基于数据挖掘的高校个性化学生管理方案研究——以A高校数据集为例
马 鑫
摘 要:高校信息系统中存储着大量产生频率非常迅速且类型繁杂的数据,传统的高校学生管理模式已很难适用于我国现阶段高校学生管理。依据数据挖掘算法理论,采用k-prototypes聚类算法代替传统的人工贴标签方式,为预处理后的数据添加标签,并在此标签数据的基础之上,通过分类回归树CART对不同学生进行分类类别特征挖掘,概括不同类别学生特征,结合学生管理经验提出有针对性的学生管理建议。
关键词:数据挖掘;数据预处理;k-prototypes;数据标签;CART;个性化学生管理
中图分类号:D630.99 文献标识码:A
Research on individualized student management plan based on CART DECISION TREE:Taking a university data set as an example
Abstract: The university information system stores a large number of unstructured data with very rapid frequency. The traditional college student management model has been difficult to apply to the current student management in China. According to the data mining algorithm theory, the k-prototypes algorithm is used instead of the traditional manual labeling method to label the pre-processed data. Based on the label data, the classification and classification feature mining of different students is carried out by the classification regression tree CART. The paper further summarizes the characteristics of different categories of students, and puts forward targeted student management suggestions based on student management experience.
Key words: data mining; Data preprocessing; k-prototypes; Data tag; CART; Personalized student management
0 引 言
高校学生从入学、军训、生活到毕业等整个的活动周期,在学校的各个信息系统如图书馆管理、教务考核、学生管理、超市管理、宿舍管理、体育管理、就医管理以及学生档案管理等诸多信息系统中都会存储下各种结构的历史数据。然而,传统的信息系统不论是在施行效率还是数据应用等多方面已不能满足当代学生管理的要求。发掘高校数据中的潜在价值,找到学生举动之间的内在联系,思索这些举动背后的逻辑关系,做出适当的管理决策,实现对高校学生个性化的管理显得尤为迫切。
本文将数据挖掘算法应用于高校学生管理系统,充分利用数据挖掘相关技术,从已知信息系统中存储的与学生有关的大量历史数据着手,挖掘数据当中潜在的有用信息,进而对学生进行分类,总结同一类别不同对象之间的共同特征,根据学生同一类别的共有特征针对性的制定个性化的学生管理方案,实现以人为本的差异化管理模式,辅助确立及时、周全的教学管理体系。以期望提高高校学生管理工作精细化水平,促进高校管理工作的科学性,为高校教务工作舔砖加瓦。
