1 对象序列化
主要讲解对象序列化的意义及实现,了解对象输入和输出流的使用,理解transient关键字。
所谓对象序列化是把在堆内存中的对象转换成二进制数据,传输给其它程序使用。
不是所有的对象能够序列化,只有实现java.io.serializable接口,
对于Serializable接口是一个标记接口,这个接口中没有任何方法。
实例化对象代码如下:
class BookS implements Serializable{
private String title;
private double price;
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public double getPrice() {
return price;
}
public void setPrice(double price) {
this.price = price;
}
@Override
public String toString() {
return "书名:"+this.title+"价格是:"+this.price;
}
}
1.1 实现序列化和反序列化
如果要实现序列化和反序列化,需要有两个类支持:
- 序列化类:java.io.ObjectOutputStream;将对象变成指定格式的二进制
- 反序列化类:java.io.ObjectInputStream;可以将序列化后的对象转换成对象内容
ObjectOutputStream - 构造方法:public ObjectOutputStream(OutputStream out) throws IOException;
- 输出对象:public final void writeObject(Object obj) throws IOException;
代码如下:
class BookS implements Serializable{
public BookS(String title, double price) {
this.title = title;
this.price = price;
}
private String title;
private double price;
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public double getPrice() {
return price;
}
public void setPrice(double price) {
this.price = price;
}
@Override
public String toString() {
return "书名:"+this.title+"价格是:"+this.price;
}
}
public class SerializableClassTest {
public static void main(String[] args) throws IOException {
ObjectOutputStream objcet = new ObjectOutputStream(new FileOutputStream(new File("d:"+File.separator+"test.txt")));
objcet.writeObject(new BookS("JAVA",45.67));
objcet.close();
}
}
序列化与反序列化在代码开发过程中很少用,是因为容器已经替我们解决了这个问题。
1.2 transient 关键字
private transient String title;
在对象序列化过程中,是把对象中的一些属性内容进行了保存,但是某些时候,有些属性不需要被保存,在这种情况下,就可以通过transient来定义,就如上面的代码一样。
2 网络编程
对于网络编程的时候基本上已经过去了,因为有很多组件都已经帮我们进行了封装,不需要单独去编写,在这里主要是了解什么是网络编程以及到后续的Jave EE项目开发中使用。
在实际工作过程中,对于网络编程有两种形式:
- C\S结构:客户端与服务端模式,这种模式开发两套程序,客户端程序和服务器端程序,但是这种程序有一个大的优势就是安全性高,客户端与服务器端的端口以及通讯协调都是自定义的。
- B\S结构:浏览器与服务器端模式,这种模式不需要再单独开发客户端代码,客户端统一使用浏览器进行统一访问,这种模式只需要开发一套程序,但是安全性不高,端口是统一的80,通讯协议是HTTp协议。
我们现在讲的网络编程就是CS结构的开发,也可以叫做Socket程序, 对于CS结构的程序分为两类: - TCP程序:采用可靠的连接方式进行的传输
- UDP程序:采用不可靠的连接方式进行的传输
网络程序最核心的两个类: - 服务器端:ServerSocket
- 客户端:Socket
服务端程序:
public class ServerSocketTest {
public static void main(String[] args) throws IOException {
ServerSocket server = new ServerSocket(9000);
Socket client = server.accept();
PrintStream out = new PrintStream(client.getOutputStream());
out.println("hello World!");
out.close();
client.close();
server.close();
}
}
客户端程序:
public class SocketClassTest {
public static void main(String[] args) throws IOException {
Socket client = new Socket("localhost",9000);
Scanner scan = new Scanner(client.getInputStream());
scan.useDelimiter("\n");
if(scan.hasNext()){
System.out.println("[回应数据:]"+scan.next());
