(还在更新中…) 这篇博客花费了我的大量时间和精力,从创作到维护;若认可本篇博客,希望给一个点赞、收藏
并且,遇到了什么问题,请在评论区留言,我会及时回复的
这本书对Python的知识点的描述很详细,而且排版看的很舒服
- 几个例题: 假装自己从零开始学,将一些有代表性、有意思的例题抽取出来
- 部分复习题: 遇到有意思的复习题,我会拿出来,并且进行分析
- 上机实践: 全部上机实践题的解题思路
文章目录
第一章 Python概述
几个例题
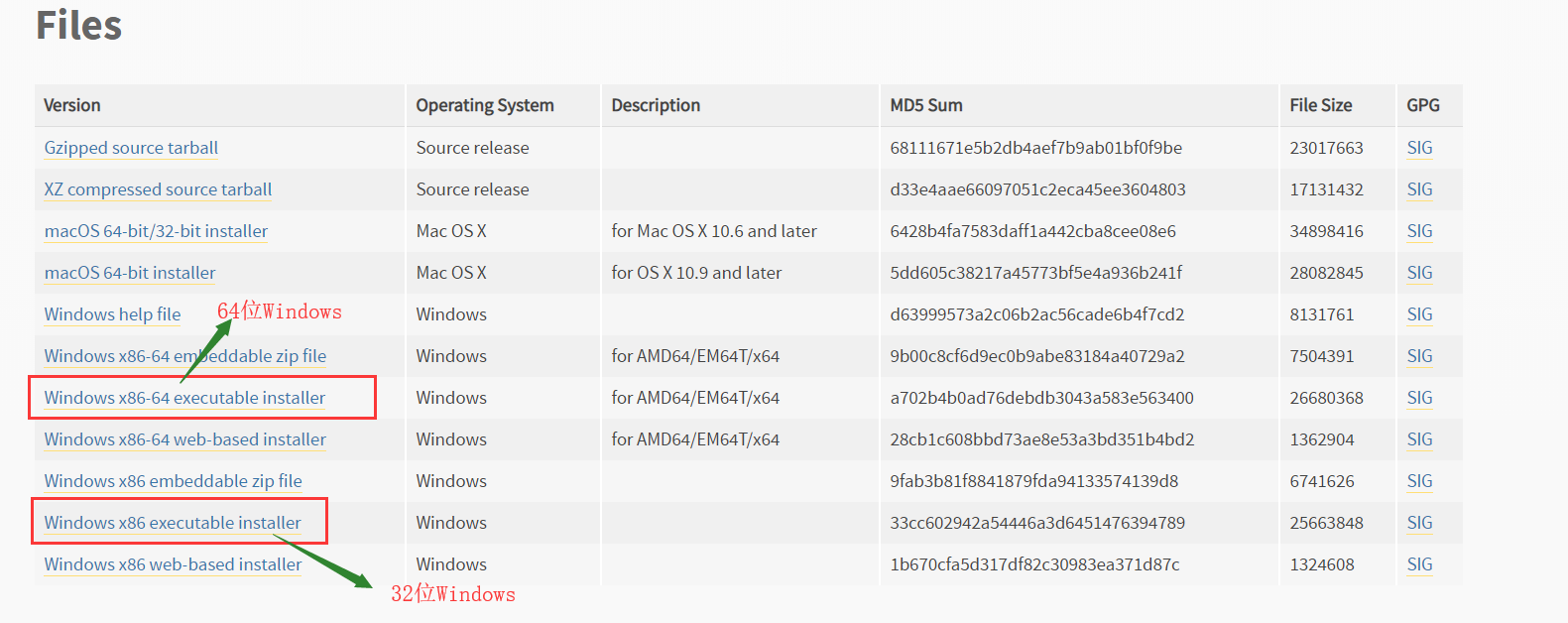
一:Python3.7.4下载
python3.7.4下载地址:https://www.python.org/downloads/release/python-374/
页面最下面:
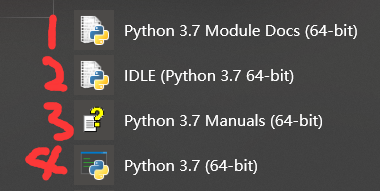
下载,安装完python后:出现的四个玩意:Python 3.7 Module Docs,IDLE,Python 3.7 Manuals,Python 3.7(64-bit)
-
Python 3.7 Module Docs(64-bit)
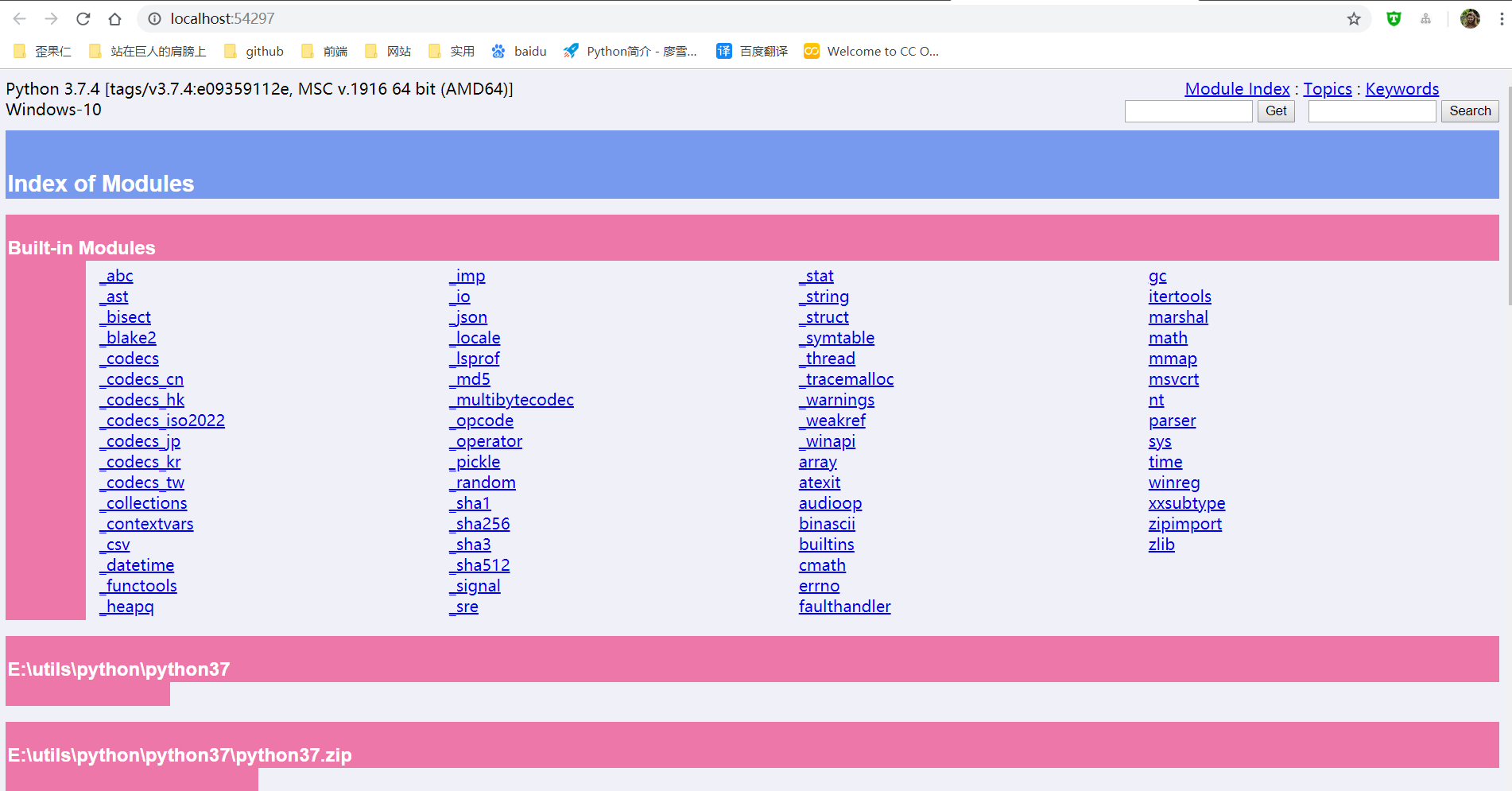
点击之后,会出现一个网页(将我下载的Python3.7.4文件夹中包含的模块都列了出来,页面不止这么点,还可以往下拉)
-
IDLE(Python 3.7 64-bit)
一个Python编辑器,Python内置的集成开发工具
-
Python 3.7 Manuals(64-bit)
Python 3.7 开发手册 -
Python 3.7(64-bit)
控制台中运行Python
二:更新pip和setuptools包,安装NumPy包,安装Matplotlib包
以下三个命令都是在控制台(windows中的cmd)中运行
更新pip和setuptools包
- pip用于安装和管理Python扩展包
- setuptools用于发布Python包
python -m pip install -U pip setuptools
安装NumPy
Python扩展模块NumPy提供了数组和矩阵处理,以及傅立叶变换等高效的数值处理功能
python -m pip install NumPy
安装Matplotlib包
Matplotlib是Python最著名的绘图库之一,提供了一整套和MATLAB相似的命令API,既适合交互式地进行制图,也可以作为绘图控件方便地嵌入到GUI应用程序中
python -m pip install Matplotlib
三:使用IDLE打开和执行Python源文件程序
首先:
有一个.py文件test.py

使用IDLE打开.py文件的两种方式:
- 右键test.py---->Edit With IDLE---->Edit With IDLE 3.7(64-bit)
- 打开IDLE,然后File---->Open(或者
ctrl+O)选择.py文件
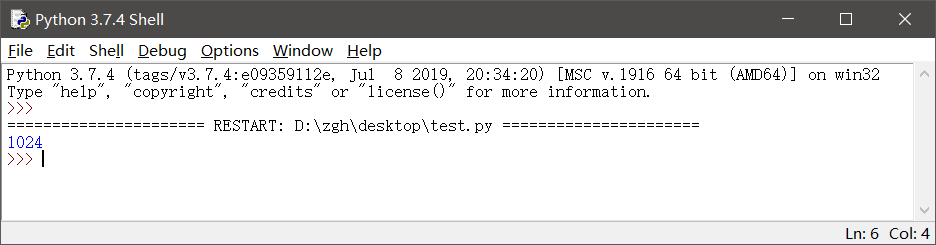
运行
Run---->Run Module(或者F5)
就会出现这个界面,执行结果显示在这个界面中
补充一点:
如果在IDLE中编辑.py文件,记得修改后要保存(ctrl+s),再运行(F5)
四:使用资源管理器运行hello.py
hello.py文件在桌面
import random
print("hello,Python")
print("你今天的随机数字是:",random.choice(range(10)))#输出在0-9之间随机选择的整数
input()
- 在桌面打开PowerShell(还有两种输入方式:
python hello.py或者.\hello.py)
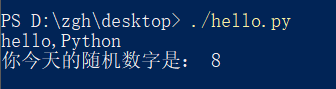
- 或者在桌面打开cmd, 就输入
hello.py或者python hello.py
补充:上述两种命令中的hello.py都是相对路径,因为文件在桌面,而且我是在桌面打开cmd,所以文件路劲可以这么简简单单的写。如果文件存储位置和cmd打开位置不一样,请使用绝对路径
五:命令行参数示例hello_argv.py
hello_argv.py文件在桌面
import sys
print("Hello,",sys.argv[1])
#这样写也行:
#print("Hello,"+sys.argv[1])
- 在桌面打开PowerShell(还有两种输入方式:
python hello_argv.py 任意输入或者./hello_argv.py 任意输入)

- 或者在桌面打开cmd,就输入
hello_argv.py 任意输入或者python hello_argv.py 任意输入
补充:以图中第一个命令举例,hello_argv.py即sys.argv[0];Python即sys.argv[1]
第二章 Python语言基础
选择题:1、3、7、8
1. 在Python中,以下标识符合法的是
| A. _ | B. 3C | C. it’s | B. str |
|---|
答案:A
- 标识符的第一个字符必须是字母,下划线(_);其后的字符可以是字母、下划线或数字。
- 一些特殊的名称,作为python语言的保留关键字,不能作为标识符
- 以双下划线开始和结束的名称通常具有特殊的含义。例如
__init__为类的构造函数,一般应避免使用
B:以数字开头,错误
C:使用了',不是字母、下划线或数字
D:str是保留关键字
3. 在下列Python语句中非法的是
| A. x = y =1 | B. x = (y =1) | C. x,y = y,x | B. x=1;y=1 |
|---|
答案:B,C
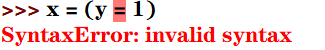

7. 为了给整型变量x,y,z赋初值10,下面Python赋值语句正确的是
| A. xyz=10 | B. x=10 y=10 z=10 | C. x=y=z=10 | B. x=10,y=10,z=10 |
|---|
答案:C
- 分号
;用于在一行书写多个语句- python支持链式赋值
A:赋值对象是xyz
B:分号;用于在一行书写多个语句,而不是' '(即空格)
D:分号;用于在一行书写多个语句,而不是,
8. 为了给整型变量x,y,z赋初值5,下面Python赋值语句正确的是
| A. x=5;y=5;z=5 | B. xyz=5 | C. x,y,z=10 | B. x=10,y=10,z=10 |
|---|
答案:A
Pytho能支持序列解包赋值,但是变量的个数必须与序列的元素个数一致,否则会报错
B:赋值对象是xyz
C:序列解包赋值,变量的个数必须与序列的元素个数一致,否则会报错
D:分号;用于在一行书写多个语句,而不是,
思考题:9
9.下列Python语句的输出结果是
def f():pass
print(type(f()))
结果:<class 'NoneType'>
NoneType数据类型包含唯一值None,主要用于表示空值,如没有返回值的函数的结果
上机实践:2~6
2. 编写程序,输入本金、年利率和年数,计算复利(结果保留两位小数)
money = int(input("请输入本金:"))
rate = float(input("请输入年利率:"))
years = int(input("请输入年数:"))
amount = money*((1+rate/100)**years)
print(str.format("本金利率和为:{0:2.2f}",amount))
运行:
请输入本金:1000
请输入年利率:6.6
请输入年数:10
本金利率和为:1894.84
3. 编写程序,输入球的半径,计算球的表面积和体积(结果保留两位小数)
import math
r = float(input("请输入球的半径:"))
area = 4 * math.pi * r**2
volume = 4/3*math.pi*r**3
print(str.format("球的表面积为:{0:2.2f},体积为:{1:2.2f}",area,volume))
运行:
请输入球的半径:666
球的表面积为:5573889.08,体积为:1237403376.70
4. 编写程序,声明函数getValue(b,r,n),根据本金b,年利率r和年数n计算最终收益v
money = int(input("请输入本金:"))
rate = float(input("请输入年利率(<1):"))
years = int(input("请输入年数:"))
def getValue(b,r,n):
return b*(1+r)**n
print(str.format("本金利率和为:{0:2.2f}",getValue(money,rate,years)))
运行:
请输入本金:10000
请输入年利率(<1):0.6
请输入年数:6
本金利率和为:167772.16
5. 编写程序,求解一元二次方程x2-10x+16=0
from math import sqrt
x = (10+sqrt(10*10-4*16))/2
y = (10-sqrt(10*10-4*16))/2
print(str.format("x*x-10*x+16=0的解为:{0:2.2f},{1:2.2f}",x,y))
运行:
x*x-10*x+16=0的解为:8.00,2.00
6. 编写程序,提示输入姓名和出生年份,输出姓名和年龄
import datetime
sName = str(input("请输入您的姓名:"))
birthday = int(input("请输入您的出生年份:"))
age = datetime.date.today().year - birthday
print("您好!{0}。您{1}岁。".format(sName,age))
运行:
请输入您的姓名:zgh
请输入您的出生年份:1999
您好!zgh。您20岁。
案例研究:使用Pillow库处理图像文件
https://blog.csdn.net/Zhangguohao666/article/details/102060722
通过此案例,进一步了解Python的基本概念:模块、对象、方法和函数的使用
第三章 程序流程控制
几个例题
一:编程判断某一年是否为闰年
闰年:年份能被4整除但不能被100整除,或者可以被400整除。
口诀:四年一闰,百年不闰,四百必闰
代码一:
y = int(input("请输入要判断的年份:"))
if((y % 4 == 0 and y % 100 != 0) or y % 400 == 0):
print("是闰年")
else:
print("不是闰年")
代码二(使用calendar模块的isleap()函数来判断):
from calendar import isleap
y = int(input("请输入要判断的年份:"))
if(isleap(y)):print("闰年")
else:print("不是闰年")
二:利用嵌套循环打印九九乘法表
九九乘法表:
for i in range(1,10):
s = ""
for j in range(1,10):
s += str.format("%d * %d = %02d " %(i, j, i*j))
print(s)
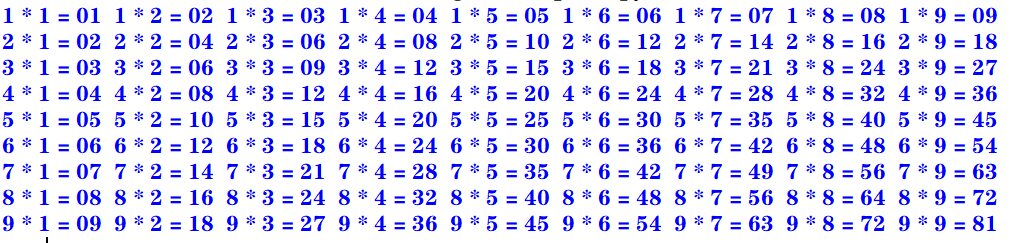
下三角:
for i in range(1,10):
s = ""
for j in range(1,i+1):
s += str.format("%d * %d = %02d " %(i, j, i*j))
print(s)
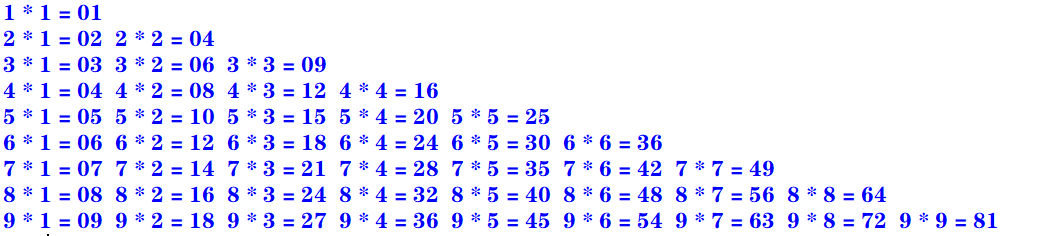
上三角:
for i in range(1,10):
s = ""
for k in range(1,i):
s += " "
for j in range(i,10):
s += str.format("%d * %d = %02d " %(i, j, i*j))
print(s)

三:enumerate()函数和下标元素循环示例
Python语言中的for循环直接迭代对象集合中的元素,如果需要在循环中使用索引下标访问集合元素,则可以使用内置的enumerate()函数
enumerate()函数用于将一个可遍历的数据对象(例如列表、元组或字符串)组合为一个索引序列,并返回一个可迭代对象,故在for循环当中可直接迭代下标和元素
seasons = ["Spring","Summer","Autumn","Winter"]
for i,s in enumerate(seasons,start=1): #start默认从0开始
print("第{0}个季节:{1}".format(i,s))
运行:
第1个季节:Spring
第2个季节:Summer
第3个季节:Autumn
第4个季节:Winter
四:zip()函数和并行循环示例
如果需要并行遍历多个可迭代对象,则可以使用Python的内置函数zip()
zip()函数将多个可迭代对象中对应的元素打包成一个个元组,然后返回一个可迭代对象。如果元素的个数不一致,则返回列表的长度与最短的对象相同。
利用运算符*还可以实现将元组解压为列表
evens = [0,2,4,6,8]
odds = [1,3,5,7,9]
for e,o in zip(evens,odds):
print("{0} * {1} = {2}".format(e,o,e*o))
运行:
0 * 1 = 0
2 * 3 = 6
4 * 5 = 20
6 * 7 = 42
8 * 9 = 72
五:map()函数和循环示例
如果需要遍历可迭代对象,并使用指定函数处理对应的元素,则可以使用Python的内置函数map()
map(func,seq1[,seq2,...])