1 数据预处理
数据预处理欲解决的问题是将未进行任何加工的数据转换成适合进行分析的形式,通常耗费大量的时间和精力,且需要人为经验的干预,是数据挖掘过程当中十分重要的一步[1]。在进行数据挖掘之前,需要对原始数据进行抽取、简化、清洗和转换等操作,提高数据挖掘结果的准确度。
1.1 数据抽取
数据抽取是指从原始数据中目标数据源体系必要的数据。现实当中,数据抽取主要是从关系型数据库中抽取,包括:增量抽取和全量抽取两种方式。本文为尽可能保留原始数据,采用增量抽取的方式进行抽取,将A校信息系统中的数据原封不动的抽取出来,最大限度的保留数据的“原貌”。
1.2 数据简化
本文研究的主要目的是对学生进行分类管理,对于student_guardian(监护人)、schoolsup(学校中额外的教育支出)、famsup(家庭中额外的教育支出)、paid(课程内的额外付费课程)、nursery(是否就读过托儿所)、romantic(是否恋爱)、famrel(家庭关系质量)、freetime(课后空闲时间)、Dalc(上课期间饮酒)、Walc(周末饮酒)等与目的无关或者主观性较大对挖掘结果造成影响的属性进行删除操作。
1.3 数据清洗
|
|||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||
|
数据清洗的目标是为之后的数据挖掘提供完备有用正确的数据,提高数据挖掘的效率[2]。相反,数据清洗不完善,结果也会存在诸多误差。本文所用数据为数据库中导出数据,此中存在少量的缺失数据、错误的数据和重复数据。
缺失型数据主要集中在travel_time(空闲时间)、medu(母亲学历水平)以及fedu(父亲学历水平)等属性值。本文采用插补法方式对缺失值进行处理,medu等定距类型数据通过计算均值进行插补,travel_time等非定距类型数据通过统计频数进行插补[3]。例如:medu的取值类型有四种1、2、3、4,缺失值则为该属性存在值的平均值2.5;travel_time当中通过统计发现空闲时间为1小时的频率最高,则空缺位置的值填补为1。而重复型数据和同一属性取值形式不同的错误型数据,本文的处理方式是通过SQL语句在数据库中进行相应处理。
1.4 数据转换
构造和添加index(对象编号)和G3(G1和G2两学期的平均成绩)两个新的属性,以使得数据更易于进行数据挖掘,提高挖掘精度和高纬数据结构的理解[4]。
2 数据标签的张贴
传统的数据标签张贴方式主要有自贴标签、专家贴标签和“羊毛出在猪身上(借助某种客户端通过用户来实现)”等方式。然而,这些方式不但费时费力,而且在应用场景中也有诸多限制,例如:“羊毛出在猪身上”这种标签张贴方式,不仅要求具备一个相应的客户端,同时该客户端需要具备一定基数的用户[5]。
而本文则采用聚类的方式为每一个数据对象贴标签。比较常见的聚类分析算法所对应的数据类型主要包括数值数据、分类数据和混合型数据。k-prototypes算法综合了k-means算法和k-modes算法优点,采用一种崭新的距离计算公式,能够快速的处理混合数据集的聚类分析问题[6]。类似于k-means算法当中的误差平方和(SSE),k-prototypes算法设定了一个最优函数,簇中心不断进行迭代,直到目标函数值不发生变化。目标函数为:
E=l=1ki=1nuildxi,Ql (1)
上式中uil可理解为第i个对象分类属性的权重,Ql可理解为当前迭代中的簇中心,xi为样本中对象,n表示样本中对象的个数,j表示对象的维数。
2.1 算法设计
设X=X1,X2,X3,…,Xn表示学生表现数据集中n个学生对象(n=1, 2, 3, …, 395),在这其中Xi表示一个具有属性A1,A2,A3,…,Am的学生数据对象(m=1,2,3,…,23)。对于数值型属性值,采用连续型的值进行表示,分类型的属性值采用有限且无任何顺序的值的集合进行表示,即使用DomAj=aj1,aj2,…,ajt对分类属性取值进行表示,其中t为Aj的可能取值的个数。综上所述Xi可表示为常见的向量的形式[xi1,xi2,…,xim]。