}
}
}
3 类集的应用
类集是java数据结构实现、是动态对象数组,也是对象数组的应用,平时,如果保存多个对象,一般情况下会使用对象数组,但是对象数组是固定(数组一般不会使用),后来使用了链表来实现一个动态的对象数组。但自己去实现链表,非常复杂,开发难度较大,在这种情况下,JAVA提供一些工具类,来解决此问题。
这些工具类中有一些主要的工具分别是:
- Collection、List、Set
- Map
- Iterator、Enumeration
3.1 Collecton接口
Collection接口是整个类集之中单值保存的最大父接口,一般不使用,直接使用它的子类。
Collection接口中有下面常用的方法:
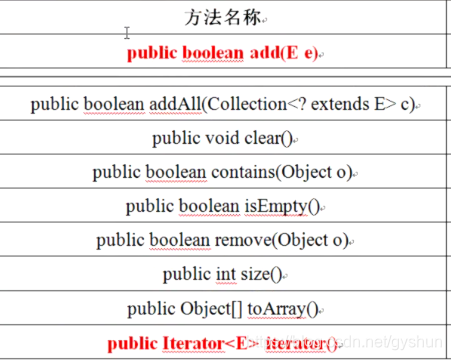
在所有的开发之中,add()与iterator()两个方法的使用机率是最高的。但是千万要记住contains()与remove()两个方法一定要依靠equals()支持。
其中List允许重复,Set不允许重复。
3.2 List子接口
掌握List子接口,验证Collection接口提供的方法;掌握List子接口的操作特点以及常用的子类(ArrayList、Vector )
List接口是Collection是常用的一个子接口。
List除了提供Collect提供的方法,另外增加一些主要的方法:

3.2.1 ArrayList类
ArrayList类是List的子类,是常用的类。
ArrayList操作代码如下:
public class ListClassTest {
public static void main(String[] args) {
List<String> list = new ArrayList<String>();
StringBuffer sb = new StringBuffer();
sb.append("大小是:");
sb.append(list.size());
sb.append("\n");
sb.append("是否为空:");
sb.append(list.isEmpty());
System.out.println(sb.toString());
list.add("Hello");
list.add("Hello");
list.add("World");
System.out.println("大小是:"+list.size()+" 是否为空:"+list.isEmpty());
for (int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}
}
}
从上面可以看出List是根据保存数据顺序进行保存,数据可以重复。
3.2.2 旧的子类:Vector
直接把上面的代码中ArrayList改成Vector就是可以运行(因为都是基于接口):
如下代码:
public class ListClassTest {
public static void main(String[] args) {
List<String> list = new Vector<String>();
StringBuffer sb = new StringBuffer();
sb.append("大小是:");
sb.append(list.size());
sb.append("\n");
sb.append("是否为空:");
sb.append(list.isEmpty());
System.out.println(sb.toString());
list.add("Hello");
list.add("Hello");
list.add("World");
System.out.println("大小是:"+list.size()+" 是否为空:"+list.isEmpty());
for (int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}
}
}
ArrayList与Vector的区别:
| 区别 | ArrayList | Vector |
|---|---|---|
| 推出时间 | JDK1.2之后,属于新类 | JDK1.0推出,是旧类 |
| 性能 | 采用异步处理 | 采用同步处理 |
| 数据安全 | 非线程安全 | 线程安全 |
| 输出 | 支持Iterator、ListIterator、Foreach | Iterator、ListIterator、Foreach、Enumration |
在开发中90%的都使用ArrayList,很少使用Vector
总结
- List中的数据保存顺序是数据的添加顺序
- List的子类通常使用ArrayList
- List集合可以保存有重复的元素
- List子接口比Collection接口扩充了一个get()方法
3.3 Set子接口
Set接口下有个常用的子类:HashSet、treeSet。
3.3.1 HashSet
public class SetClassTest {
public static void main(String[] args) {
Set<String> set = new HashSet<String>();
set.add("Hello!");
set.add("Hello!");
set.add("Hello");
set.add("World");
System.out.println(set);
}
}
执行结果:
[Hello!, Hello, World]
从上面代码执行的结果,可以知道:
- HashSet是无序的
- HashSet是不能重复,如果有新增重复数据,它会自动删除掉重复的内容
3.3.2 TreeSet
TreeSet是默认是有序,所以对于数组排序,数组中的对象一定要实现Comparabler接口,并实现comparaTo()方法。
TreeSet主要依靠Comparable接口中的comparaTo()方法来判断,如果判断返回值为0,就认为是重复数据,就不会被保存。
代码如下:
class BookSet implements Comparable<BookSet>{