- func作用于seq中的每一个元素,并将所有的调用结果作为可迭代对象返回。
- 如果func为None,该函数的作用等同于zip()函数
计算绝对值:
>>> list(map(abs, [-1, 0, 7, -8]))
[1, 0, 7, 8]
计算乘幂:
>>> list(map(pow, range(5), range(5)))
[1, 1, 4, 27, 256]
计算ASCII码:
>>> list(map(ord, 'zgh'))
[122, 103, 104]
字符串拼接(使用了匿名函数lambda):
>>> list(map(lambda x, y: x+y, 'zgh', '666'))
['z6', 'g6', 'h6']
选择题:1、2、3
1. 下面的Python循环体的执行次数与其他不同的是
A.
i = 0
while(i <= 10):
print(i)
i = i + 1
B.
i = 10
while(i > 0):
print(i)
i = i - 1
C.
for i in range(10):
print(i)
D.
for i in range(10,0,-1):
print(i)
答案:A
A:[0,10] 执行11次
B:[10,1] 执行10次
C:[0,9) 执行10次
D:[10,0) 执行10次
2. 执行下列Python语句将产生的结果是
x = 2; y = 2.0
if(x == y): print("Equal")
else: print("Not Equal")
| A. Equal | B. Not Equal | C. 编译错误 | D. 运行时错误 |
|---|
答案:A
Python中的自动类型转换:
- 自动类型转换注意针对Number数据类型来说的
- 当2个不同类型的数据进行运算的时候,默认向更高精度转换
- 数据类型精度从低到高:bool int float complex
- 关于bool类型的两个值:True 转化成整型是1;False 转化成整型是0
int类型的2转化为float类型的2.0
3. 执行下列Python语句将产生的结果是
i= 1
if(i): print(True)
else: print(False)
| A. 输出1 | B. 输出True | C. 输出False | D. 编译错误 |
|---|
答案:B
在Python中,条件表达式最后被评价为bool值True或False。
如果表达式的结果为数值类型(0),空字符串(""),空元组(()),空列表([]),空字典({}),其bool值为False,否则其bool值为True
填空题:6
6. 要使语句for i in range(_,-4,-2)循环执行15次,则循环变量i的初值应当为
答案:26
>>> a = 0
>>> for i in range(26, -4, -2): a+=1
>>> print(a)
15
这种题目有一个规律:for i in range(x,y,z):
若循环中没有break或者continue语句,
执行次数的绝对值 = (x-y)÷z
思考题:3~6
3. 阅读下面的Python程序,请问程序的功能是什么?
from math import sqrt
n = 0
for m in range(101,201,2):
k = int(sqrt(m))
for i in range(2, k+2):
if m % i == 0:break
if i == k + 1:
if n % 10 == 0:print()
print('%d' % m,end = " ")
n += 1
输出101到200之间的素数
每行输出10个,多余换行
运行:
101 103 107 109 113 127 131 137 139 149
151 157 163 167 173 179 181 191 193 197
199
素数(质数)是指在大于1的自然数中,除了1和它本身以外不再有其他因数的自然数。
4. 阅读下面的Python程序,请问输出的结果使什么?
n = int(input("请输入图形的行数:"))
for i in range(0, n):
for j in range(0, 10 - i):print(" ", end=" ")
for k in range(0, 2 * i + 1):print(" * ", end=" ")
print("\n")
输出的是一个金字塔
运行:
请输入图形的行数:4
*
* * *
* * * * *
* * * * * * *
5. 阅读下面的Python程序,请问输出的结果使什么?程序的功能是什么?
for i in range(100,1000):
n1 = i // 100
n2 = i // 10 % 10
n3 = i % 10
if(pow(n1, 3) + pow(n2, 3) + pow(n3, 3) == i):print(i, end=" ")
输出三位数中所有的水仙花数
运行:
153 370 371 407
水仙花数 是指一个 3 位数,它的每个位上的数字的 3次幂之和等于它本身
6. 阅读下面的Python程序,请问输出的结果使什么?程序的功能是什么?
for n in range(1,1001):
total = 0; factors = []
for i in range(1, n):
if(n % i == 0):
factors.append(i)
total += i
if(total == n):print("{0} : {1}".format(n, factors))
输出1到1000的所有完数,并输出每个完数的所有因子
运行:
6 : [1, 2, 3]
28 : [1, 2, 4, 7, 14]
496 : [1, 2, 4, 8, 16, 31, 62, 124, 248]
完数 所有的真因子(即除了自身以外的约数)的和(即因子函数),恰好等于它本身
上机实践:2~14
2. 编写程序,计算1=2+3+…+100之和
- 使用for循环(递增):
total = 0
for i in range(101):
total += i
print(total)
- 使用求和公式:
>>> (1 + 100) * 100 /2
5050.0
- 使用累计迭代器itertools.accumulate
>>> import itertools
>>> list(itertools.accumulate(range(1, 101)))[99]
5050
3. 编写程序,计算10+9+8+…+1之和
- 使用for循环(递增):
total = 0
for i in range(11):
total += i
print(total)
- 使用for循环(递减):
total = 0
for i in range(10,0,-1):
total += i
print(total)
- 使用求和公式:
>>> (1 + 10) * 10 / 2
55.0
- 使用累计迭代器itertools.accumulate
>>> import itertools
>>> list(itertools.accumulate(range(1,11)))[9]
55
4. 编写程序,计算1+3+5+7+…+99之和
- 使用for循环(递增):
total = 0
for i in range(1,100,2):
total += i
print(total)
- 使用求和公式:
>>> (1 + 99) * 50 /2
2500.0
- 使用累计迭代器itertools.accumulate
>>> import itertools
>>> list(itertools.accumulate(range(1,100,2)))[49]
2500
5. 编写程序,计算2+4+6+8+…+100之和
- 使用for循环(递增):
total = 0
for i in range(2,101,2):
total += i
print(total)
- 使用求和公式:
>>> (2 + 100) * 50 / 2
2550.0
- 使用累计迭代器itertools.accumulate
>>> import itertools
>>> x = list(itertools.accumulate(range(2,101,2)))
>>> x[len(x)-1]
2550
6. 编写程序,使用不同的实现方法输出2000~3000的所有闰年
代码一:
for y in range(2000,3001):
if((y % 4 == 0 and y % 100 != 0) or y % 400 == 0):
print(y,end = ' ')
代码二(使用calendar模块的isleap()函数来判断):
from calendar import isleap
for y in range(2000,3001):
if(isleap(y)):print(y,end = " ")
运行:
2000 2004 2008 2012 2016 2020 2024 2028 2032 2036 2040 2044 2048 2052 2056 2060 2064 2068 2072 2076 2080 2084 2088 2092 2096 2104 2108 2112 2116 2120 2124 2128 2132 2136 2140 2144 2148 2152 2156 2160 2164 2168 2172 2176 2180 2184 2188 2192 2196 2204 2208 2212 2216 2220 2224 2228 2232 2236 2240 2244 2248 2252 2256 2260 2264 2268 2272 2276 2280 2284 2288 2292 2296 2304 2308 2312 2316 2320 2324 2328 2332 2336 2340 2344 2348 2352 2356 2360 2364 2368 2372 2376 2380 2384 2388 2392 2396 2400 2404 2408 2412 2416 2420 2424 2428 2432 2436 2440 2444 2448 2452 2456 2460 2464 2468 2472 2476 2480 2484 2488 2492 2496 2504 2508 2512 2516 2520 2524 2528 2532 2536 2540 2544 2548 2552 2556 2560 2564 2568 2572 2576 2580 2584 2588 2592 2596 2604 2608 2612 2616 2620 2624 2628 2632 2636 2640 2644 2648 2652 2656 2660 2664 2668 2672 2676 2680 2684 2688 2692 2696 2704 2708 2712 2716 2720 2724 2728 2732 2736 2740 2744 2748 2752 2756 2760 2764 2768 2772 2776 2780 2784 2788 2792 2796 2800 2804 2808 2812 2816 2820 2824 2828 2832 2836 2840 2844 2848 2852 2856 2860 2864 2868 2872 2876 2880 2884 2888 2892 2896 2904 2908 2912 2916 2920 2924 2928 2932 2936 2940 2944 2948 2952 2956 2960 2964 2968 2972 2976 2980 2984 2988 2992 2996
7. 编写程序,计算Sn=1-3+5-7+9-11…
代码一:
n = int(input("项数:"))
total = 0
flag = True
for i in range(1,2*n,2):
if(flag):
total += i
flag = False
else:
total -= i
flag = True
print(total)
代码二:
n = int(input("项数:"))
total = 0
x = 2
for i in range(1,2*n,2):
total += pow(-1,x)*i
x += 1
print(total)
运行:
项数:10
-10
8. 编写程序,计算Sn=1+1/2+1/3+…
n = int(input("项数:"))
total = 0.0
for i in range(1,n+1):
total += 1/i
print(total)
运行:
项数:10
2.9289682539682538
9. 编写程序,打印九九乘法表。要求输入九九乘法表的各种显示效果(上三角,下三角,矩形块等方式)
矩形块:
for i in range(1,10):
s = ""
for j in range(1,10):
s += str.format("%d * %d = %02d " %(i, j, i*j))
print(s)
下三角:
for i in range(1,10):
s = ""
for j in range(1,i+1):
s += str.format("%d * %d = %02d " %(i, j, i*j))
print(s)
上三角:
for i in range(1,10):
s = ""
for k in range(1,i):
s += " "
for j in range(i,10):
s += str.format("%d * %d = %02d " %(i, j, i*j))
print(s)
10. 编写程序,输入三角形的三条边,先判断是否可以构成三角形,如果可以,则进一步求三角形的周长和面积,否则报错“无法构成三角形!”
from math import sqrt
a = float(input("请输入三角形的边长a:"))
b = float(input("请输入三角形的边长b:"))
c = float(input("请输入三角形的边长c:"))
if(a < b): a,b = b,a
if(a < c): a,c = c,a
if(b < c): b,c = c,b
if(a < 0 or b < 0 or c < 0 or b+c <= a): print("无法构成三角形!")
else:
h = (a+b+c)/2
area = sqrt(h*(h-a)*(h-b)*(h-c))
print("周长:{0},面积:{1}".format(a+b+c,area))
运行:
请输入三角形的边长a:4
请输入三角形的边长b:3
请输入三角形的边长c:5
周长:12.0,面积:6.0
11. 编写程序,输入x,根据如下公式计算分段函数y的值。请分别用单分支语句,双分支语句结构以及条件运算语句等方法实现
y = (x2-3x)/(x+1) + 2π + sinx (x≥0 )
y = ln(-5x) + 6√(|x|+e4) - (x+1)3 (x<0)
单分支语句:
import math
x = float(input("请输入x:"))
if(x >= 0):
y = (x*x - 3*x)/(x+1) + 2*math.pi + math.sin(x)
if(x < 0):
y = math.log(-5*x) + 6 * math.sqrt(abs(x) + math.exp(4)) - pow(x+1,3)
print(y)
双分支语句:
import math
x = float(input("请输入x:"))
if(x >= 0):
y = (x*x - 3*x)/(x+1) + 2*math.pi + math.sin(x)
else:
y = math.log(-5*x) + 6 * math.sqrt(abs(x) + math.exp(4)) - pow(x+1,3)
print(y)
条件运算语句:
import math
x = float(input("请输入x:"))
y = ((x*x - 3*x)/(x+1) + 2*math.pi + math.sin(x)) if(x >= 0) \
else (math.log(-5*x) + 6 * math.sqrt(abs(x) + math.exp(4)) - pow(x+1,3))
print(y)
运行一:
请输入x:666
668.2715406628656
运行二:
请输入x:-666
294079794.1744833
12. 编写程序,输入一元二次方程的3个系数a、b、c,求ax2+bx+c=0方程的解
import math
a = float(input("请输入系数a:"))
b = float(input("请输入系数b:"))
c = float(input("请输入系数c:"))
delta = b*b -4*a*c
if(a == 0):
if(b == 0): print("无解")
else: print("有一个实根:",-1*c/b)
elif(delta == 0): print("有两个相等实根:x1 = x2 = ", (-1*b)/(2*a))
elif(delta > 0): print("有两个不等实根:x1 = {0},x2 = {1}".format\
((-1*b +math.sqrt(delta))/2*a,(-1*b -math.sqrt(delta))/2*a))
elif(delta < 0): print("有两个共轭复根:x1 = {0},x2 = {1}".format\
(complex( (-1*b)/(2*a),math.sqrt(delta*-1)/(2*a)),complex( (-1*b)/(2*a),-1*math.sqrt(delta*-1)/(2*a))))
运行一:
请输入系数a:0
请输入系数b:0
请输入系数c:10
无解
运行二:
请输入系数a:0
请输入系数b:10
请输入系数c:5
有一个实根: -0.5
运行三:
请输入系数a:1
请输入系数b:8
请输入系数c:16
有两个相等实根:x1 = x2 = -4.0
运行四:
请输入系数a:1
请输入系数b:-5
请输入系数c:6
有两个不等实根:x1 = 3.0,x2 = 2.0
运行五:
请输入系数a:5
请输入系数b:2
请输入系数c:1
有两个共轭复根:x1 = (-0.2+0.4j),x2 = (-0.2-0.4j)
13. 编写程序,输入整数n(n≥0),分别利用for循环和while循环求n!
- for循环
n = int(input("请输入n:"))
if(n == 0): total = 1
if(n > 0):
total = 1
for i in range(n,0,-1):
total *= i
print(total)
- while循环
n = int(input("请输入n:"))
if(n == 0): total = 1
if(n > 0):
total = 1
while(n >= 1):
total *= n
n -= 1
print(total)
- 补充一个:使用累计迭代器itertools.accumulate
>>> import itertools, operator
>>> n = int(input('请输入n:'))
请输入n:7
>>> x = list(accumulate(range(1, n+1), operator.mul))
>>> x[len(x)-1]
5040
14. 编写程序,产生两个0~100(包含0和100)的随机整数a和b,求这两个整数的最大公约数和最小公倍数
- 现有知识点解决方法
import random
a = random.randint(0,100)
b = random.randint(0,100)
sum = a*b
print(a) #输出原来的a,b
print(b)
if(a < b): a,b = b,a
while(a%b != 0):
a,b = b,a%b
print("最大公约数:{0},最小公倍数:{1}".format(b,sum/b))
- 补充:使用生成器(generate)函数:yield
>>> def func(a, b):
if(a < b): a,b = b,a
while(a%b != 0):
a,b = b,a%b
yield b
>>> import random
>>> if __name__ == '__main__':
a = random.randint(0,100)
b = random.randint(0,100)
sum = a*b
print(a,b)
t = list(iter(func(a, b)))
gcd = t[len(t)-1]
print("gcd = {0}, mcm = {1}".format(gcd, sum/gcd))
29 65
gcd = 1, mcm = 1885.0
- 补充:使用math模块中的
gcd(x,y)函数
>>> import random
>>> import math
>>> if __name__ == '__main__':
a = random.randint(0,100)
b = random.randint(0,100)
sum = a*b
print(a,b)
gcd = math.gcd(a,b)
print("gcd = {0}, mcm = {1}".format(gcd, sum/gcd))
29 48
gcd = 1, mcm = 1392.0
案例研究:使用嵌套循环实现图像处理算法
https://blog.csdn.net/Zhangguohao666/article/details/103935185
通过图像处理算法案例,深入了解Python数据结构和基本算法流程
第四章 常用内置数据类型
几个例题
一:Python内置数据类型概述
Python中一切皆为对象,而每个对象属于某个数据类型
Python的数据类型包括:
- 内置的数据类型
- 模块中定义的数据类型
- 用户自定义的类型
四种内置的数值类型:int,float,bool,complex
- int
与其他计算机语言有精度限制不同,Python中的整数位数可以为任意长度(只受限于计算机内存)。
整型对象是不可变对象。- float
与其他计算机语言中的double和float对应
Python的浮点类型的精度和系统相关- bool
- complex
当数值字符串中包含虚部j(或J)时即复数字面量
序列数据类型:str,tuple,bytes,list,bytearray
序列数据类型表示若干有序数据.
不可变序列数据类型:
- str(字符串)
表示Unicode字符序列,例如:“zgh666”
在Python中没有独立的字符数据类型,字符即长度为1的字符串- tuple(元组)
表示任意数据类型的序列,例如:(“z”,“g”,“h”,6,6,6)- bytes(字节序列)
表示字节(8位)序列数据
可变序列数据类型:
- list(列表)
表示可以修改的任意类型数据的序列,比如:[‘z’,‘g’,‘h’,6,6,6]- bytearray(字节数组)
表示可以修改的字节(8位)数组
集合数据类型:set,frozenset
集合数据类型表示若干数据的集合,数据项目没有顺序,且不重复
- set(集)
例如:{1,2,3}- frozenset(不可变集)
字典数据类型:dict
字典数据类型用于表示键值对的字典
例如:{1:"zgh", 2:666}
NoneType,NotImplementedType,EllipsisType
- NoneType数据类型包含唯一值None,主要用于表示空值,如没有返回值的函数的结果
- NotImplementedType数据类型包含唯一值NotImplemented,在进行数值运算和比较运算时,如果对象不支持,则可能返回该值
- EllipsisType数据类型包含唯一值Ellipsis,表示省略字符串符号
...
其他数据类型
Python中一切对象都有一个数据类型,模块、类、对象、函数都属于某种数据类型
Python解释器包含内置类型,
例如:
代码对象Code objects
框架对象Frame objects
跟踪对象Traceback objects
切片对象Slice objects
静态方法对象Static method objects
类方法对象Class method objects
二:整型字面量示例
Python3.7支持使用下划线作为整数或者浮点数的千分位标记,以增强大数值的可阅读性。
二进制、八进制、十六进制则使用下划线区分4位标记
1_000_000_000 #输出1000000000
0xff_ff_ff_ff #输出4294967295
0x_FF_FF_FF_FF #输出4294967295
三:字符串字面量示例
两个紧邻的字符串,如果中间只有空格分隔,则自动拼接位一个字符串
'zgh' '666' #输出'zgh666'
'zgh' + "666" #输出'zgh666'
四:转义字符示例
转义字符后跟Unicode编码也可以表示字符
\ooo八进制Unicode码对应的字符\xhh十六进制Unicode码对应的字符
'\101' #输出'A'
'\x41' #输出'A'
使用r’‘或者R’'的字符串称为原始字符串,其中包含的任何字符都不进行转义
s = r'换\t行\t符\n'
s #输出:'换\\t行\\t符\\n'
print(s) #输出:换\\t行\\t符\\n
五:字符串的格式化
一:
"student number:{0},score_average:{1}".format(2,100)
#输出:'student number:2,score_average:100'
二:
str.format("student number:{0},score_average:{1}",2,100)
#输出:'student number:2,score_average:100'
三(兼容Python2的格式,不推荐使用):
"student number:%4d,score_average:%2.1f" %(2,100)
#输出:'student number: 2,score_average:100.0'
六:字符串示例,格式化输出字符串堆积的三角形
str.center()方法用于字符串两边填充str.rjust()方法用于字符串右填充
print("1".center(20)) #一行20个字符,居中对齐
print(format("121","^20")) #一行20个字符,居中对齐
print("1".rjust(20,"*")) #一行20个字符,右对齐,加*
print(format("121","*>20")) #一行20个字符,右对齐,加*
运行:
1
121
*******************1
*****************121
选择题:11
11. 关于Python字符串,下列说法错误的是
A. 字符即长度为1的字符串
B. 字符串以/0标识字符串的结束
C. 用户既可以用单引号,也可以用双引号创建字符串
D. 用三引号字符串中可以包含换行回车等特殊字符
答案:B
Python中字符串不是用\0来判断字符串结尾,
每个字符串都存有字符串的长度,通过计数来判断是否到达结尾。
虽然在c语言中\0就是来判断字符串的结尾;
填空题:4、7、8、9、10、13、21
4. Python表达式3 ** 2 ** 3的值为
答案:6561
表达式中,相同优先级的运算,从右往左
7. Python语句print(pow(-3,2),round(18.67,1),round(18.67,-1))的输出结果是
答案:9 18.7 20.0
pow()幂运算
round()四舍六入,五留双
8. Python语句print(round(123.84,0),round(123.84,-2),floor(15.5))的输出结果是
答案:124.0 100.0 15
补充:floor()是math模块中的方法,向下取整
9. Python语句print(int(‘20’,16),int(‘101’,2))的输出结果是
答案:32 5
注意:int(x,y)是指将y进制的数值x转化为10进制数
10. Python语句print(hex(16),bin(10))的输出结果是
答案:0x10 0b1010
hex(x)将十进制数x转化为十六进制,以字符串形式输出
bin(x)将十进制数x转化为二进制,以字符串形式输出
13. Python语句print(gcd(12,16),divmod(7,3))的输出结果是
答案:4 (2,1)
gcd()是math模块中的函数,求最大公约数
divmod()是内置函数,返回商和余数
21. Python语句序列 x=True;y=False;z=False;print(x or y and z) 的运行结果是
答案:True
and优先级比or高
思考题:5
5. 阅读下面的Python程序,请问输出结果是什么?
from decimal import *
ctx = getcontext()
ctx.prec = 2
print(Decimal('1.78'))#1.78
print(Decimal('1.78') + 0)#1.8
ctx.rounding = ROUND_UP
print(Decimal('1.65') + 0)#1.7
print(Decimal('1.62') + 0)#1.7
print(Decimal('-1.45') + 0)#-1.5
print(Decimal('-1.42') + 0)#-1.5
ctx.rounding = ROUND_HALF_UP
print(Decimal('1.65') + 0)#1.7
print(Decimal('1.62') + 0)#1.6
print(Decimal('-1.45') + 0)#-1.5
ctx.rounding = ROUND_HALF_DOWN
print(Decimal('1.65') + 0)#1.6
print(Decimal('-1.45') + 0)#-1.4
上机实践:2~14
2. 编写程序,格式化输出杨辉三角
杨辉三角即二项式定理的系数表,各元素满足如下条件:第一列及对角线上的元素均为1;其余每个元素等于它上一行同一列元素与前一列元素之和
我使用了一个更加精妙的规律
比如第一行为1
第二行:01 + 10 = 11
第三行:011 + 110 = 121
第四行:0121 + 1210 = 1331
。。。
def generate(numRows):
l1 = [1]
n = 0
while n < numRows:
print(str(l1).center(66))
l1 = [sum(t) for t in zip([0] + l1, l1 + [0])] #利用zip函数算出每一行 如第二行 zip([0,1],[1,0])=[1,1],以此类推
n += 1
a=int(input("请输入行数"))
generate(a)
运行:
请输入行数4
[1]
[1, 1]
[1, 2, 1]
[1, 3, 3, 1]
3. 输入直角三角形的两个直角边,求三角形的周长和面积,以及两个锐角的度数。结果保留一位小数
import math
a = float(input("请输入直角三角形的直角边a:"))
b = float(input("请输入直角三角形的直角边b:"))
c = math.sqrt(a*a+b*b)
p = a + b + c
area = 0.5*a*b
print("三角形的周长:{0:1.1f},面积:{1:1.1f}".format(p,area))
sina = a/c
sinb = b/c
a_degree = round(math.asin(sina) * 180 / math.pi,0)
b_degree = round(math.asin(sinb) * 180 / math.pi,0)
print("三角形直角边a的度数:{0},b的度数:{1}".format(a_degree,b_degree))
运行:
请输入直角三角形的直角边a:3
请输入直角三角形的直角边b:4
三角形的周长:12.0,面积:6.0
三角形直角边a的度数:37.0,b的度数:53.0
4. 编程产生0~100(包含0和100)的三个随机数a、b、c,要求至少使用两种不同的方法,将三个数按从小到大的顺序排序
方法一:
import random
a = random.randint(0, 100)
b = random.randint(0, 100)
c = random.randint(0, 100)
print(str.format("原始值:{0},{1},{2}", a, b, c))
if(a > b): a,b = b,a
if(a > c): a,c = c,a
if(b > c): b,c = c,b
print(str.format("增序:{0},{1},{2}", a, b, c))
方法二(使用内置函数max、min、sum):
import random
a = random.randint(0, 100)
b = random.randint(0, 100)
c = random.randint(0, 100)
print(str.format("原始值:{0},{1},{2}", a, b, c))
maxx = max(a, b, c)
minx = min(a, b, c)
median = sum([a, b, c]) - minx - maxx
print(str.format("增序:{0},{1},{2}", minx, median, maxx))
方法三(使用内置函数sorted):
>>> import random
>>> a = random.randint(0,100)
>>> b = random.randint(0,100)
>>> c = random.randint(0,100)
>>> print("init value: {0} , {1} , {2}".format(a,b,c))
init value: 17 , 6 , 59
>>> sorted([a,b,c])
[6, 17, 59]
5. 编程计算有固定工资收入的党员每月所缴纳的党费。
工资基数3000元及以下者,交纳工资基数的0.5%
工资基数3000~5000元者,交纳工资基数的1%
工资基数在5000~10000元者,交纳工资基数的1.5%
工资基数超过10000元者,交纳工资基数的2%
salary = float(input("请输入有固定工资收入的党员的月工资:"))
if salary <= 3000: dues = salary*0.005
elif salary <= 5000: dues = salary*0.01
elif salary <= 10000: dues = salary*0.15
else: dues = salary*0.02
print("交纳党费:",dues)
运行:
请输入有固定工资收入的党员的月工资:10001
交纳党费: 200.02
6. 编程实现袖珍计算器,要求输入两个操作数和一个操作符(+、-、*、/、%),根据操作符输出运算结果。注意/和%运算符的零异常问题
a = float(input("请输入操作数(左):"))
b = float(input("请输入操作数(右):"))
operator = input("请输入操作符(+、-、*、/、%):")
if(b == 0 and (operator == '/' or operator == '%')):
print("分母为零,异常!")
else:
if operator == '+': result = a+b
elif operator == '-': result = a-b
elif operator == '*': result = a*b
elif operator == '/': result = a/b
elif operator == '%': result = a%b
print("{0} {1} {2}= {3}:".format(a,operator,b,result))
运行:
请输入操作数(左):10
请输入操作数(右):5
请输入操作符(+、-、*、/、%):+
10.0 + 5.0= 15.0:
7. 输入三角形的3条边a、b、c,判断此3边是否可以构成三角形。若能,进一步判断三角形的性质,即为等边、等腰、直角或其他三角形
a = float(input("请输入三角形的边a:"))
b = float(input("请输入三角形的边b:"))
c = float(input("请输入三角形的边c:"))
if(a > b): a,b = b,a
if(a > c): a,c = c,a
if(b > c): b,c = c,b
result = "三角形"
if(not(a>0 and b>0 and c>0 and a+b>c)):
result = '此三边无法构成三角形'
else:
if a == b == c: result = '等边三角形'
elif(a==b or a==c or b==c): result = '等腰三角形'
elif(a*a+b*b == c*c): result = '直角三角形'
print(result)
运行:
请输入三角形的边a:3
请输入三角形的边b:4
请输入三角形的边c:5
直角三角形
8. 编程实现鸡兔同笼问题
已知在同一个笼子里共有h只鸡和兔,鸡和兔的总脚数为f,其中h和f由用户输入,求鸡和兔各有多少只?要求使用两种方法:一是求解方程;二是利用循环进行枚举测试
h = int(input("请输入总头数:"))
f = int(input("请输入总脚数:"))
def fun1(h,f):
rabbits = f/2-h
chicken = h-rabbits
if(chicken < 0 or rabbits < 0): return '无解'
return chicken,rabbits
def fun2(h,f):
for i in range(0,h+1):
if(2*i + 4*(h-i) == f):return i,h-i
return '无解'
if(h>0 and f>0 and f % 2 == 0):
if fun1(h,f)=='无解':
print("无解")
else:
print("方法一:鸡:{0},兔:{1}".format(fun1(h,f)[0],fun1(h,f)[1]))
print("方法二:鸡:{0},兔:{1}".format(fun2(h,f)[0],fun2(h,f)[1]))
else:
print('输入的数据无意义')
运行:
请输入总头数:100
请输入总脚数:100
无解
9. 输入任意实数x,计算ex的近似值,直到最后一项的绝对值小于10-6为止
ex = 1 + x + x2/2 + x3/3! + x4/4! + … + xn/n!
x = int(input("请输入任意实数:"))
e = 1
i = 1
t = 1
a = 1
while(a >= 10e-6):
t *= i
a = pow(x,i)/t
e += a
i += 1
print(e)
运行:
请输入任意实数:1
2.7182815255731922
我发现了在Python中10e-6和pow(10,-6)是有差别的,将上述代码中的10e-6改为pow(10,-6),输出结果会有细微的差别
运行:
请输入任意实数:1
2.7182818011463845
10. 输入任意实数a(a>=0),用迭代法求x=√a,要求计算的相对偏差小于10-6
求平方根的公式:
Xn+1 = 0.5(Xn + a/Xn)
import math
a = int(input("请输入任意实数a(>=0):"))
x = a / 2
y = (x + a/x) / 2
while(abs(y-x) >= pow(10,-6)):
x = y
y = (x + a/x) / 2
print(y)
运行:
请输入任意实数a(>=0):2
1.414213562373095
11. 即有一个数,用3除余2,用5除余3,用7除余2,请问0~1000中这样的数有哪些?
