目录
xpath如何取包含多个class属性如果HTML结构是这样
通过打开页面,打开xpath,可以直接复制下来!!谷歌十分nice的体验。
通过class调用:
resp.xpath("//*[@class='otherName']//text()").extract()
通过xpath:
resp.xpath("/html/body/div[3]/div/div[3]/span/em//text()").extract()
使用谷歌直接复制xpath:
优点:十分方便快捷,可以直接定位,不需要再选择class。
缺点:如果页面结构改变,那么可能会报错或者获取不了,是十分不稳定的。
方法:打开页面——右键——复制——复制xpath——直接塞代码使用。
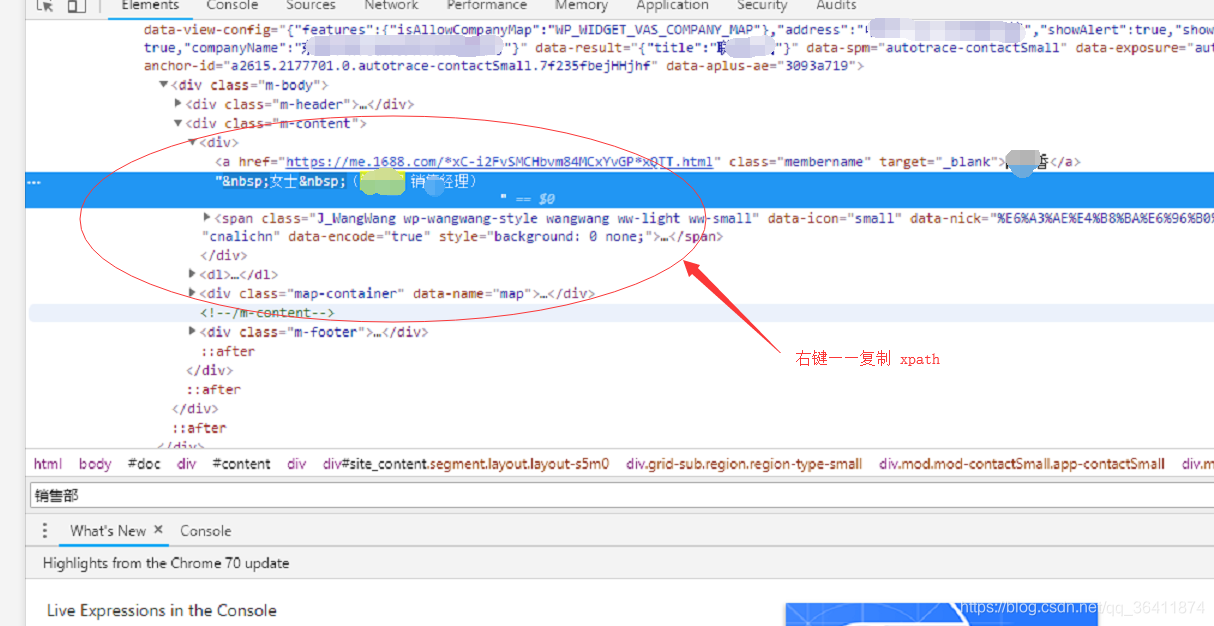
有空可以研究下chrome的api,这个东西很好玩的,看了下,pyppeteer其实调用的chromeapi应该就是这个东西.

代码例子:
#coding:utf-8
from scrapy.selector import Selector
from scrapy.http import HtmlResponse
import requests
import re
import urllib.request
def fecth(target):
print("target:"+target)
# 得到这个url下的内容content,应该是二进制的
html = requests.get(target).content
# 实例化 response 对象
resp = HtmlResponse(url=target, body=html)
# 获取公司名字
company = resp.xpath("//*[@class='otherName']//text()").extract()
#取出中文
company_name = company[0].replace("\n", "").replace("\r", "")
print('公司名称:'+company_name)
# 获取公司联系电话
try:
#当不需要点击按钮的时候
pythone = resp.xpath("/html/body/div[3]/div/div[3]/span/em//text()").extract()
if len(pythone) > 0:
company_pythone = pythone[0].replace("\n", "").replace("\r", "")
print('公司联系电话:' + company_pythone)
except Exception as e:
print(e)
try:
# 当需要点击按钮的时候
pythone_button_name = resp.xpath("//*[@class='popContact']//text()").extract()
for i in range(1,len(pythone_button_name)):
print(pythone_button_name[i])
except Exception as e:
print(e)
# 获取公司联系人
try:
contact = resp.xpath("/html/body/div[8]/div[1]/div[3]/ul/li[1]/p//text()").extract()
contact_people = contact[0].replace("\n", "").replace("\r", "")
print('公司联系人:'+contact_people)
except Exception as e:
print(e)
# 主营产品
products = resp.xpath("/html/body/div[8]/div[1]/div[1]/ul/li[4]//text()").extract()
#从3开始遍历,提取所有数据
num=3
#输出所有数据
for i in range(num,len(products)):
print(products[i])
#根据主页,获取所有地址
def seachWeb(target):
print(target)
html1=urllib.request.urlopen(target).read()
html1=str(html1)
print(html1)
pat1='<div class="productShowGrid".+? <input type="text" id="pageNum" value="1" style="display:none">'
result1=re.compile(pat1).findall(html1)
result1=result1[0]
print(result1)
if __name__ == "__main__":
fecth("http://product.qihuiwang.com/389883550.html")
输出结果:

xpath如何取包含多个class属性
如果HTML结构是这样
<div class="demo"></div>
那么我知道可以写xpath //div[@class="demo"],但是如果我的html是
<div class="test demo"></div>
<div class="demo test"></div>
<div class="test demo2"></div>
我只想选出有demo这个class的对象,那应该怎么弄?
要取多个class属性值的元素,应该如何办呢;
如:
<div class='a b'>test</div>
如果是用xpath('//div[@class="a"]') 会取不到这里面的值;
可以用如下的表达式:
xpath('//div[contains(@class,"a")]') #它会取得所有class为a的元素
或者
xpath('//div[contains(@class,"a") and contains(@class,"b")]') #它会取class同时有a和b的元素
关于上面的问题,如果没记错的话可以这么来:
//div[contains(@class, 'demo')]
如果标签是多个则可以,other是代指元素:
//div[contains(@class, 'demo') and contains(@class, 'other')]
如果目标 class 不一定是第一个,那么:
//div[contains(concat(' ', @class, ' '), 'demo')]
顺便一提,用 Jetbrains 家的 IDE,里面有内置的 xpath 规则生成器。
参考文章链接:http://www.365jz.com/article/24244