设k为一个正整数,表示k-prototypes算法需要将源数据集X聚类为k个簇,也即选择k个初始聚类中心。该聚类算法的聚类准则为最小化目标函数:
EY,Q=l=1ki=1nyildxi,Ql (2)
上式中dXi,Ql为差异度,其可定义如下:
dXi,Ql=j=1mdxij,qlj (3)
其中dxij,qlj的取值又可分为:
dxij,qlj=xijr-qljr2 ,m=rγlδxijc,qljc , m=c (4)
上式当中xijr和qljr为数值属性,xijc和qljc为分类属性,r和c分别为数值变量和分类变量的个数。同时,通过计算可以发现,当xijc=qljc时,δxijc,qljc的值为0,反之则δxijc,qljc为1;其中需要重点说明的是γl为混合数据类型当中分类属性的权重,分类属性相对重要,权重值则大;分类属性相比于输指数型不是那么重要,权重则小。当xij为数值属性时,qlj代表的是第l个簇中第j个属性的均值;当xij是分类属性时,qlj代表的是第l个簇中第j个属性的对应模式。
2.2 k值的选择
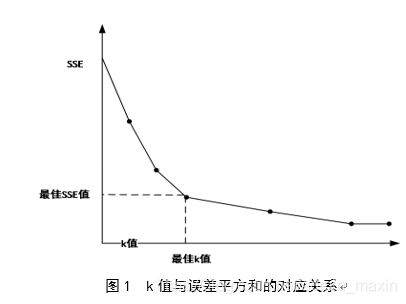
聚类结果在很大程度上取决于k值的选择,k值过大或过小都会对聚类结果产生巨大的影响。本文采取手肘法确定k的取值。该方法的核心思想是随着初始聚类书k的输入不断增大,样本数据的分类精细度会不断提高,也即簇的聚类程度不断提高,SSE逐渐减小。而且,当k小于样本数据真实的聚类数时,随着k数值的增长会大幅度的增加各个簇的聚合程度,SSE降低的幅度增大;当k在样本真实的聚类数周边浮动时,随着k的增加,聚合程度的回报会锐减,后随着k值输入的增大曲线逐渐变得平缓。
因而,SSE和k的干系图为手肘状的外形,手肘状的顶点对应的k值则为学生数据对应的真实聚类数。手肘法的主要判断依据是SSE(误差平方和):
SSE=i=1kp∈cip-mi2 (5)
上式中,ci表示第i个簇,p为簇ci中的样本,mi是ci的质心(ci中整个样本的均值),SSE也可代表全部样本的聚类偏差,代表了聚类结果的好坏。
mi=1nij=1nipj (6)
此中ni表示第i个簇中样本的个数,pj表示第i个簇中样本对象的个数。在某个簇ci质心的计算过程中,数值型数据直接求均值,分类型数据则通过频数的方式确定质心对应属性的属性值;分型属性做差时,属性值相同为0,不同为1。
2.3 聚类结果展示
通过循环递增设置k值,为每一个聚类结果计算一个误差平方和SSE,通过比较发现当k=6时聚类结果的反馈程度最高,也即k=6为聚类最佳k值。k-prototypes算法的最终聚类结果如图2,该算法将本科生数据样本分为6个簇,每个簇对应的比例分别为22.8%,22.5%,15.7%,14.4%,13.7%,10.9%,最小与最大簇之间的比值为2.09。

3 基于CART的分类特征挖掘
单从聚类结果的可视化数据当中很难找到某些确切的描述同一类别不同学生对象的共有特征,因此本文采用分类回归树CART决策树对其进行特征挖掘,选择决策树构建较为重要的前几个特征对不同学生类别进行描述,进而提出个性化的学生管理方案。
3.1 分类尺度确定
在决策树当中有一个重要性程度非常高的问题,那就是如何选择原始数据集当中哪一个特征在划分数据分类时起到相对重要的作用,即“树”在“分叉”时应该参照什么属性进行“分叉”。本文采用CART(分类及回归树),该算法选取划分数据的特征时不同于传统的ID3以及C4.5等决策树算法采取信息熵来划分数据集,至于如何分割,则由目的变量的类型决定。假设是分类变量,Gini或Twoing任意选择,若为连续变量(数值),则自动确定方差来选择分割点[7]。本文分类变量选用Gini系数确定分类尺度。