private String title;
private double price;
@Override
public String toString() {
return
"title='" + title + '\'' +
", price=" + price;
}
@Override
public int compareTo(BookSet o) {
if (this.price > o.price){
return 1;}
else if (o.price > this.price)
{return -1;} else{
return this.title.compareTo(o.title);
}
}
public BookSet(String title, double price) {
this.title = title;
this.price = price;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public double getPrice() {
return price;
}
public void setPrice(double price) {
this.price = price;
}
}
public class SetClassTest {
public static void main(String[] args) {
/* Set<String> set = new HashSet<String>();
set.add("Hello!");
set.add("Hello!");
set.add("Hello");
set.add("World");
System.out.println(set);*/
Set<BookSet> set = new TreeSet<BookSet>();
set.add(new BookSet("JAVA开发1",90.8));
set.add(new BookSet("JAVA开发2",91.8));
set.add(new BookSet("JAVA开发2",91.8));
set.add(new BookSet("JAVA开发3",93.8));
System.out.println(set);
}
}
通过上面可以知道 ,通过TreeSet操作,会比较麻烦,在开发中用的较少。
关于重复元素的说明
Comparable接口只能够负责TreeSet类进行重复元素的判断,还有就是数组进行排序时,需要数组中的对象实现Comparable,对于重复元素的判断,在JAVA中大部分是只能依靠Object类中所提供的方法:
- 取得哈希码:public int hashCode(); 先判断哈希值是否有相同,如果有相同,就需要借助equal()来判断。
- 对象比较:public boolean equals(Object obj);将对象的属性进行依次比较
对于hashCode()与equals()的区别,请查看:https://blog.csdn.net/gyshun/article/details/80852278
下面使用HashSet去重复的代码:
class BookSet implements Comparable<BookSet>{
private String title;
private double price;
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (!(o instanceof BookSet)) return false;
BookSet bookSet = (BookSet) o;
return Double.compare(bookSet.price, price) == 0 &&
Objects.equals(title, bookSet.title);
}
@Override
public int hashCode() {
return Objects.hash(title, price);
}
@Override
public String toString() {
return
"title='" + title + '\'' +
", price=" + price;
}
@Override
public int compareTo(BookSet o) {
if (this.price > o.price){
return 1;}
else if (o.price > this.price)
{return -1;} else{
return this.title.compareTo(o.title);
}
}
public BookSet(String title, double price) {
this.title = title;
this.price = price;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public double getPrice() {
return price;
}
public void setPrice(double price) {
this.price = price;
}
}
public class SetClassTest {
public static void main(String[] args) {
/* Set<String> set = new HashSet<String>();
set.add("Hello!");
set.add("Hello!");
set.add("Hello");
set.add("World");
System.out.println(set);*/
Set<BookSet> set = new HashSet<>();
set.add(new BookSet("JAVA开发1",90.8));
set.add(new BookSet("JAVA开发2",91.8));
set.add(new BookSet("JAVA开发2",91.8));
set.add(new BookSet("JAVA开发3",93.8));
System.out.println(set);
}
}