我国古代有位大将,名叫韩信。他每次集合部队,只要求部下先后按1-3,1-5,1-7报数,然后再报告一下各队每次报数的余数,他就知道到了多少人。他的这种巧妙算法被人们称作“鬼谷算”,也叫“隔墙算”,或称为“韩信点兵”,外国人还称它为“中国余数定理”。
for i in range(0,1001):
if((i % 3 == 2 )and (i % 5 == 3) and (i % 7 == 2)): print(i, end=" ")
运行:
23 128 233 338 443 548 653 758 863 968
12. 一球从100米的高度自由下落,每次落地后反弹回原高度的一半,再落下。求小球在第10次落地时共经过多少米?第10次反弹多高
规律:
第一次下落时的高度:100
第二次下落时的高度(第一次反弹的高度):50
第三次下落时的高度(第二次反弹的高度):25
…
n = 10
h_down = 100
h_up = 0
sum = 0
for i in range(1,n+1):
sum += h_down+h_up
h_down = h_up = h_down/2
print("小球在第十次落地时共经过:{0}米,第十次反弹高度:{1}米".format(sum,h_up))
运行:
小球在第十次落地时共经过:299.609375米,第十次反弹高度:0.09765625米
13. 猴子吃桃问题
猴子第一天摘下若干个桃子,当天吃掉一半多一个;第二天接着吃了剩下的桃子的一半多一个;以后每天都吃了前一天剩下的桃子的一半多一个。到第八天发现只剩一个桃子了。请问猴子第一天共摘了多少个桃子?
这是一个递推问题
某天所剩桃子数x
后一天所剩桃子数y = x - (x/2+1) = x/2-1
则x = 2(y+1)
result = 1
for i in range(8,0,-1):
print("第{0}天桃子数:{1}".format(i,result))
result = 2*(result+1)
运行:
第8天桃子数:1
第7天桃子数:4
第6天桃子数:10
第5天桃子数:22
第4天桃子数:46
第3天桃子数:94
第2天桃子数:190
第1天桃子数:382
14. 计算Sn = 1+11+111+…+111…111(最后一项是n个1)。n是一个随机产生的1~10(包括1和10)中的正整数
import random
n = random.randint(1,10)
x = 1
s = 0
for i in range(1,n+1):
s += x
x = 10*x+1
print("n = {0},sn = {1}".format(n,s))
运行:
n = 6,sn = 123456
random.randint(a, b)
- 生成指定范围内的整数
- 范围:[a, b]
案例研究:科学计算和数据分析
https://blog.csdn.net/Zhangguohao666/article/details/103941448
通过Python科学计算和数据分析库的安装和基本使用,了解使用Python进行科学计算的基本方法
第五章 序列数据类型
几个例题
一:Python中内置的序列数据类型
- 元组也称为定值表,用于存储固定不变的表
- 列表也称为表,用于存储其值可变的表
- 字符串是包括若干字符的序列数据,支持序列数据的基本操作
- 字节序列数据是包括若干字节的序列。Python抓取网页时返回的页面通常为utf-8编码的字节序列。
字节序列和字符串可以直接相互转换(字节编码和解码):
>>> s1 = b'abc'
>>> s1
b'abc'
>>> s1.decode("utf-8")
abc
>>> s2 = "中国"
>>> s2.encode("utf-8")
b'\xe4\xb8\xad\xe5\x9b\xbd'
二:序列的切片操作示例
>>> s = 'zgh666'
>>> s[0]
'z'
>>> s[2]
'h'
>>> s[:3]
'zgh'
>>> s[1:3]
'gh'
>>> s[3:6]
'666'
>>> s[3:55]
'666'
>>> s[::-1]
'666hgz'
>>> s[3:2]
''
>>> s[:]
'zgh666'
>>> s[::2]
'zh6'
三:序列的连接和重复操作
- 通过连接操作符
+可以连接两个序列,形成一个新的序列对象- 通过重复操作符
*可以重复一个序列n次- 连接操作符和重复操作符也支持复合赋值运算,即:
+=,*=
>>> x = 'zgh'
>>> y = '666'
>>> x + y
'zgh666'
>>> x *2
'zghzgh'
>>> x += y
>>> x
'zgh666'
>>> y *= 3
>>> y
'666666666'
四:序列的成员关系操作
- in
- not in
- s.count(x)
x在s中出现的次数 - s.index(x)
x在s中第一次出现的下标
>>> s = "zgh666"
>>> 'z' in s
True
>>> 'g' not in s
False
>>> s.count('6')
3
>>> s.index('6')
3
五:序列的排序操作
sorted(iterable,key=None,reverse=False)
>>> sorted(s)
[1, 3, 5, 9]
>>> sorted(s,reverse=True)
[9, 5, 3, 1]
>>> s = 'zGhZgH'
>>> sorted(s)
['G', 'H', 'Z', 'g', 'h', 'z']
>>> sorted(s,key=str.lower)
['G', 'g', 'h', 'H', 'z', 'Z']
>>> sorted(s,key=str.lower,reverse=True)
['z', 'Z', 'h', 'H', 'G', 'g']
六:序列的拆分
- 变量个数与序列长度相等
若变量个数与序列的元素个数不一致,将导致ValueError
>>> data = (118,'zgh',(100,100,100))
>>> sid,name,(chinese,english,math) = data
>>> sid
118
>>> name
'zgh'
>>> chinese
100
>>> english
100
>>> math
100
- 变量个数与序列长度不等
如果序列长度未知,可以使用*元组变量,将多个值作为元组赋值给元组变量。在一个赋值语句中,*元组变量只允许出现一次,否则将导致SyntaxError
>>> first,second,third,*middles,last = range(10)
>>> first
0
>>> second
1
>>> third
2
>>> middles
[3, 4, 5, 6, 7, 8]
>>> last
9
>>> first,*middles,last = sorted([58,60,60,100,70,70])
>>> sum(middles)/len(middles)
65.0
- 使用临时变量
_
如果只需要部分数据,序列的其它位置可以使用临时变量_
>>> record = ['zgh','[email protected]','17354364147','15272502101']
>>> name,_,*phone = record
>>> name
'zgh'
>>> phone
['17354364147', '15272502101']
七:使用元组字面量,tuple创建元组实例对象的实例
>>> t1 = 1,2,3
>>> t1
(1, 2, 3)
>>> t2 = (4,5,6)
>>> t2
(4, 5, 6)
>>> t3 = (9,)
>>> t3
(9,)
如果元组中只有一个项目,后面的逗号不能省略。
Python解释器把(1)解释为整数1,将(1,)解释为元组
>>> t1 = tuple()
>>> t1
()
>>> t2 = tuple("zgh666")
>>> t2
('z', 'g', 'h', '6', '6', '6')
>>> t3 = tuple(['z','g','h'])
>>> t3
('z', 'g', 'h')
八:使用列表字面量,list创建列表实例对象的实例
>>> l1 = []
>>> l1
[]
>>> l2 = ['zgh666']
>>> l2
['zgh666']
>>> l3 = [(1,2,3)]
>>> l3
[(1, 2, 3)]
>>> l1 = list()
>>> l1
[]
>>> l2 = list(b'zgh666')
>>> l2
[122, 103, 104, 54, 54, 54]
>>> l3 = list(b'aAbBcC')
>>> l3
[97, 65, 98, 66, 99, 67]
补充:列表是可变对象,故用户可以改变列表对象中元素的值,也可以通过del删除某元素
九:列表解析表达式示例
使用列表解析表达式可以简单,高效地处理一个可迭代对象,并生成结果列表
>>> [(i,i**2) for i in range(10)]
[(0, 0), (1, 1), (2, 4), (3, 9), (4, 16), (5, 25), (6, 36), (7, 49), (8, 64), (9, 81)]
>>> [i for i in range(10) if i%2==0]
[0, 2, 4, 6, 8]
>>> [(x,y,x*y) for x in range(1,4) for y in range(1,4) if x>=y]
[(1, 1, 1), (2, 1, 2), (2, 2, 4), (3, 1, 3), (3, 2, 6), (3, 3, 9)]
选择题:4、5、7、11、12
4. Python语句序列“a = (1,2,3,None,(),[]);print(len(a))”的运行结果是
>>> a = (1,2,3,None,(),[])
>>> len(a)
6
5. Python语句序列“nums = set([1,2,2,3,3,3,4]);print(len(nums))”的运行结果是
>>> nums = set([1,2,2,3,3,3,4])
>>> nums
{1, 2, 3, 4}
>>> len(nums)
4
7. Python语句序列“s1=[4,5,6];s2=s1;s1[1]=0;print(s2)”的运行结果是
Python中变量(如s1,s2)存储在栈中,存放的是地址
[4,5,6]存储在堆中
s1 = [4,5,6]即s1存储指向堆中[4,5,6]的地址
s2 = s1地址赋值,即s2和s1都指向同一个地址
所以对列表进行修改,两者的显示都会发生变化
>>> s1 = [4,5,6]
>>> s2 = s1
>>> s1[1] = 0
>>> s1
[4, 0, 6]
>>> s2
[4, 0, 6]
11. Python语句序列“s={‘a’,1,‘b’,2};print(s[‘b’])”的运行结果是
| A. 语法错 | B. ‘b’ | C. 1 | D. 2 |
|---|
答案:A
通过值访问集合是没有意义的,语法也不支持
>>> s ={'a',1,'b',2}
>>> print(s['b'])
Traceback (most recent call last):
File "<pyshell#29>", line 1, in <module>
print(s['b'])
TypeError: 'set' object is not subscriptable
补充:集合set是无序不重复的,是无法通过下标访问的
12. Python语句print(r"\nGood")的运行结果是
| A. 新行和字符串Good | B. r"\nGood" | C. \nGood | D. 字符r、新行和字符串Good |
|---|
答案:C
>>> print(r"\nGood")
\nGood
r""声明原始字符串
填空题:1、5、6、12、13、14
1. Python语句序列“fruits = [‘apple’,‘banana’,‘bear’];print(fruits[-1][-1])”的运行结果是
注意:fruit[-1]是字符串’bear’
所以:fruit[-1][-1]即'bear[-1]'
>>> fruits = ['apple','banana','pear']
>>> fruits[-1]
'pear'
>>> fruits[-1][-1]
'r'
5. Python语句 print(’%d%%%d’%(3/2,3%2)) 的运行结果是
>>> print('%d%%%d'%(3/2,3%2))
1%1
6. Python语句序列“s = [1,2,3,4];s.append([5,6]);print(len(s))”的运行结果是
答案:5
注意append()和extend()函数的区别
s.append(x)将对象x追加到s尾部
s.extend(x)将序列x追加到s尾部
append
>>> s = [1,2,3,4]
>>> s.append([5,6])
>>> s
[1, 2, 3, 4, [5, 6]]
>>> len(s)
5
extend
>>> s = [1,2,3,4]
>>> s.extend([5,6])
>>> s
[1, 2, 3, 4, 5, 6]
>>> len(s)
6
12
>>> s =('a','b','c','d','e')
>>> s[2]
'c'
>>> s[2:3]
('c',)
>>> s[2:4]
('c', 'd')
>>> s[1::2]
('b', 'd')
>>> s[-2]
'd'
>>> s[::-1]
('e', 'd', 'c', 'b', 'a')
>>> s[-2:-1]
('d',)
>>> s[-99:-5]
()
>>> s[-99:-3]
('a', 'b')
>>> s[::]
('a', 'b', 'c', 'd', 'e')
>>> s[1:-1]
('b', 'c', 'd')
13
>>> s = [1,2,3,4,5,6]
>>> s[:1] = []
>>> s
[2, 3, 4, 5, 6]
>>> s[:2] = 'a'
>>> s
['a', 4, 5, 6]
>>> s[2:] = 'b'
>>> s
['a', 4, 'b']
>>> s[2:3] = ['x','y']
>>> s
['a', 4, 'x', 'y']
>>> del s[:1]
>>> s
[4, 'x', 'y']
14
>>> s = ['a','b']
>>> s.append([1,2])
>>> s
['a', 'b', [1, 2]]
>>> s.extend('34')
>>> s
['a', 'b', [1, 2], '3', '4']
>>> s.extend([5,6])
>>> s
['a', 'b', [1, 2], '3', '4', 5, 6]
>>> s.insert(1,7)
>>> s
['a', 7, 'b', [1, 2], '3', '4', 5, 6]
>>> s.insert(10,8)
>>> s
['a', 7, 'b', [1, 2], '3', '4', 5, 6, 8]
>>> s
['a', 7, 'b', [1, 2], '3', '4', 5, 6]
>>> s.remove('b')
>>> s
['a', 7, [1, 2], '3', '4', 5, 6]
>>> s[3:] =[]
>>> s
['a', 7, [1, 2]]
>>> s.reverse()
>>> s
[[1, 2], 7, 'a']
>>>
思考题:2、3、5
2. 阅读下面的Python语句,请问输出结果是什么?
n = int(input('请输入图形的行数:'))
for i in range(n,0,-1):
print(" ".rjust(20-i),end=' ')
for j in range(2*i-1):print(" * ",end=' ')
print('\n')
for i in range(1,n):
print(" ".rjust(19-i),end=' ')
for j in range(2*i+1):print(" * ",end=' ')
print('\n')
运行一:
请输入图形的行数:1
*
运行二:
请输入图形的行数:2
* * *
*
* * *
运行三:
请输入图形的行数:3
* * * * *
* * *
*
* * *
* * * * *
3. 阅读下面的Python语句,请问输出结果是什么?
n = int(input('请输入上(或下)三角行数:'))
for i in range(0,n):
print(" ".rjust(19-i),end=' ')
for j in range(2*i+1):print(" * ",end=' ')
print('\n')
for i in range(n-1,0,-1):
print(" ".rjust(20-i),end=' ')
for j in range(2*i-1):print(" * ",end=' ')
print('\n')
运行:
请输入上(或下)三角行数:4
*
* * *
* * * * *
* * * * * * *
* * * * *
* * *
*
5. 阅读下面的Python语句,请问输出结果是什么?
先看这三句:
>>> names1 = ['Amy','Bob','Charlie','Daling']
>>> names2 = names1
>>> names3 = names1[:]
毫无疑问,此时names1,names2,names3的值都是[‘Amy’,‘Bob’,‘Charlie’,‘Daling’]
但是
>>> id(names1)
2338529391368
>>> id(names2)
2338529391368
>>> id(names3)
2338529391560
names1和names2指向同一个地址
而names3指向另一个地址
然后:
>>> names2[0] = 'Alice'
>>> names3[1] = 'Ben'
>>> names1
['Alice', 'Bob', 'Charlie', 'Daling']
>>> names2
['Alice', 'Bob', 'Charlie', 'Daling']
>>> names3
['Amy', 'Ben', 'Charlie', 'Daling']
最后:
>>> sum = 0
>>> for ls in(names1,names2,names3):
if ls[0] == 'Alice': sum+=1
if ls[1] == 'Ben':sum+=2
>>> print(sum)
4
上机实践:2~6
2. 统计所输入字符串中单词的个数,单词之间用空格分隔
s = input("请输入字符串:")
num = 0
for i in s:
if((i >= 'a' and i <= 'z') or (i >= 'A' and i <= 'Z')):
num += 1
print("其中的单词总数:",num)
运行:
请输入字符串:zgh666 ZGH6
其中的单词总数: 6
3. 编写程序,删除一个list里面重复元素
方法一:利用set集合不重复的性质(但结果不能保证原来的顺序)
l = [1,2,2,3,3,3,4,5,6,6,6]
s = set(l)
l = list(s)
print(l)
运行:
[1, 2, 3, 4, 5, 6]
方法二:既可以去除重复项,又可以保证原来的顺序
def unique(items):
items_existed = set()
for item in items:
if item not in items_existed:
yield item
items_existed.add(item)
if __name__ == '__main__':
a = [1, 8, 5, 1, 9, 2, 1, 10]
a1 = unique(a)
print(list(a1))
运行结果:
[1, 8, 5, 9, 2, 10]
对代码的分析:
- 可以看出,
unique()函数返回的并不是items_existed,而是利用了yield
在函数定义中,如果使用yield语句代替return返回一个值,则定义了一个生成器函数(generator)
生成器函数是一个迭代器,是可迭代对象,支持迭代
a1 = unique(a)这个函数返回的实际上是一个可迭代对象
若print(a1)得到的会是:<generator object unique at 0x0000016E23AF4F48>- 所以,要得到去掉重复后的列表的样子,需要将可迭代对象a1放在
list()中
运行:
4. 编写程序,求列表[9,7,8,3,2,1,55,6]中的元素个数、最大值、最小值,以及元素之和、平均值。请思考有几种实现方法?
内置函数:
s = [9,7,8,3,2,1,55,6]
print("元素个数:{0},最大值:{1},最小值:{2},和:{3},平均值:{4}".\
format(len(s),max(s),min(s),sum(s),sum(s)/len(s)))
直接访问元素列表(for i in s…):
s = [9,7,8,3,2,1,55,6]
sum = 0
max = s[0]
min = s[0]
length = 0
for i in s:
sum += i
length += 1
if(i > max): max = i
if(i < min): min = i
print("元素个数:{0},最大值:{1},最小值:{2},和:{3},平均值:{4}".\
format(length,max,min,sum,sum/length))
间接访问列表元素(for i in range(0,len(s))…):
s = [9,7,8,3,2,1,55,6]
sum = 0
max = s[0]
min = s[0]
length = len(s)
for i in range(0,length):
sum += s[i]
if(s[i] > max): max = s[i]
if(s[i] < min): min = s[i]
print("元素个数:{0},最大值:{1},最小值:{2},和:{3},平均值:{4}".\
format(length,max,min,sum,sum/length))
正序访问(i=0;while i<len(s)…):
s = [9,7,8,3,2,1,55,6]
sum = 0
max = s[0]
min = s[0]
length = len(s)
i = 0
while(i < length):
sum += s[i]
if(s[i] > max): max = s[i]
if(s[i] < min): min = s[i]
i += 1
print("元素个数:{0},最大值:{1},最小值:{2},和:{3},平均值:{4}".\
format(length,max,min,sum,sum/length))
反序访问(i=len(s)-1;while i>=0…):
s = [9,7,8,3,2,1,55,6]
sum = 0
max = s[0]
min = s[0]
length = len(s)
i = length-1
while(i >= 0):
sum += s[i]
if(s[i] > max): max = s[i]
if(s[i] < min): min = s[i]
i -= 1
print("元素个数:{0},最大值:{1},最小值:{2},和:{3},平均值:{4}".\
format(length,max,min,sum,sum/length))
while True:…break
s = [9,7,8,3,2,1,55,6]
sum = 0
max = s[0]
min = s[0]
length = len(s)
i = 0
while(True):
if(i > length-1): break
sum += s[i]
if(s[i] > max): max = s[i]
if(s[i] < min): min = s[i]
i += 1
print("元素个数:{0},最大值:{1},最小值:{2},和:{3},平均值:{4}".\
format(length,max,min,sum,sum/length))
运行:
元素个数:8,最大值:55,最小值:1,和:91,平均值:11.375
5. 编写程序,将列表[9,7,8,3,2,1,5,6]中的偶数变成它的平方,奇数保持不变
l = [9,7,8,3,2,1,5,6]
for i,value in enumerate(l):
if(value % 2 == 0):l[i] = value**2
print(l)
运行:
[9, 7, 64, 3, 4, 1, 5, 36]
6. 编写程序,输入字符串,将其每个字符的ASCII码形成列表并输出
s = input("请输入一个字符串:")
l = list()
for i in s:
l.append(ord(i))
print(l)
运行:
请输入一个字符串:zgh666
[122, 103, 104, 54, 54, 54]
案例研究:猜单词游戏
通过猜单词游戏的设计和实现,帮助读者了解使用Python系列数据类型和控制流程
第六章 输入和输出
几个例题
一:运行时提示输入密码
输入密码时,一般需要不明显,则可以使用模块getpass,以保证用户输入的密码在控制台中不回显
import getpass
username = input("user:")
password = getpass.getpass("password:")
if(username == 'zgh' and password == '666'):
print('logined!')
else:
print('failed!')
input()#为了看到输出结果。因为执行完毕后,控制台会立马关闭
注意:上面这个代码,如果使用IDLE执行,会因为安全问题而执行失败

但是,在控制台中执行就没问题,看输出结果(可以看到,输入的密码不会显示出来):
user:zgh
password:
logined!
