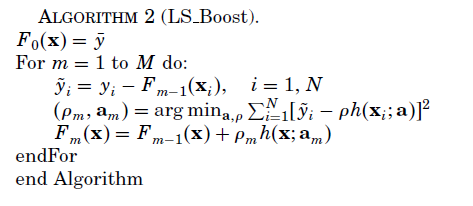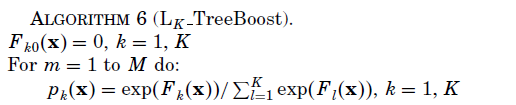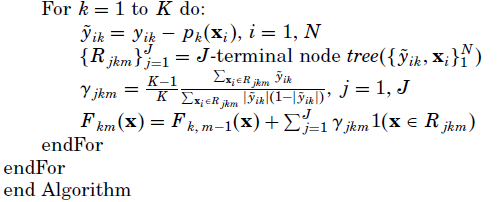组合模型
委员会(PRML 14.2)
构建⼀个委员会的最简单的⽅法是对⼀组独⽴的模型的预测取平均。这样的⽅法的动机可以从频率学家的观点看出来。这种观点考虑偏置和⽅差之间的折中,它将模型的误差分解为偏置分量和⽅差分量,其中偏置分量产⽣于模型和真实的需要预测的函数之间的差异,⽅差分量表⽰模型对于单独的数据点的敏感性。回忆⼀下,根据图3.5,当我们使⽤正弦数据训练多个多项式函数,然后对得到的函数求平均时,来⾃⽅差项的贡献倾向于被抵消掉,从⽽产⽣了预测的提升。当我们对⼀组低偏置的模型(对应于⾼阶多项式)求平均时,我们得到的对⽤于⽣成数据的正弦函数的精确的预测。当然,在实际应⽤中,我们只有⼀个单独的数据集,因此我们必须寻找⼀种⽅式来表⽰委员会中不同模型之间的变化性。⼀种⽅法是使⽤1.2.3节讨论的⾃助(bootstrap)数据集。
基于树的模型(PRML 14.4)
有许多简单但⼴泛使⽤的模型,它们将输⼊空间划分为超⽴⽅体区域,超⽴⽅体的边与坐标轴对齐,然后为每个区域分配⼀个简单的模型(例如,⼀个常数)。这些模型可以被看成⼀种模型组合⽅法,其中只有⼀个模型对于输⼊空间中任意给定点的预测起作⽤。给定⼀个新的输⼊x,选择⼀个具体的模型的过程可以由⼀个顺序决策的过程描述,这个过程对应于对⼀个⼆叉树(每个节点划分为两个分⽀的树)的遍历。这⾥,我们关注⼀个特定的基于树的框架,被称为分类与回归树(classification and regression tree),或者CART(Breiman et al., 1994),虽然还有很多其他的变体,例如ID3和C4.5(Quinlan, 1986; Quinlan, 1993)。
条件混合模型(PRML 14.5)
普通混合
线性回归混合、logistic混合、高斯混合、多项分布混合。(PRML 14.4)
专家混合
在14.5.1节,我们考虑了线性回归模型的混合,在14.5.2节,我们讨论了线性分类器的类似的混合。虽然这些简单的混合扩展了线性模型的灵活程度,包含了更复杂的(例如多峰的)预测分布,但是它们仍然具有很⼤的局限性。我们可以进⼀步增强这些模型的能⼒,⽅法是使得混合系数本⾝是输⼊变量的函数

由于门函数和专家函数使⽤了线性模型,因此这样的模型仍然有很⼤的局限性。⼀个更加灵活的模型时使⽤多层门函数,得到了专家层次混合(hierarchical mixture of experts)模型或者HME模型(Jordan and Jacobs, 1994)。为了理解这个模型的结构,假设⼀个混合分布,它的每个分量本⾝都是⼀个混合分布。对于⽆条件的混合分布,层次混合简单地等价于⼀个普通的混合分布。然⽽,当混合系数与输⼊相关时,层次模型就变得不普通了。HME模型也可以被看成14.4节讨论的决策树的概率版本,并且与之前⼀样可以通过最⼤似然的⽅式使⽤EM算法以及M步骤中的IRLS算法⾼效计算。
我们这⾥不会详细讨论HME。然⽽,值得指出的⼀点是,它与PRML5.6节讨论的混合密度⽹络(mixture density network)有着密切的联系。
提升方法(Boosting)(PRML 14.3、ESL 10.* paper_GBM)
提升⽅法是⼀种很强⼤的⽅法,它将多个“基”分类器进⾏组合,产⽣⼀种形式的委员会,委员会的表现会⽐任何⼀个基分类器的表现好得多。
提升⽅法最初被⽤来解决分类问题,但是也可以推⼴到回归问题。
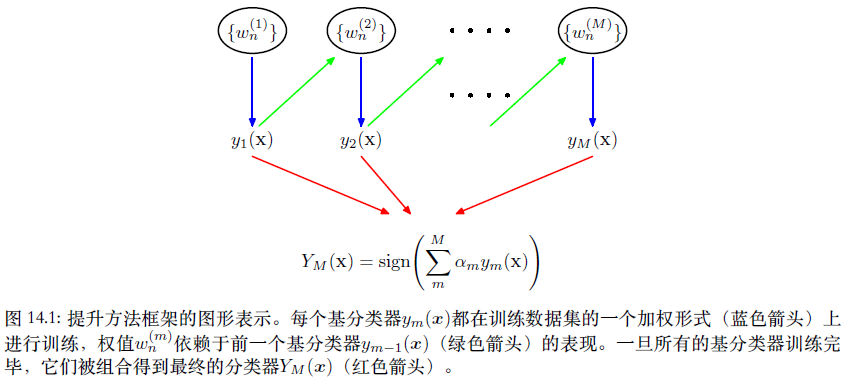
提升⽅法和委员会⽅法(例如上⾯讨论的打包⽅法)的主要不同在于,基分类器是顺序训练的,每个基分类器使⽤数据集的⼀个加权形式进⾏训练,其中与每个数据点相关联的权系数赖于前⼀个分类器的表现。特别地,被⼀个基分类器误分类的点在训练序列中的下⼀个分类器时会被赋予更⾼的权重。⼀旦所有的分类器都训练完毕,那么它们的预测就会通过加权投票的⽅法进⾏组合,如图14.1所⽰。
AdaBoost(原理见PRML 14.3)(ESL 10.4 10.5 10.6)
这⾥,我们介绍提升⽅法的最⼴泛使⽤的⼀种形式,被称为AdaBoost,是“可调节提升⽅法(adaptive boosting)”的简称,由Freund and Schapire(1996)提出。即使基分类器的表现仅仅⽐随机猜测的表现稍好,提升⽅法仍可以产⽣⽐较好的结果。

误差函数(ESL 10.4 10.5 10.6)
分析角度:
健壮性,可扩展性(能否扩展到多分类),是否运算便利
分类问题:
指数误差
负对数似然函数(交叉熵)
误分类率
回归问题:
Least squares(LS)
Least absolute deviation (LAD)
Huber (M),
梯度推进机(GBM)(参见论文:GREEDY FUNCTION APPROXIMATION_a gradient boosting machine)