注意:
对于Eclipse和IDEA中都提供自动生成equals和hashCode两个方法。
总结
- 开发过程中,Set接口绝对不是首选,如果要使用,建议使用HashSet子类开发过程中,Set接口绝对不是首选,如果要使用,建议使用HashSet子类
- Comparable这种比较器,大部分情况下只会存在于JAVA理论中
- Set不管如何操作,必须保存一个前提:数据不能够重复。
3.4 集合输出操作
在JDK 1.8之前支持四种种输出:Iterator、ListIterator、Enumeration、Foreach。
如果遇见了集合操作,那么一般就会使用Iterator方法。
Iterator接口主要方法:
- public boolean hasNext();
- public E next();
代码如下 :
public class IteratorTest {
public static void main(String[] args) {
Set<String> set = new HashSet<String>();
set.add("wq");
set.add("wq");
set.add("wqq");
Iterator it = set.iterator();
while (it.hasNext()){
System.out.println(it.next());
}
}
}
ListIterator
ListIterator支持双向迭代,对于Iterator来说,只能支持由前向后的执行。
在这个接口中主要是两个方法:
- 判断是否有前一个元素:public boolean hasPrevious();
- 取得前一个元素:public E previous()
ListIterator是专门为List子接口定义的方法。
代码如下:
public class IteratorTest {
public static void main(String[] args) {
List<String> set = new ArrayList<String>();
set.add("wq");
set.add("wq1");
set.add("wq2");
ListIterator it = set.listIterator();
System.out.println("由前先后输出:");
while (it.hasNext()){
System.out.println(it.next());
}
System.out.println("由后向前输出:");
while(it.hasPrevious()){
System.out.println(it.previous());
}
}
注意:
对由后向前输出前提是先由前向后输出。
forEach输出
对于foreach输出还是挺方便使用的,可以方便的输出数组。
代码如下:
public class IteratorTest {
public static void main(String[] args) {
List<String> set = new ArrayList<String>();
set.add("wq");
set.add("wq1");
set.add("wq2");
for(String str : set){
System.out.println(str);
}
}
}
Enumeration 输出
Enumeration类与Vector类一起在JDK 1.0的时候推出的输出接口。
主要的方法有:
- public boolean hasMoreElements();
- public E nextElement();
由于方法名称太长,被Iterator代码掉了。如果如果想取得Enumeration接口的实例化对象,就必须依靠Vector子类进行实例化,代码如下:
public class IteratorTest {
public static void main(String[] args) {
Vector<String> set = new Vector<String>();
set.add("wq");
set.add("wq1");
set.add("wq2");
Enumeration<String> e = set.elements();
while (e.hasMoreElements()) {
System.out.println(e.nextElement());
}
}
}
对 Enumeration这个类,由于考虑到过去的代码经常使用,一定要记住。
3.5 Map接口
Map接口保存键值对(key\value),它除保存数据之后,还能够根据Key值进行查询(Key不能重复)。
定义的方法主要有:
- public V put(K key,V value);
- public V get (Object key);
- public set<Map.Entry<K,V>>entrySet();
- public Set keySet();
代码如下:
public class MapClassTest {
public static void main(String[] args) {
Map<String,Integer> map = new HashMap<String,Integer>();
map.put("1",1);
map.put("2",2);
map.put("3",3);
map.put("3",6);
map.put(null,4);
System.out.println(map);
}
}
结果:
{null=4, 1=1, 2=2, 3=6}
注意:
- Map中的Key值不能重复
- Map中的Key值可以是null
HashMap与HashTable的区别:
| 区别 | HashMap | HashTable |
|---|---|---|
| 推出时间 | JDK1.2之后,属于新类 | JDK1.0推出,是旧类 |
| 性能 | 采用异步处理 | 采用同步处理 |
| 数据安全 | 非线程安全 | 线程安全 |
| 设置Null | 允许Key、Value内容都可以为Null | 不允许Key、Value内容为Null |