二:重定向标准输出到一个文件的示例
这种重定向由控制台完成,而与Python本身无关。
格式:
程序 > 输出文件
其目的是将显示屏从标准输出中分离,并将输出文件与标准输出关联,即程序的执行结果将写入输出文件,而不是发送到显示屏中显示
首先准备一个test.py文件(代码如下)
import sys,random
n = int(sys.argv[1])
for i in range(n):
print(random.randrange(0,100))
然后在PowerShell中:python test.py 100 > scores.txt
记住,切记,一定要注意:千万能省略python,这样写./test.py 100 > scores.txt会出现问题,生成的scores文件中会没有任何内容!!!(原因未知)
然后在当前目录下,100个[0,100)范围内的的整数生成在scores.txt文件中了
三:重定向文件到标准输入
格式:
程序 < 输入文件
其目的是将控制台键盘从标准输入中分离,并将输入文件与标准输入关联,即程序从输入文件中读取输入数据,而不是从键盘中读取输入数据
准备一个average.py文件(代码如下)
import sys
total =0.0
count = 0
for line in sys.stdin:
count += 1
total += float(line)
avg = total/count
print("average:",avg)
然后问题总是不期而至,
在PowerShell中:python average.py < scores.txt,会报错,PowerShell会提示你:“<”运算符是为将来使用而保留的。
很无奈,我只能使用cmd了,然后得出结果
四:管道
格式:
程序1 | 程序2 | 程序3 | … | 程序4
其目的是将程序1的标准输出连接到程序2的标准输入,
将程序2的标准输出连接到程序3的标准输入,以此类推
例如:
打开cmd,输入python test.py 100 | average.py,其执行结果等同于上面两个例子中的命令
使用管道更加简洁,且不用创建中间文件,从而消除了输入流和输出流可以处理的数据大小的限制,执行效率更高
五:过滤器
-
使用操作系统实用程序more逐屏显示数据
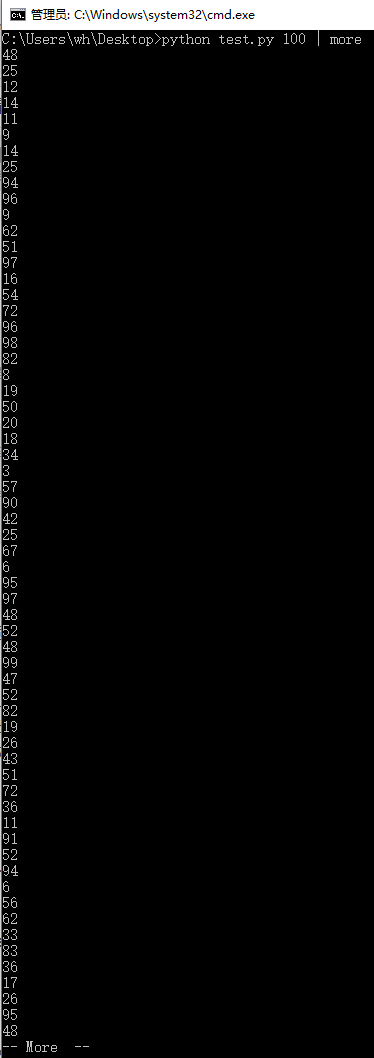
-
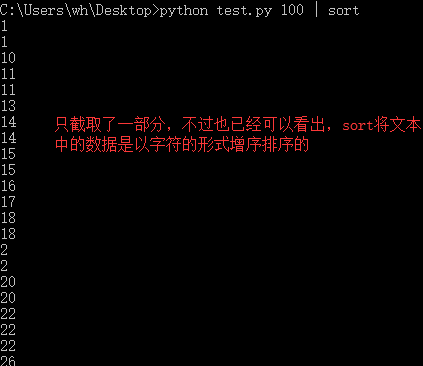
使用操作系统实用程序sort排序输出数据
more和sort都可以在一个语句中使用
填空题:1、2
print(value, ..., sep = ' ', end = '\n', file = sys.stdout, flush = False)
- sep(分隔符,默认为空格)
- end(换行符,即输入的末尾是个啥)
- file(写入到指定文件流,默认为控制台sys.stdout)
- flush(指定是否强制写入到流)
1
>>> print(1,2,3,4,5,sep='-',end='!')
1-2-3-4-5!
2
>>> for i in range(10):
print(i,end=' ')
0 1 2 3 4 5 6 7 8 9
例题及上机实践:2~5
2. 尝试修改例6.2编写的命令行参数解析的程序,解析命令行参数所输入边长的值,计算并输出正方形的周长和面积
argparse模块用于解析命名的命令行参数,生成帮助信息的Python标准模块
例6.2:解析命令行参数所输入的长和宽的值,计算并输出长方形的面积
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('--length', default = 10, type = int, help = '长度')
parser.add_argument('--width', default = 5, type = int, help = '宽度')
args = parser.parse_args()
area = args.length * args.width
print('面积 = ', area)
input()#加这一句是为了可以看到输出结果
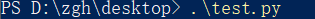
输出:面积 = 50
如果在执行这个模块时,加入两个命令行参数

输出:面积 = 36
基本上看了上面这个例子后,就可以理解argparse的用法了
本题代码:
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('--length', default = 10, type = int, help = '长度')
args = parser.parse_args()
area = args.length ** 2
perimeter = 4 * args.length
print('面积 = {0},周长 = {1}'.format(area,perimeter))
input()#加这一句是为了可以看到输出结果
在PowerShell中输入.\test.py
不给命令行参数,输出是以默认值来计算的
输出:面积 = 100,周长 = 40
给命令行参数:.\test.py --length 1
输出:面积 = 1,周长 = 4
3. 尝试修改例6.8编写读取并输出文本文件的程序,由命令行第一个参数确认所需输出的文本文件名
f = open(file, mode = 'r' , buffering = -1, encoding = None)
- file是要打开或创建的文件名,如果文件不在当前路径,需指出具体路径
- mode是打开文件的模式,模式有:
‘r’(只读)
‘w’(写入,写入前删除就内容)
‘x’(创建新文件,如果文件存在,则导致FileExistsError)
‘a’(追加)
‘b’(二进制文件)
‘t’(文本文件,默认值)
‘+’(更新,读写)- buffering表示是否使用缓存(缓存为-1,表示使用系统默认的缓冲区大小)
- encoding是文件的编码
例6.8:读取并输出文本文件
import sys
filename = sys.argv[0]#就读取本文件,骚的呀皮
f = open(filename, 'r', encoding = 'utf-8')
line_no = 0
while True:
line_no += 1
line = f.readline()
if line:
print(line_no, ":", line)
else:
break
f.close()
输出(代码输出的就是本python文件):
1 : import sys
2 :
3 : filename = sys.argv[0]#就读取本文件,骚的呀皮
4 : f = open(filename, 'r', encoding = 'utf-8')
5 :
6 : line_no = 0
7 : while True:
8 : line_no += 1
9 : line = f.readline()
10 : if line:
11 : print(line_no, ":", line)
12 : else:
13 : break
14 : f.close()
15 :
本题代码:
对例题代码进行些许修改就可以了,首先将上例中的第二个语句改为:filename = sys.argv[0],再考虑下面怎么进行
准备一个用来测试的文件test.txt:
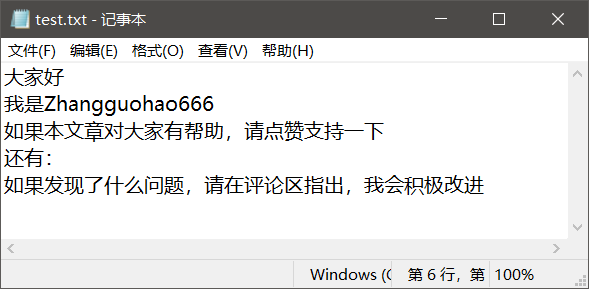
对于这个文件要注意一点(你们很可能回出现这个问题!!!),win10默认创建的文本文件的字符编码是ANSI
代码怎么写,有两种:
- 将test.txt文本文件的编码修改为utf-8,代码如上所说
记事本方式打开test.txt文件,点击文件,点击另存为,看到下方的编码(修改为utf-8) - test.txt就用默认的ANSI编码方式,再将上例代码的第三个语句修改为
f = open(filename, 'r', encoding = 'ANSI')
在PowerShell中输入:./test.py test.txt
输出:
1 : 大家好
2 : 我是Zhangguohao666
3 : 如果本文章对大家有帮助,请点赞支持一下
4 : 还有:
5 : 如果发现了什么问题,请在评论区指出,我会积极改进
4. 尝试修改例6.9编写利用with语句读取并输出文本文件的程序,由命令行第一个参数确认所需输出的文本文件名
为了简化操作,Python语言中与资源相关的对象可以实现上下文管理协议,可以使用with语句,确保释放资源。
with open(file,mode) as f:
例6.9:利用with语句读取并输出文本文件
import sys
filename = sys.argv[0]
line_no = 0
with open(filename, 'r', encoding = 'utf-8') as f:
for line in f:
line_no += 1
print(line_no, ":", line)
f.close()
基本上,看这个例子,就可以上手with语句了
本题代码:
还是上一题准备的文本文件,
代码一(文本文件的编码为默认的ANSI):
import sys
filename = sys.argv[1]
line_no = 0
with open(filename, 'r', encoding = 'ANSI') as f:
for line in f:
line_no += 1
print(line_no, ":", line)
f.close()
代码二(将文本文件的编码修改为utf-8):
import sys
filename = sys.argv[1]
line_no = 0
with open(filename, 'r', encoding = 'utf-8') as f:
for line in f:
line_no += 1
print(line_no, ":", line)
f.close()
本题的输出,我再不要脸的放一次吧:
1 : 大家好
2 : 我是Zhangguohao666
3 : 如果本文章对大家有帮助,请点赞支持一下
4 : 还有:
5 : 如果发现了什么问题,请在评论区指出,我会积极改进
5. 尝试修改例6.12编写标准输出流重定向的程序,从命令行第一个参数中获取n的值,然后将0-n,0-n的2倍值,2的0-n次幂的列表打印输出到out.log文件中
例6.12:从命令行第一个参数中获取n的值,然后将0-n,2的0-n次幂的列表打印输出到out.log文件中
- 标准输入流文件对象:sys.stdin,
默认值为sys.__stdin__- 标准输出流文件对象:sys.stdout,
默认值为sys.__stdout__- 错误输出流文件对象(标准错误流文件对象):sys.stderr
默认值为sys.__stderr__
书中给的代码是这样的:
import sys
n = int(sys.argv[1])
power = 1
i = 0
f = open('out.log', 'w')
sys.stdout = f
while i <= n:
print(str(i), ' ', str(power))
power = 2*power
i += 1
sys.stdout = sys.__stdout__
如果使用的编辑器是PyCharm(现在大多数编辑器会帮你对代码进行优化和处理一些隐患),运行书中的这个代码没有问题。
但是:
若使用的编辑器是python自带的IDLE,运行这个代码有问题!
第一:out.log文件会生成,但是没有东西
(发现文件关闭不了(就是×不掉),
确定是文件没关闭(f.close())的原因)
第二:控制台没有输出’done’语句(估计是IDLE编辑器处理不了__stdout__这个值)
经过研究后,发现(基于IDLE编辑器):
如果在上面的代码中加入f.close()后,该输入的东西都成功输入进out.log文件了,
但是,
还有一个问题
控制台依旧没有输出’done’语句
经过一步步的断点调试(就是手动写print)
发现sys.stdout = sys.__stdout__不会执行
然后进行改动后,就可以了,代码如下:
(既然__stdout__不好使,就使用中间变量)
import sys
n = int(sys.argv[1])
power = 1
i = 0
output = sys.stdout
f = open('out.log', 'w')
sys.stdout = f
while i <= n:
print(str(i), ' ', str(power))
power = 2*power
i += 1
f.close()
sys.stdout = output
print('done!')#这一句是用来检测上面的代码是否成功执行
问题虽然解决,但是原因没有彻底弄清楚,求助。。。。。。
本题代码:
import sys
n = int(sys.argv[1])
power = 1
i = 0
output = sys.stdout
f = open('out.log', 'w')
sys.stdout = f
while i <= n:
print(str(i), ' ', str(2*i), ' ', str(power))
power = 2*power
i += 1
f.close()
sys.stdout = output
print('done!')#这一句是用来检测上面的代码是否成功执行
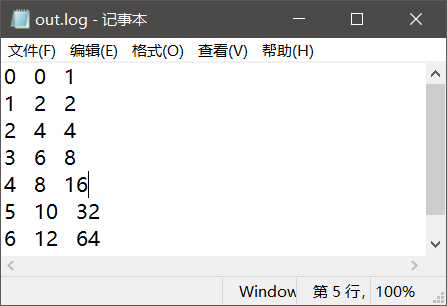
比如时输入的命令行参数是6
输出:
案例研究:21点扑克牌游戏
通过21点扑克牌游戏的设计和实现,了解使用Python数据类型、控制流程和输入输出
第七章 错误和异常处理
Python语言采用结构化的异常处理机制捕获和处理异常
而我感觉,Python在这方面的知识点其实和Java的差不多
几个例题
一:程序的错误和异常处理
- 语法错误
指源代码中的拼写错误,这些错误导致Python编译器无法把Python源代码转换为字节码,故也称之为编译错误
- 运行时错误
在解释执行过程中产生的错误
例如:
- 程序中没有导入相关的模块,NameError
- 程序中包括零除运算,ZeroDivisionError
- 程序中试图打开不存在的文件,FileNotFoundError
- 逻辑错误
程序可以执行(程序运行本身不报错),但执行结果不正确。
对于逻辑错误,Python解释器无能为力,需要用户根据结果来调试判断
大部分由程序错误而产生的错误和异常一般由Python虚拟机自动抛出。另外,在程序中如果判断某种错误情况,可以创建相应的异常类的对象,并通过raise语句抛出
>>> a = -1
>>> if(a < 0): raise ValueError("数值不能为负数")
Traceback (most recent call last):
File "<pyshell#9>", line 1, in <module>
if(a < 0): raise ValueError("数值不能为负数")
ValueError: 数值不能为负数
>>>
在程序中的某个方法抛出异常后,Python虚拟机通过调用堆栈查找相应的异常捕获程序。如果找到匹配的异常捕获程序(即调用堆栈中的某函数使用try…except语句捕获处理),则执行相应的处理程序(try…except语句中匹配的except语句块)
如果堆栈中没有匹配的异常捕获程序,则Python虚拟机捕获处理异常,在控制台打印出异常的错误信息和调用堆栈,并中止程序的执行
二:try …except…else…finally
try:
可能产生异常的语句
except Exception1:
发生Exception1时执行的语句
except (Exception2,Exception3):
发生Exception2或Exception3时执行的语句
except Exception4 as e:
发生Exception4时执行的语句,Exception4的实例是e
except:
捕获其他所有异常
else:
无异常时执行的语句
finally:
不管异常发生与否都保证执行的语句
except语句可以写多个,但是要注意一点:系统是自上而下匹配发生的异常,所以用户需要将带有最具体的(即派生类程度最高的)异常类的except写在前面
三:创建自定义异常,处理应用程序中出现的负数参数的异常
自定义异常类一般继承于Exception或其子类。自定义异常类的名称一般以Error或Exception为后缀
>>> class NumberError(Exception):
def __init__(self,data):
Exception.__init__
(self,data)
self.data = data
def __str__(self):
return self.data + ':非法数值(<0)'
>>>
>>> def total(data):
total = 0
for i in data:
if i < 0: raise NumberError(str(i))
total += 1
return total
>>>
>>> data1 = (44, 78, 90, 80, 55)
>>> print("sum: ",total(data1))
sum: 5
>>>
>>> data2 = (44, 78, 90, 80, -1)
>>> print("sum: ",total(data2))
Traceback (most recent call last):
File "<pyshell#24>", line 1, in <module>
print("sum: ",total(data2))
File "<pyshell#18>", line 4, in total
if i < 0: raise NumberError(str(i))
NumberError: -1:非法数值(<0)
>>>
四:断言处理
用户在编写程序时,在调试阶段往往需要判断代码执行过程中变量的值等信息:
- 用户可以使用print()函数打印输出结果
- 也可以通过断点跟踪调试查看变量
- 但使用断言更加灵活
assert语句和AssertionError
断言的声明:
assert <布尔表达式>
即:if __debug__: if not testexpression: raise AssertionErrorassert <布尔表达式>,<字符串表达式>
即:if __debug__: if not testexpression: raise AssertionError(data)
字符串表达式(即data)是断言失败时输出的失败消息
__debug__也是布尔值,Python解释器有两种:调试模式和优化模式
- 调试模式:
__debug__ == True - 优化模式:
__debug__ == False
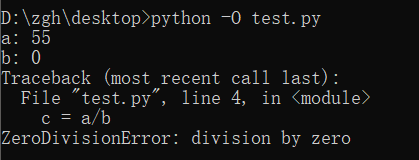
在学习中,对于执行一个py模块(比如test.py)我们通常在cmd中这么输入python test.py,而这默认是调试模式。
如果我们要使用优化模式来禁用断言来提高程序效率,我们可以加一个运行选项-O,在控制台中这么输入python -O test.py
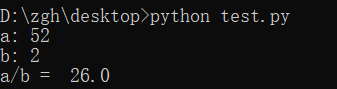
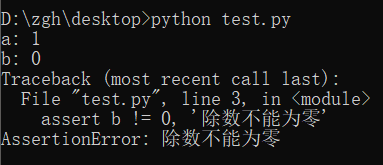
看一下断言的示例吧,理解一下用法:
a =int(input("a: "))
b =int(input("b: "))
assert b != 0, '除数不能为零'
c = a/b
print("a/b = ", c)
cmd出场:
输入正确数值时:
输入错误数值时:
禁用断言,并且输入错误数值时:
案例研究:使用调试器调试Python程序
了解使用Python调试器调试程序的方法
第八章 函数和函数式编程
一些知识点总结和几个例题
Python中函数的分类:
- 内置函数
在程序中可以直接使用 - 标准库函数
Python语言安装程序同时会安装若干标准库,例如math、random等 - 第三方库函数
Python社区提供了许多其它高质量的库,在下载、安装这些库后,通过import语句可以导入库 - 用户自定义函数
- 函数名为有效的标识符(命名规则为全小写字母,可以使用下划线增加可阅读性,例如
my_func()) - 函数可以使用return返回值
如果函数体中包含return语句,则返回值,
否则不返回,即返回值为空(None),无返回值的函数相当于其它编程语言中的过程
调用函数之前程序必须先执行def语句,创建函数对象
- 内置函数对象会自动创建
- import导入模块时会执行模块中的def语句,创建模块中定义的函数
- Python程序结构顺序通常为
import语句>函数定义>全局代码
一:产生副作用的函数,纯函数
打印等腰三角形
n = int(input("行数:"))
def print_star(n):
print((" * " * n).center(50))
for i in range(1, 2*n, 2):
print_star(i)
输出:
行数:5
*
* * *
* * * * *
* * * * * * *
* * * * * * * * *
上面代码中的print_star()是一个产生副作用的函数,其副作用是向标准输出写入若干星号
- 副作用:例如读取键盘输入,产生输出,改变系统的状态等
- 在一般情况下,产生副作用的函数相当于其它程序设计语言中的过程,可以省略return语句
定义计算并返回第n阶调和数(1+1/2+1/3+…+1/n)的函数,输出前n个调和数
def harmonic(n):
total = 0.0
for i in range(1, n+1):
total += 1.0/i
return total
n = int(input("n:"))
print("输出前n个调和数的值:")
for i in range(1, n+1):
print(harmonic(i))
输出:
n:8
输出前n个调和数的值:
1.0
1.5
1.8333333333333333
2.083333333333333
2.283333333333333
2.4499999999999997
2.5928571428571425
2.7178571428571425
上面代码中的harmonic()是纯函数
纯函数:给定同样的实际参数,其返回值唯一,且不会产生其它的可观察到的副作用
注意:编写同时产生副作用和返回值的函数通常被认为是不良编程风格,但有一个例外,即读取函数。例如,input()函数既可以返回一个值,又可以产生副作用(从标准输入中读取并消耗一个字符串)
二:传递不可变对象、可变对象的引用
- 实际参数值默认按位置顺序依次传递给形式参数。如果参数个数不对,将会产生错误
在调用函数时:
- 若传递的是不可变对象(例如:int、float、bool、str对象)的引用,则如果函数体中修改对象的值,其结果实际上是创建了一个新的对象
i = 1
def func(i,n):
i += n
return i
print(i)#1
func(i,10)
print(i)#1
执行函数func()后,i依旧为1,而不是11
- 若传递的是可变对象(例如:list对象)的引用,则在函数体中可以直接修改对象的值
import random
def shuffle(a):
n = len(a)
for i in range(n):
r = random.randrange(i,n)
a[i],a[r] = a[r],a[i]
a = [1,2,3,4,5]
print("初始:",a)
shuffle(a)
print("调用函数后:",a)
输出:
初始: [1, 2, 3, 4, 5]
调用函数后: [1, 5, 4, 3, 2]
三:可选参数,命名参数,可变参数,强制命名参数
可选参数
- 在声明函数时,如果希望函数的一些参数是可选的,可以在声明函数时为这些参数指定默认值
>>> def babbles(words, times=1):
print(words * times)
>>> babbles('Hello')
Hello
>>>
>>> babbles("Hello", 2)
HelloHello
>>>
注意到一点:必须先声明没有默认值的形参,然后再声明有默认值的形参,否则报错。 这是因为在函数调用时默认是按位置传递实际参数的。
怎么理解上面那句话呢?
默认是按位置传递实际参数(如果有默认值的形参在左边,无默认值的形参在右,那么在调用函数时,你的实参该怎么传递呢?)
