Abstract
• 为了提高聚类性能和保持聚类结果的稳定性,提出了一种算法同时学习相似度矩阵和聚类结构;
• 通过自适应地分配数据的模糊邻域,来确定数据的模糊相似度,从而确定数据的谱聚类结构,以及保证聚类稳定性。
1. INTRODUCTION
• 为了使谱聚类结果有效、稳定,需要一个合适的affinity matrix;
2. SPECTRAL CLUSTERING AND DI-FCM
A. Normalized Cut(NC)
B. DI-FCM
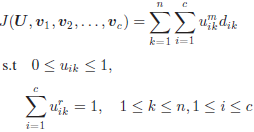
• 相较于FCM,多了一个模糊指数r在约束条件中,具有基于熵的物理意义,可以拓展模糊指数m的范围并且降低FCM对噪声的敏感性;
• 当c=n,m=1,DI-FCM可以被用来确定数据的相似度矩阵。
3. JOINT LEARNING OF SPECTRAL CLUSTERING STRUCTURE AND FUZZY SIMILARITY MATRIX OF DATA
A. Theoretical Motivation
• 传统的谱聚类算法中,相似度学习和获得数据的聚类结构是两个分开的过程,不能同时得到两者的最优解。FSCM是两者同时学习的;
• 相似度矩阵的约束有模糊指数r,是基于熵的约束;
• 拉普拉斯矩阵的秩约束,使相似度矩阵的连通分量恰好等于簇的个数。
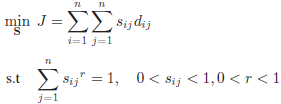
• 该约束可以获得两条特性:一个是模糊相似度矩阵的稀疏性,这有利于谱聚类;另一个是很强的解释性。