目录
Abstract
广播模式在云计算和数据中心设置中很常见。 Spark等应用程序和基础架构工具经常移动大型对象,更新复制文件到多个节点,或者将新版本的程序推送到计算节点。 某些应用程序直接使用复制,例如,以提高容错性或实现并行性。 为了实现Paxos、区块链和其他库通常使用手工构建的可靠广播为单元。然而,操作系统仍然专注于TCP等点对点通信解决方案。 我们的系统RDMC(RDMA Multicast)提供从RDMA单播构建的可靠多播功能。 我们讨论了设计选择,提出了RDMC对延迟和慢速网络链路的鲁棒性的理论分析,并报告了评估RDMC对Mellanox RDMA的实验。
1.Introduction
数据中心负载主要由数据复制延迟造成,通常是从源节点到两个或更多目的地。 到2011年,像Cosmos(微软),GFS(谷歌)和HDFS(Hadoop)这样的分布式文件系统每天处理许多PB的写入(数百Gb / s)[6],而今天的吞吐量肯定要高得多。 许多文件被复制到多个存储服务器[8]。 此过程的延迟决定了最终用户应用程序的整体写入性能。 在Facebook中,Hadoop Trace显示,对于MapReduce的作业Job,Reduce阶段之间的数据传输占总运行时间的33%[4]。 谷歌的Borg的任务启动延迟中位数约为25秒(大约80%专门用于软件包安装),在某些Cell中每分钟开始执行的任务超过10,000个[22]。 在某些情况下,复制VM映像和输入文件比计算需要更多的时间[19]。
尽管快速复制很重要,但缺乏有效的通用解决方案。 如今,云中间件系统通常会以一次制作一个副本的方式将新数据推送到节点上去。 内容共享通常通过中间缓存或一个key-value层来处理,这可以很好地扩展,但会引入额外的延迟和复制。 在像Hadoop这样的并行平台中,调度程序通常可以预期一组任务将读取同一文件,但除非数据恰好在本地缓存,否则它将在每个任务打开并访问该文件时进行点对点移动。 通过将这种交互识别为共同模式的实例,云系统可以显着提高效率。 这样做可以恢复当前因无关传输和不需要的复制而丢失的网络带宽和CPU时间。 对于时间关键的用途,这样的原语会减少陈旧性。
我们的RDMA多播协议RDMC解决了这个问题,提供了更高的速度和更低的资源利用率。 RDMC实例化成本低廉,并提供类似于N个并排TCP链路的可靠性语义,每个接收器一个。 该协议对于中断也很稳健并且提供了公平的带宽划分,因为我们使用实验证明RDMC暴露于调度延迟,链路拥塞和重叠交付模式。
RDMC还可以扩展以提供更强大的语义。在其他地方报道的工作中,我们描述了Derecho [9]:一个新的开源软件库,分布在RDMC上,支持原子组播以及经典的持久Paxos。 为了获得这些属性,Derecho引入了一个小延迟,在此期间接收者缓冲消息和交换状态信息。 当已知RDMC消息已到达所有目的地时,这时候数据发送完成。 不会出现带宽损失,增加的延迟非常小。
本文件的贡献如下:
•我们详细描述了RDMC,展示了如何将广播传输映射到RDMA单播操作的有效模式。
•我们对系统进行了广泛的评估。
•我们表明RDMC对调度和网络延迟具有鲁棒性,并讨论了在极少发生传输失败的情况下恢复的选项。
•我们认为,由于RDMC生成确定性块传输模式,因此它为将可靠多播直接卸载到NIC上提供了一个垫脚石。
2. Background On RDMA
RDMA(远程直接存储器访问)是零拷贝通信标准。 它已在Infiniband上使用多年,但现在也在标准数据中心以太网上运行稳健。
RDMA是一种用户空间网络解决方案,可通过queue pair访问:这是一种无锁的数据结构共享user code 和 网络控制器(NIC),包括发送队列和接收队列。 RDMA支持多种操作模式。 RDMC。 RDMC使用可靠的双边RDMA操作,其行为与TCP类似。使用此模式,发送方和接收方将其各自的队列对绑定在一起,从而创建由NIC端点完全实现的会话。通过将Memory Region发布到发送队列来发出发送,并且进程通过将Memory Region发布到接收队列来指示其准备接收。然后,发送方NIC将传输数据,等待硬件级别的确认。在指定的超时后,NIC重试;在指定次数的重试之后,它会中断连接并报告失败(如下所述,除非接收器准备就绪,否则RDMC不会开始发送,因此连接断开表示网络或端点出现故障)。一旦发送了发送和匹配的接收,数据将直接从发送方的内存复制到接收方的指定位置,并且可以硬件和硬件支持的全速率复制。RDMA 通过一个完成队列报告结果。不需要端到端软件重发或确认:硬件提供正确的数据(按FIFO顺序)并报告成功或连接中断。