命名参数
- 位置参数:当函数调用时,实参默认按位置顺序传递形参
- 命名参数(关键字参数):按名称指定传入的参数
参数按名称意义明确
传递的参数与顺序无关
如果有多个可选参数,则可以选择指定某个参数值
基于期中成绩和期末成绩,按照指定的权重计算总评成绩
>>> def my_sum(mid_score, end_score, mid_rate = 0.4):
score = mid_score*mid_rate + end_score*(1-mid_rate)
print(format(score,'.2f'))
>>> my_sum(80,90)
86.00
>>> my_sum(mid_score = 80,end_score = 90)
86.00
>>> my_sum(end_score = 90,mid_score = 80)
86.00
>>>
可变参数
- 在声明函数时,可以通过带星号的参数(例如:
def func(* param))向函数传递可变数量的实参,调用函数时,从那一点后所有的参数被收集为一个元组 - 在声明函数时,可以通过带双星号的参数(例如:
def func(** param))向函数传递可变数量的实参,调用函数时,从那一点后所有的参数被收集为一个字典
利用带星的参数计算各数字的累加和
>>> def my_sum(a,b,*c):
total = a+b
for i in c:
total += i
return total
>>> print(my_sum(1,2))
3
>>> print(my_sum(1,2,3,4,5,6))
21
利用带星和带双星的参数计算各数字的累加和
>>> def my_sum(a,b,*c,**d):
total = a+b
for i in c:
total += i
for key in d:
total += d[key]
return total
>>> print(my_sum(1,2))
3
>>> print(my_sum(1,2,3,4))
10
>>> print(my_sum(1,2,3,4,male=1,female=2))
13
强制命名参数
- 在带星号的参数后面声明参数会导致强制命名参数(Keyword-only),然后在调用时必须显式使用命名参数传递值
- 因为按位置传递的参数默认收集为一个元组,传递给前面带星号的可变参数
>>> def my_sum(*, mid_score, end_score, mid_rate = 0.4):
score = mid_score*mid_rate + end_score*(1-mid_rate)
print(format(score,'.2f'))
>>> my_sum(mid_score=80,end_score=90)
86.00
>>> my_sum(end_score=90,mid_score=80)
86.00
>>> my_sum(80,90)
Traceback (most recent call last):
File "<pyshell#47>", line 1, in <module>
my_sum(80,90)
TypeError: my_sum() takes 0 positional arguments but 2 were given
>>>
四:全局语句global示例,非局部语句nonlocal示例,输出局部变量和全局变量
- 在函数体中可以引用全局变量,但是要为定义在函数外的全局变量赋值,需要使用global语句
pi = 2.1415926
e = 2.7182818
def my_func():
global pi
pi = 3.14
print("global pi = ", pi)
e = 2.718
print("local e = ", e)
print('module pi = ', pi)
print('module e = ', e)
my_func()
print('module pi = ', pi)
print('module e = ', e)
输出:
module pi = 2.1415926
module e = 2.7182818
global pi = 3.14
local e = 2.718
module pi = 3.14
module e = 2.7182818
- 在函数体中可以定义嵌套函数,在嵌套函数中如果要为定义在上级函数体的局部变量赋值,可以使用nonlocal
def outer_func():
tax_rate = 0.17
print('outer function tax rate is ',tax_rate)
def inner_func():
nonlocal tax_rate
tax_rate = 0.01
print('inner function tax rate is ',tax_rate)
inner_func()
print('outer function tax rate is ',tax_rate)
outer_func()
输出:
outer function tax rate is 0.17
inner function tax rate is 0.01
outer function tax rate is 0.01
- 输出局部变量和全局变量
- 内置函数
locals(),局部变量列表 - 内置函数
globals(),全局变量列表
五:获取和设置最大递归数
在sys模块中,函数getrecursionlimit()和setrecursionlimit()用于获取和设置最大递归次数
>>> import sys
>>> sys.getrecursionlimit()
1000
>>> sys.setrecursionlimit(666)
>>> sys.getrecursionlimit()
666
>>>
六:三个有趣的内置函数:eval()、exec()、compile()
eval
- 对动态表达式进行求值,返回值
eval(expression, globals=None, locals=None)
expression是动态表达式的字符串
globals和locals是求值时使用的上下文环境的全局变量和局部变量,如果不指定,则使用当前运行上下文
>>> x = 2
>>> str_func = input("请输入表达式:")
请输入表达式:x**2+2*x+1
>>> eval(str_func)
9
>>>
exec
- 可以执行动态表达式,不返回值
exec(str, globals=None, locals=None)
>>> exec("for i in range(10): print(i, end=' ')")
0 1 2 3 4 5 6 7 8 9
>>>
compile
- 编译代码为代码对象,可以提高效率
compile(source, filename, mode)
source为代码语句的字符串;如果是多行语句,则每一行的结尾必须有换行符\n
filename为包含代码的文件
mode为编码方式,可以为'exec'(用于语句序列的执行),可以为'eval'(用于表达式求值),可以为'single'(用于单个交互语句)
>>> co = compile("for i in range(10): print(i, end=' ')", '', 'exec')
>>> exec(co)
0 1 2 3 4 5 6 7 8 9
>>>
七:map(),filter()
- map(f, iterable,…),将函数
f应用于可迭代对象,返回结果为可迭代对象
示例1:
>>> def is_odd(x):
return x%2 == 1
>>> list(map(is_odd,range(5)))
[False, True, False, True, False]
>>>
示例2:
>>> list(map(abs,[1,-2,3,-4,5,-6]))
[1, 2, 3, 4, 5, 6]
>>>
示例3:
>>> list(map(str,[1,2,3,4,5]))
['1', '2', '3', '4', '5']
>>
示例4:
>>> def greater(x,y):
return x>y
>>> list(map(greater,[1,5,7,3,9],[2,8,4,6,0]))
[False, False, True, False, True]
>>>
- filter(f, iterable),将函数
f应用于每个元素,然后根据返回值是True还是False决定保留还是丢弃该元素,返回结果为可迭代对象
示例1(返回个位数的奇数):
>>> def is_odd(x):
return x%2 == 1
>>> list(filter(is_odd, range(10)))
[1, 3, 5, 7, 9]
>>>
示例2(返回三位数的回文):
>>> list(filter(is_palindrome, range(100, 1000)))
[101, 111, 121, 131, 141, 151, 161, 171, 181, 191, 202, 212, 222, 232, 242, 252, 262, 272, 282, 292, 303, 313, 323, 333, 343, 353, 363, 373, 383, 393, 404, 414, 424, 434, 444, 454, 464, 474, 484, 494, 505, 515, 525, 535, 545, 555, 565, 575, 585, 595, 606, 616, 626, 636, 646, 656, 666, 676, 686, 696, 707, 717, 727, 737, 747, 757, 767, 777, 787, 797, 808, 818, 828, 838, 848, 858, 868, 878, 888, 898, 909, 919, 929, 939, 949, 959, 969, 979, 989, 999]
>>>
八:Lambda表达式和匿名函数
匿名函数广泛应用于需要函数对象作为参数、函数比较简单并且只使用一次的场合
格式:
lambda arg1,arg2... : <expression>
其中,arg1、arg2等为函数的参数,<expression>为函数的语句,其结果为函数的返回值
示例1(计算两数之和):
>>> f = lambda x,y : x+y
>>> type(f)
<class 'function'>
>>> f(1,1)
2
>>>
示例2(返回奇数):
>>> list(filter(lambda x:x%2==1, range(10)))
[1, 3, 5, 7, 9]
>>>
示例3(返回非空元素):
>>> list(filter(lambda s:s and s.strip(), ['A', '', 'B', None, 'C', ' ']))
['A', 'B', 'C']
>>>
补充:
strip()用来去除头尾字符、空白符(\n,\r,\t,’’,即换行、回车、制表、空格)lstrip()用来去除开头字符、空白符rstrip()用来去除结尾字符、空白符
再补充一点:
\n到下一行的开头\r回到这一行的开头
示例4(返回大于0的元素):
>>> list(filter(lambda x:x>0, [1,0,-2,8,5]))
[1, 8, 5]
>>>
示例5(返回元素的平方):
>>> list(map(lambda x:x*x, range(10)))
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
>>>
九:operator模块和操作符函数
Python内置操作符的函数接口,它定义了对应算术和比较等操作的函数,用于map()、filter()等需要传递函数对象作为参数的场合,可以直接使用而不需要使用函数定义或者Lambda表达式,使得代码更加简洁
示例1(concat(x,y)对应于x+y):
>>> import operator
>>> a = 'hello'
>>>> operator.concat(a, ' world')
'hello world'
实例2(operator.gt对应于操作符>):
>>> import operator
>>> list(map(operator.gt, [1,5,7,3,9],[2,8,4,6,0]))
[False, False, True, False, True]
>>>
十:functools.reduce(),偏函数functools.partial(),sorted()
functools.reduce()
functools.reduce(func, iterable[, iterable[, initializer]])
- 使用指定的带两个参数的函数
func对一个数据集合的所有数据进行下列操作:- 使用第一个和第二个数据作为参数用
func()函数运算,得到的结果再与第三个数据作为参数用func()函数运算,依此类推,最后得到一个结果- 可选的
initialzer为初始值
示例:
>>> import functools,operator
>>> functools.reduce(operator.add, [1,2,3,4,5])
15
>>> functools.reduce(operator.add, [1,2,3,4,5], 10)
25
>>> functools.reduce(operator.add, range(1,101))
5050
>>>
>>> functools.reduce(operator.mul, range(1,11))
3628800
偏函数functools.partial()
functools.partial(func, *arg, **keywords)
- 通过把一个函数的部分参数设置为默认值的方式返回一个新的可调用(callable)的partial对象
- 主要用于设置预先已知的参数,从而减少调用时传递参数的个数
示例(2的n次方):
>>> import functools,math
>>> pow2 = functools.partial(math.pow, 2)
>>> list(map(pow2, range(11)))
[1.0, 2.0, 4.0, 8.0, 16.0, 32.0, 64.0, 128.0, 256.0, 512.0, 1024.0]
>>>
十一:sorted()
sorted(iterable, *, key=None, reverse=False)
- iterable是待排序的可迭代对象
- key是比较函数(默认为None,按自然顺序排序)
- reverse用于指定是否逆序排序
示例1(数值。默认自然排序):
>>> sorted([1,6,4,-2,9])
[-2, 1, 4, 6, 9]
>>> sorted([1,6,4,-2,9], reverse=True)
[9, 6, 4, 1, -2]
>>> sorted([1,6,4,-2,9], key=abs)
[1, -2, 4, 6, 9]
示例2(字符串,默认按字符串字典序排序):
>>> sorted(['Dod', 'cat', 'Rabbit'])
['Dod', 'Rabbit', 'cat']
>>> sorted(['Dod', 'cat', 'Rabbit'], key=str.lower)
['cat', 'Dod', 'Rabbit']
>>> sorted(['Dod', 'cat', 'Rabbit'], key=len)
['Dod', 'cat', 'Rabbit']
示例3(元组,默认按元组的第一个元素排序):
>>> sorted([('Bob', 75), ('Adam', 92), ('Lisa', 88)])
[('Adam', 92), ('Bob', 75), ('Lisa', 88)]
>>> sorted([('Bob', 75), ('Adam', 92), ('Lisa', 88)], key=lambda t:t[1])
[('Bob', 75), ('Lisa', 88), ('Adam', 92)]
十二:函数装饰器
这玩意就很有意思了,很Java语言中的注解是很相像的
示例1:
import time,functools
def timeit(func):
def wrapper(*s):
start = time.perf_counter()
func(*s)
end = time.perf_counter()
print('运行时间:', end - start)
return wrapper
@timeit
def my_sum(n):
sum = 0
for i in range(n): sum += i
print(sum)
if __name__ == '__main__':
my_sum(10_0000)
结果:
4999950000
运行时间: 0.013929100000000028
怎么理解上面的代码呢?
- 首先,
timeit()返回的是wrapper,而不是执行(没有小括号) @timeit相当于,在调用my_sum()的前一刻,会执行这么个语句:my_sum = timeit(my_sum)
示例2:
def makebold(fn):
def wrapper(*s):
return "<b>" + fn(*s) + "</b>"
return wrapper
def makeitalic(fn):
def wrapper(*s):
return "<i>" + fn(*s) + "</i>"
return wrapper
@makebold
@makeitalic
def htmltags(str1):
return str1
print(htmltags('Hello'))
输出:
<b><i>Hello</i></b>
选择题:1~5
1
>>> print(type(lambda:None))
<class 'function'>
2
>>> f = lambda x,y:x*y
>>> f(12, 34)
408
3
>>> f1 = lambda x:x*2
>>> f2 = lambda x:x**2
>>> print(f1(f2(2)))
8
4
>>> def f1(p, **p2):
print(type(p2))
>>> f1(1, a=2)
<class 'dict'>
5
>>> def f1(a,b,c):
print(a+b)
>>> nums = (1,2,3)
>>> f1(*nums)
3
思考题:4~11
4
>>> d = lambda p:p*2
>>> t = lambda p:p*3
>>> x = 2
>>> x = d(x)
>>> x = t(x)
>>> x = d(x)
>>> print(x)
24
5
>>> i = map(lambda x:x**2, (1,2,3))
>>> for t in i:
print(t, end=' ')
1 4 9
6
>>> def f1():
"simple function"
pass
>>> print(f1.__doc__)
simple function
7
>>> counter = 1
>>> num = 0
>>> def TestVariable():
global counter
for i in (1, 2, 3) : counter += 1
num = 10
>>> TestVariable()
>>> print(counter, num)
4 0
8
>>> def f(a,b):
if b==0 : print(a)
else : f(b, a%b)
>>> print(f(9,6))
3
None
求最大公约数
9
>>> def aFunction():
"The quick brown fox"
return 1
>>> print(aFunction.__doc__[4:9])
quick
10
>>> def judge(param1, *param2):
print(type(param2))
print(param2)
>>> judge(1, 2, 3, 4, 5)
<class 'tuple'>
(2, 3, 4, 5)
11
>>> def judge(param1, **param2):
print(type(param2))
print(param2)
>>> judge(1, a=2, b=3, c=4, d=5)
<class 'dict'>
{'a': 2, 'b': 3, 'c': 4, 'd': 5}
上机实践:2~5
2. 编写程序,定义一个求阶乘的函数fact(n),并编写测试代码,要求输入整数n(n>=0)。请分别使用递归和非递归方式实现
递归方式:
def fact(n):
if n == 0 :
return 1
return n*fact(n-1)
n = int(input("请输入整数n(n>=0):"))
print(str(n)+" ! = " + str(fact(n)))
非递归方式:
def fact(n):
t = 1
for i in range(1,n+1):
t *= i
return t
n = int(input("请输入整数n(n>=0):"))
print(str(n)+" ! = " + str(fact(n)))
输出:
请输入整数n(n>=0):5
5 ! = 120
3. 编写程序,定义一个求Fibonacci数列的函数fib(n),并编写测试代码,输出前20项(每项宽度5个字符位置,右对齐),每行输出10个。请分别使用递归和非递归方式实现
递归方式:
def fib(n):
if (n == 1 or n == 2):
return 1
return fib(n-1)+fib(n-2)
for i in range(1,21):
print(str(fib(i)).rjust(5,' '),end = ' ')
if i %10 == 0:
print()
非递归方式:
def fib(n):
if (n == 1 or n == 2):
return 1
n1 = n2 = 1
for i in range(3,n+1):
n3 = n1+n2
n1 = n2
n2 = n3
return n3
for i in range(1,21):
print(str(fib(i)).rjust(5,' '),end = ' ')
if i %10 == 0:
print()
输出:
1 1 2 3 5 8 13 21 34 55
89 144 233 377 610 987 1597 2584 4181 6765
4. 编写程序,利用可变参数定义一个求任意个数数值的最小值的函数min_n(a,b,*c),并编写测试代码。例如对于“print(min_n(8, 2))”以及“print(min_n(16, 1, 7, 4, 15))”的测试代码
def min_n(a,b,*c):
min_number = a if(a < b) else b
for n in c:
if n < min_number:
min_number = n
return min_number
print(min_n(8, 2))
print(min_n(16, 1, 7, 4, 15))
输出:
2
1
5. 编写程序,利用元组作为函数的返回值,求序列类型中的最大值、最小值和元素个数,并编写测试代码,假设测试代码数据分别为s1=[9, 7, 8, 3, 2, 1, 55, 6]、s2=[“apple”, “pear”, “melon”, “kiwi”]和s3="TheQuickBrownFox"
def func(n):
return (max(n),min(n),len(n))
s1=[9, 7, 8, 3, 2, 1, 55, 6]
s2=["apple", "pear", "melon", "kiwi"]
s3="TheQuickBrownFox"
for i in (s1,s2,s3):
print("list = ", i)
t = func(i)
print("最大值 = {0},最小值 = {1},元素个数 = {2}".format(t[0], t[1], t[2]))
输出:
list = [9, 7, 8, 3, 2, 1, 55, 6]
最大值 = 55,最小值 = 1,元素个数 = 8
list = ['apple', 'pear', 'melon', 'kiwi']
最大值 = pear,最小值 = apple,元素个数 = 4
list = TheQuickBrownFox
最大值 = x,最小值 = B,元素个数 = 16
案例研究:井字棋游戏
https://blog.csdn.net/Zhangguohao666/article/details/103280740
了解Python函数的定义和使用
第九章 面向对象的程序设计
例9.1~例9.53
补充:类名为有效的标识符,一般为多个单词组成的名称,每个单词除第一个字母大写外,其余的字母均小写
一:类对象和实例对象
例9.1(创建类对象和实例对象)
>>> class Person:
pass
>>> p = Person()
>>> print(Person, type(Person), id(Person))
<class '__main__.Person'> <class 'type'> 2096437524072
>>> print(p, type(p), id(p))
<__main__.Person object at 0x000001E81DA88BC8> <class '__main__.Person'> 2096441625544
例9.2(实例对象的创建和使用)
- Python创建实例对象的方法无须使用关键字new,而是直接像调用函数一样调用类对象并传递参数,因此类对象是可调用对象(Callable)
- 在Python内置函数中,bool、float、int、str、list、dict、set等均为可调用内置类对象
>>> c = complex(1, 2)
>>> c.conjugate()
(1-2j)
>>> c.real
1.0
二:属性
例9.3(定义实例属性)
Python变量不需要声明,可直接使用。所以建议用户在类定义的开始位置初始化类属性,或者在构造函数
__init__()中初始化实例属性
>>> class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def say_hi(self):
print("您好,我叫", self.name)
>>> p = Person('zgh', 18)
>>> p.say_hi()
您好,我叫 zgh
>>> print(p.age)
18
例9.4(定义类对象属性)
类属性如果通过
obj.属性名来访问,则属于该实例地实例属性
>>> class Person:
count = 0
name = "Person"
>>> Person.count += 1
>>> print(Person.count)
1
>>> print(Person.name)
Person
>>> p1 = Person(); p2 = Person()
>>> print(p1.name, p2.name)
Person Person
>>> Person.name = "雇员"
>>> print(p1.name, p2.name)
雇员 雇员
>>> p1.name = '员工'
>>> print(p1.name, p2.name)
员工 雇员
例9.5(私有属性)
Python类的成员没有访问控制限制,这与其他面向对象语言不同
通常约定以两个下划线开头,但是不以两个下划线结束的属性是私有的(private),其它为公共的(public)
>>> class Person:
__name = 'class Person'
def get_name():
print(Person.__name)
>>> Person.get_name()
class Person
>>> Person.__name
Traceback (most recent call last):
File "<pyshell#46>", line 1, in <module>
Person.__name
AttributeError: type object 'Person' has no attribute '__name'
例9.6、9.7、9.8(property装饰器)
- 面向对象编程的封装性原则要求不直接访问类中的数据成员
- 在Python中可以定义私有属性,然后定义相应的访问该私有属性的函数,并使用@property装饰器来装饰这些函数
- 程序可以把函数“当作”属性访问,从而提供更加友好的访问方式
>>> class Person:
def __init__(self, name):
self.__name = name
@property
def name(self):
return self.__name
>>> p = Person('zgh666')
>>> print(p.name)
zgh666
尝试了一个想法(如果对象也有一个同名的属性,会怎么样?):
>>> class Person:
name = 'zgh'
def __init__(self, name):
self.__name = name
@property
def name(self):
return self.__name
>>> p = Person('zgh666')
>>> print(p.name)
zgh666
很显然,返回的是装饰器修饰的name函数
@property装饰器默认提供一个只读属性,如果需要,可以使用对应的getter、setter和deleter装饰器实现其他访问器函数
>>> class Person:
def __init__(self, name):
self.__name = name
@property
def name(self):
return self.__name
@name.setter
def name(self, value):
self.__name = value
@name.deleter
def name(self):
del self.__name
>>> p = Person('zgh')
>>> p.name = 'Zhanggguohao'
>>> print(p.name)
Zhanggguohao
property(fget=None, fset=None, fdel=None, doc=None)
>>> class Person:
def __init__(self, name):
self.__name = name
def getname(self):
return self.__name
def setname(self, value):
self.__name = value
def delname(self):
del self.__name
name = property(getname, setname,delname, "I'm the 'name' property.")
>>> p = Person('zgh')
>>> print(p.name)
zgh
>>> p.name = 'zgh666'
>>> print(p.name)
zgh666
例9.9(自定义属性)
在Python中,可以赋予一个对象自定义的属性,即类定义中不存在的属性。对象通过特殊属性
__dict__存储自定义属性
>>> class Person:
pass
>>> p = Person()
>>> p.name = 'custom name'
>>> p.name
'custom name'
>>> p.__dict__
{'name': 'custom name'}
通过重载
__getattr__和__setattr__可以拦截对成员的访问,从而自定义属性的行为
__getattr__()只有在访问不存在的成员时才会被调用__getattribute__()拦截所有的(包括不存在)获取操作__setattr__()设置属性__delattr__()删除属性
>>> class CustomAttribute(object):
def __init__(self):
pass
def __getattribute__(self, name):
return str.upper(object.__getattribute__(self, name))
def __setattr__(self, name, value):
object.__setattr__(self, name, str.strip(value))
>>> p = CustomAttribute()
>>> p.firstname = ' mary'
>>> print(p.firstname)
MARY
三:方法
对象实例方法的第一个参数一般为self,但是用户调用时不需要也不能给该参数传值
例9.11(静态方法:摄氏温度与华氏温度之间的相互转换)
class TemperatureConverter:
@staticmethod
def c2f(t_c):
return (float(t_c) * 9/5) + 32
@staticmethod
def f2c(t_f):
return ((float(t_f) - 32) * 5/9)
print("1. 从摄氏温度到华氏温度.")
print("2. 从华氏温度到摄氏温度.")
choice = int(input("请选择转换方向:"))
if choice == 1:
t_c = float(input("请输入摄氏温度:"))
t_f = TemperatureConverter.c2f(t_c)
print("华氏温度为:{0:.2f}".format(t_f))
elif choice == 2:
t_f = float(input("请输入华氏温度:"))
t_c = TemperatureConverter.f2c(t_f)
print("摄氏温度为:{0:.2f}".format(t_c))
else:
print("无此选项,只能选择1或2")
输出:
====================== RESTART: D:\zgh\desktop\test.py ======================
1. 从摄氏温度到华氏温度.
2. 从华氏温度到摄氏温度.
请选择转换方向:1
请输入摄氏温度:30
华氏温度为:86.00
>>>
====================== RESTART: D:\zgh\desktop\test.py ======================
1. 从摄氏温度到华氏温度.
2. 从华氏温度到摄氏温度.
