目录
本篇文章记录用户访问session分析-数据倾斜解决方案之sample采样倾斜key单独进行join。
思路解析
关键之处在于,将发生数据倾斜的key,单独拉出来,放到一个RDD中去,
就用这个原本会倾斜的key RDD跟其他RDD,单独去join一下,这个时候,key对应的数据,可能就会分散到多个task中去进行join操作。 就不至于说是,这个key跟之前其他的key混合在一个RDD中时,肯定是会导致一个key对应的所有数据,都到一个task中去,就会导致数据倾斜。

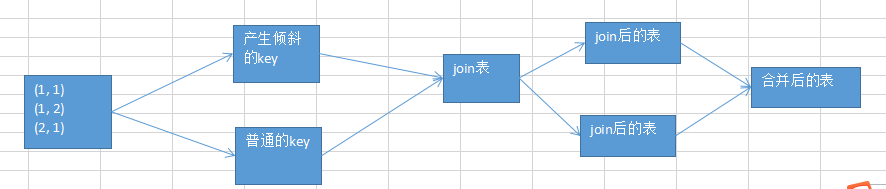

这种方案什么时候适合使用?
优先对于join,肯定是希望能够采用上一讲讲的,reduce join转换map join。两个RDD数据都比较大,那么就不要那么搞了。 针对你的RDD的数据,你可以自己把它转换成一个中间表,或者是直接用countByKey()的方式,你可以看一下这个RDD各个key对应的数据量;
此时如果发现整个RDD就一个,或者少数几个key,是对应的数据量特别多;建议,比如就是一个key对应的数据量特别多。 此时可以采用这种方案,单独拉出来那个对应values最多的key,进行单独进行join,尽可能地将key分散到各个task上去进行join操作。
什么时候不适用呢?
如果一个RDD中,导致数据倾斜的key,特别多,那么此时,最好还是不要这样了;还是使用我们最后一个方案,终极的join数据倾斜的解决方案。
/** * sample采样倾斜key单独进行join */ //对userid2PartAggrInfoRDD进行采样 JavaPairRDD<Long, String> sampledRDD = userid2PartAggrInfoRDD.sample(false, 0.1, 9); //对采样出来的的数据进行mapToPair操作,转换为<key,1l>,方便计数 JavaPairRDD<Long, Long> mappedSampledRDD = sampledRDD.mapToPair( new PairFunction<Tuple2<Long,String>, Long, Long>() { private static final long serialVersionUID = 1L; @Override public Tuple2<Long, Long> call(Tuple2<Long, String> tuple) throws Exception { return new Tuple2<Long, Long>(tuple._1, 1L); } }); //对采样出来的数据对每个key进行计数 JavaPairRDD<Long, Long> computedSampledRDD = mappedSampledRDD.reduceByKey( new Function2<Long, Long, Long>() { private static final long serialVersionUID = 1L; @Override public Long call(Long v1, Long v2) throws Exception { return v1 + v2; } }); //为了方便排序,将tuple进行转换为<values,key>,通过values对key进行排序 JavaPairRDD<Long, Long> reversedSampledRDD = computedSampledRDD.mapToPair( new PairFunction<Tuple2<Long,Long>, Long, Long>() { private static final long serialVersionUID = 1L; @Override public Tuple2<Long, Long> call(Tuple2<Long, Long> tuple) throws Exception { return new Tuple2<Long, Long>(tuple._2, tuple._1); } }); //对采样结果进行排序,选出最可能出现数据倾斜的key来 final Long skewedUserid = reversedSampledRDD.sortByKey(false).take(1).get(0)._2; //通过随机数将数据倾进行拆分 //产生数据倾斜的数据集 JavaPairRDD<Long, String> skewedRDD = userid2PartAggrInfoRDD.filter( new Function<Tuple2<Long,String>, Boolean>() { private static final long serialVersionUID = 1L; @Override public Boolean call(Tuple2<Long, String> tuple) throws Exception { return tuple._1.equals(skewedUserid); } }); //其他没有产生数据倾斜的数据集 JavaPairRDD<Long, String> commonRDD = userid2PartAggrInfoRDD.filter( new Function<Tuple2<Long,String>, Boolean>() { private static final long serialVersionUID = 1L; @Override public Boolean call(Tuple2<Long, String> tuple) throws Exception { return !tuple._1.equals(skewedUserid); } }); //产生数据倾斜的数据和userid2InfoRDD进行join JavaPairRDD<String, Row> joinedRDD1= skewedRDD.join(userid2InfoRDD); //没有产生数据倾斜的数据和userid2InfoRDD进行join JavaPairRDD<Long, Tuple2<String, Row>> joinedRDD2 = commonRDD.join(userid2InfoRDD); //将两个join的数据进行合并 JavaPairRDD<Long, Tuple2<String, Row>> joinedRDD = joinedRDD1.union(joinedRDD2); JavaPairRDD<String, String> sessionid2FullAggrInfoRDD = joinedRDD.mapToPair( new PairFunction<Tuple2<Long,Tuple2<String,Row>>, String, String>() { private static final long serialVersionUID = 1L; @Override public Tuple2<String, String> call( Tuple2<Long, Tuple2<String, Row>> tuple) throws Exception { String partAggrInfo = tuple._2._1; Row userInfoRow = tuple._2._2; String sessionid = StringUtils.getFieldFromConcatString( partAggrInfo, "\\|", Constants.FIELD_SESSION_ID); int age = userInfoRow.getInt(3); String professional = userInfoRow.getString(4); String city = userInfoRow.getString(5); String sex = userInfoRow.getString(6); String fullAggrInfo = partAggrInfo + "|" + Constants.FIELD_AGE + "=" + age + "|" + Constants.FIELD_PROFESSIONAL + "=" + professional + "|" + Constants.FIELD_CITY + "=" + city + "|" + Constants.FIELD_SEX + "=" + sex; return new Tuple2<String, String>(sessionid, fullAggrInfo); } });
优化的一个操作
对于那个key,从另外一个要join的表中,也过滤出来一份数据,比如可能就只有一条数据。userid2infoRDD,一个userid key,就对应一条数据。 然后呢,采取对那个只有一条数据的RDD,进行flatMap操作,打上100个随机数,作为前缀,返回100条数据。 单独拉出来的可能产生数据倾斜的RDD,给每一条数据,都打上一个100以内的随机数,作为前缀。 再去进行join,是不是性能就更好了。肯定可以将数据进行打散,去进行join。join完以后,可以执行map操作,去将之前打上的随机数,给去掉,然后再和另外一个普通RDD join以后的结果,进行union操作。
/** * sample采样倾斜key单独进行join */ //对userid2PartAggrInfoRDD进行采样 JavaPairRDD<Long, String> sampledRDD = userid2PartAggrInfoRDD.sample(false, 0.1, 9); //对采样出来的的数据进行mapToPair操作,转换为<key,1l>,方便计数 JavaPairRDD<Long, Long> mappedSampledRDD = sampledRDD.mapToPair( new PairFunction<Tuple2<Long,String>, Long, Long>() { private static final long serialVersionUID = 1L; @Override public Tuple2<Long, Long> call(Tuple2<Long, String> tuple) throws Exception { return new Tuple2<Long, Long>(tuple._1, 1L); } }); //对采样出来的数据对每个key进行计数 JavaPairRDD<Long, Long> computedSampledRDD = mappedSampledRDD.reduceByKey( new Function2<Long, Long, Long>() { private static final long serialVersionUID = 1L; @Override public Long call(Long v1, Long v2) throws Exception { return v1 + v2; } }); //为了方便排序,将tuple进行转换为<values,key>,通过values对key进行排序 JavaPairRDD<Long, Long> reversedSampledRDD = computedSampledRDD.mapToPair( new PairFunction<Tuple2<Long,Long>, Long, Long>() { private static final long serialVersionUID = 1L; @Override public Tuple2<Long, Long> call(Tuple2<Long, Long> tuple) throws Exception { return new Tuple2<Long, Long>(tuple._2, tuple._1); } }); //对采样结果进行排序,选出最可能出现数据倾斜的key来 final Long skewedUserid = reversedSampledRDD.sortByKey(false).take(1).get(0)._2; //通过随机数将数据倾进行拆分 //产生数据倾斜的数据集 JavaPairRDD<Long, String> skewedRDD = userid2PartAggrInfoRDD.filter( new Function<Tuple2<Long,String>, Boolean>() { private static final long serialVersionUID = 1L; @Override public Boolean call(Tuple2<Long, String> tuple) throws Exception { return tuple._1.equals(skewedUserid); } }); //其他没有产生数据倾斜的数据集 JavaPairRDD<Long, String> commonRDD = userid2PartAggrInfoRDD.filter( new Function<Tuple2<Long,String>, Boolean>() { private static final long serialVersionUID = 1L; @Override public Boolean call(Tuple2<Long, String> tuple) throws Exception { return !tuple._1.equals(skewedUserid); } }); //将userid2InfoRDD的数据的进行加上随机数前缀打散 JavaPairRDD<String, Row> skewedUserid2infoRDD = userid2InfoRDD.filter( new Function<Tuple2<Long,Row>, Boolean>() { private static final long serialVersionUID = 1L; @Override public Boolean call(Tuple2<Long, Row> tuple) throws Exception { return tuple._1.equals(skewedUserid); } }).flatMapToPair(new PairFlatMapFunction<Tuple2<Long,Row>, String, Row>() { private static final long serialVersionUID = 1L; @Override public Iterator<Tuple2<String, Row>> call( Tuple2<Long, Row> tuple) throws Exception { Random random = new Random(); List<Tuple2<String, Row>> list = new ArrayList<Tuple2<String, Row>>(); for(int i = 0; i < 100; i++) { int prefix = random.nextInt(100); list.add(new Tuple2<String, Row>(prefix + "_" + tuple._1, tuple._2)); } return list.iterator(); } }); //将产生数据倾斜的数据加上随机数前缀进行打散 JavaPairRDD<Long, Tuple2<String, Row>> joinedRDD1 = skewedRDD.mapToPair( new PairFunction<Tuple2<Long,String>, String, String>() { private static final long serialVersionUID = 1L; @Override public Tuple2<String, String> call(Tuple2<Long, String> tuple) throws Exception { Random random = new Random(); int prefix = random.nextInt(100); return new Tuple2<String, String>(prefix + "_" + tuple._1, tuple._2); } //将skewedRDD和skewedUserid2infoRDD }).join(skewedUserid2infoRDD).mapToPair( new PairFunction<Tuple2<String,Tuple2<String,Row>>, Long, Tuple2<String, Row>>() { private static final long serialVersionUID = 1L; @Override public Tuple2<Long, Tuple2<String, Row>> call( Tuple2<String, Tuple2<String, Row>> tuple) throws Exception { long userid = Long.valueOf(tuple._1.split("_")[1]); return new Tuple2<Long, Tuple2<String, Row>>(userid, tuple._2); } }); JavaPairRDD<Long, Tuple2<String, Row>> joinedRDD2 = commonRDD.join(userid2InfoRDD); JavaPairRDD<Long, Tuple2<String, Row>> joinedRDD = joinedRDD1.union(joinedRDD2); JavaPairRDD<String, String> sessionid2FullAggrInfoRDD = joinedRDD.mapToPair( new PairFunction<Tuple2<Long,Tuple2<String,Row>>, String, String>() { private static final long serialVersionUID = 1L; @Override public Tuple2<String, String> call( Tuple2<Long, Tuple2<String, Row>> tuple) throws Exception { String partAggrInfo = tuple._2._1; Row userInfoRow = tuple._2._2; String sessionid = StringUtils.getFieldFromConcatString( partAggrInfo, "\\|", Constants.FIELD_SESSION_ID); int age = userInfoRow.getInt(3); String professional = userInfoRow.getString(4); String city = userInfoRow.getString(5); String sex = userInfoRow.getString(6); String fullAggrInfo = partAggrInfo + "|" + Constants.FIELD_AGE + "=" + age + "|" + Constants.FIELD_PROFESSIONAL + "=" + professional + "|" + Constants.FIELD_CITY + "=" + city + "|" + Constants.FIELD_SEX + "=" + sex; return new Tuple2<String, String>(sessionid, fullAggrInfo); } });