如果进程P和Q希望建立双向RDMA连接,则它们必须首先交换密钥形式(RDMA缺少相当于TCP侦听操作,并且没有硬件层3次握手)。 RDMC可以支持多个重叠sessions,并且可以根据需要创建它们,因此可以在没有警告的情况下生成交换密钥。 为了最大限度地减少延迟,RDMC创建了一整套N * N TCP连接设置和故障报告,如下所述。
RDMA提供了几种附加模式:one-side RDMA READ和WRITE(Q授权P直接访问某些存储区域),数据内联,不可靠的点对点数据报和不可靠的组播。 这些功能适用于小型传输,并且由于RDMC专注于大型传输,我们没有发现它们有用,但有一个例外:当每个接受者准备接受传入传输时,它会进行单向写入以告知发送方 ,只有在准备完毕后才开始发送。
RDMA NIC可编程性的演变。人们对可编程网络设备越来越感兴趣。 对于RDMA NIC,这可能会引入新的请求排序选项。
现如今的RDMA网卡保证两种方式:(1)在单个发送或接收队列中排队的请求将按FIFO顺序执行(2)只有在传入传输完成后才会发生接收完成。 Mellanox的CORE-Direct [14]功能提出了第三种请求排序形式:可以将RDMA发送入队,该RDMA发送将等待先前请求完成,以及完成其他一些RDMA发送或接收, 甚至可能在不同的队列对上。 在节点Q需要将从P接收的数据重新存储到另一个节点R的情况下,这避免了Q处的软件延迟在接收完成之后发出中继操作。 我们相信CORE-Direct只是最终广泛的新RDMA NIC可编程功能之一。
RDMC旨在预测这一趋势,尽管硬件功能尚未完全成熟,因此对潜力的严格评估将需要额外的工作。 RDMC可以预先计算数据流图,描述每个广播发送开始时的完整数据移动模式。 因此,复制组的成员可以在传输开始时发布数据流图,并通过跨节点发送/接收依赖关联。 然后硬件将在没有进一步帮助的情况下执行整个传输。 卸载将消除对任何软件操作的需要,但会产生一个有趣的调度难题:如果操作一旦可能就执行,则可能出现优先级反转,从而将紧急操作延迟一个实际上具有大量调度松弛的操作。 随着这些新硬件功能的成熟,我们希望能够探索这些问题。
3. High level RDMC summary
我们使用上述双边RDMA操作实现了RDMC。 基本要求是创建RDMA广播模式,以有效地执行所需的广播。 在下面的讨论中,术语消息指的是传输的整个最终用户对象:它可能是几百兆字节甚至几千兆字节。 小消息作为单个块发送,而大消息作为一系列块发送:这允许中继模式,其中接收器同时用作发送器。 中继的好处是它允许充分利用接收器NIC的传入和传出带宽。 相比之下,使用单个大型广播传输发送对象的协议是有限的:任何给定节点一次只能在一个方向上使用其NIC。
这产生了一个框架,其操作如下:
- 对于每个RDMC传输,发送方和接收方首先创建多路绑定的覆盖网格:RDMC Group。 这种情况发生在带外,使用TCP作为引导捆绑协议。 RDMC是轻量级的,可以支持大量重叠组,但为了最大限度地减少引导延迟,执行重复传输的应用程序应该在可行时重用组。
- 每次传输都是作为一系列可靠的单播RDMA传输进行的,没有重传。 RDMC在开始时计算发送和接收的序列,并将它们排队以尽可能异步地运行。 如前所述,最终将整个序列卸载到可编程NIC是可行的。
- 在接收端,RDMC通知用户应用程序传入消息,并且它必须发布一个接收字节的正确大小的缓冲区
- 在发送方按发送顺序发送完成。 传入的消息保证不会被破坏,并且按照发送者的顺序到达,不会被破坏。
- 如果一个NIC中有多个活动传输,则RDMA会公平地分配带宽。 RDMC扩展了这一属性,为重叠Group提供了公平性。
- 如果RDMA连接失败,则非崩溃的端点将从其NIC中了解该事件。 RDMC转发这些通知,以便所有幸存者最终了解该事件。 然后,应用程序可以通过关闭旧的RDMC会话并启动新的RDMC会话来进行自我修复。

4. System Design