请选择转换方向:2
请输入华氏温度:70
摄氏温度为:21.11
>>>
补充一个很有意思的代码:
(包含了很多知识点)
TempStr = input("请输入带有符号的温度值:")
if TempStr[-1] in ['F', 'f']:
C = (eval(TempStr[0:-1]) - 32) / 1.8
print("转化后的温度是{:.2f}C".format(C))
elif TempStr[-1] in ['C', 'c']:
F = 1.8 * eval(TempStr[0:-1]) + 32
print("转化后的温度是{:.2f}F".format(F))
else:
print("输入格式错误")
例9.12(类方法)
类方法的第一个参数为cls,但是调用时用户不需要也不能给该参数传值
>>> class Person:
classname = "zgh"
def __init__(self, name):
self.name = name
#实例方法
def f1(self):
print(self.name)
#静态方法
@staticmethod
def f2():
print("static")
#类方法
@classmethod
def f3(cls):
print(cls.classname)
>>> p = Person("666")
>>> p.f1()
666
>>> Person.f2()
static
>>> p.f2()
static
>>> Person.f3()
zgh
>>> p.f3()
zgh
>>> Person.f1()
Traceback (most recent call last):
File "<pyshell#23>", line 1, in <module>
Person.f1()
TypeError: f1() missing 1 required positional argument: 'self'
类名不能访问实例方法
补充:
- 无论是静态方法还是类方法一般通过类名来访问,也可以通过对象实例来调用
- 在静态方法中访问对象实例会导致错误
- 在类方法中访问对象实例属性会导致错误
例9.15(__init__()方法、__new__()方法、__del__()方法)
__init__()
构造函数,用于执行类的实例的初始化工作。在创建完对象后调用,初始化当前对象的实例,无返回值__new__()
是一个类方法,在创建对象时调用,返回当前对象的一个实例,一般无须重载该方法__del__()
析构函数,用于实现销毁类的实例所需的操作,如释放对象占用的非托管资源(打开的文件、网络连接等)
在默认情况下,当对象不再被使用时,__del__()方法运行。由于Python解释器实现自动垃圾回收,所以无法保证这个方法究竟在什么时候运行
但通过del语句可以强制销毁一个对象实例,从而保证调用对象实例的__del__()方法
>>> class Person:
count = 0
def __init__(self, name, age):
self.name = name
self.age = age
Person.count += 1
def __del__(self):
Person.count -= 1
def say_hi(self):
print("hello, i'm ", self.name)
def get_count():
print("count: ",Person.count)
>>> print("count: ", Person.count)
count: 0
>>> p1 = Person('zhangsan', 18)
>>> p1.say_hi()
hello, i'm zhangsan
>>> Person.get_count()
count: 1
>>> p2 = Person('lisi', 28)
>>> p2.say_hi()
hello, i'm lisi
>>> Person.get_count()
count: 2
>>> del p1
>>> Person.get_count()
count: 1
>>> del p2
>>> Person.get_count()
count: 0
例9.16(私有方法)
- 与私有属性类似,Python约定以两个下划线开头,但不以两个下划线结束的方法是私有的
- 不能直接访问私有的
>>> class Book:
def __init__(self, name, author, price):
self.name = name
self.author = author
self.price = price
def __check_name(self):
if self.name == '': return False
else: return True
def get_name(self):
if self.__check_name(): print(self.name, self.author)
else: print("No Value")
>>> b = Book("Python", 'zgh', 666)
>>> b.get_name()
Python zgh
>>> b.__check_name()#直接调用私有方法,非法
Traceback (most recent call last):
File "<pyshell#66>", line 1, in <module>
b.__check_name()
AttributeError: 'Book' object has no attribute '__check_name'
例9.17(方法的重载)
Python本身是动态语言,
- 方法的参数没有声明类型(在调用传值时确定参数的类型)
- 参数的数量由可选参数和可变参数来控制
- 故Python对象方法不需要重载,定义一个方法即可实现多种调用,从而实现相当于其他程序设计语言的重载功能
>>> class Person:
def say_hi(self, name=None):
self.name = name
if name ==None: print("hello!")
else: print("hello, i'm ", self.name)
>>> p = Person()
>>> p.say_hi()
hello!
>>> p.say_hi('zgh')
hello, i'm zgh
>>>
注意:在Python类体中定义多个重名的方法虽然不会报错,但只有最后一个方法有效,所以建议不要定义重名的方法
四:继承
- Pyhon支持多重继承,即一个派生类可以继承多个基类
- 如果在类定义中没有指定基类,则默认其基类为
object- 在声明派生类时,必须在其构造函数中调用基类的构造函数
例9.19(派生类)
>>> class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def say_hi(self):
print("hello, i'm {0}, {1} olds".format(self.name, self.age))
>>> class Student(Person):
def __init__(self, name, age, stu_id):
Person.__init__(self, name, age)
self.stu_id = stu_id
def say_hi(self):
Person.say_hi(self)
print("i'm student, my student_number is ", self.stu_id)
>>> p =Person('zhangsan',18)
>>> p.say_hi()
hello, i'm zhangsan, 18 olds
>>> s = Student('lisi', 5, '17202030118')
>>> s.say_hi()
hello, i'm lisi, 5 olds
i'm student, my student_number is 17202030118
例9.20(查看类的继承关系)
多个类的继承可以形成层次关系,通过类的方法
mro()或类的属性__mro__可以输出其继承的层次关系
>>> class A: pass
>>> class B(A): pass
>>> class C(B): pass
>>> class D(A): pass
>>> class E(B,D): pass
>>> A.mro()
[<class '__main__.A'>, <class 'object'>]
>>> B.__mro__
(<class '__main__.B'>, <class '__main__.A'>, <class 'object'>)
>>> C.mro()
[<class '__main__.C'>, <class '__main__.B'>, <class '__main__.A'>, <class 'object'>]
>>>
>>> D.mro()
[<class '__main__.D'>, <class '__main__.A'>, <class 'object'>]
>>>
>>> E.__mro__
(<class '__main__.E'>, <class '__main__.B'>, <class '__main__.D'>, <class '__main__.A'>, <class 'object'>)
例9.21(类成员的继承和重写)
>>> class Dimension:
def __init__(self, x, y):
self.x = x
self.y = y
def area(self):
pass
>>> class Circle(Dimension):
def __init__(self, r):
Dimension.__init__(self, r, 0)
def area(self):
return 3.14 * self.x * self.x
>>> class Rectangle(Dimension):
def __init__(self, w, h):
Dimension.__init__(self, w, h)
def area(self):
return self.x * self.y
>>> d1 = Circle(2.0)
>>> d2 = Rectangle(3.0, 4.0)
>>> print(d1.area(), d2.area())
12.56 12.0
五:对象的特殊方法
- 在Python对象中包含许多以双下划线开始和结束的方法,称之为特殊方法。
- 特殊方法通常在针对对象的某种操作时自动调用
例9.22(重写对象的特殊方法)
| 特殊方法 | 含义 |
|---|---|
__init__(),__del__() |
创建或销毁对象时调用 |
__setitem__(),__getitem__() |
按索引赋值、取值 |
__len__() |
对应于内置函数len() |
__repr__(self) |
对应于内置函数repr() |
__str__(self) |
对应于内置函数str() |
__bytes__(self) |
对应于内置函数bytes() |
__format__(self, format_spec) |
对应于内置函数format() |
__bool__(self) |
对应于内置函数bool() |
__hash__(self) |
对应于内置函数hash() |
__dir__(self) |
对应于内置函数dir() |
>>> class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def __str__(self):
return '{0}, {1}'.format(self.name, self.age)
>>> p = Person('zgh', '18')
>>> print(p)
zgh, 18
例9.23(运算符重载)
| 特殊方法 | 含义 |
|---|---|
__lt__(),__le__(),__eq__() |
对应于运算符<,<=,== |
__gt__(),__ge__(),__ne__() |
对应于运算符>,>=,!= |
__or__(),__ror__();__xor__(),__rxor__();__and__(),__rand__() |
对应于运算符|,^,& |
__ior__(),__ixor__(),__iand__() |
对应于运算符|=,^=,&= |
__lshift__(),__rlshift__();__rshift__(),__rrshift__() |
对应于运算符<<,>> |
__ilshift__(),__irlshift__();__irshift__(),__irrshift__() |
对应于运算符<<=,>>= |
__add__(),__radd__();__sub__(),__rsub__() |
对应于运算符+,- |
__iaddr__(),__isub__() |
对应于运算符+=,-= |
__mul__(),__rmul__();__truediv__(),__rtruediv__() |
对应于运算符*,/ |
__mod__(),__rmod__();__floordiv__(),__rfloordiv__() |
对应于运算符%,// |
__imul__(),__idiv__(),__itruediv__(),__imod__(),__ifloordiv__() |
对应于运算符*=,/=,%=,//= |
__pos__(),__neg__() |
正负号 |
__invert__() |
按位翻转 |
__pow__(),__rpow__(),__ipow__() |
指数运算 |
看了上这么多特殊方法和运算符的对应,你是否会感到一些奇怪的地方:
r,某些运算符为啥子有两个,然后其中一个的最前面加了一个r
举个例子就懂了:x.__mul__(y) == x / y;而x.__rmul__(y) == y / x- 如果上手去尝试的话,发现复合赋值运算对应的特殊方法都使用不了(未找到原因,暂过,哪位大佬知道啊,评论区留言)
>>> class MyList:
def __init__(self, *args):
self.__mylist = []
for arg in args:
self.__mylist.append(arg)
def __add__(self, n):
for i in range(0, len(self.__mylist)):
self.__mylist[i] += n
def __sub__(self, n):
for i in range(0, len(self.__mylist)):
self.__mylist[i] -= n
def __mul__(self, n):
for i in range(0, len(self.__mylist)):
self.__mylist[i] *= n
def __truediv__(self, n):
for i in range(0, len(self.__mylist)):
self.__mylist[i] /= n
def __len__(self):
return (len(self.__mylist))
def __repr__(self):
str1 = ''
for i in range(0, len(self.__mylist)):
str1 += str(self.__mylist[i]) + " "
return str1
>>> m = MyList(1, 2, 3, 4, 5)
>>> m+2
>>> m
3 4 5 6 7
>>> m -1
>>> m
2 3 4 5 6
>>> m*4
>>> m
8 12 16 20 24
>>> m/2
>>> m
4.0 6.0 8.0 10.0 12.0
>>> len(m)
5
例9.24(@functools.total_ordering装饰器)
实现了
total_ordering装饰器后,则是需要实现__eq__()以及__lt__()、__le__()、__gt__()、__ge__()中的任意一个,那么实现其他比较运算符能简化代码量
import functools
@functools.total_ordering
class Student:
def __init__(self, firstname, lastname):
self.firstname = firstname
self.lastname = lastname
def __eq__(self, other):
return ((self.lastname.lower(), self.firstname.lower()) ==
(other.lastname.lower(), other.firstname.lower()))
def __lt__(self, other):
return ((self.lastname.lower(), self.firstname.lower()) <
(other.lastname.lower(), other.firstname.lower()))
if __name__ == '__main__':
s1 = Student('Mary', 'Clinton')
s2 = Student('Mary', 'Clinton')
s3 = Student('Charlie', 'Clinton')
print(s1 == s2)
print(s1 > s3)
print(s1 < s3)
输出:
True
True
False
例9.25(定义了__call__()方法的对象称为可调用对象)
class GDistance:
def __init__(self, g):
self.g = g
def __call__(self, t):
return (self.g * t ** 2)/2
if __name__ == '__main__':
e_gdist = GDistance(9.8)
for t in range(11):
print(format(e_gdist(t), "0.2f"), end = ' ')
输出:
0.00 4.90 19.60 44.10 78.40 122.50 176.40 240.10 313.60 396.90 490.00
六:对象的引用、浅拷贝和深拷贝
例9.26(对象的引用)
对象的赋值实际上是对象的引用,在创建一个对象并把它赋值给一个变量时,该变量是指向该对象的引用,其id()返回值保持一致
>>> acc10 = ['zgh', ['zgh666', 666]]
>>> acc11 = acc10
>>> id(acc10) == id(acc11)
True
例9.27(对象的浅拷贝)
对象的赋值引用同一个对象(即:不复制对象)
如果要复制对象,可以使用下列方法之一:
- 切片操作:例如acc11[:]
- 对象实例化:例如list(acc11)
- copy模块的copy()函数:例如copy.copy(acc11)
>>> import copy
>>> acc1 = ['Charlie', ['credit', 0.0]]
>>> acc2 = acc1[:]
>>> acc3 = list(acc1)
>>> acc4 = copy.copy(acc1)
>>> id(acc1), id(acc2), id(acc3), id(acc4)
(2387738921800, 2387738921544, 2387735787656, 2387738922888)
Python复制一般是浅拷贝,即复制对象时,对象内包含的子对象并不复制,而是引用同一个子对象
>>> acc2[0] = 'zgh666'
>>> acc2[1][1] = 100.0
>>> acc1
['Charlie', ['credit', 100.0]]
>>> acc2
['zgh666', ['credit', 100.0]]
>>> id(acc1[1]) == id(acc2[1])
True
例9.28(对象的深拷贝)
使用copy模块的deepcopy()函数
>>> import copy
>>> acc1 = ['Charlie', ['credit', 0.0]]
>>> acc5 = copy.deepcopy(acc1)
>>> acc5[0] = 'zgh666'
>>> acc5[1][1] = 666
>>> acc1
['Charlie', ['credit', 100.0]]
>>> acc5
['zgh666', ['credit', 666]]
>>> id(acc1) == id(acc5)
False
>>> id(acc1[1]) == id(acc5[1])
False
七:可迭代对象:迭代器和生成器
相对于序列,可迭代对象仅在迭代时产生数据,故可以节省内存空间
- Python语言提供了若干内置可迭代对象,例如:range、map、enumerate、filter、zip
- 在标准库itertools模块中包含各种迭代器,这些迭代器非常高效,且内存消耗小
- 在Python中,实现了
__iter__()的对象是可迭代对象 - 在collections.abc模块中定义了抽象基类Iterable,使用内置的isinstance()可以判断一个对象是否为可迭代对象
>>> import collections.abc
>>> isinstance((1, 2, 3), collections.abc.Iterable)
True
>>> isinstance('Python33', collections.abc.Iterable)
True
>>> isinstance(123, collections.abc.Iterable)
False
- 实现了
__next__()的对象是迭代器 - 使用迭代器可以实现对象的迭代循环,迭代器让程序更加通用、优雅、高效,更加Python化。对于大量项目的迭代,使用列表会占用更多的内存,而使用迭代器可以避免之
>>> [i**2 for i in range(10)]
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
>>> import collections.abc
>>> i1 = (i**2 for i in range(10))
>>> isinstance(i1, collections.abc.Iterator)
True
- 迭代器对象必须实现两个方法,即
__iter__()、__next__(),二者合称为迭代器协议 __iter__()用于返回对象本身,以方便for语句进行迭代__next__()用于返回下一元素- 内置函数
iter(iterable)可以返回可迭代对象iterable的迭代器 - 内置函数
next()调用迭代器__next__()方法依次返回下一个项目值,如果没有新项目,则将导致StopIteration
>>> t = ('zgh', '666')
>>> i = iter(t)
>>> next(i)
'zgh'
>>> next(i)
'666'
>>> next(i)
Traceback (most recent call last):
File "<pyshell#72>", line 1, in <module>
next(i)
StopIteration
- 例9.29(使用while循环迭代可迭代对象)
>>> t = (0, 1, 2, 3, 4, 5, 6, 7, 8, 9)
>>> fetch = iter(t)
>>> while True:
try: i = next(fetch)
except StopIteration: break
print(i, end = ' ')
0 1 2 3 4 5 6 7 8 9
声明一个类,定义
__iter__()、__next__()方法。创建该类的对象既是可迭代对象,也是迭代器
- 例9.30(定义Fib,实现Fibonacci数列)
>>> class Fib:
def __init__(self):
self.a, self.b = 0, 1
def __next__(self):
self.a, self.b = self.b, self.a+self.b
return self.a
def __iter__(self):
return self
>>> fibs = Fib()
>>> for i in fibs:
if i < 1000: print(i, end =', ')
else: break
1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987,
- 在函数定义中,如果使用yield语句代替return返回一个值,则定义了一个生成器函数(generator)
- 生成器函数是一个迭代器,是可迭代对象,支持迭代
>>> def triples(n):
for i in range(n):
yield i*3
>>> f = triples(10)
>>> f
<generator object triples at 0x0000022BF0563DC8>
>>> i = iter(f)
>>> next(i)
0
>>> next(i)
3
>>> for t in f: print(t, end = ', ')
6, 9, 12, 15, 18, 21, 24, 27,
- 例9.31(利用生成器函数创建Fibonacci数列)
>>> def fib():
a,b = 0,1
while True:
a,b = b,a+b
yield a
>>> if __name__ == '__main__':
fibs = fib()
for f in fibs:
if f < 1000: print(f, end = ' ')
else: break
1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987
- 例9.32(利用生成器函数创建返回m到n之间素数的生成器)
>>> import math
>>> def is_prime(n):
if n < 2: return False
if n == 2: return True
if n % 2 == 0: return False
sqrt_n = int(math.floor(math.sqrt(n)))
for i in range(3, sqrt_n+1, 2):
if n % i == 0: return False
return True
>>> def primes(m, n):
for i in range(m, n+1):
if is_prime(i):
yield i
>>> if __name__ == '__main__':
primes1 = primes(50_0000_0000, 50_0000_0090)
for p in primes1:
print(p, end = ' ')
5000000029 5000000039 5000000059 5000000063
只有长度有限的序列或者实现了
__reversed__()方法的可迭代对象才可以使用内置函数reversed()
>>> reversed([1, 2, 3, 4, 5])
<list_reverseiterator object at 0x0000022BF04FE608>
>>> for i in reversed([1, 2, 3, 4, 5]): print(i, end = ' ')
5 4 3 2 1
- 只有长度有限的序列或者实现了
__reversed__()方法的可迭代对象才可以使用内置函数reversed()
>>> class Countdown:
def __init__(self, start):
self.start = start
def __iter__(self):
n = self.start
while n > 0:
yield n
n -= 1
def __reversed__(self):
n = 1
while n <= self.start:
yield n
n += 1
>>> if __name__ == '__main__':
for i in Countdown(10): print(i, end = ' ')
for i in reversed(Countdown(10)): print(i, end = ' ')
10 9 8 7 6 5 4 3 2 1 1 2 3 4 5 6 7 8 9 10
- 生成器表达式
生成器表达式的语法和列表解析基本一样,只不过生成器表达式使用()代替[]
>>> (i **2 for i in range(10))
<generator object <genexpr> at 0x0000022BF0563F48>
>>> for j in (i **2 for i in range(10)):
print(j, end = ' ')
0 1 4 9 16 25 36 49 64 81
>>> for j in (i **2 for i in range(10) if i %3 == 0):
print(j, end = ' ')
0 9 36 81
- map迭代器和itertools.starmap迭代器
- 我们已经学过了
map(function, iterable, ...)函数 - 如果函数的参数为元组,则需要使用
itertools.starmap()迭代器
>>> import itertools
>>> list(itertools.starmap(pow, [(2,5), (3,2), (10,3)]))
[32, 9, 1000]
- filter迭代器和itertools.filterfalse迭代器
- 我们已经学过了
filter(function, iterable)函数,若结果为True,则返回该元素。如果function为None,则返回元素为True的元素 itertools.filterfalse(predicate, iterable)则反之
>>> filter
<class 'filter'>
>>> list(filter(lambda x : x > 0, (-1, 2, -3, 0, 5)))
[2, 5]
>>> list(filter(None, (1, 2, 3, 0, 5)))
[1, 2, 3, 5]
>>>
>>> import itertools
>>> list(itertools.filterfalse(lambda x : x%2, range(10)))
[0, 2, 4, 6, 8]
- zip迭代器和itertools.zip_longest迭代器
zip(*iterables)用于拼接多个可迭代对象的元素,返回新的可迭代对象。如果各序列的长度不一致,则截取至最小序列长度- 如果需要截取最长的长度,可以使用
itertools.zip_longest(*iterables, fillvalue = None)迭代器
>>> zip
<class 'zip'>
>>> zip((1,2,3), 'abc', range(3))
<zip object at 0x000001B3CDD758C8>
>>> list(zip((1,2,3), 'abc', range(3)))
[(1, 'a', 0), (2, 'b', 1), (3, 'c', 2)]
>>> list(zip('zgh', range(6,10)))
[('z', 6), ('g', 7), ('h', 8)]
>>>
>>>
>>> import itertools
>>> list(itertools.zip_longest('zgh', range(6,10), fillvalue = '-'))
[('z', 6), ('g', 7), ('h', 8), ('-', 9)]
>>> list(itertools.zip_longest('zgh', range(6,10)))
[('z', 6), ('g', 7), ('h', 8), (None, 9)]
- enumerate(iterable, start = 0)可迭代对象
- 用于枚举可迭代对象iterable中的元素,返回元素为元组(计数,元素)的可迭代对象
>>> enumerate
<class 'enumerate'>
>>> list(enumerate('zgh666', start = 666))
[(666, 'z'), (667, 'g'), (668, 'h'), (669, '6'), (670, '6'), (671, '6')]
- 无穷序列迭代器itertools.count、itertools.cycle和itertools.repeat
count(start = 0, step = 1)
从start开始,步长为step的无穷序列cycle(iterable)
可迭代对象iterable元素的无限重复repeat(object[, times])
重复对象object无数次(若指定times,则重复times次)
>>> from itertools import *
>>> list(zip(count(1), 'zgh666'))
[(1, 'z'), (2, 'g'), (3, 'h'), (4, '6'), (5, '6'), (6, '6')]
>>> list(zip(range(10), cycle('zgh')))
[(0, 'z'), (1, 'g'), (2, 'h'), (3, 'z'), (4, 'g'), (5, 'h'), (6, 'z'), (7, 'g'), (8, 'h'), (9, 'z')]
>>> list(repeat('zgh', 6))
['zgh', 'zgh', 'zgh', 'zgh', 'zgh', 'zgh']
- 累计迭代器itertools.accumulate
accumulate(iterable[, func])- 如果指定了带两个参数的func,则func代替默认的加法运算
>>> import itertools
>>> list(itertools.accumulate(range(1,11)))
[1, 3, 6, 10, 15, 21, 28, 36, 45, 55]
>>> import operator
>>> list(itertools.accumulate(range(1,11), operator.mul))
[1, 2, 6, 24, 120, 720, 5040, 40320, 362880, 3628800]
- 级联迭代器itertools.chain
chain(*iterables)- 由于连接所有的可迭代函数,及连接多个可迭代对象的元素,作为一个序列
- chain的类工厂函数
chain.from_iterable(iterable)也可以用于连接多个序列
>>> import itertools
>>> list(itertools.chain('zgh',(6,6,6),range(5)))
['z', 'g', 'h', 6, 6, 6, 0, 1, 2, 3, 4]
>>>
>>> list(itertools.chain.from_iterable(['zgh', '666']))
['z', 'g', 'h', '6', '6', '6']
- 选择压缩迭代器itertools.compress
compress(data, selectors)- 根据selectors的元素(True/False),返回True对应的data序列中的元素。当data序列或者selectors终止时停止判断
>>> import itertools
>>> list(itertools.compress('abcdef', [1,0,1,0,1,1]))
['a', 'c', 'e', 'f']
- 截取迭代器itertools.dropwhile和itertools.takewhile
dropwhile(predicate, iterable)
根据条件函数predicate处理可迭代对象的每个元素,丢弃iterable的元素,直到条件函数的结果为False(补充:这里不应该是True,书上有误)takewhile(predicate, iterable)
根据条件函数predicate处理可迭代对象的每个元素,返回iterable的元素,直到条件函数的结果为False
>>> import itertools
>>> list(itertools.dropwhile(lambda x : x < 5, [1, 4, 6, 4, 1]))
[6, 4, 1]
>>> list(itertools.takewhile(lambda x : x < 5, [1, 4, 6, 4, 1]))
[1, 4]
- 切片迭代器itertools.islice
islice(iterable, stop)islice(iterable, start, stop[, step])- 返回可迭代对象iterable的切片,从索引位置start(第一个元素为0)开始到stop(不包括)结束,步长为step(默认为1)。如果stop为None,则操作直到结束
>>> import itertools
>>> list(itertools.islice('ABCDEF', 2))
['A', 'B']
>>> list(itertools.islice('ABCDEF', 2, 4))
['C', 'D']
>>> list(itertools.islice('ABCDEF', 2, None))
['C', 'D', 'E', 'F']
>>> list(itertools.islice('ABCDEF', 0, None, 2))
['A', 'C', 'E']
- 分组迭代器itertools.groupby
groupby(iterable, key = None)- iterable为待分组的可迭代对象
- 可选的key为用于计算键值的函数,默认为None,即键值为元素本身值
- 返回的结果为迭代器,其元素为(key, group),其中key为分组的键值,group为iterable中具有相同key值的元素的集合的子迭代器
- 一般与排序联合使用
>>> import itertools
>>> data = [1, -2, 0, 0, -1, 2, 1, -1, 2, 0, 0]
