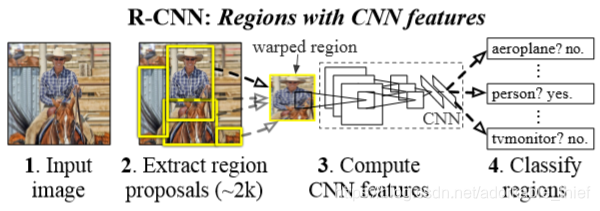
一、R-CNN的三个模块
- 每个图片生成独立类别的 region proposal,这些 proposals 定义了可用于检测器的候选框集合
- 使用大型的卷积神经网络,可以从每个region proposal中提取固定长度的特征向量
- 一组能区分每个类别的线性向量机组
二、测试阶段
1.Region Proposal
论文中提到了很多生成独立类别 region proposal的方法,作者选择了selective search的方法确定2000个region proposal,关于selective proposal的详述,请参照论文《Selective Search for Object Recoginition》,这里简单说明下使用到的区域合并算法:
输入:图片(RGB通道)
输出:目标位置
1.使用《Efficient Graph-Based Image Segmentation》中的方法获取原始分割区域:
2.初始化相似度集合
3.对相邻区域,计算两区域的相似度
,并加入到相似度集合S
4.当相似度集合不为空时(此时集合S内是相邻区域的相似度)
(1) 选相似度最高的区域
(2) 将两个区域合并成一个区域
(3) 从相似度集合S去除与 相邻相似度的集合,从相似度集合S去除与
相邻相似度集合
(4) 计算 与其相邻区域的相似度。
(5) 把 加入到区域集合 R中
5.获取R中每个区域的bbox
2.Feature extraction
从每一个region proposal提取4096维度的特征向量。提取的方法是使用训练好的AlexNet模型,为了能适应网络227227的固定输入,所以需要将每个region proposal调整到这个尺寸。
调整的方法有很多,论文这里使用了最简单的方法。
即对整个区域不保持横纵比缩放到所需要的大小。在缩放之前,首先扩大被缩放区域,让缩放后的区域边界与之前的区域边界相隔p个padding,本文中取的是16个,然后不管图像的大小强制缩小到所需求的尺寸。
3.Test-time detection
之前使用selective search在测试图片上提取了2000个region proposal,然后把每个region proposal归一化到227227尺寸,输入到AlexNet网络中,每个region提取到4096个特征向量,这样有2000
4096维度的特征,再把这些特征向量导入到事先训练好的SVM中,分别对每个类别进行打分,选择分数最高的作为最终预测结果。这时候可能会出现多个bbox,使用NMS对每一类剔除IOU与得分较高的selected region
三、训练阶段
1.Supervised pre-training
使用ILSVRC2012只有图像类别标签,没有图像物体标注的数据集,预先训练好网络模型AlexNet
2.Domain-specific fine-tuning
这一阶段使用既有图像中物体的类别标签,又有图像物体的位置的PASCAL VOC 2012数据集,针对AlexNet网络进行一些微调,将原来1000个类别的输出换成21个类别(20个类和1个背景),选择学习率为0.001,每一个mini-batch包含有32个正样本和96个副样本。通过每个region proposal与ground-truth box的IOU来判断正负样本,如果IOU大于等于0.5就是正样本,反之为负样本。总的来说就是为了训练AlexNet网络的参数。
3.Object category classifiers
在训练线性SVM前,需要划分正负样本。包含在ground-truth box内的region proposal作为正样本,完全不包含在ground-truth box的region proposal作为负样本,同时设定阈值,对ground-truth box 与 region proposal的 IOU<0.3 的也作为负样本,剩余的全部丢弃。然后针对每一个类别训练一个线性的SVM分类器。然而这会带来一个问题就是,正样本数量相对于负样本数量会少很多,于是作者采用了standard hard negative mining method 的方式训练。简单解释下就是在训练过程中,有一些得分很高的false positive,这就是所说的hard negative,分类器会误判这些hard negative,那么简单的方法就是把这些拿出来再训练一次。
读到这里,很不清楚为什么不采用CNN进行分类,还有为什么重新设定了IOU的阈值。这在附录中解释基本上都是从实验结果做出的改善。
4.Bounding-box regression
设第 i 个region proposal ,其中前量两个表示中点坐标,后两个分别表示宽和高,为简单起见,后面就不考虑上标 i了。ground-truth box的数学表达式:
,所以现在我们希望能学习一种转化方式,可以将 P 映射到 G
映射d关系如下:
设表示
中的一种,在AlexNet的pool5层,抽象整个线性关系为:
这里的是Proposal的特征向量,其中
就是要学习的回归参数。
因此损失函数为:
上述的损失函数有个参数t,定义如下:
这里做一个总的说明,来描述上面函数式表达的意思,首先分别表示region proposal box,ground-truth box,bounding box
函数关系式的目的式寻找到一个映射d,使:
简单来就是让P经过一个平移或者缩放过程得到:
(1)(2)式子代表平移,(3)(4)代表缩放,现在的问题式如何得到映射关系d,因此定义(6)式的loss函数,这里的 t 表示原始P与真正的结果G之间的偏移值,如(7)(8)(9)(10)式