4.1 External API
图1显示了RDMC接口,省略了块大小等配置参数。 发送和销毁组功能是不言自明的。 所有组成员同时调用create_group 函数(具有相同的成员信息); 我们使用前面提到的带外TCP连接来启动此步骤。 create group有两个回调函数,用于通知应用程序事件。 当新的传输开始时,接收者触发incoming消息回调,并且还用于获取将消息写入的Memory Region。 由于内存注册成本很高,因此我们会在启动之前,在任何通信活动发生之前执行此步骤。
一旦消息发送/接收在本地完成并且可以重用相关的Memory Region,则触发消息完成回调。请注意,这可能发生在其他接受者完成消息之前,或者甚至在其他接收器发生故障之后。
在Group内,只允许一个节点(“root”)发送数据。 但是,应用程序可以自由创建具有相同成员资格但不同发件人的多个Group。 请注意,Group Member身份在创建后是静态的:要更改Group的成员身份或root,应用程序应销毁该组并创建一个新组。
4.2 Architectural Details
RDMC作为用户空间库运行。 图2显示了其体系结构的概述。
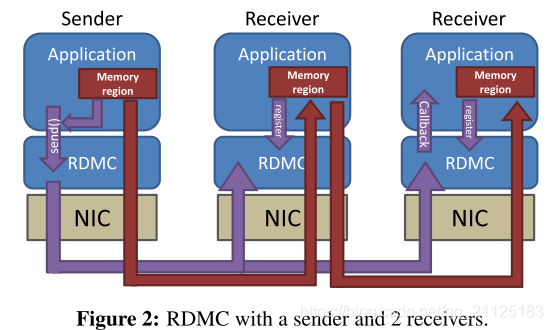
Initialization. 当应用程序首次启动时,其成员必须初始化RDMC。 此时,RDMC创建前面提到的TCP连接网格,注册内存,创建单个RDMA完成队列,并准备其他内部数据结构。 稍后,在运行时,所有RDMC会话共享一个完成队列和线程,从而减少开销。 为避免在没有I / O发生时轮询,完成线程在每次完成事件后轮询50 ms,然后切换到中断驱动的完成模式。 它会在下一个事件中切换回轮询。
Data Transfer. 虽然我们将主要关注二项式流水线算法,但RDMC实际上实现了几种数据传输算法,这使得可以进行直接的并排比较。 要在RDMC中使用,发送算法必须保留发送顺序,将消息发送映射到块传输的确定序列。
当发送方发起传输时,我们的第一步是告诉接收方传入消息的大小,因为任何一个RDMC组都可以传输各种大小的消息。 在这里,我们利用RDMA功能,允许数据包携带整数“immediate”值。 消息中的每个块都将以立即值发送,指示其所属消息的总大小。 因此,当建立RDMC Group时,接受者发出一个receive请求用于初始化已知block块的大小。 当此块到达时,immediate Vaule允许我们确定完整的传输大小,并且(如果需要)为整个消息分配空间。 如果将发送更多块,接受者可以根据需要发布其他异步Receive 请求,并行地将第一个块复制到接收区域的开头。 然后,在传输结束时,为下一条消息的第一个块发布新的Receive 请求。
发送方和每个接收方将调度视为一系列异步步骤。 在每个步骤中,每个参与者要么空闲,要么做一些发送块和接收块的组合。 最有效的计划是双向的:它们最大化节点发送一个块的程度,同时接收一些其他块。 给定异步步骤编号,可以精确地确定这些块将是哪些块。 因此,当每个接收器为下一个块发布内存时,它可以精确地确定将到达哪个块并选择正确的偏移到接收Memory Region中。 类似地,在每个步骤中,发送者知道接下来要发送哪个块以及向谁发送。 我们的设计通常避免任何形式的带外信令或其他协议消息,但有一个例外:为了防止块过早发送,每个节点将等待从目标接收准备好的块消息,以便它知道目标准备就绪。 通过确保发送方永远不会启动,直到接收方准备就绪,我们避免了代价高昂的退避/重传延迟,并消除了连接可能因为某个接收方有一个调度延迟并且没有及时发布内存而导致断开的风险。 我们还大幅减少任何一个广播所使用的NIC资源量:如果并发活动的接收缓冲区数超过NIC缓存容量,则今天的NIC表现出性能下降。 RDMC每组只有一些少数的receiveers,并且由于我们预计不会有大量并发活跃Group,因此避免了这种形式的资源耗尽。
4.3 Protocol
鉴于这种高级设计,最明显和最重要的问题是用于从一系列点对点单播构建多播的算法。 RDMC实现多种算法; 我们将按照提高效率的顺序对它们进行描述。