>>> data1 = sorted(data, key = abs)
>>> for k, g in itertools.groupby(data, key = abs):
print(k, list(g))
1 [1]
2 [-2]
0 [0, 0]
1 [-1]
2 [2]
1 [1, -1]
2 [2]
0 [0, 0]
>>> for k, g in itertools.groupby(data1, key = abs):
print(k, list(g))
0 [0, 0, 0, 0]
1 [1, -1, 1, -1]
2 [-2, 2, 2]
- 返回多个迭代器itertools.tee
tee(iterable, n = 2)- 其返回可迭代对象iterable的nge(默认为2)迭代器
>>> import itertools
>>> for i in itertools.tee(range(10), 3): print(list(i))
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
- 组合迭代器itertools.combinations和itertools.combinations_with_replacement
combinations(iterable, r)
元素不重复combinations_with_replacement(iterable, r)
元素可重复- 其返回可迭代对象iterable的元素的组合,组合的长度为r
- 可以把它理解为数学中的组合
>>> import itertools
>>> list(itertools.combinations([1, 2, 3], 2))
[(1, 2), (1, 3), (2, 3)]
>>> list(itertools.combinations([1, 2, 3, 4], 2))
[(1, 2), (1, 3), (1, 4), (2, 3), (2, 4), (3, 4)]
>>> list(itertools.combinations([1, 2, 3, 4], 3))
[(1, 2, 3), (1, 2, 4), (1, 3, 4), (2, 3, 4)]
>>>
>>>
list(itertools.combinations_with_replacement([1, 2, 3], 2))
[(1, 1), (1, 2), (1, 3), (2, 2), (2, 3), (3, 3)]
- 排列迭代器itertools.permutations
permutations(iterable, r = None)- 排列长度为r(默认为序列长度)
>>> import itertools
>>> list(itertools.permutations([1, 2, 3], 2))
[(1, 2), (1, 3), (2, 1), (2, 3), (3, 1), (3, 2)]
>>> list(itertools.permutations([1, 2, 3]))
[(1, 2, 3), (1, 3, 2), (2, 1, 3), (2, 3, 1), (3, 1, 2), (3, 2, 1)]
- 笛卡尔积迭代器itertools.product
product(*iterables, repeat = 1)- 其返回可迭代对象的元素的笛卡尔积,repeat为可迭代对象的重复次数(默认为1)
>>> import itertools
>>> list(itertools.product([1, 2], 'abc'))
[(1, 'a'), (1, 'b'), (1, 'c'), (2, 'a'), (2, 'b'), (2, 'c')]
>>> list(itertools.product([1, 2], repeat = 3))
[(1, 1, 1), (1, 1, 2), (1, 2, 1), (1, 2, 2), (2, 1, 1), (2, 1, 2), (2, 2, 1), (2, 2, 2)]
八:自定义类应用举例
用户可以通过自定义类创建和使用新的数据结构
例9.52 实现RGB颜色模型的Color类
class Color:
def __init__(self, r = 0, g = 0, b = 0):
self.__r = r
self.__g = g
self.__b = b
@property
def r(self):
return self.__r
@property
def g(self):
return self.__g
@property
def b(self):
return self.__b
def luminance(self):
#计算并返回颜色的亮度
return self.__r * .299 + .587 * self.__g + .114 * self.__b
def toGray(self):
#转换为灰度颜色
y = int(round(self.luminance()))
return Color(y, y, y)
def isCompatible(self, c):
#比较前景色和背景色是否匹配
return abs(self.luminance() - c.luminance()) >= 128.0
def __str__(self):
#重载方法,输出:(r, g, b)
return '({}, {}, {})'.format(self.__r, self.__g, self.__b)
#常用颜色
WHITE = Color(255, 255, 255)
BLACK = Color(0, 0, 0)
RED = Color(255, 0, 0)
GREEN = Color(0, 255, 0)
BLUE = Color(0, 0, 255)
CYAN = Color(0, 255, 255)
MAGENTA = Color(255, 0, 255)
YELLOW = Color(255, 255, 0)
#测试代码
if __name__ == '__main__':
c = Color(255, 200, 0)
print('颜色字符串:{0}'.format(c))
print('颜色分量:r = {0}, g = {1}, b = {1}'.format(c.r, c.g, c.b))
print('颜色亮度:{0}'.format(c.luminance()))
print('转换为灰度颜色:{0}'.format(c.toGray()))
print('{0} 和 {1} 是否匹配:{2}'.format(c, RED, c.isCompatible(RED)))
例9.53 实现直方图类Histogram
import random
import math
class Stat:
def __init__(self, n):
self.__data = []
for i in range(n):
self.__data.append(0)
def addDataPoint(self, i):
"""增加数据点"""
self.__data[i] += 1
def count(self):
"""计算数据点个数之和(统计数据点个数)"""
return sum(self.__data)
def mean(self):
"""平均值"""
return sum(self.__data)/len(self.__data)
def max(self):
return max(self.__data)
def min(self):
return min(self.__data)
def draw(self):
"""绘制简易直方图"""
for i in self.__data:
print(' # ' * i)
if __name__ == '__main__':
st = Stat(10)
for i in range(100):
score = random.randrange(0, 10)
st.addDataPoint(math.floor(score))
print('数据点个数:{}'.format(st.count()))
print('数据点个数的平均值:{}'.format(st.mean()))
print('数据点个数的最大值:{}'.format(st.max()))
print('数据点个数的最小值:{}'.format(st.min()))
st.draw()
输出:
数据点个数:100
数据点个数的平均值:10.0
数据点个数的最大值:14
数据点个数的最小值:7
# # # # # # # #
# # # # # # # # # #
# # # # # # # # #
# # # # # # # # # #
# # # # # # # # # #
# # # # # # # # # # #
# # # # # # # # #
# # # # # # # # # # # #
# # # # # # # # # # # # # #
# # # # # # #
填空题:2
2
>>> x = '123'
>>> print(isinstance(x, int))
False
思考题:3~11
3
在声明派生类时,必须在其构造函数中调用基类的构造函数
>>> class Parent:
def __init__(self, param):
self.v1 = param
>>> class Child(Parent):
def __init__(self, param):
Parent.__init__(self, param)
self.v2 = param
>>> obj = Child(100)
>>> print("%d %d" % (obj.v1, obj.v2))
100 100
4
注意区分实例对象属性和局部变量
>>> class Account:
def __init__(self, id):
self.id = id
id = 888
>>> acc = Account(100)
>>> print(acc.id)
100
5
>>> #5
>>> class Account:
def __init__(self, id, balance):
self.id = id
self.balance = balance
def deposit(self, amount):
self.balance += amount
def withdraw(self, amount):
self.balance -= amount
>>> acc1 = Account('1234', 100)
>>> acc1.deposit(500)
>>> acc1.withdraw(200)
>>> print(acc1.balance)
400
6
getattr(object, name[, default])
获取object对象的属性的值,如果存在则返回属性值setattr(object, name, value)
给object对象的name属性赋值value,如果对象原本存在给定的属性name,则setattr会更改属性的值为给定的value;如果对象原本不存在属性name,setattr会在对象中创建属性,并赋值为给定的value;
>>> class A:
def __init__(self, a, b, c):
self.x = a+b+c
>>> a = A(6, 2, 3)
>>> b = getattr(a, 'x')
>>> setattr(a, 'x', b+1)
>>> print(a.x)
12
7
浅拷贝,复制对象时对象中包含的子对象并不复制,而是引用同一个子对象
>>> import copy
>>> d1 = {'a' : [1, 2], 'b' : 2}
>>> d2 = copy.copy(d1)
>>> d1['a'][0] = 6
>>> sum = d1['a'][0] + d2['a'][0]
>>> print(sum)
12
8
深拷贝,可以递归复制对象中包含的子对象
>>> from copy import *
>>> d1 = {'a' : [1, 2], 'b' : 2}
>>> d2 = deepcopy(d1)
>>> d1['a'][0] = 6
>>> sum = d1['a'][0] + d2['a'][0]
>>> print(sum)
7
9
浅拷贝,复制对象时对象中包含的子对象并不复制,而是引用同一个子对象
>>> from copy import *
>>> list1 = [1, 2, 3]
>>> list2 = [3, 4, 5]
>>> dict1 = {"1" : list1, '2' : list2}
>>> dict2 = dict1.copy()
>>> dict1['1'][0] = 15
>>> print(dict1['1'][0] + dict2['1'][0])
30
10
深拷贝,可以递归复制对象中包含的子对象
>>> from copy import *
>>> list1 = [1, 2, 3]
>>> list2 = [3, 4, 5]
>>> dict1 = {"1" : list1, '2' : list2}
>>> dict2 = deepcopy(dict1)
>>> dict1['1'][0] = 15
>>> print(dict1['1'][0] + dict2['1'][0])
16
11
对象通过特殊属性__dict__存储属性,包括自定义属性
>>> class Person:
def __init__(self, id):
self.id = id
>>> mary = Person(123)
>>> mary.__dict__['age'] = 18
>>> mary.__dict__['gender'] = 'female'
>>> print(mary.age + len(mary.__dict__))
21
>>> mary.__dict__
{'id': 123, 'age': 18, 'gender': 'female'}
上机实践:2~3
2. 编写程序,创建类MyMath,计算圆的周长和面积以及球的表面积和体积,并编写测试代码,结果均保留两位小数
import math
class MyMath:
def __init__(self, r):
self.r = r
def perimeter_round(self):
return 2 * math.pi * self.r
def area_round(self):
return math.pi * self.r * self.r
def area_ball(self):
return 4 * math.pi * self.r ** 2
def volume_ball(self):
return 4 / 3 * math.pi *self.r ** 3
if __name__ == '__main__':
n = float(input("请输入半径:"))
m = MyMath(n)
print("圆的周长 = {0:.2f}\n圆的面积 = {1:.2f}\n球的表面积 = {2:.2f}\n球的体积 = {3:.2f}".\
format(m.perimeter_round(), m.area_round(), m.area_ball(), m.volume_ball()))
输出:
请输入半径:5
圆的周长 = 31.42
圆的面积 = 78.54
球的表面积 = 62.83
球的体积 = 523.60
3. 编写程序,创建类Temperature,其包含成员变量degree(表示温度)以及实例方法ToFahrenheit(将摄氏温度转换为华氏温度)和ToCelsius(将华氏温度转换为摄氏温度),并编写测试代码
class Temperature:
def __init__(self, degree):
self.degree = degree
def toFahrenheit(self):
return self.degree*9/5 + 32
def toCelsius(self):
return (self.degree -32) * 5/9
if __name__ == '__main__':
n1 = float(input("请输入摄氏温度:"))
t1 = Temperature(n1)
print("摄氏温度 = {0:.2f}, 华氏温度 = {1:.2f}".format(n1, t1.toFahrenheit()))
n2 = float(input("请输入华氏温度:"))
t2 = Temperature(n2)
print("摄氏温度 = {0:.2f}, 华氏温度 = {1:.2f}".format(t2.toCelsius(), n2))
输出:
请输入摄氏温度:30
摄氏温度 = 30.00, 华氏温度 = 86.00
请输入华氏温度:70
摄氏温度 = 21.11, 华氏温度 = 70.00
第十章 模块和客户端
上机实践:2~4
2. 编写程序,创建一个实现+、-、*、/和**(幂)运算的模块MyMath.py,并编写测试代码
先创建一个模块代码MyMath.py
def add(x,y):
return x+y
def sub(x,y):
return x-y
def mul(x,y):
return x*y
def div(x,y):
if y == 0: return "除数不能为零!"
return x/y
def power(x,y):
return x**y
测试代码:
>>> import MyMath
>>> dir(MyMath)
['__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', 'add', 'div', 'mul', 'power', 'sub']
>>> MyMath.add(10,12)
22
>>> MyMath.div(5,4)
1.25
>>> MyMath.mul(9,9)
81
>>> MyMath.sub(6,1)
5
>>> MyMath.power(2,10)
1024
3. 编写程序,创建一个求圆的面积和球体体积的模块AreaVolume.py,并编写只有独立运行时才执行的测试代码,要求输入半径,输出结果保留两位小数
先创建一个模块代码AreaVolume.py
import math
def area(r):
return math.pi * r * r
def volume(r):
return 4/3 * math.pi * r**3
测试代码:
import AreaVolume
if __name__ == '__main__':
r = float(input("请输入半径:"))
print("圆的面积:{0:.2f},球的体积:{1:.2f}".\
format(AreaVolume.area(r), AreaVolume.volume(r)))
输出:
请输入半径:5.1
圆的面积:81.71,球的体积:555.65
4. 编写程序,创建输出命令行参数个数以及各参数内容的模块SysArgvs.py,并编写测试代码
先创建一个模块代码SysArgvs.py
import sys
print("参数个数:", len(sys.argv))
for i,x in enumerate(sys.argv):
print("argv[{0}] = {1}".format(i, x))
测试(cmd):
D:\zgh\desktop>python SysArgvs.py
参数个数: 1
argv[0] = SysArgvs.py
D:\zgh\desktop>python SysArgvs.py a b c
参数个数: 4
argv[0] = SysArgvs.py
argv[1] = a
argv[2] = b
argv[3] = c
第十一章 算法与数据结构基础
一些知识点总结和几个例题
一:二分查找法,冒泡、选择、插入、归并、快速排序算法
我把这几个例题中的查找算法和排序算法,把自己对它们的理解总结了一下:
Python 关于下标的运用技巧(二分查找法,冒泡、选择、插入、归并、快速排序算法)
二:数组
import array
array.array(typecode [, initializer])
- typecode:array对象中数据元素的类型
创建array对象时必须指定其元素类型typecode,且其元素只能为该类型,否则将导致TypeError - initializer:为初始化数据序列或可迭代对象
例11.15
>>> import array
>>> a = array.array('b', (1, 2, 3, 4, 5))
>>> a[1] = 66
>>> a[1:]
array('b', [66, 3, 4, 5])
>>> a[0] = 'zgh'
Traceback (most recent call last):
File "<pyshell#29>", line 1, in <module>
a[0] = 'zgh'
TypeError: an integer is required (got type str)
下表来自https://docs.python.org/3.5/library/array.html#module-array
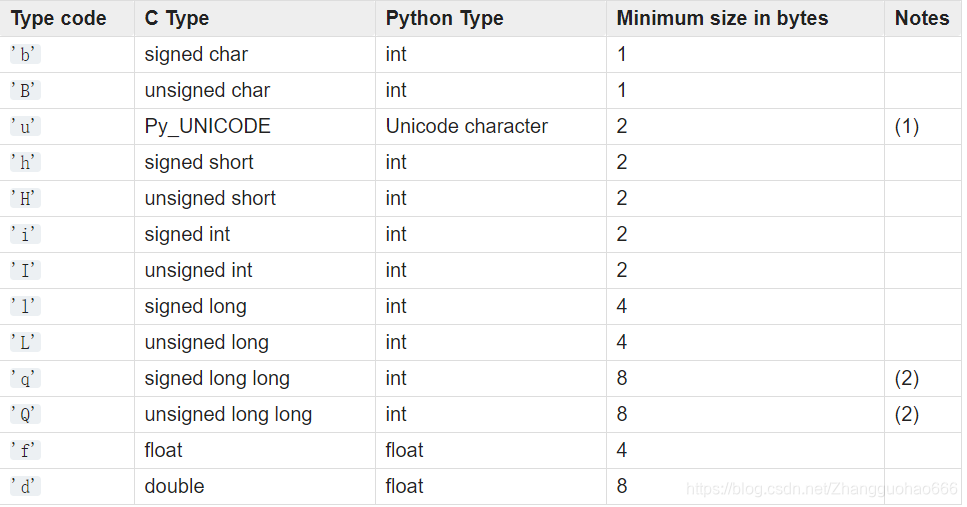
三:栈和队列(collections.deque)
- collections模块中的deque对象:双端队列
支持从任意一端增加和删除元素。 - deque是线程安全的,内存高效的队列,它被设计为从两端追加和弹出都非常快
import collections
collections.deque([iterable [, maxlen]])
- iterable:初始元素
- maxlen:指定队列长度(默认无限制)
| deque对象dq支持的方法: | |
|---|---|
dq.append(x) |
在右端添加元素x |
dq.appendleft(x) |
在左端添加元素x |
dq.pop() |
从右端弹出元素。若队列中无元素,则导致IndexError |
dq.popleft() |
从左端弹出元素。若队列中无元素,则导致IndexError |
dq.extend(iterable) |
在右端添加序列iterable中的元素 |
dq.extendleft(iterable) |
在左端添加序列iterable中的元素 |
dq.remove(value) |
移除第一个找到的x。若未找到,则导致IndexError |
dq.count(x) |
返回元素x在队列中出现的个数 |
dq.clear() |
清空队列,删除所有元素 |
dq.reverse() |
反转 |
dq.rotate(n) |
如果n>0,则所有元素向右移动n个位置(循环),否则向左 |
例11.17(读取文件,返回文件最后的n行内容)
import collections
def tail(filename, n = 10):
'Return the last n lines of a file'
with open(filename) as f:
return collections.deque(f, n)
if __name__ == '__main__':
path = r'test.py'
dq = tail(path, n = 2)
print(dq.popleft())
print(dq.popleft())
输出:
print(dq.popleft())
print(dq.popleft())
若将代码中的这一句改为dq = tail(path, n = 5)
再看输出:
if __name__ == '__main__':
path = r'test.py'
例11.18(deque作为栈)
- 入栈:deque的append()方法
- 出栈:deque的pop()方法
>>> from collections import deque
>>> dq = deque()
>>> dq.append(1)
>>> dq.append(2)
>>> dq.append(3)
>>> dq.pop()
3
>>> dq.pop()
2
>>> dq.pop()
1
例11.16(用列表list实现栈)
list.append()入栈list.pop()出栈
class Stack:
def __init__(self, size = 16):
self.stack = []
def push(self, obj):
self.stack.append(obj)
def pop(self):
try:
return self.stack.pop()
except IndexError as e:
print("stack is empty")
def __str__(self):
return str(self.stack)
def main():
stack = Stack()
#1,2先后入栈
stack.push(1)
stack.push(2)
print(stack)
#出栈
stack.pop()
print(stack)
stack.pop()
print(stack)
stack.pop()
print(stack)
if __name__ == '__main__':main()
输出:
[1, 2]
[1]
[]
stack is empty
[]
例11.19(deque作为队列)
- 进队:deque的append()方法
- 出队:deque的popleft()方法
>>> from collections import deque
>>> dq = deque()
>>> dq.append(1)
>>> dq.append(2)
>>> dq.append(3)
>>> dq.popleft()
1
>>> dq.popleft()
2
>>> dq.popleft()
3
四:集合
- 可变集合对象 set
set()
set(iterable) - 不可变集合对象 frozenset
frozenset()
frozenset(iterable)
- 集合中的元素不可重复,且无序,其存储依据对象的hash码
hash码是依据对象的值计算出来的一个唯一的值
一个对象的hash值可以使用内置函数hash()获得- 所有的内置不可变对象,都是可hash对象
可hash对象,即实现了__hash__()的对象
bool、int、float、complex、str、tuple、frozenset- 所有内置可变对象,都是非hash对象
list、dict、set
因为可变对象的值可以变化,故无法计算唯一的hash值
在集合中可以包含内置不可变对象,不能包含内置可变对象
例11.20(创建集合对象示例)
集合:无序、不可重复
>>> {1, 2, 1}
{1, 2}
在集合中,重复元素,保留前面的
>>> {'a', 1, True, False, 0}
{False, 1, 'a'}
在集合中可以包含内置不可变对象,不能包含内置可变对象(list、dict、set)
>>> {'zgh', [6,6,6]}
Traceback (most recent call last):
File "<pyshell#3>", line 1, in <module>
{'zgh', [6,6,6]}
TypeError: unhashable type: 'list'
>>> {'zgh', {6, 6, 6}}
Traceback (most recent call last):
File "<pyshell#4>", line 1, in <module>
{'zgh', {6, 6, 6}}
TypeError: unhashable type: 'set'
>>> {'zgh', {'sex':'male'}}
Traceback (most recent call last):
File "<pyshell#5>", line 1, in <module>
{'zgh', {'sex':'male'}}
TypeError: unhashable type: 'dict'
例11.21(集合解析表达式)
>>> {i for i in range(5)}
{0, 1, 2, 3, 4}
>>> {2**i for i in range(5)}
{1, 2, 4, 8, 16}
>>> {x**2 for x in [1, 1, 2]}
{1, 4}
- 判断元素x是否在集合s是否存在:
x in s如果为True,则表示存在x not in s如果为True,则表示不存在
- 集合的运算:并集、交集、差集、对称差集
| 运算符 | 说明 |
|---|---|
s1 | s2 | ... |
返回 s1、s2…的并集 |
s1 & s2 | ... |
返回 s1、s2…的交集 |
s1 - s2 - ... |
返回 s1、s2…的差集 |
s1 ^ s2 |
返回 s1、s2 的对称差集 |
- 集合的对象方法:
| 方法 | 说明 |
|---|---|
s1.union(s2, ...) |
返回集合s1、s2…的并集 |
s1.update(s2, ...) |
返回集合s1、s2…的并集,s1 |= (s2 | ...) (可变集合的方法) |
s1.intersection(s2, ...) |
返回集合s1、s2…的交集 |
s1.intersection_update(s2, ...) |
返回集合s1、s2…的交集,s1 &= (s2 & ...) (可变集合的方法) |
s1.difference(s2, ...) |
返回集合s1、s2…的差集 |
s1.difference_update(s2, ...) |
返回集合s1、s2…的差集,s1 -= (s2 - ...) (可变集合的方法) |
s1.symmetric_difference(s2) |
返回集合s1、s2的对称差集 |
s1.symmetric_difference_update(s2) |
返回集合s1、s2的对称差集,s1 ^= (s2) (可变集合的方法) |
>>> s1 = {1, 2, 3}
>>> s2 = {2, 3, 4}
>>> '''并集'''
>>> s1 | s2
{1, 2, 3, 4}
>>> s1.union(s2)
{1, 2, 3, 4}
>>> '''交集'''
>>> s1 & s2
{2, 3}
>>> s1.intersection(s2)
{2, 3}
>>> '''差集'''
>>> s1 - s2
{1}
>>> s2 - s1
{4}
>>> s1.difference(s2)
{1}
>>> '''对称差集'''
>>> s1 ^ s2
{1, 4}
>>> s1.symmetric_difference(s2)
{1, 4}
- 集合的比较运算:相等、子集、超集
| 运算符 | 说明 |
|---|---|
s1 == s2 |
s1和s2的元素相同 |
s1 != s2 |
s1和s2的元素不完全相同 |
s1 < s2 |
s1是s2的纯子集 |
s1 <= s2 |
s1是s2的子集 |
s1 >= s2 |
s1是s2的超集 |
s1 > s2 |
s1是s2的纯超集 |
| 方法 | 说明 |
|---|---|
s1.isdisjoint(s2) |
如果集合s1和s2没有共同元素,返回True |
s1.issubset(s2) |
如果集合s1是s2的子集,返回True |
s1.issuperset(s2) |
如果集合s1是s2的超集,返回True |
-
集合的长度、最大值、最小值、元素和
len()
max()
min()
sum()如果元素有非数值类型(数值类型:int、float、bool、complex),则求和将导致TypeError -
可变集合 set 的常用方法:
| set的方法 | 说明 |
|---|---|
s.add(x) |
把对象x添加到集合s |
s.remove(x) |
从集合s中移除对象x,若不存在,则导致KeyError |
s.discard(x) |
从集合s中移除对象x(如果存在) |
s.pop() |
从集合s中随机弹出一个元素,如果s为空,则导致KeyError |
s.clear() |
清空集合s |
五:字典
- 字典(dict)是一组键/值对的数据类型
字典的键必须是可hash对象 - 每个键对应于一个值
- 在字典中,键不能重复,根据键可以查询到值
字典的定义:
dict()
创建一个空字典
>>> {}
{}
>>> dict()
{}
dict(**kwargs)
使用关键字参数创建一个新的字典,此方法最紧凑
>>> dict(baidu = 'baidu.com', google = 'google.com')
{'baidu': 'baidu.com', 'google': 'google.com'}
dict(mapping)
从一个字典对象创建一个新的字典
>>> {'a':'apple', 'b':'boy'}
{'a': 'apple', 'b': 'boy'}
>>> dict({'a':'apple', 'b':'boy'})
{'a': 'apple', 'b': 'boy'}
dict(iterable)
使用序列创建一个新的字典
>>> dict([('id','666'),('name','zgh')])
{'id': '666', 'name': 'zgh'}
>>> dict((('id','666'),('name','zgh')))
{'id': '666', 'name': 'zgh'}
字典的访问操作:
d[key]
返回键为key的value,如果key不存在,则导致KeyError
>>> d = {1:'zgh', 2:'666'}
>>> d
{1: 'zgh', 2: '666'}
>>> d[1]
'zgh'
>>> d[2]
'666'
>>> d[3]
Traceback (most recent call last):
File "<pyshell#43>", line 1, in <module>
d[3]
KeyError: 3
d[key] = value
设置d[key]的值为value,如果key不存在,则添加键/值对
>>> d[3] = 'yes'
>>> d
{1: 'zgh', 2: '666', 3: 'yes'}
del d[key]
删除字典元素,如果key不存在,则导致KeyError
>>> del d[2]
>>> d
{1: 'zgh', 3: 'yes'}
字典的视图对象:
d.keys()
返回字典d的键key的列表
>>> d = dict(name = 'zgh', sex = 'male', age = '18')
>>> d
{'name': 'zgh', 'sex': 'male', 'age': '18'}
>>> d.keys()
dict_keys(['name', 'sex', 'age'])
d.values()
返回字典d的值value的列表
>>> d.values()
dict_values(['zgh', 'male', '18'])
d.items()
返回字典d的(key, value)对的列表
>>> d.items()
dict_items([('name', 'zgh'), ('sex', 'male'), ('age', '18')])
字典解析表达式:
>>> {key:value for key in "ABC" for value in range(3)}
{'A': 2, 'B': 2, 'C': 2}
>>> d = {'name':'zgh', 'sex':'male', 'age':'18'}
>>> {key:value for key,value in d.items()}
{'name': 'zgh', 'sex': 'male', 'age': '18'}
>>> {x:x*x for x in range(10) if x%2 == 0}
{0: 0, 2: 4, 4: 16, 6: 36, 8: 64}
判断字典键是否存在:
key in d
如果为True,表示存在
>>> d = dict([('name', 'zgh'), ('sex', 'male'), ('age', '18')])
>>> d
{'name': 'zgh', 'sex': 'male', 'age': '18'}
>>> 'name' in d
True
key not in d
如果为True,表示不存在
>>> 'names' in d
False
字典对象的长度和比较:
len()
获取字典的长度
虽然,字典对象也支持内置函数max()、min()、sum(),但是它们计算的是字典key,没有意义
>>> d1 = {1:'food'}
>>> d2 = {1:'food', 2:'drink'}
>>> len(d1)
1
>>> len(d2)
2
==,!=
字典支持的比较运算中,只有==,!=有意义
>>> d1 == d2
False
>>> d1 != d2
True
字典对象的方法:
| 字典对象的方法 | 说明 |
|---|---|
d.clear() |
删除所有元素 |
d.copy() |
浅复制字典 |
d.get(k) |
返回键k对应的值,如果key不存在,返回None |
d.get(k,v) |
返回键k对应的值,如果key不存在,返回v |
d.pop(k) |
如果键k存在,返回其值,并删除该项目;否则将导致KeyError |
d.pop(k,v) |
如果键k存在,返回其值,并删除该项目;否则返回v |
d.setdefault(k,v) |
如果键k存在,返回其值;否则添加项目k=v,v默认为None |
d.update([other]) |
使用字典或键值对,更新或添加项目到字典d |
六:collections模块的数据结构
与字典相关
collections.defaultdict(function_factory)
用于构建类似dict的对象defaultdict
与dict的区别是,在创建defaultdict对象时可以使用构造函数参数function_factory指定其键值对中值的类型
import collections
collections.defaultdict([function_factory[, ...]])
