版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/firstchange/article/details/84585541
分析算法的意义就是为了预测算法所需要的资源,更通常的说法是为了计算时间复杂度和空间复杂度。
RAM模型
在分析一个算法之前,我们必须有一个要使用的实现技术的模型,包括描述所用资源及其代价的模型。在算法导论中假定了一种通用的单处理器模型——随机访问模型(RAM)。
RAM模型包含真实计算机中常见的指令:算术指令(如加减乘除、取余、上取整、下取整)、数据移动指令(装入、存储、复制)和控制指令(条件与无条件转移、子程序调用与返回)。其中每条这样的指令所需时间都为常量。
但是还有一些计算是RAM模型所没有的,有些计算可能不能在常数时间内处理完成如指数计算。当然从某些角度上看也是可以近似表示的指数计算,如移位运算,通过2k来近似表示幂,从而把指数计算看作是在常数时间内完成的。
采用RAM模型即使分析一个简单的算法也可能非常困难。需要的数学工具可能包括组合学、概率论、代数技巧,以及识别一个公式中最有意义一个项的能力。
插入排序算法的分析
一个算法在特定输入上的运行时间是指执行的基本操作数或步数。我们在研究的过程中进行如下假定,执行每行伪代码需要常量时间,虽然执行时间可能不同。这个观点与RAM模型是一致的,也与在真实计算机中的执行相似。
我们来看看具体的分析过程:

将这些运行时间累加得:
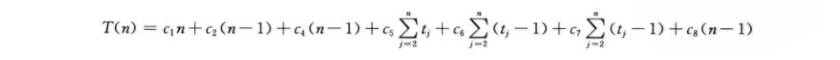
最优情况

最差情况

最坏情况与平均情况分析
- 一个算法的最坏情况所执行的时间是任何输入的运行时间的上界,即改算法的执行时间不会超过此
- 对于某些算法最坏情况经常出现,如一个数据不在数据库中,却需要去search,而且在某些应用中,对于缺失值的检索可能是频繁的
- “平均情况”往往与最坏情况大致是一致的
有时可以用随机化算法,做出一些随机的选择,允许使用期望来表示算法的运行时间。
增长量级
随着输入规模的增长,运行时间会有什么样的变化。因为当n的值很大时,低阶项相对来说并不重要,所以我们在计算时间复杂度时通常关注的是最高阶项,我们也忽略最重要的项的常系数。这样对于插入排序来说,只剩下了n^2,读作”theta n 平方“。
小结
- RAM模型是算法导论计算运行时间的重要前提
- 计算时间复杂度通常考虑最坏运行时间
- 通常对于时间复杂度我们更关心增长量级,所以会忽略低阶项和常系数