Sequential Send. 顺序模式在今天的数据中心很常见,对于小消息来说是一个很好的选择。 它实现了从发送者一个接一个地将整个消息传递给每个接收者的简单解决方案。 由于单个RDMA传输的带宽几乎是线速,因此该模式实际上与同时运行N个独立的点对点传输相同。
请注意,对于顺序发送,在创建B位消息的N个副本时,发送方的NIC将产生N * B位的IO负载。 副本将接收B位,但不发送。 对于大量消息,这会导致NIC资源使用不佳:100Gbps NIC可能会发送和接收100Gbps的数据。 因此,顺序发送会在发送方处创建热点。
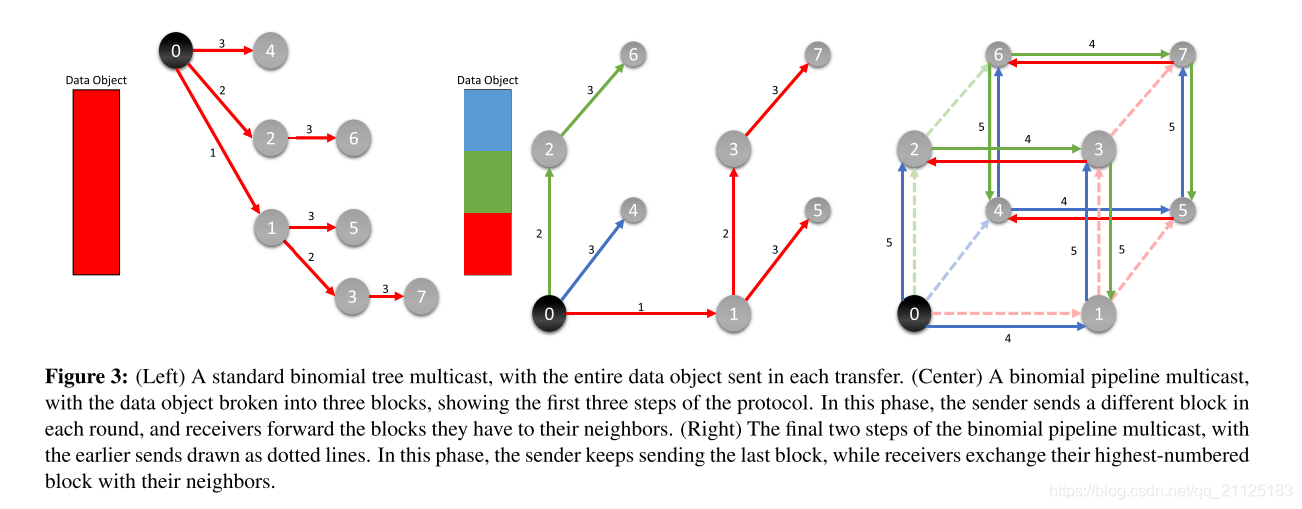
Chain Send. 该算法实现了一个bucket-brigade,类似于[21]中描述的链复制方案。 在将消息分成块之后,该队中的每个内部接收器在接收它们时都会转发块。 中继器使用它们的完全双向带宽,但是它们越往下走,它们在第一次阻塞之前就处于空闲状态的时间越长,因此最坏情况下的延迟很高。
Binomial Tree. 对于大型对象,如果发送者发送完整的消息,则接收者可以获得更好的性能,接收者一旦获得它就会中继每个消息,如图3(左)所示。箭头上的标签表示异步时间步长。这里,发送方0通过向接收方1发送一些消息开始。然后并行,0发送到2而1发送到3,然后在最后一步0发送到4,1发送到5,2发送到6和3发送由此产生的发送模式追溯到二叉树,因此延迟将优于顺序发送,但是在内部传输完成之前,内部传输无法启动。对于小规模的转移,这是不可避免的,但请记住,RDMC的目标是转移通常非常大的情况。理想情况下,我们希望通过将大型传输分成一系列较小的块并对块传输进行流水线操作来提高链路利用率,同时通过利用二叉树路由模式最大限度地减少延迟。
Binomial Pipeline. 通过将Chain Send与二叉树结合起来,我们可以实现这两个目标,这是Ganesan和Seshadri首先做出的观察[7]。该算法通过创建维度d的虚拟超立方体叠加来工作,其中d个不同的块将被同时中继(图3,中间,其中块由红色,绿色和蓝色表示)。每个节点重复执行一次发送操作和一次接收操作,直到最后一步它们全部同时接收到它们的最后一个块(如果节点数不是2的幂,则最终收据分布在两个异步上脚步)。 Ganesan和Seshadri的原创作品是理论性的,并通过模拟验证。此外,他们假设网络是同步的。我们将他们的方法扩展到完全异步设置,其中一个节点正在等待一个节点发送一个块。我们还解除了发送和接收步骤的耦合,以便只有在未收到相关块的情况下,发送步骤才会挂起。结果算法非常有效,因为它可以快速达到其满载传输模式,确保节点在发送和接收块的同时花费尽可能多的时间。
Hybrid Algorithms. 当前的数据中心隐藏了网络拓扑,以防止可能会破坏更广泛的管理目标的应用程序行为。但是,假设有人正在为数据中心范围的使用构建基础结构服务,并且可以使用这种形式的信息。许多数据中心在逐个机架的基础上具有完全的二分带宽,但使用某种形式的超额订购机架式(TOR)交换机来连接不同的机架。当二项式流水线多播在这样的设置中运行时,大部分传输操作都会穿过TOR交换机(这是因为如果我们使用随机节点对构建覆盖,许多链路将连接位于不同机架中的节点) 。相反,假设我们使用二项式管道的两个独立实例,一个在TOR层,另一个在机架内。通过这样做,我们可以为每个机架领导者提供一条消息的副本,以创建更高负载的突发,但是高效并且实现最低可能的延迟和倾斜。然后我们重复在机架内的传播,并再次最大化带宽,同时最小化延迟和歪斜。
4.6 Insights from Using RDMA
我们现在有多年的RDMC在各种设置方面的经验,并在我们自己的Derecho平台中使用它。 这些活动产生了一些见解。
Recovery From Failure. 如前所述,RDMC Group的行为很像从发送方到每个接收方的一组并排TCP连接。 虽然当单个RDMA连接报告问题时会感觉到故障,但我们的中继故障信息的策略会迅速收敛到中断的RDMC Group停止新传输的状态,并且所有幸存的端点都知道故障。 此时,某些接受者可能已成功接收并传递其他接受者尚未完成接收的消息。