关于Iterator输出的问题
对于集合的输出,一般情况下都使用iterator,但是在Map中没有返回Iterator接口的方法。
Collection集合与Map集合的对象存储关系如下:
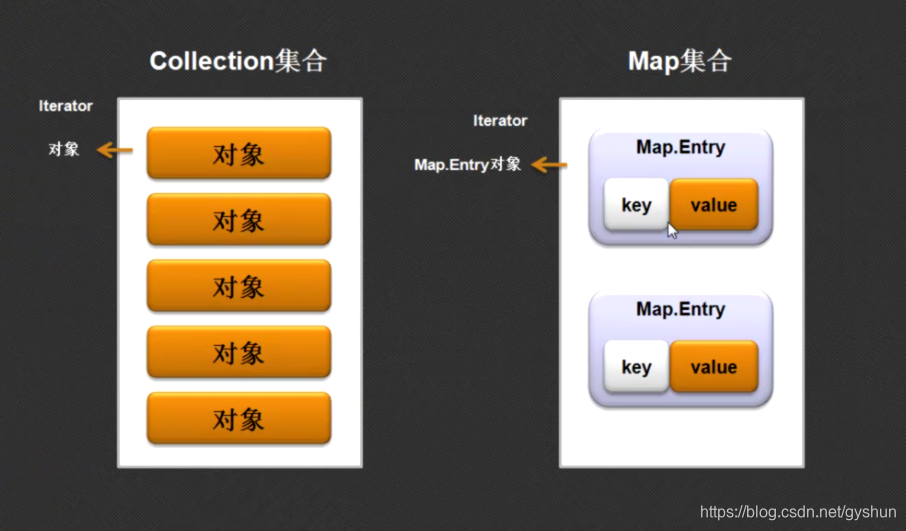
在Map中有一个静态对象:Map.Entry对象。
Map集合利用Iterator接口输出的步骤:
- 利用Map接口的entrySet()方法将Map集合变为Set集合
- 利用Set集合中的Iterator()方法将Set集合进行Iterator输出
- 每一个Iterator循环输出的是Map.Entry对象。
代码如下:
public class MapClassTest {
public static void main(String[] args) {
Map<String,Integer> map = new HashMap<String,Integer>();
map.put("1",1);
map.put("2",2);
map.put("3",3);
map.put("3",6);
map.put(null,4);
Set<Map.Entry<String,Integer>> set = map.entrySet();
Iterator<Map.Entry<String,Integer>> it = set.iterator();
while (it.hasNext()){
Map.Entry<String,Integer> entry = it.next();
System.out.println(entry.getKey());
System.out.println(entry.getValue());
}
}
}
4 Stack子类的使用
Stack表示的是栈操作,栈是一种先进后出的操作,而Stack是Vector的子类。
代码如下:
public class Stack<E> extends Vector<E>;
注意
虽然Stack是Vector的子类,但是它不会使用父类的方法,只会使用自己的方法,它主要有两个方法:
public E push(E item);
public E pop();
对于栈的操作代码如下:
public class StackClassTest {
public static void main(String[] args) {
Stack<String> stack = new Stack<String>();
stack.push("A");
stack.push("B");
stack.push("C");
System.out.println(stack.pop());
System.out.println(stack.pop());
System.out.println(stack.pop());
}
}
栈的操作还能够使用的地方就是Android上面(就是上面的返回键 )。
5 Properties子类
Properties是HashTable的子类,主要是对属性进行操作(属性文件最大特点就是设置Key、Value来定义属性)。这个类一般很少用,一般都用资源文件来操作(ResourceBundle类),Properties类的主要操作方法:
- public Object setProperty(String key,String value);
- public String getProperty(String key);如果Key不存在返回null,
- public String getProperty(String key,String defaultValue);如果Key不存在返回默认值,
代码如下:
public class PropertiesClassTest {
public static void main(String[] args) {
Properties p = new Properties();
p.setProperty("bj","北京");
p.setProperty("sh","上海");
p.setProperty("gz","广州");
p.setProperty("sz","深圳");
System.out.println(p.getProperty("bj"));
System.out.println(p.getProperty("sh"));
System.out.println(p.getProperty("gz"));
System.out.println(p.getProperty("ss"));
}
}
Properties类也可以对Properties属性文件进行操作,通过两个方法:
- public void store(OutputStream out,String commnets);
- public void load(InputStream in);
把属性存储到properties属性文件中,代码如下:
public class PropertiesClassTest {
public static void main(String[] args) throws Exception {
Properties p = new Properties();
p.setProperty("bj","北京");
p.setProperty("sh","上海");
p.setProperty("gz","广州");
p.setProperty("sz","深圳");
p.store(new FileOutputStream(new File("d:"+ File.separator+"area.properties")),"comments");
}
}
结果为:
#comments
#Fri Nov 30 15:31:57 CST 2018
bj=\u5317\u4EAC
sh=\u4E0A\u6D77
gz=\u5E7F\u5DDE
sz=\u6DF1\u5733
从properties属性文件中读取数据,代码如下:
public class PropertiesClassTest {
public static void main(String[] args) throws Exception {
