细过程请读者参见其它专门介绍算法过程的资料,当然本文还是会讲解这些排序算法的大致过程。
2、性能分析
2-1、快速排序
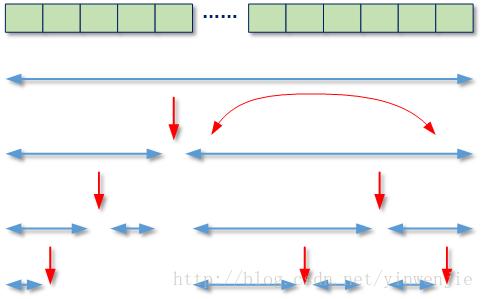
快速排序算法是冒泡排序算法的改进,是一种最基本的交换排序算法。上图中,展示了一个快速排序算法过程概要,最简要的描述是:在待排序的数组范围内,选择一个数值(通常是待排序数组的左侧第一个位置的数值)base。然后从待排序数组的两侧开始,向内侧进行搜索(分别记为索引位i和索引位j)。如果发现右侧索引位j的数值比base小,且发现左侧索引位i的数值比base大,则交换这两个索引位的数值。直到索引位i和索引位j重合(或者相交),最后将base数值交换到重合位置。最后递归进行交换后位置左侧的快速排序和交换后位置后侧的快速排序。以下是一个单线程的快速排序算法实现过程:
......
public class QuickSort {
// 测试是20个随机整数进行排序呢
// 对1亿条整型数据进行排序时,改这里就行了
private static int MAX = 20;
private static int resources[] = new int[MAX];
// 随机生成待排序的数组元素
static {
Random random = new Random();
for(int index = 0 ; index < MAX; index++) {
resources[index] = random.nextInt(MAX);
}
}
public static void main(String[] args) throws Exception {
System.out.println("开始计算===== ");
// 如果排序集合非常大,一定要把这个打印过程去掉
// System.out.println(Arrays.toString(resources));
long beginTime = System.currentTimeMillis();
QuickSort quickSort = new QuickSort();
quickSort.scan(resources , 0 , resources.length - 1);
long endTime = System.currentTimeMillis();
System.out.println("耗时=" + (endTime - beginTime) + " | ");
// 如果排序集合非常大,一定要把这个打印过程去掉
// System.out.println(Arrays.toString(resources));
// 开始检查
System.out.println("检查结果:" + SortResultCheck.scan(resources));
}
private void scan(int[] resources, int startIndexs , int endIndexs) {
/*
* 每次扫描的过程为:
* 0,确定一个base数值,这个数值是扫描数组的第一个元素
* 1、首先从endIndexs位置标记j,向左开始移动,一旦发现当前元素小于等于base,说明这个元素需要交换
* 2、然后再从startIndexs位置标记i,向右开始移动,一旦发现当前元素大于base,说明这个元素需要和之前的j位置进行交换
* 3、如果j的位置和i的位置已经相交,则按照当前j的位置和base的值交换
* 4、执行3完成后,按照交换后base的位置,分别递归排序左侧和右侧两部分
* */
if (endIndexs - startIndexs < 1) {
return;
}
// 以第startIndexs个元素为基准,进行扫描
int base = resources[startIndexs];
for (int i = startIndexs, j = endIndexs;;) {
boolean sawpBase = false;
// 1、=============================
for (;; j--) {
// 如果条件成立,说明j的位置找到一个比base小或者等于base的值
// 那么开始移动i
if (resources[j] <= base) {
break;
}
}
// 2、=============================
if (!sawpBase) {
for (;; i++) {
// 如果条件成立,说明i和j已经重合,开始移动基准数到指定位置
if (i >= j) {
sawpBase = true;
break;
}
// 如果条件成立,说明j的位置找到一个比base大的值
if (resources[i] > base) {
break;
}
}
// 3、=============================
if(i < j) {
swap(resources , i , j);
}
}
// 4、=============================
if (sawpBase) {
swap(resources , startIndexs , j);
// 开始进行递归计算,先计算左侧,再计算右侧
if(j != endIndexs) {
this.scan(resources, startIndexs, j);
this.scan(resources, j+1, endIndexs);
} else {
this.scan(resources, startIndexs, j - 1);
}
return;
}
}
}
// 该方法用于交换
private void swap(int[] arrays, int i, int j) {
int temp;
temp = arrays[i];
arrays[i] = arrays[j];
arrays[j] = temp;
}
}
......以下是一个可能的计算结果示例(你可以多运行几次,以测试算法是否正确):
开始计算=====
[105, 98, 218, 128, 141, 344, 292, 191, 329, 378, 272, 272, 125, 331, 109, 154, 296, 235, 321, 63]
耗时=0 |
[63, 98, 105, 109, 125, 128, 141, 154, 191, 218, 235, 272, 272, 292, 296, 321, 329, 331, 344, 378]另外在本文讲解的所有排序算法实例中,你都可以使用以下代码片段对排序后的结果正确性进行检查(因为数据量一旦大了,这样的方式总比用肉眼看效率高得多):
......