为了理解由此产生的恢复挑战,我们可以询问发送方在第一次得知其RDMC Group失败时“知道”了什么。 正如TCP发送方没有得知TCP窗口中的数据已被接收和处理,除非引入某种形式的端到端确认,RDMC发送方信任RDMC完成其工作。 如果一个组用于一系列传输,则发送方将缺乏关于最近传输的消息的状态的确定性(RDMC不提供端到端状态报告机制)。 另一方面,如果出现问题,所有RDMC集团成员都会感受到中断。 此外,关闭(销毁)RDMC组时将始终报告故障。 因此,如果Group关闭操作成功,则发送方(以及所有接收方)可以确信每个RDMC消息到达每个目的地。
对于介绍中列出的大多数目的,此保证就足够了。 例如,如果多播文件传输完成且关闭成功,则文件已成功传递给完整的接收者,没有重复,遗漏或损坏。 相反,如果转移失败,每个接收者都会得知这一点,文件传输工具可以简单地重试幸存成员内的转移。 如果该工具正在传输一长串文件并且重新发送它们的成本是一个问题,它可以实现端到端状态检查以确定哪些不需要重新发送。
寻求更强保证的系统也可以利用RDMC。 例如,Derecho使用单边RDMA Write实现了复制状态表来扩充RDMC [9]。 收到RDMC消息后,Derecho会暂时缓冲它。 只有在每个接收者都有一个消息副本之后才会发送,接收者通过监视状态表来发现。 当故障中断RDMC组时,将使用类似形式的分布式状态跟踪。 在这里,Derecho使用基于领导者的清理机制(再次基于单边RDMA WRITE协议)从所有生存节点收集状态,分析结果,然后告诉参与者哪些缓冲消息要传递,哪些 放弃。 通过一系列此类扩展,Derecho能够提供全套Paxos保证,但它仍然可以通过RDMC传输所有消息。
Small Message. RDMC针对批量数据移动进行了优化。 这里报道的工作只关注大型消息案例。 Derecho包括一个小消息协议,它使用单侧RDMA写入一组循环有界缓冲区,每个接收器一个,并将该方法的性能与RDMC的性能进行比较。 总之,与RDMC相比,优化的小消息协议可以获得高达5倍的加速,前提是该组足够小(最多约16个成员)并且消息足够小(不超过10KB)。 对于较大的组或较大的消息,以及可以批量处理的长串消息,二项式管道占主导地位。
Memory Management. RDMC提供灵活的内存管理。 在此处报告的实验中,我们预先注册将与RDMA NIC一起使用的内存区域,但在第一个块出现时为每个新消息分配内存。 因此,接收器在关键路径上执行对malloc的调用。 在可以提前计划的应用程序中,可以通过在一系列传输开始之前执行内存分配来实现更好的性能。
5. Experiments
5.1 Step
我们在几个配备有不同内存和NIC硬件的集群上进行了实验。
Fractus Fractus是一个由16个支持RDMA的节点组成的集群,运行Ubuntu 16.04,每个节点配备4x QDR Mellanox NIC和94 GB DDR3内存。 所有节点都连接到100 Gb / s Mellanox IB交换机和100 Gb / s Mellanox RoCE交换机,并且具有相互之间的单跳路径。
Sierra. 劳伦斯利弗莫尔国家实验室的Sierra集群由1,944个节点组成,其中1,856个节点被指定为批量计算节点。 每个都配备两个6核Intel Xeon EP X5660处理器和24GB内存。 它们通过Infiniband结构连接,该结构被构造为两阶段,联合,双向,胖树。 NIC是4x QDR QLogic适配器,每个适配器以40 Gb / s的线速运行。 Sierra集群运行TOSS 2.2,这是Red Hat Linux的修改版本。
Stampede-1. U. Texas Stampede-1集群包含6400个C8220计算节点和56 Gb / s FDR Mellanox NIC。 与Sierra一样,它是批量安排的,几乎无法控制节点位置。 我们测量的单播速度高达40 Gb / s。
Apt Cluster. EmuLab Apt集群包含总共192个节点,分为两类:128个节点具有单个Xeon E5-2450处理器和16 GB RAM,而64个节点具有两个Xeon E5-2650v2处理器和64 GB RAM。 它们都有一个FDR Mellanox CX3 NIC,能够达到56 Gb / s。