Properties p = new Properties();
p.load(new FileInputStream(new File("d:"+File.separator+"area.properties")));
System.out.println(p.getProperty("bj"));
}
}
故,对于属性文件,可以通过Properties类读取,也可以通过ResourceBundle类进行读取。
6 Collections类的使用
Collections类是对List、Map、Set集合类进行辅助操作,是一个工具集。担任了一些辅助功能。
Collection与Collections类的区别:
- Collection是一个集合接口
- Collections是一个工具类,是对List、Map、Set等集合方法进行操作
代码如下:
public class CollectionsTest {
public static void main(String[] args) {
List<String> list = new ArrayList<String>();
//填写集合中的内容
Collections.addAll(list,"A","B","C","D");
//集合的内容可以进行翻转操作
Collections.reverse(list);
}
}
7 Stream类(集合的辅助工具)
7.1 forEach()方法的使用
代码如下:
public class ForEachClassTest {
public static void main(String[] args) {
List<String> list = new ArrayList<String>();
list.add("ww");
list.add("qq");
list.add("ee");
list.forEach(System.out ::println);
}
}
7.2 Stream类能做什么
除了使用Iterator迭代和处理数据之后,在JDK 1.8之后,提供了一个Stream类的工具,可以通过Connection类获得这个对象,方法:
default Stream stream();
Stream类的简单应用如下:
public class ForEachClassTest {
public static void main(String[] args) {
List<String> list = new ArrayList<String>();
list.add("ww");
list.add("qq");
list.add("ee");
Stream<String> stream = list.stream();
System.out.println(stream.count());
}
}
Stream类是把Collection类的数据进行深加工处理,是对Collection数据的处理进行补充,Stream类主要功能
- 取消重复数据:public Stream distinct(); 返回的是Stream类,但是原集合的数据还是重复的。
- 收集器:public <R,A> R collect(Collector<?super T,A,R> collector) ;其中Collectors类中提供了一个转换成集合的方法:public static Collector<T,?,List> toList();
代码如下:
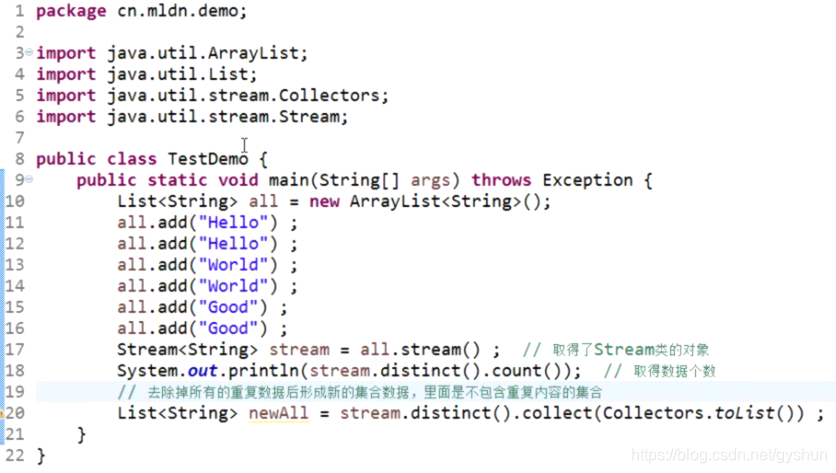
通过Stream类的ditinct().filter()方法对List数据进行过滤,并返回一个过滤后的List,如下代码:
public class ForEachClassTest {
public static void main(String[] args) {
List<String> list = new ArrayList<String>();
list.add("Android");
list.add("java");
list.add("Ios");
list.add("jsp");
list.add("ORACLE");
Stream<String> stream = list.stream();//取得Stream类对象
//增加了数据过滤操作,使用了断言型函数式接口,使用了String类中的contains()
List<String> newList = stream.distinct().filter((x) -> x.contains("a")).collect(Collectors.toList());
newList.forEach(System.out :: println);
}
}
通过上面代码filter()是区分大小写。
对于Stream也可以通过下面的方法,进行数据过滤前进行处理:
public Stream map(Function<?superT,?extends R> mapper);
在过滤前,先把字符串转换成小写,再过滤,代码如下:
public class ForEachClassTest {
public static void main(String[] args) {
List<String> list = new ArrayList<String>();
list.add("Android");
list.add("java");
list.add("Ios");
list.add("jsp");
list.add("ORACLE");
Stream<String> stream = list.stream();//取得Stream类对象
//增加了数据过滤操作,使用了断言型函数式接口,使用了String类中的contains()
List<String> newList = stream.distinct().map((x) -> x.toLowerCase()).filter((x) -> x.contains("a")).collect(Collectors.toList());
newList.forEach(System.out :: println);
