Python 3.5_简单上手、爬取百度图片的高清原图
利用工作之余的时间,学习Python差不多也有小一个月的时间了,路漫漫其修远兮,我依然是只菜鸟。
感觉学习新技术确实是一个痛并快乐着的过程,在此分享些心得和收获,并贴一个爬取百度图片原图的代码。
代码主要参考了xiligey老司机前辈的一篇文章,在基础上添加了一些的功能,在此谢过。http://m.blog.csdn.net/xiligey1/article/details/73321152
一、安装,搭建环境
首先是Python的安装,我想网上已经很多了,如果连安装都搞不定接下来的也不用看了,我自己用得是3.5的版本。

除此之外分享一个国外的网站,涵盖了几乎全部的python模块,运行过程中有模块缺失的可以pip或者手动在这里下载安装。
下载下来的文件后缀名改成.zip,解压出来的文件夹直接放在python安装目录下的Lib文件夹里即可。
为了让我们码代码更简单舒服,调试更轻松,推荐一个IDE:PyCharm ,界面和操作都很友好易上手,需要的自行百度安装。
二、核心代码
首先F12调试模式,查看图片的链接地址

后来实验了,发现这是小图的链接地址,咱直接pass。在网页空白处右键查看源码,根据前辈的经验,我们能找到objUrl既是我们需要的原图的地址,这下就好办了,直接正则匹配,
pattern_pic = '"objURL":"(.*?)",'而后处理翻页的问题
pattern_fanye = '<a href="(.*)" class="n">下一页</a>'
fanye_url = re.findall(pattern_fanye, html)[0] # 下一页的链接最后就可以循环保存图片了。
以下贴出代码:
- # coding=utf-8
- """
- 爬取百度图片的高清原图
- Author : MirrorMan
- Created : 2017-11-10
- """
- import re
- import sys
- import urllib
- import os
- import requests
- def get_onepage_urls(onepageurl):
- if not onepageurl:
- print('执行结束')
- return [], ''
- try:
- html = requests.get(onepageurl).text
- except Exception as e:
- print(e)
- pic_urls = []
- fanye_url = ''
- return pic_urls, fanye_url
- pic_urls = re.findall('"objURL":"(.*?)",', html, re.S)
- fanye_urls = re.findall(re.compile(r'<a href="(.*)" class="n">下一页</a>'), html, flags=0)
- fanye_url = 'http://image.baidu.com' + fanye_urls[0] if fanye_urls else ''
- return pic_urls, fanye_url
- def down_pic(pic_urls,localPath):
- if not os.path.exists(localPath): # 新建文件夹
- os.mkdir(localPath)
- """给出图片链接列表, 下载图片"""
- for i, pic_url in enumerate(pic_urls):
- try:
- pic = requests.get(pic_url, timeout=15)
- string = str(i + 1) + '.jpg'
- with open(localPath + '%d.jpg' % i, 'wb')as f:
- f.write(pic.content)
- # with open(string, 'wb') as f:
- # f.write(pic.content)
- print('成功下载第%s张图片: %s' % (str(i + 1), str(pic_url)))
- except Exception as e:
- print('下载第%s张图片时失败: %s' % (str(i + 1), str(pic_url)))
- print(e)
- continue
- if __name__ == '__main__':
- keyword = '泰勒斯威夫特1920*1080' # 关键词, 改为你想输入的词即可
- url_init_first = r'http://image.baidu.com/search/flip?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=result&fr=&sf=1&fmq=1497491098685_R&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&ctd=1497491098685%5E00_1519X735&word='
- url_init = url_init_first + urllib.parse.quote(keyword, safe='/')
- all_pic_urls = []
- onepage_urls, fanye_url = get_onepage_urls(url_init)
- all_pic_urls.extend(onepage_urls)
- fanye_count = 1 # 图片所在页数,下载完后调整这里就行
- while 1:
- onepage_urls, fanye_url = get_onepage_urls(fanye_url)
- fanye_count += 1
- print('第%s页' % fanye_count)
- if fanye_url == '' and onepage_urls == []:
- break
- all_pic_urls.extend(onepage_urls)
- down_pic(list(set(all_pic_urls)),'e:/PythonPic/泰勒%s/' % fanye_count)#保存位置也可以修改
三、其它
运行跑起来,

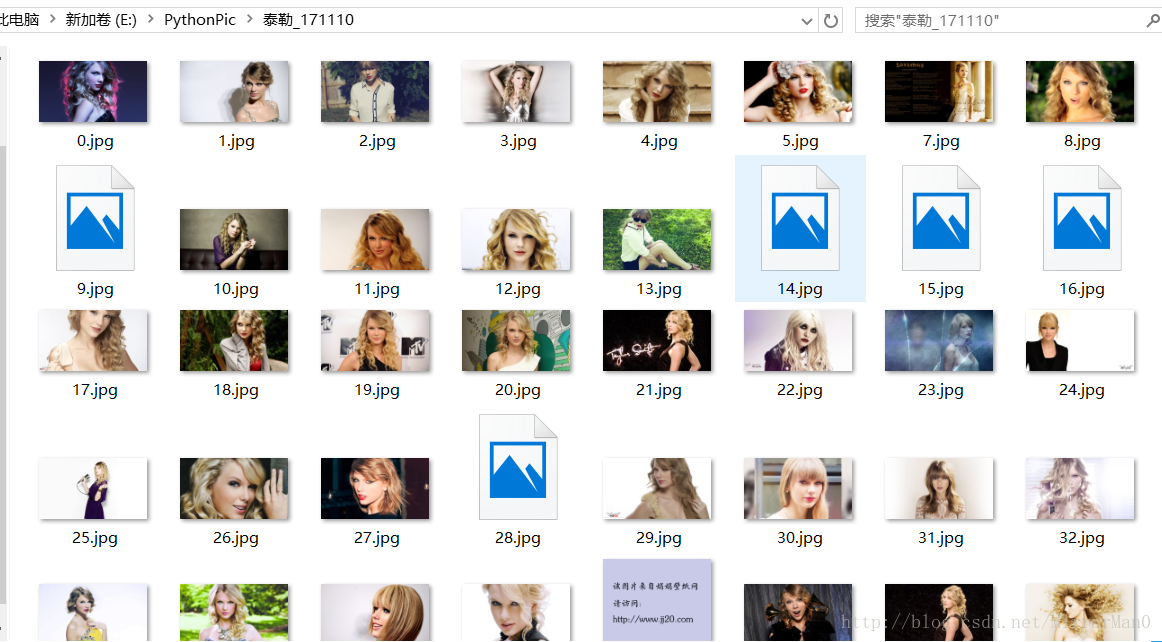
有些图片是无效的,一般就是链接失效了,也在我们的承受范围中,接下来大家就尽情享受吧
MirrorMan
2017/11/10