Gini系数[8]计算公式如下:
Gt=1-t1T2-t2T2-…-tnT2 (7)
上式中,t1,t2,…,tn代表每个类别的记录数,T为总记录数,本文数据中即样本总量(理论上来说)。在CART算法当中,采用Gini系数的减少量来确定当前节点的分裂标准:
∆Gt=Gt-n1N*Gt1-n2N*Gt2 (8)
其中,n1为左子树的记录数,n2为右子树的记录数,N=n1+n2。另外,由于CART算法仅能建立二叉树,则对于分类多与两种的类别,首先需要先将多于的类别值合并为两个,进而形成超类,然后计算∆Gt。以上的Gini系数是针对分类型变量,而针对连续型变量,必须首先将连续型变量升序排列,分别以相邻两个数值型数据的中心值作为分支尺度,分别计算左右子树的∆Gt。
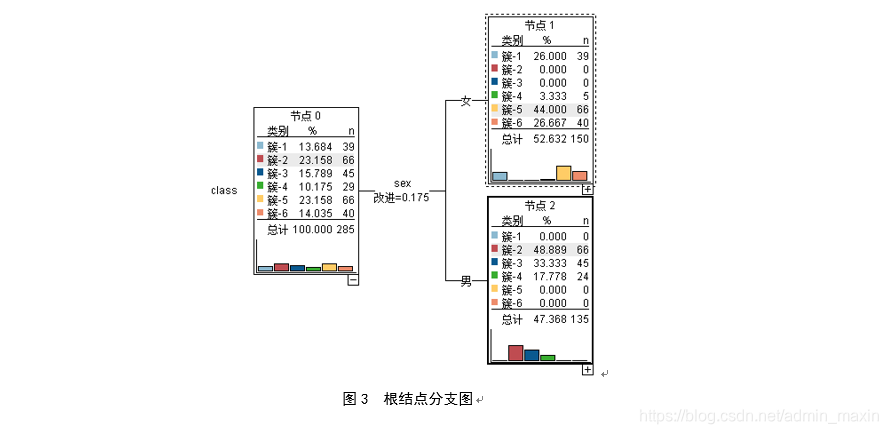
以根结点的划分为例:第一步,计算全部数据的差异度Gt=1-392852-…-402852=0.819034,Gt1=0.666578,Gt2=0.618272;第二步,计算根结点以特征sex(男or女)划分后的∆Gt,∆Gt=0.8190-150/(285*0.6667)-135/(285*0.6183)≈0.175;第三步,遍历数据集所有属性及其对应的属性值,计算出一系的∆Gt,最大的∆Gt对应的属性和属性值则为最佳分割点。
3.2 分类特征挖掘
通过最终的决策树可视化结果分析,sex(学生性别)、activities(是否参加活动)、choose_reason(择校原因)、medu(母亲受教育程度)四个属性能够更加迅速的构建决策树,且对决策树的影响程度依次下降。需要特别指出的是,图4中的“改进=0.175”指的是最佳分割点所对应的∆Gt。

4 特征描述与管理方案研究
4.1 “天才型”学生
针对簇2,本文称之为天才型学生。此类学生一般为男生、喜欢参加课外各种活动、择校原因多为学校名气、父母受教育程度高且多为大学及以上学历、城镇户口、宿舍中有上网设备以及成绩优秀等共同特征。针对此类学生,本文给出以下管理建议:
(1)善于引导
老师或者学校教学管理人员可为此类同学提供一些帮扶平台,让其能帮扶其他同学,这样既可以给这类学生自信,又能给他们提供一份责任,传播自己的各方面的成功经验。
(2)懂得宽容
此类学生由于各方面能力出众,父母疼爱,在自主能力和辨别能力上会有所欠缺,作为老师或学校教学管理人员应多一些宽容,培养这类学生自主安排学习和各方面实物的能力,毕竟知错能改善莫大焉。
(3)培养宽松的师生关系
在这类学生的管理过程中,不管是老师还是其他的教学管理人员,都应该提升自己的创造力、想象力和创新性,在学生心目当中树立亦师亦友的个人形象。
4.2 “自我否定型”学生
针对簇4,本文称之为“自我否定型”学生。此类学生大多数为平时不爱参加课外活动、选择某个学校看中的则是课程情况、父母受教育程度低、农村户口、家庭条件较差、宿舍无上网设备、成绩极差的男生(占比84%)。此类学生受到家庭对于教育观念的曲解,其对学习有一种抵触情绪,年龄相对于同一级的学生来说偏大,生活相对拮据;对外界缺乏一些了解的渠道(互联网),过分的贬低自身的能力,是老师的“眼中钉,肉中刺”。针对这一类学生,本文给出以下管理建议:
(1)真诚的关心
这一类学生由于从小受到生活条件和家庭观念等的约束,不能正确的认识自己的能力,过分的自卑,从小接触的教学资源不足,学习能力较低,作为老师和教学管理人员应当为他们提供一个展示风采的平台,引导其树立起强大的自信心,帮助其逐渐建立起对学习的兴趣。
(2)善于发现闪光点,并实时的给与赞赏[9]
逐渐的改变其对学习的认识,充当其与外界联系的“媒介”。
4.3 “理工型”学生