有趣的是,Apt有一个明显超额订购的TOR网络,当负载较重时,每个链路降级到大约16 Gb / s。 这使我们能够在一些网络链路比其他网络链路慢得多的情况下查看RDMC的行为。 虽然这种情况似乎非常适合采取下一步并尝试混合协议,但事实证明这是不切实际的:Apt像Sierra一样是批量调度的,无法控制节点布局,我们无法动态发现网络拓扑。
我们的实验包括紧密复制当今云平台中的RDMA部署的案例。 例如,Microsoft Azure通过Infiniband提供RDMA作为其Azure Compute HPC框架的一部分,许多供应商在他们自己的基础设施工具中使用RDMA,无论是在Infiniband还是在RoCE上。 然而,暴露RoCE的大规模终端用户测试平台尚不可用:运营商显然担心大量使用RoCE会触发数据中心范围的不稳定性。 我们希望DC-QCN的推出能够让运营商放心,然后运营商会看到允许其用户访问RoCE的明显好处。
在我们的所有实验中,发送方生成包含随机数据的消息,并且我们测量从发送提交到库的时间到所有客户端都获得指示多播已完成的上行调用的时间。 发送的最大消息具有在传输视频的应用程序中或在将大图像推送到数据分析环境中的计算节点时可能出现的大小。 选择较小的消息大小以匹配复制照片或XML编码消息等任务。 带宽计算为发送的消息数,乘以每个消息的大小除以花费的总时间(无论接收器的数量)。 RDMC不管道消息,因此多播的延迟只是消息大小除以其带宽。
5.2 Results
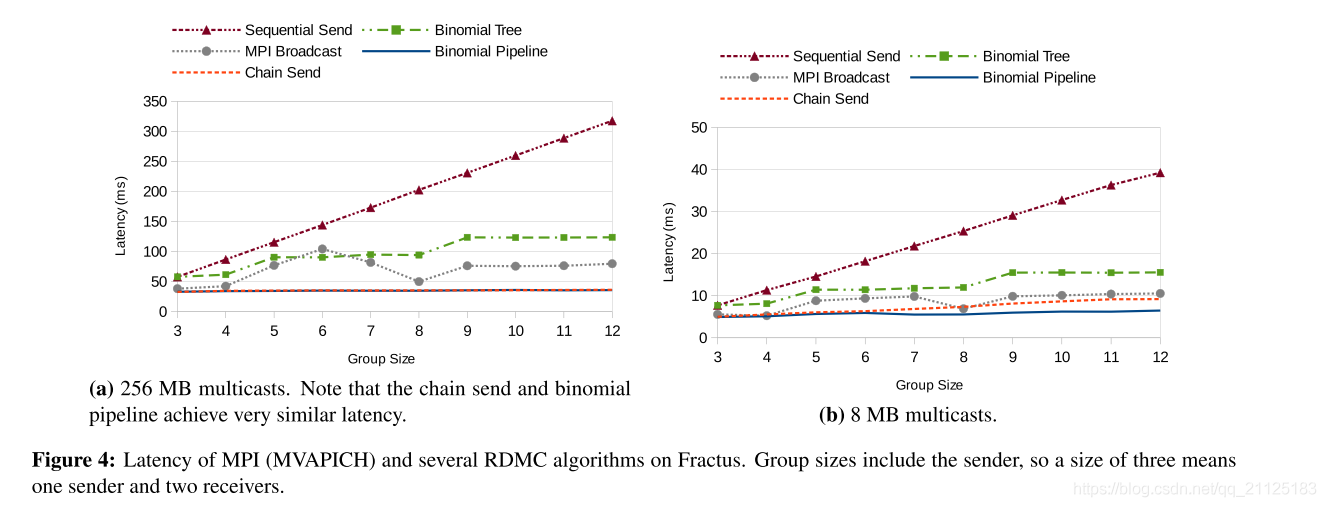
图4比较了所考虑的不同算法的相对性能。 为了比较,它还显示了MVAPICH的高度优化的MPI Bcast()方法的吞吐量,MVAPICH是一个在Infiniband网络上实现MPI标准的高性能计算库(我们使用单独的基准测试套件测量)。 随着节点数量的增加,顺序发送和二叉树都表现不佳。 同时,链发送与二项式管道竞争,除了小型转移到大量节点,其中二项式提前。 MVAPICH介于两者之间,与二项式管道一样,从1.03倍到3倍。 在本文的其余部分,我们主要关注二项式管道,因为它在一系列设置中具有强大的性能,但我们注意到链式发送由于其简单性通常很有用。
5.2.1 Microbenchmarks
在表1中,我们分析了在Stampede上进行单个256 MB传输(1 MB块)和组大小为4(意味着1个发送器和3个接收器)的时间。 所有值均以微秒为单位,并且在距离根最远的节点上进行测量。 因此,远程设置和远程块传输反映了根要发送和第一个接收器进行中继所花费的时间总和。 大约99%的总时间花费在远程块传输或块传输状态(其中网络被充分利用)中,这意味着来自RDMC的开销仅占传输所花费时间的大约1%。
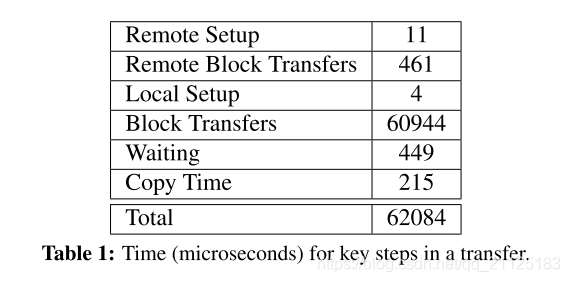
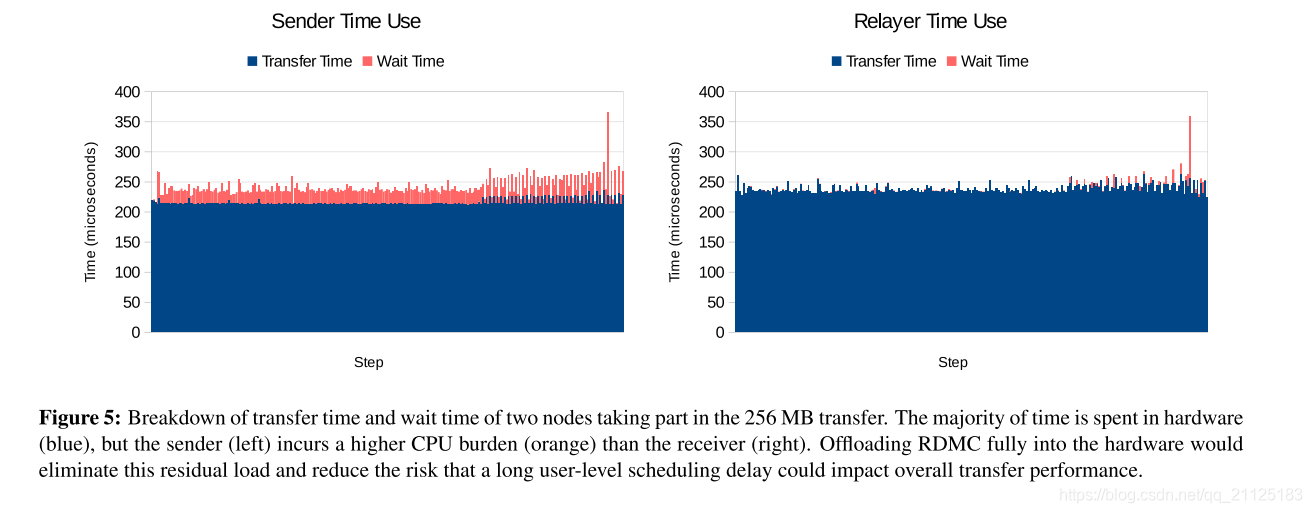
图5检查了相同的发送,但显示了转发器(其时间在表中报告)和根发送方的每个传输步骤的时间使用情况。 在消息传输结束时,我们看到两个已检测节点上的等待时间异常长。 事实证明,这证明了RDMC如何容易受到各个节点延迟的影响。 在这种情况下,继电器上大约100μs的延迟(可能是由操作系统选择不合时宜的时间来阻止我们的过程)迫使发送方在发现其下一个区块的目标不是时,推迟到下一步骤。 准备好了。 CORE-Direct功能可以减轻这种影响。
在图6中,我们检查了块大小对一系列消息大小的带宽的影响。 请注意,增加块大小最初会提高性能,但会达到峰值。 由于存在两个相互竞争的因素,因此实际上可以预期这一结果。 每个块传输都涉及一定的延迟,因此增加块大小实际上会增加信息在链路上移动的速率(随着块大小的增大,收益递减)。 但是,与二项式流水线算法相关的开销与传输单个块所花费的时间量成正比。 当消息中没有足够的块使所有节点有效地为传输做出贡献时,还会产生额外的开销。
最后,图7测量了使用二项式管道每秒传递的1字节消息的数量,同样在Fractus上。 但请注意,二项式管道(以及整个RDMC)并不是真正意图作为高速事件通知解决方案:我们是否主要关注以尽可能高的速度传递非常小的消息,以及 尽可能低的延迟,我们可以探索的其他算法在大多数条件下都优于RDMC的这种配置。 因此,RDMC的1字节行为作为理解开销的方式比其实际性能更有意义。

5.2.2 Scalability