}
}
通过上面一行代码,对List的数据进行处理,并进行了过滤,并返回一个新的List数据。
在Stream接口里面提供了有进行集合数据分布的操作
- 设置跳过的数据行数:public Stream skip(long n);
- 设置取出的数据个数:public Stream limit(long maxSize);
如下代码:
public class ForEachClassTest {
public static void main(String[] args) {
List<String> list = new ArrayList<String>();
list.add("Android");
list.add("java");
list.add("Ios");
list.add("jsp");
list.add("ORACLE");
Stream<String> stream = list.stream();//取得Stream类对象
//增加了数据过滤操作,使用了断言型函数式接口,使用了String类中的contains()
List<String> newList = stream.distinct().map((x) -> x.toLowerCase()).skip(2).limit(2).collect(Collectors.toList());
newList.forEach(System.out :: println);
}
}
Streamg还可以进行数据的全匹配或部分匹配
- 全匹配:public boolean allMacth(Predicate<?superT> predicate);
- 匹配任意一个:public boolean anyMatch(Predicate<?superT> predicate);
代码如下:
public class ForEachClassTest {
public static void main(String[] args) {
List<String> list = new ArrayList<String>();
list.add("Android");
list.add("java");
list.add("Ios");
list.add("jsp");
list.add("ORACLE");
Stream<String> stream = list.stream();//取得Stream类对象
if(stream.anyMatch((x)->x.contains("jsp"))){
System.out.println("有数据存在!!");
}
}
}
可以根据Predicate可以设置多个过滤条件,如下代码:
public class ForEachClassTest {
public static void main(String[] args) {
List<String> list = new ArrayList<String>();
list.add("Android");
list.add("java");
list.add("Ios");
list.add("jsp");
list.add("ORACLE");
Predicate<String> p1 = (x)->x.contains("jsp");
Predicate<String> p2 = (x)->x.contains("Ios");
Stream<String> stream = list.stream();//取得Stream类对象
if(stream.anyMatch(p1.or(p2))){
System.out.println("有数据存在!!");
}
}
}
如果想更好的反应出Stream的操作优势,必须结合MapReduce一起使用
Stream提供了一些方法:
- 数据分析方法:public Optional reduce(BinaryOperator accumulator);
下面代码是做简单的统计分析工作,如下:
class ShopCar{
private String pNmae;
private double price;
private int n;
public ShopCar(String pNmae, double price, int n) {
this.pNmae = pNmae;
this.price = price;
this.n = n;
}
public String getpNmae() {
return pNmae;
}
public void setpNmae(String pNmae) {
this.pNmae = pNmae;
}
public double getPrice() {
return price;
}
public void setPrice(double price) {
this.price = price;
}
public int getN() {
return n;
}
public void setN(int n) {
this.n = n;
}
}
public class StreamReduceTest {
public static void main(String[] args) {
List<ShopCar> shopCar = new ArrayList<ShopCar>();
shopCar.add(new ShopCar("娃娃机",23.3,2));
shopCar.add(new ShopCar("娃娃机1",89.3,5));
shopCar.add(new ShopCar("娃娃机2",20.3,7));
shopCar.add(new ShopCar("娃娃机3",27.3,100));
shopCar.add(new ShopCar("娃娃机4",90.3,209));
shopCar.stream().map((x) -> x.getN()*x.getPrice()).forEach(System.out ::println);
}
}
对上面的代码进行求和操作:
如下代码:
class ShopCar{
private String pNmae;
private double price;