public class SortResultCheck {
public boolean scan(Integer[] resources) {
// 主要就是确定,下一个数字一定比上一个数字大或者相等
int len = resources.length;
for(int index = 0 ; index < len - 1 ; index++) {
if(resources[index] > resources[index + 1]) {
System.out.println("检测到错误!index = " + index);
return false;
}
}
return true;
}
}
......快速排序算法是一种不稳定的排序算法,所谓不稳定排序算法是指看似两个(或多个)相同的数值,在排序过程中是会发生变化的,且最终的相对位置顺序可能并不是它们原来的相对位置顺序。而且快速排序算法在最坏情况下的时间复杂度甚至可能会达到O(n2),所以快速排序法的应用在很多时候还停留在教材上用于向入门者讲述算法理论。但是快速排序算法也有其优点,例如快速排序算法是一种交换排序算法,它在运算时不需要更多的临时空间,所以它可以使用在一些待排序元素不多且存储空间又非常有限的场景下。下表展示了单线程情况下使用快速排序算法,对总数1亿条的整型数字集合进行排序操作所耗费的时间情况:
| 测试次数(单线程) | 所需时间(毫秒) |
|---|---|
| 1 | 13129 |
| 2 | 14407 |
| 3 | 14455 |
| 4 | 14238 |
| 5 | 13604 |
请注意运行过程并没有进行JVM优化,所以当你运行以上快速排序代码时,虽然也只有单线程在进行实际运算,但是运行过程会产生大量的GC回收运算,所以实际CPU使用情况会比较高——特别是你强行将基本类型int装箱为Integer类型时(这个现象你只需要打开jvisualvm就可以印证)。笔者相信在进行代码优化和JVM优化后,以上代码的运行性能会进一步提升,但这并不是本文的重点。
- JDK1.7+ 中使用的基本排序算法:
通过阅读Java JDK1.7+ 的官方文档和代码后你可以轻松的发现,Java中使用的主要基础排序算法是一种叫做TimSort的排序算法,TimSort算法是一种基于归并排序和插入排序的混合排序算法,并做了大量的细节优化。该算法最初由Tim Peters于2002年在Python语言中提出的,具体可参见http://svn.python.org/projects/python/trunk/Objects/listsort.txt。Java中使用的主要基础排序算法可不是什么快速排序算法。
你也可以参见java.util.Collections.sort方法、java.util.Arrays.sort方法或者其它相似的方法。
- JDK 1.7+ 中使用的排序算法,为什么比我自己写的排序过程慢?
那是因为你的测试过程写得有问题!使用java.util.Arrays.sort方法对1一亿条整型(int不是Integer)进行排序的性能时间分别是(毫秒):9525、 9803、 9529、 9836、9899。此外这只是单线程运行的情况下,如果使用后续介绍的桶排序 + TimSort的方式,那么排序操作完成的速度会更快。
2-3、归并排序——fork/join框架
归并排序算法已经在之前的文章中详细介绍过了,读者可以参见《线程基础:多任务处理(13)——Fork/Join框架(解决排序问题)》,这里我们直接列出基于fork/join pool进行多线程归并计算,对1亿个随机数进行多次排序运算后的计算性能情况:
- 使用单线程进行归并排序计算的耗时
| 测试次数 | 所需时间(毫秒) |
|---|---|
| 1 | 18812 |
| 2 | 18369 |
| 3 | 19101 |
| 4 | 18854 |
| 5 | 18710 |
- 使用fork/join pool运行归并排序计算的耗时
| 测试次数 | 所需时间(毫秒) |
|---|---|
| 1 | 14229 |
| 2 | 14665 |
| 3 | 14996 |
| 4 | 14456 |
| 5 | 15025 |
2-4、桶排序——fork/join框架
桶排序是一种针对多线程计算场景设计的排序算法,它的主要思路是先将一个无序的待排序的集合放入不同的集合(桶)中,并使用一种具体的排序算法,使用多个线程对这些桶中的元素进行排序。最后在这些桶中的元素都完成了排序后,再对这些桶进行一次遍历,最后合并成一个新的,已排序的结果集合:
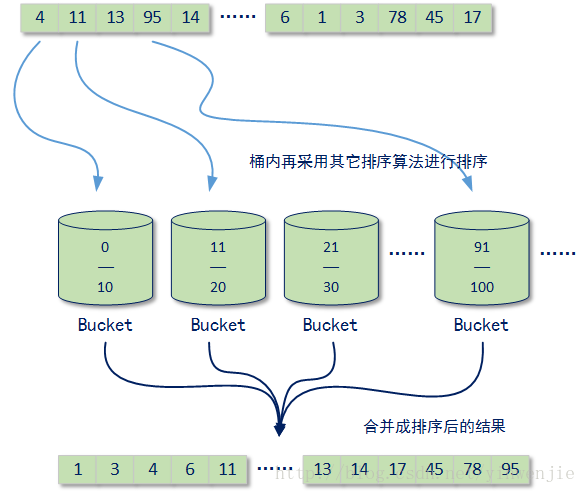
以上示意图是桶排序的基本过程。注意,每个桶都有自己承载的数值范围。例如上图所示的第一个桶,桶中的元素数值范围都在0-10(含)之间、第二个桶中的元素数值范围都在11-20(含)之间……
请看如下桶排序的代码示例:
......