针对簇3,本文称之为“理工型”学生。此类学生,一般为平时不爱参加活动、择校主要是听从家人的安排、父母受教育程度高、城镇户口、宿舍有固定上网设备且成绩较为优秀的男生。这个群体的学生被认为是“宅而木讷”但智商超高的一群人,喜欢挑战电脑游戏,狂热于电子产品,缺少人际交往的一些必备常识(不愿参加一些课外活动)。通过与“天才型”学生对比发现,该类学生课下花在学习上的时间更少,但成绩却出乎预料的好,微低于“天才型”学生。针对这一类学生,本文给出以下管理建议:
(1)学习之余多体贴学生生活
此类学生虽然智商超高,但是生活不休边幅,呆板无趣,影响他们的不是学习有多困难,而是怎样与他人沟通交流。作为老师或学校的管理人员应多关心他们的生活,帮助其树立正确的价值观,处理好电子游戏与学习之间的关系,防止该类型学生向更加糟糕的情况转化,因为高校中因为游戏而引发的留级和辍学时间屡见不鲜。
(2)激励引导其多与外界接触
几天甚至几周都不出宿舍不下床的高校学生大有人在,这不仅不利于学生自身的健康,人际关系的营造,也不利于学生的学习和自我提高。因而,老师和学校的相干管理人员都应当展开一些有利于学生之间彼此沟通和交流的活动,丰富该类学生的空闲生活,转变其“电脑,宿舍,游戏足以!”的思想观念,全身心的投入到学习生活当中。
4.4 “勤奋自觉型”学生
针对簇1,本文称之为“勤奋自觉型”学生。此类学生多为平时不愿参加活动、择校主要是冲着学校课程安排、父母学历较高、城镇户口、宿舍有固定上网设备、成绩较低的女生。此类学生家庭条件良好,虽就智商来说可能不及“理工型”或“天才型”学生,但是却认真刻苦,懂得“知识改变命运”的思想,能自觉维护上课纪律,在课堂上能与老师进行良性交流,能充分利用课下时间进行学习,懂得劳逸结合,日复一日的匆匆穿梭于宿舍和教室之间。针对这一类学生,本文给出以下建议:
(1)在该类学生当中树立一种勤奋上进的形象
这一类学生由于勤奋上进,大把时间用来学习,以至于在一部分学生眼中她们是另类。这个时候老师和学校的相关管理人员应以身作则,勤奋是一种优秀的品质,树立起身边的榜样。
(2)及时解答学习上的困惑
该类学生勤奋好学,能够合理的安排自己的学生和生活,日常生活当中学习是其“主战场”,而最令其头疼的问题则是“这个地方实在是想不出来”“这种问题我应该怎么考虑”“我应该从什么角度入手”“从哪里开始学习”等问题,这个时候学校相关管理人员或老师则应及时的为其解答疑难困惑,不定期开展一些学习经验交流会,为其分享相关的学习经验。
4.5 “学习方法欠佳型”学生
针对簇5,本文称之为“学习方法欠佳型”学生。这一类学生多为空余时间积极参加课外活动、择校主要考虑的是学校名气、父母学历较高、城镇户口且家庭条件良好的女生(单亲家庭占比6.7%)。此类学生学习认真刻苦,有非常高的学习欲望,积极参加各类活动,渴望成为全能型学生,但成绩总不理想,变化波动较大。针对这一类学生本文给出如下建议:
(1)授人以渔
这一类学生学习态度端正,对知识的渴求之高常人无法想象,但学习方法欠佳。老师或学校教学管理人员可充分发挥“天才型”学生的作用,开展一对一帮扶,逐渐的帮助这一类学生找到正确的学习方法。
(2)努力没有错,错在方法
这一类学生花费在学习上的时间非常多,但效果几乎为0,因此其开始怀疑自己的能力,怀疑自己是不是比别人笨,更严重的甚至有开始厌学的倾向,情况之严重应当引起足够的重视。作为老师,可以多体贴这类学生,辅助他们找到合适自身的学习方法;作为学校教学管理人员,可以开展一些心理讲座之类的活动,帮助有认识问题的学生走出误区。
4.6 “偏执型”学生
针对簇6,本文称之为“偏执型”学生。这一类学生多为平时不愿参加活动、择校主要听从家人安排、父母双方学历较高、城镇户口、宿舍有固定上网设备、成绩良好且家庭条件优越的女生(单亲家庭占比20.4%)。此类学生及其富有主见,不爱学习,认为学习无用,经常旷课,一有空闲时间就用来“丰富自我”,经常去图书馆看一些小说之类的书籍,追剧等。她们高度自信,认为学习无用不如通过其他方式提高自己。这一类学生主要受教育功利性观点的影响,认为教育的投入与产出不对等,觉得就算大学毕业也不好就业,就算就业了工资也不高,所以他们认为学习无用。这部分本科生的学习目的非常的肤浅,学习完全是被动的,其学习方式以应付为主,普遍认为无所谓,学习效率低下。针对这一类学生,本文提出以下建议:
(1)施压
对学生不作为的举动直接进行点名指责,或公开做反省。
(2)逼迫其直面人生
作为老师,课堂上可以偶尔分享一些长期抱有学习无用态度且多年后一事无成得不到别人尊重的人的反例;作为学校教学管理人员,则可对这一类学生进行抽查点名,定期通报等方式,催促他们学习。
(3)规划人生。
这个工作完全可以通过学校开设的相关课程进行讲解,比如《大学生生涯规划》等课程。
5 总结
将数据挖掘引入高校信息系统是现阶段高校学生管理的发展趋势[10-12]。本文从高校教务管理信息系统中的历史数据出发,在预处理数据的基础之上,采用手肘法确定聚类最佳k值,进而通过聚类算法k-prototypes算法替换传统的标签张贴方式为每一数据对象添加标签(省时省力,且准确性高);并应用分类回归树CART算法挖掘不同标签之间的特有特征,对同一标签中不同对象之间的共有特征做出精确描述,进而针对每一标签提出针对性的个性化管理建议。
本文通过挖掘高校信息系统中的数据,将数据转化为知识,可以促进高校学生管理工作的提升,在构建符合现代高校学生教务管理新模式,全面提升学生培养质量方面具有一定的参考价值。
[参考文献]
[1]黄航辉. 互联网访问数据预处理研究与应用[D].东华大学,2014.
[2]董潇潇,胡延,陈彦萍. 基于校园数据的大学生行为画像研究与分析[J]. 计算机与数字工程,2018,46(06):1200-1204+1262.
[3]杨帆,庞新生. 处理缺失数据的分数插补法研究[J]. 统计与决策,2017(14):15-18.
[4]冯柳伟. 基于近邻的聚类算法研究[D].北京交通大学,2018.
[5]Ti S U, Yang M, Wang C X, et al. Classification and Regression Tree Based Traffic Merging for Method Self-driving Vehicles[J]. Acta Automatica Sinica, 2018.
[6]徐健. 基于改进型K-prototypes算法的云服务推荐研究[D].合肥工业大学,2017.
[7]李亚芳. K-means型社区发现方法研究[D].北京交通大学,2017.
[8]Ti S U, Yang M, Wang C X, et al. Classification and Regression Tree Based Traffic Merging for Method Self-driving Vehicles[J]. Acta Automatica Sinica, 2018.
[9]谭凯茵. 教育要滋润学生的心田[J]. 读与写(教育教学刊),2018,15(05):177.
[10]葛璐瑶.改进的决策树ID3算法及应用[J/OL]. 电子技术与软件工程,2018(13):153-154[2018-07-23].http://kns.cnki.net/kcms/detail/10.1108.TP.20180710.0913.212.html.
[11] Choubin B, Zehtabian G, Azareh A, et al. Precipitation forecasting using classification and regression trees (CART) model: a comparative study of different approaches[J]. Environmental Earth Sciences, 2018, 77(8):314.
[12]柯玲. 高校教务管理信息化和科学化建设的思考[J]. 信息技术与信息化,2018(Z1):171-173.