private int n;
public ShopCar(String pNmae, double price, int n) {
this.pNmae = pNmae;
this.price = price;
this.n = n;
}
public String getpNmae() {
return pNmae;
}
public void setpNmae(String pNmae) {
this.pNmae = pNmae;
}
public double getPrice() {
return price;
}
public void setPrice(double price) {
this.price = price;
}
public int getN() {
return n;
}
public void setN(int n) {
this.n = n;
}
}
public class StreamReduceTest {
public static void main(String[] args) {
List<ShopCar> shopCar = new ArrayList<ShopCar>();
shopCar.add(new ShopCar("娃娃机",23.3,2));
shopCar.add(new ShopCar("娃娃机1",89.3,5));
shopCar.add(new ShopCar("娃娃机2",20.3,7));
shopCar.add(new ShopCar("娃娃机3",27.3,100));
shopCar.add(new ShopCar("娃娃机4",90.3,209));
//这是得到的总金额
double d = shopCar.stream().map((x) -> x.getN()*x.getPrice()).reduce((sum,m)->sum+m).get();
System.out.println(d);
}
}
上面的代码统计功能过于有限,如做复杂的方法,需要使用Stream接口里面定义的以下方法:
- 按照Double处理:public DoubleStream mapToDouble(ToDoubleFunction<? super T> mapper);
- 按照Int处理:public IntStream mapToInt(ToIntFunction<?SuperT> mapper);
- 按照Long处理:public LongStream mapToInt(ToLongFunction<?SuperT> mapper);
相对比较复杂的统计:
public class StreamReduceTest {
public static void main(String[] args) {
List<ShopCar> shopCar = new ArrayList<ShopCar>();
shopCar.add(new ShopCar("娃娃机",23.3,2));
shopCar.add(new ShopCar("娃娃机1",89.3,5));
shopCar.add(new ShopCar("娃娃机2",20.3,7));
shopCar.add(new ShopCar("娃娃机3",27.3,100));
shopCar.add(new ShopCar("娃娃机4",90.3,209));
DoubleSummaryStatistics d = shopCar.stream().mapToDouble((sc) ->sc.getPrice()*sc.getN()).summaryStatistics();
System.out.println("商品个数:"+d.getCount());
System.out.println("平均花费:"+d.getAverage());
System.out.println("总花费:"+d.getSum());
System.out.println("最高花费:"+d.getMax());
System.out.println("最低花费:"+d.getMin());
}
}
8 JDBC
JDBC是JAVA数据库连接技术(JAVA Database Connection),是数据库操作标准,与数据库平台无关的。
在JDBC技术范畴里面实际上规定了四种JAVA数据库操作的形式:
- JDBC-ODBC桥接技术(很少用)
- JDBC直接连接(由不同的数据库提供商提供对应的数据库连接驱动)性能较高
- JDBC网络连接(使用最多):使用专门的数据库网络连接指令进行指定主机的数据库操作。
- 模拟指定数据的通讯协议,自己编写进行连接
在JAVA之中,所有操作数据库的类和接口都保存在java.sql包里,这个包里面核心的组成: - 一个类:DriverManager类
- 四个接口:Connection、Statement、ResultSet、PreparedStatement
连接数据库操作流程都是固定的,按照如上几步操作:
- 加载数据库的驱动程序
- 进行数据库的连接(DriverManager类、Connection接口)
- 进行数据库接任(Statement、PreparedStatement、ResultSet)
- 关闭数据库操作以及连接(直接关闭连接)。
代码如下:
使用Statement代码如下:
61827707.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2d5c2h1bg==,size_16,color_FFFFFF,t_70)
使用PreparedStatement类操作数据库,如下:
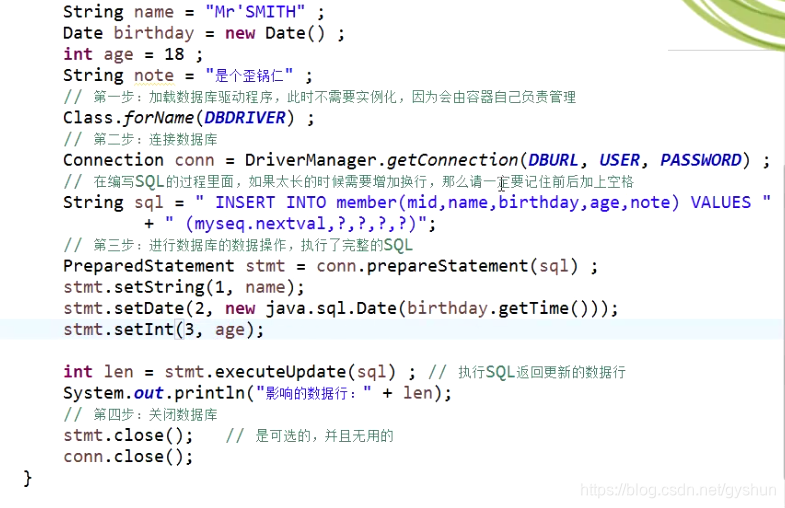
ResultSet结果集的操作,如下:
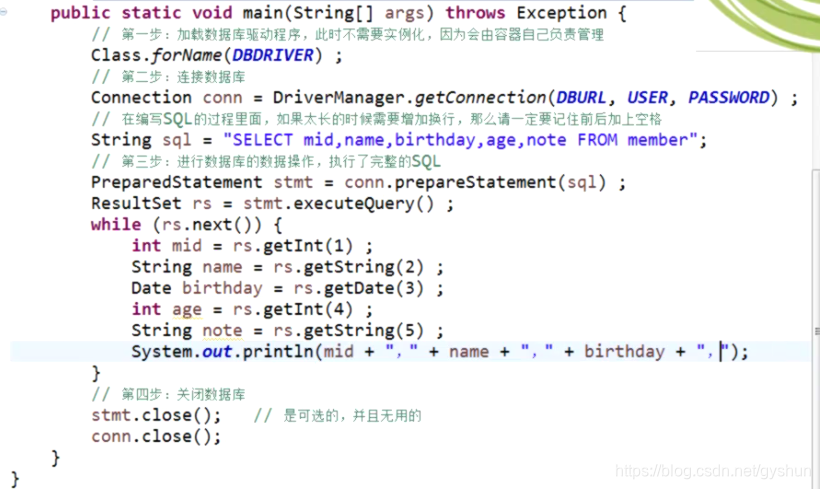
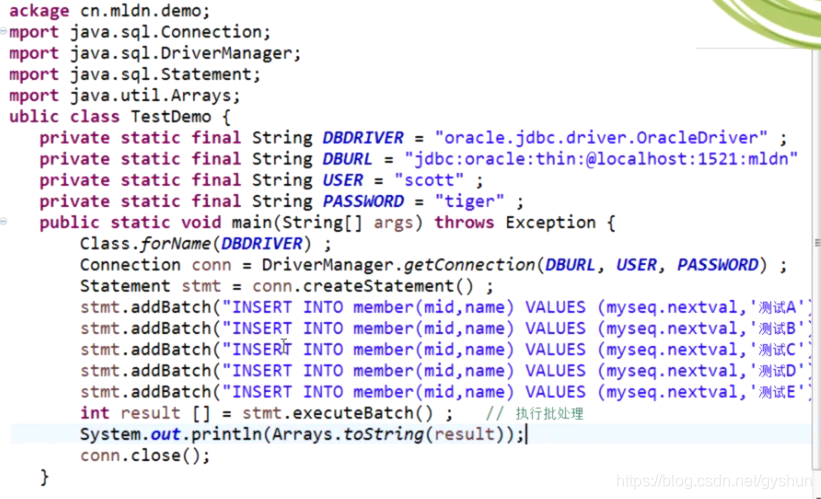
使用批处理的操作:
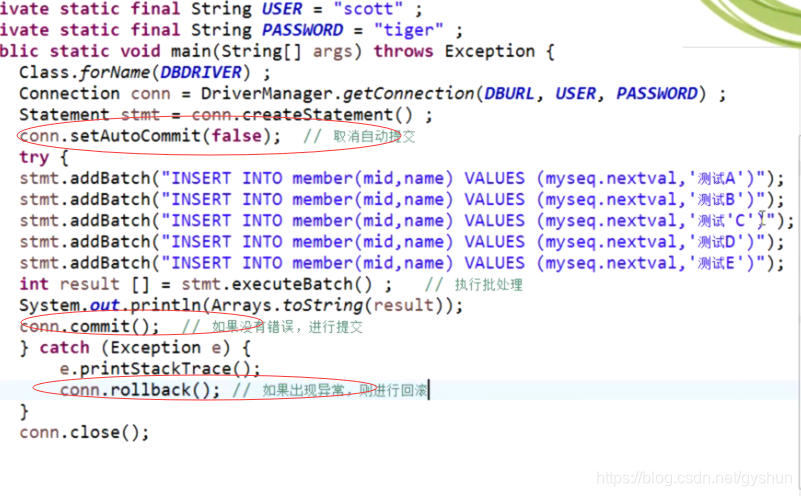
增加事务处理:
总结
批处理对于操作数据库是非常方便
Connection提供了事务处理的方法