public class Bucket {
private static final ForkJoinPool FORKJOIN_POOL = ForkJoinPool.commonPool();
// 单桶初始化大小
private static final int MAXINITPERBUCKET = 100000;
// 桶的数量
private static final int MAXBUCKET = 1000;
private static int resources[] = new int[MAXBUCKET *MAXINITPERBUCKET ];
static {
// 随机生成待排序的数组元素
Random random = new Random();
int len = MAXINITPERBUCKET * MAXBUCKET;
for(int index = 0 ; index < len; index++) {
resources[index] = random.nextInt(len);
}
}
public static void main(String[] args) throws Exception {
/*
* 操作步骤如下:
* 1、首先开始分桶
* 2、然后将这些桶放入fork/join pool中进行归并计算
* 3、待所有桶的排序完成后,再将这些有序集合,排列成一个新的有序集合
* */
// 1、==========
// 初始化分桶(还是单线程的)
System.out.println("开始计算===== ");
long beginTime = System.currentTimeMillis();
// 桶的大小是固定的,为了避免数组超界,在实际应用中单桶大小应设置一个合理的值
int[][] bucketArrays = new int[MAXBUCKET][MAXINITPERBUCKET *10];
// 单桶目前已存储的元素个数
int[] bucketIndexs = new int[MAXBUCKET];
int resourceLen = MAXBUCKET * MAXINITPERBUCKET;
for(int index = 0 ; index < resourceLen ; index++) {
int bucketIndex = resources[index] / MAXINITPERBUCKET;
// 放入相应的桶,并更新这个桶“已存储的元素个数”
bucketArrays[bucketIndex][bucketIndexs[bucketIndex]++] = resources[index];
}
System.out.println("完成分桶===== ");
// 2、==========
List<ForkJoinTask<int[]>> results = new ArrayList<>();
for(int index = 0 ; index < MAXBUCKET ; index++) {
int[] itemBucket = bucketArrays[index];
BucketSortTask bucketSortTask = new BucketSortTask(itemBucket , 0 , bucketIndexs[index] - 1);
ForkJoinTask<int[]> taskFeature = FORKJOIN_POOL.submit(bucketSortTask);
results.add(taskFeature);
}
// 3、==========
// 依次获得每个桶的结果就是一个有序集合了,这个步骤必须要算在时间内
System.out.println("开始最后排序===== ");
int[] resultAll = new int[MAXBUCKET * MAXINITPERBUCKET];
int destPos = 0;
for(int index = 0 ; index < MAXBUCKET ; index++) {
int[] bucketResults = results.get(index).get();
System.arraycopy(bucketResults, 0, resultAll,destPos , bucketIndexs[index]);
destPos += bucketIndexs[index];
}
long endTime = System.currentTimeMillis();
System.out.println("耗时=" + (endTime - beginTime) + " | ");
// 开始检查
System.out.println("检查结果:" + SortResultCheck.scan(resultAll));
}
// 桶排序任务,每个桶中采用快速排序法进行
static class BucketSortTask extends RecursiveTask<int[]> {
private int resources[];
private int startIndex , endIndex;
public BucketSortTask(int resources[] , int startIndex , int endIndex) {
this.resources = resources;
this.startIndex = startIndex;
this.endIndex = endIndex;
}
@Override
protected int[] compute() {
QuickSortTask quickSortTask = new QuickSortTask(resources, this.startIndex, this.endIndex );
ForkJoinTask<int[]> result = quickSortTask.fork();
// 等待这个任务
int[] resultArrays;
try {
resultArrays = result.get();
return resultArrays;
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
return null;
}
}
// 快速排序任务(子任务)
static class QuickSortTask extends RecursiveTask<int[]> {
private int resources[];
private int beginIndex;
private int endIndex;
public QuickSortTask(int resources[] , Integer beginIndex , Integer endIndex) {
this.resources = resources;
this.beginIndex = beginIndex;
this.endIndex = endIndex;
}
@Override
protected int[] compute() {
this.scan(resources, beginIndex, endIndex);
return resources;
}
private void scan(Integer[] resources, int startIndexs , int endIndexs) {
// 这部分代码请参见之前的快速排序算法代码
......
}
}
}以上代码片段中,在重要的步骤位置已经注释的比较清楚了,可以看出我们将1亿个随机数(最大值100000000)分别放入1000个桶中,然后将这1000个桶让如fork/join pool中进行并行计算。待这些桶都完成计算后,再顺序遍历这些桶,将桶中的元素合并成一个新的最终排序的结果。下表反应了桶排序 + 快速排序多次运行后的计算性能情况:
| 测试次数 | 所需时间(毫秒) |
|---|---|
| 1 | 6755 |
| 2 | 6928 |
| 3 | 6827 |
| 4 | 6890 |
| 5 | 7046 |