图8比较了Sierra上的二项式管道与顺序发送的可扩展性(趋势很明显,Sierra是一个昂贵的系统,因此我们推断了512节点的顺序发送数据点)。 虽然序列发送量在接收器数量上呈线性变化,但二项式管道在线性上进行缩放,这在创建大量大型对象副本时会产生巨大的差异。 这个图表带来了令人惊讶的见解:使用RDMC,复制几乎是免费的:无论是制作127,255还是511副本,所需的总时间几乎相同。
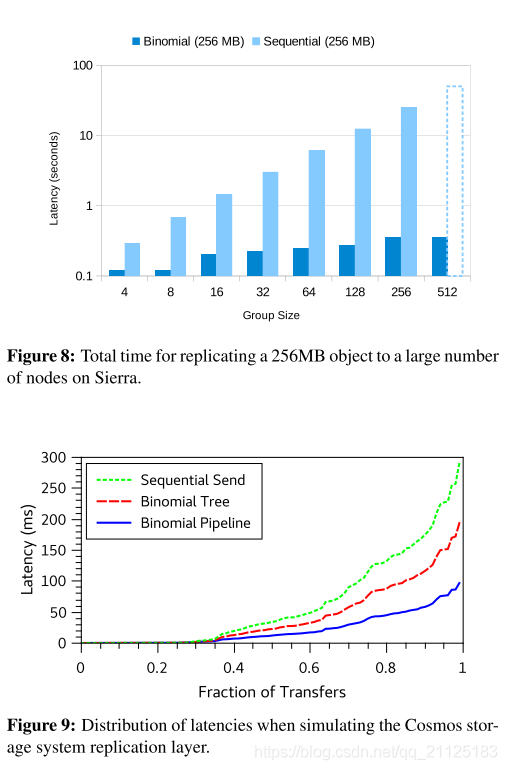
虽然我们没有单独绘制传输结束时间,但二项式管道传输几乎同时完成:这最大限度地减少了时间偏差,这在并行计算设置中很重要,因为许多此类系统运行为一系列松散同步的步骤,最终以 某种形式的shuffle或all-to-all数据交换。 Skew可以让整个系统空闲等待一个节点完成。 相反,顺序发送的线性劣化也与高偏斜相关。 这凸显了当今大多数云计算框架中使用的技术的非常差的性能:不仅复制副本复制缓慢,而且它还会中断需要等待转移到所有完成的计算,或者应该运行的计算 松散同步的阶段。
接下来,我们开始研究RDMC在应用程序中的行为,这些应用程序向重叠组发出大量并发多播。 我们从Microsoft的Cosmos系统的数据复制层获取了一个跟踪样本,这是Bing平台使用的数据仓库。 Cosmos目前在TCP / IP网络上运行,不使用RDMA或多播。 跟踪有数百万个3节点写入,随机目标节点和对象大小从数百个字节到数百MB不等(中位数为12MB,平均值为29 MB)。 许多转移都有重叠的目标群体。
为了模拟Cosmos工作负载的多播使用,我们指定了一个Fractus节点来生成流量,并指定了15个节点来托管副本。系统通过生成填充有随机内容的对象来操作,这些对象具有与跟踪中看到的相同的大小,然后通过随机选择一个可能的3节点分组作为目标来复制它们(事先创建了所需的455个RDMC组,以便这样做将离开关键路径)。图9显示了3种不同发送算法的延迟分布。请注意,二项式管道的速度是二项式树的两倍,速度是顺序发送速度的三倍。使用二项式管道运行时的平均吞吐量大约为93 Gb / s的复制数据,相当于每天大约1 PB。我们几乎达到了Fractus的完全二分能力,并没有在并发重叠传输之间产生干扰的迹象。 RDMC数据模式对此工作负载非常高效:任何网络链路上都不会发生冗余数据传输。
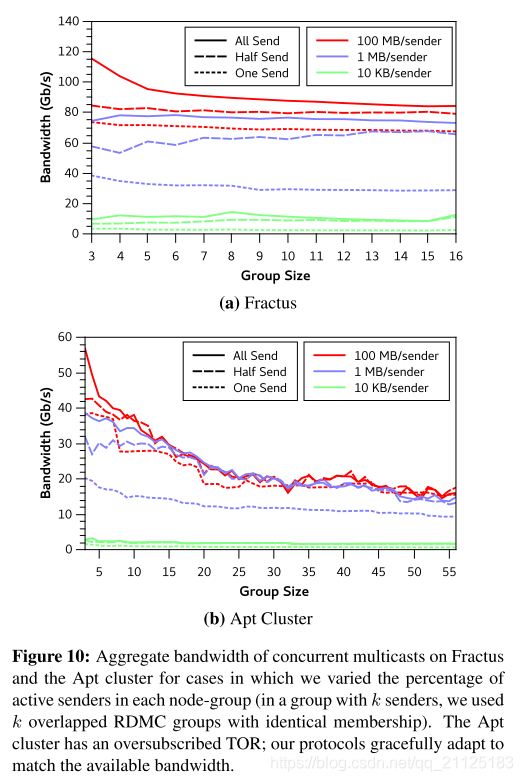
第二个实验以更加受控的方式查看具有固定多播消息大小的组重叠。在图10中,我们构造了由X轴标签给出的大小的组。这些集合具有相同的成员(例如,8节点的情况总是具有相同的8个成员),但是不同的发送者。在每个尺寸,我们进行3次实验,改变发送者的数量。 (1)在对应于实线的实验中,所有成员都是发送者(因此我们有8个完全重叠的组,每个组具有相同的成员,但是不同的发送者)。 (2)用虚线表示,重叠组的数量是一半大小:成员的一半是发送者。 (3)最后,虚线显示跨越所有成员但具有单个发送者的单个组的性能。所有发件人都以最大速率运行,发送指定大小的消息。然后我们通过测量将给定大小的消息传送到所有重叠组的时间,并除以消息大小乘以组的数量(即发送的总字节数)来计算带宽。
同样,我们看到测试系统的全部资源得到了有效利用。在Fractus上,具有100Gbps的完全二分能力,我们的峰值速率(在并发发送器的模式中看到)非常接近极限,至少对于较大的消息大小。在Apt上,具有超额认购的TOR,对于这种通信模式,二分带宽接近16Gbps,并且我们的图也这样做,至少对于较大的组(其产生足够的负载以使TOR开关饱和)。
5.3 Future Work:RDMC On TCP
当Ganesan和Seshadri首次探索多播覆盖拓扑时,他们表示担心即使是单个滞后节点也可能导致级联延迟,影响每个参与者并限制可扩展性[7]。这使他们将工作重点放在专用的,同步的HPC设置上,证明假设节点将以锁步方式运行而不会出现调度延迟或链路拥塞。
但是,今天的RDMA在多租户环境中运行。即使是超级计算机也会承载大量工作,因此存在链路拥塞的风险。标准以太网设置中的RDMA使用类似TCP的拥塞控制(DCQCN或TIMELY)。然而,我们并未看到业绩大规模崩溃。我们的松弛分析提出了一个可能的解释:双向管道生成块传输计划,其中有延迟节点有机会赶上。随着我们扩大规模,各种延迟确实会发生。然而,这种松弛显然可以弥补,减少经济放缓。
该观察结果具有一个有趣的实际结果:它表明RDMC可能比高速数据中心TCP(没有RDMA),甚至可能在WAN网络中工作得更好。在仍在进行的工作中,我们正在通过OpenFabrics接口联盟(OFI)[16]将RDMC移植到通过LibFabrics访问RDMA。 LibFabrics是一个成熟的解决方案,用作HPC计算的消息传递接口(MPI)库的最低层。该软件包使用宏扩展方法,直接映射到RDMA以及其他硬件加速器,甚至是标准TCP。端口完成后,我们计划在各种TCP设置中仔细研究RDMC的行为。
6.Related Work
复制是一个丰富的软件库和系统领域。 我们已经提到了可靠的广播,主要是为了强调RDMC旨在复制数据,但并不打算提供相关的强组语义和广播原子性。 Paxos是最著名的状态机复制(共识)技术。 此类系统的示例包括经典的Paxos协议本身,我们的Derecho库,libPaxos,Zookeeper的ZAB层,Corfu中的日志机制,DARE和APU [1,9,10,12,13,18,24。 Derecho表明RDMC在Paxos解决方案中很有用,但在这样做时还需要额外的机制:RDMC的语义比Paxos弱。
我们不是第一个询问如何在操作系统中利用RDMA的人。 早期的RDMA概念本身可以追溯到Von Eicken和Vogels [23]的经典论文,该论文引入了零拷贝选项并重新编程了一个网络接口以展示其优势。 VIA,随后出现了虚拟接口架构; 其“Verbs”API扩展了UNet的想法,以支持Infiniband,Myrinet,QLogic和其他供应商的硬件。 RDMC使用的Verbs API是广泛标准的,但其他选项包括RDMA的QLogic PSM子集,Intel的Omni-Path Fabric解决方案,套接字级别的产品,如Chelsio WD-UDP [3]嵌入等。
尽管产品数量众多,但似乎有理由断言迄今为止最大的成功是与Infiniband RDMA的MPI平台集成,后者已成为HPC通信的支柱。 MPI本身实际上提供了类似于本文所述的广播原语,但MPI强加的编程模型有许多限制,使其不适合RDMC所针对的应用:(1)发送模式是事先知道的 因此,接收器可以在启动之前预测任何广播的确切大小和Root,(2)通过检查点处理容错,以及(3)作业中的一组进程必须在该作业的持续时间内保持固定。 即便如此,RDMC仍然比MPI的流行MVAPICH实施性能大幅提升。
广播在CPU内核之间也很重要,而Smelt库[11]提供了一种解决这一挑战的新方法。 他们的解决方案并不直接适用于我们的设置,因为它们处理的微小消息不需要增加被分解成块的复杂性,但是自动推断合理发送模式的想法很有趣。
虽然我们的重点是大量数据移动,但这里的核心论点可能最接近于最近的操作系统论文,如FaRM [5],Arrakis [17]和IX [2]。 在这些工作中,操作系统越来越多地被视为控制平面,RDMA网络被视为数据平面的带外技术,在最小的中断时效果最佳。 采用这种观点,可以将RDMC视为非常适合带外部署的通用数据平面解决方案。 最近使用RDMA优化数据库的一个例子是Crail [20]。
7. Conclusion
我们的论文介绍了RDMC:一种新的可靠的内存到内存复制工具,通过RDMA单播实现。 RDMC可以作为免费的开源库下载,并且应该直接用于O / S服务,这些服务目前一个接一个地移动对象,或者通过多个并行TCP链接移动对象。 该协议还可以用作具有更强语义的更高级库的组件。
与最广泛使用的通用选项相比,RDMC性能非常高,并且协议可扩展到大量副本。 即使只需要3个副本,RDMC也会带来好处。 事实上复制相对于创建一个副本而言非常便宜:一个可以有4个或8个副本,价格几乎与1相同,并且只需要几倍的时间来制作数百个副本。另外,RDMC对各种延迟都很稳健:数据丢失和复制的正常网络问题由RDMA处理,而RDMC的逐块发送模式和接收器 - 接收器中继补偿偶尔的调度和网络延迟。 RDMC代码库可作为Dere- cho平台(https://GitHub.com/Derecho-Project)的一部分下载。