- 其中,可选参数
function_factory为字典键值对中值的类型;其他可选参数同dict构造函数 defaultdict实现了__missing__(key),即键不存在时返回值的类型(function_factory)对应的默认值,例如数值为0、字符串为'',list为[]
键不存在时返回:值的类型(function_factory)对应的默认值,例如数值为0
>>> import collections
>>> s = [('r', 1), ('g', 2), ('b', 3)]
>>>> dd = collections.defaultdict(int, s)
>>> dd['r']
1
>>> dd['g']
2
>>> dd['b']
3
>>> dd['z']
0
我们知道,在字典中键是不能重复的,而且键对应一个值
当键有重复的时候,后面的覆盖前面的
>>> s1 = [('r', 1), ('g', 2), ('b', 3), ('r', 4), ('b', 5)]
>>> dict(s1)
{'r': 4, 'g': 2, 'b': 5}
那么,
怎么使字典中的键对应多个值呢?
>>> import collections
>>> s1 = [('r', 1), ('g', 2), ('b', 3), ('r', 4), ('b', 5)]
>>> dd1 = collections.defaultdict(list)
>>> for k,v in s1:
dd1[k].append(v)
>>> list(dd1.items())
[('r', [1, 4]), ('g', [2]), ('b', [3, 5])]
>>> dd1.items()
dict_items([('r', [1, 4]), ('g', [2]), ('b', [3, 5])])
collections.OrderedDict([items])
是dict的子类,能够记录字典元素插入的顺序
OrderedDict对象的元素保持插入的顺序,在更新键的值时不改变顺序;
若删除项,然后插入与删除项相同的键值对,则置于末尾
除了继承dict的方法外,OrderedDict对象包括以下两个方法:
| OrderedDict对象的方法 | 说明 |
|---|---|
popitem(last=True) |
弹出最后一个元素;如果last=False,则弹出第一个元素 |
move_to_end(key, last=True) |
移动键key到最后;如果last=False,则移动到最前面 |
>>> import collections
>>> od = collections.OrderedDict(sorted(d.items()))
>>> od
OrderedDict([('age', '18'), ('name', 'guohao'), ('sex', 'female')])
>>> od.popitem()
('sex', 'female')
>>> od
OrderedDict([('age', '18'), ('name', 'guohao')])
>>> od['sex'] = 'male'
>>> od
OrderedDict([('age', '18'), ('name', 'guohao'), ('sex', 'male')])
>>> od.move_to_end('name')
>>> od
OrderedDict([('age', '18'), ('sex', 'male'), ('name', 'guohao')])
>>> od.move_to_end('name', False)
>>> od
OrderedDict([('name', 'guohao'), ('age', '18'), ('sex', 'male')])
与map相关
collections.ChainMap( * maps)
用于连接多个map
ChainMap对象内部包含多个map的列表(第一个map为子map,其余map为父map),maps属性返回这个列表。
>>> import collections
>>> m1 = {'a':1, 'b':2}
>>> m2 = {'a':2, 'x':3, 'y':4}
>>> m = collections.ChainMap(m1, m2)
ChainMap对象m除了支持字典映射的属性和方法以外,还包含下列属性和方法:
m.maps
属性,返回m对象内部包含的map的列表
>>> m.maps
[{'a': 1, 'b': 2}, {'a': 2, 'x': 3, 'y': 4}]
m.parents
属性,返回包含其父map的新的ChainMap对象,即ChainMap( * d.maps[1:])
>>> m.parents
ChainMap({'a': 2, 'x': 3, 'y': 4})
m.new_child()
方法,返回新的ChainMap对象,即ChainMap({}, * d.maps)
>>> m.new_child()
ChainMap({}, {'a': 1, 'b': 2}, {'a': 2, 'x': 3, 'y': 4})
- 在查询时,首先查询第一个map,如果没有查到,则依次查询其他map
>>> m['a']
1
>>> m['x']
3
- ChainMap只允许更新第一个map
>>> m['a'] = 99
>>> m['x'] = 10
>>> m
ChainMap({'a': 99, 'b': 2, 'x': 10}, {'a': 2, 'x': 3, 'y': 4})
更新键'x'的值,因为夫map不能更新,故实际上是在子map中插入键值对
collections.Counter([iterable - or - mapping])
可选参数为序列或字典map
创建Counter对象:
c = Counter()
创建空的Counter对象c = Counter('banana')
基于序列创建Counter对象c = Counter({'red':4, 'blue':2})
基于字典映射c = Counter(cats = 4, dogs = 8)
基于命名参数
- Counter对象支持字典映射的属性和方法,但查询时如果键不存在将不会报错,而是返回值0
>>> import collections
>>> c = collections.Counter({'r':3, 'g':2, 'b':1, 'y':4, 'w':3})
>>> c['green']
0
c.elements()
返回元素列表,各元素重复的次数为其计数
>>> c.elements()
<itertools.chain object at 0x000001F92336F8C8>
>>> list(c.elements())
['r', 'r', 'r', 'g', 'g', 'b', 'y', 'y', 'y', 'y', 'w', 'w', 'w']
c.most_common([n])
返回计数值最大的n个元素的元组(元素,计数)列表
>>> c.most_common(2)
[('y', 4), ('r', 3)]
c.subtract([iterable-or-mapping])
元素的计数值减去序列或字典中对应元素的计数
>>> c.subtract('red')
>>> c
Counter({'y': 4, 'w': 3, 'r': 2, 'g': 2, 'b': 1, 'e': -1, 'd': -1})
与元组相关
namedtuple(typename, field_names, verbose = False, rename = False)
typename
返回tuple的子类的类名field_names
是命名元组元素的名称,必须为合法的标识符verbose
当verbose为True时,在创建命名元组后会打印类定义信息rename
当rename为True时,如果field_names包含保留关键字,则自动命名为_1、_2等
tuple是常用的数据类型,但只能通过索引访问其元素
使用namedtuple的构造函数可以定义一个tuple的子类命名元组,namedtuple对象既可以使用元素名称访问其元素,也可以使用索引访问
- 创建的命名元组的类可以通过
_fields返回其字段属性
>>> from collections import namedtuple
>>> p = namedtuple('Point', ['x', 'y'])
>>> print(p._fields)
('x', 'y')
>>> p.x = 11
>>> p.y = 22
>>> p.x + p.y
33
- namedtuple创建的类继承自tuple,包含额外的三个方法:
_make(iterable),从指定序列iterable构建命名元组对象
>>> t = [3, 4]
>>> p1 = p._make(t)
>>> p1
Point(x=3, y=4)
_asdict()
把命名元组对象转换为OrderDict对象
>>> p1._asdict()
OrderedDict([('x', 3), ('y', 4)])
_replace(kwargs())
创建新的命名元组对象,替换指定字段
>>> p1._replace(x=30)
Point(x=30, y=4)
>>> p1
Point(x=3, y=4)
UserDict、UserList和UserString对象
UserDict、UserList和UserString分别是dict、list、str的子类,一般用于创建其派生类
collections.UserDict([initialdata])collections.UserList([list])collections.UserString([sequence])
虽然可以直接基于dict、list、str创建派生类,但UserDict、UserList和UserString包括一个属性成员—data,用于存放内容,因此可以更方便实现
以UserString为例:
>>> from collections import *
>>> us = UserString('zgh')
>>> us.data
'zgh'
以UserList为例:
>>> ul = UserList([1,1,3])
>>> ul.data
[1, 1, 3]
>>> ul.data[0]
1
以UserDict为例:
>>> ud = UserDict({'name':'zgh', 'sex':'male', 'age':'18'})
>>> ud.data
{'name': 'zgh', 'sex': 'male', 'age': '18'}
>>> ud.data['name']
'zgh'
七:基于字典的通讯录
实现一个简单的基于字典数据结构的通讯管理系统,该系统采用JSON文件来保存数据
通讯录设计为字典:{name : tel}
有五个功能:
- 显示通讯录清单
若通讯录中无任何用户信息,则提示:通讯录为空 - 查询联系人资料
若并不存在,则提示:是否新建联系人 - 插入新的联系人
若联系人已存在,则提示:是否进行修改 - 删除已有联系人
若不存在此联系人,则提示:联系人不存在 - 退出
保存通讯录字典到addressbook.json中,退出循环
Python代码:
"""简易通讯录程序"""
import os, json
address_book = {}
if os.path.exists("addressbook.json"):
with open(r'addressbook.json', 'r', encoding='utf-8') as f:
address_book = json.load(f)
while True:
print("| --- 欢迎使用通讯录程序 --- |")
print("| --- 1:显示通讯录清单--- |")
print("| --- 2:查询联系人资料 --- |")
print("| --- 3:插入新的联系人 -- |")
print("| --- 4:删除已有联系人 --- |")
print("| --- 0:退出 --- |")
choice = input('请选择功能菜单:')
if choice == '1':
if(len(address_book) == 0):
print("通讯录为空")
else:
for k,v in address_book.items():
print("姓名 = {},联系电话 = {}".format(k, v))
print()
elif choice == '2':
name = input("请输入联系人姓名:")
if (name not in address_book):
yn = input("联系人不存在,是否增加用户资料(Y/N):")
if yn in ['Y', 'y']:
tel = input("请输入联系人电话:")
address_book[name] = tel
else:
print("联系人信息:{} {}".format(name, address_book[name]))
print()
elif choice == '3':
name = input("请输入联系人姓名:")
if (name in address_book):
print("已存在联系人:{} {}".format(name, address_book[name]))
yn = input("是否修改用户资料(Y/N):")
if yn in ['Y', 'y']:
tel = input("请输入联系人电话:")
address_book[name] = tel
else:
tel = input("请输入联系人电话:")
address_book[name] = tel
print()
elif choice == '4':
name = input('请输入联系人姓名:')
if (name not in address_book):
print("联系人不存在:{}".format(name))
else:
tel = address_book.pop(name)
print("删除联系人:{} {}".format(name, tel))
print()
elif choice == '0':
with open(r'addressbook.json', 'w', encoding='utf-8') as f:
json.dump(address_book, f)
break
运行Python模块之前的json文件:
{"zgh": "15272502101", "xy": "110", "lcw": "888", "hq": "120"}
运行过程:
| --- 欢迎使用通讯录程序 --- |
| --- 1:显示通讯录清单--- |
| --- 2:查询联系人资料 --- |
| --- 3:插入新的联系人 -- |
| --- 4:删除已有联系人 --- |
| --- 0:退出 --- |
请选择功能菜单:1
姓名 = zgh,联系电话 = 15272502101
姓名 = xy,联系电话 = 110
姓名 = lcw,联系电话 = 888
姓名 = hq,联系电话 = 120
| --- 欢迎使用通讯录程序 --- |
| --- 1:显示通讯录清单--- |
| --- 2:查询联系人资料 --- |
| --- 3:插入新的联系人 -- |
| --- 4:删除已有联系人 --- |
| --- 0:退出 --- |
请选择功能菜单:2
请输入联系人姓名:zgh
联系人信息:zgh 15272502101
| --- 欢迎使用通讯录程序 --- |
| --- 1:显示通讯录清单--- |
| --- 2:查询联系人资料 --- |
| --- 3:插入新的联系人 -- |
| --- 4:删除已有联系人 --- |
| --- 0:退出 --- |
请选择功能菜单:2
请输入联系人姓名:tf
联系人不存在,是否增加用户资料(Y/N):y
请输入联系人电话:000
| --- 欢迎使用通讯录程序 --- |
| --- 1:显示通讯录清单--- |
| --- 2:查询联系人资料 --- |
| --- 3:插入新的联系人 -- |
| --- 4:删除已有联系人 --- |
| --- 0:退出 --- |
请选择功能菜单:2
请输入联系人姓名:zwl
联系人不存在,是否增加用户资料(Y/N):n
| --- 欢迎使用通讯录程序 --- |
| --- 1:显示通讯录清单--- |
| --- 2:查询联系人资料 --- |
| --- 3:插入新的联系人 -- |
| --- 4:删除已有联系人 --- |
| --- 0:退出 --- |
请选择功能菜单:3
请输入联系人姓名:zgh
已存在联系人:zgh 15272502101
是否修改用户资料(Y/N):y
请输入联系人电话:155
| --- 欢迎使用通讯录程序 --- |
| --- 1:显示通讯录清单--- |
| --- 2:查询联系人资料 --- |
| --- 3:插入新的联系人 -- |
| --- 4:删除已有联系人 --- |
| --- 0:退出 --- |
请选择功能菜单:3
请输入联系人姓名:zgh
已存在联系人:zgh 155
是否修改用户资料(Y/N):n
| --- 欢迎使用通讯录程序 --- |
| --- 1:显示通讯录清单--- |
| --- 2:查询联系人资料 --- |
| --- 3:插入新的联系人 -- |
| --- 4:删除已有联系人 --- |
| --- 0:退出 --- |
请选择功能菜单:3
请输入联系人姓名:zwl
请输入联系人电话:555
| --- 欢迎使用通讯录程序 --- |
| --- 1:显示通讯录清单--- |
| --- 2:查询联系人资料 --- |
| --- 3:插入新的联系人 -- |
| --- 4:删除已有联系人 --- |
| --- 0:退出 --- |
请选择功能菜单:4
请输入联系人姓名:zwl
删除联系人:zwl 555
| --- 欢迎使用通讯录程序 --- |
| --- 1:显示通讯录清单--- |
| --- 2:查询联系人资料 --- |
| --- 3:插入新的联系人 -- |
| --- 4:删除已有联系人 --- |
| --- 0:退出 --- |
请选择功能菜单:1
姓名 = zgh,联系电话 = 155
姓名 = xy,联系电话 = 110
姓名 = lcw,联系电话 = 888
姓名 = hq,联系电话 = 120
姓名 = tf,联系电话 = 000
| --- 欢迎使用通讯录程序 --- |
| --- 1:显示通讯录清单--- |
| --- 2:查询联系人资料 --- |
| --- 3:插入新的联系人 -- |
| --- 4:删除已有联系人 --- |
| --- 0:退出 --- |
请选择功能菜单:0
运行之后的json文件:
{"zgh": "155", "xy": "110", "lcw": "888", "hq": "120", "tf": "000"}
选择题:1~5
1
>>> print(type({}))
<class 'dict'>
2
>>> print(type([]))
<class 'list'>
3
>>> print(type(()))
<class 'tuple'>
4
>>> dict1 = {}
>>>
>>> dict2 = {2:6}
>>>
>>> dict3 = {[1,2,3] : "user"}
Traceback (most recent call last):
File "<pyshell#10>", line 1, in <module>
dict3 = {[1,2,3] : "user"}
TypeError: unhashable type: 'list'
>>>
>>> dict4 = {(1,2,3) : "users"}
字典的键必须是可hash对象:bool、int、float、complex、str、tuple、frozenset
而 list、dict、set 是不可hash的
5
>>> dict1 = {}
>>>
>>> dict2 = {1:8}
>>>>
>>> dict3 = dict([2,4], [3,6])
Traceback (most recent call last):
File "<pyshell#20>", line 1, in <module>
dict3 = dict([2,4], [3,6])
TypeError: dict expected at most 1 arguments, got 2
>>>
>>> dict4 = dict(([2,4], [3,6]))
填空题:1~8
1
>>> print(len({}))
0
2
>>> d = {1:'x', 2:'y', 3:'z'}
>>> del d[1]
>>> del d[2]
>>> d[1] = 'A'
>>> print(len(d))
2
3
>>> print(set([1, 2, 1, 2, 3]))
{1, 2, 3}
4
>>> fruits = {'apple':3, 'banana':4, 'pear':5}
>>> fruits['banana'] = 7
>>> print(sum(fruits.values()))
15
d.values()
返回字典d的值value的列表
5
>>> d1 = {1:'food'}
>>> d2 = {1:'食品', 2:'饮料'}
>>> d1.update(d2)
>>> print(d1[1])
食品
d.update([other])
使用字典或键值对,更新或添加项目到字典d
6
>>> names = ['Amy', 'Bob', 'Charlie', 'Daling']
>>> print(names[-1][-1])
g
names[-1] = ‘Daling’
names[-1][-1] = ‘Daling’[-1] = ‘g’
7
>>> s1 = {1, 2, 3}
>>> s2 = {3, 4, 5}
>>>
>>> s1.update(s2)
>>> s1
{1, 2, 3, 4, 5}
>>>
>>> s1.intersection_update(s2)
>>> s1
{3, 4, 5}
>>>
>>> s1.difference_update(s2)
>>> s1
set()
>>>
>>> s1.symmetric_difference_update(s2)
>>> s1
{3, 4, 5}
>>>
>>> s1.add('x')
>>> s1
{3, 4, 5, 'x'}
>>>
>>> s1.remove(1)
Traceback (most recent call last):
File "<pyshell#67>", line 1, in <module>
s1.remove(1)
KeyError: 1
>>>
>>> s1.discard(3)
>>> s1
{4, 5, 'x'}
>>>
>>> s1.clear()
>>> s1
set()
思考题:1~15
1
>>> list1 = {}
>>> list1[1] = 1
>>> list1['1'] = 3
>>> list1[1] += 2
>>> sum = 0
>>> for k in list1:
sum += list1[k]
>>> print(sum)
6
2
>>> d = {1 : 'a', 2 : 'b', 3 : 'c'}
>>> del d[1]
>>> d[1] = 'x'
>>> del d[2]
>>> print(d)
{3: 'c', 1: 'x'}
3
>>> item_counter = {}
>>> def addone(item):
if item in item_counter:
item_counter[item] += 1
else:
item_counter[item] = 1
>>> addone('Apple')
>>> addone('Pear')
>>> addone('apple')
>>> addone('Apple')
>>> addone('kiwi')
>>> addone('apple')
>>> print(item_counter)
{'Apple': 2, 'Pear': 1, 'apple': 2, 'kiwi': 1}
4
>>> numbers = {}
>>> numbers[(1,2,3)] = 1
>>> numbers
{(1, 2, 3): 1}
>>> numbers[(2,1)] = 2
>>> numbers
{(1, 2, 3): 1, (2, 1): 2}
>>> numbers[(1,2)] = 3
>>> numbers
{(1, 2, 3): 1, (2, 1): 2, (1, 2): 3}
>>> sum = 0
>>> for k in numbers:
sum += numbers[k]
>>> print(len(numbers),' ',sum,' ', numbers)
3 6 {(1, 2, 3): 1, (2, 1): 2, (1, 2): 3}
提示:
>>> (1,2) == (1,2)
True
>>> (1,2) == (2,1)
False
5
>>> d1 = {'a' : 1, 'b' : 2}
>>> d2 = d1
>>> d1['a'] = 6
>>> sum = d1['a'] + d2['a']
>>> print(sum)
12
d2 = d1
d1,d2指向同一个地址
6
>>> d1 = {'a' : 1, 'b' : 2}
>>> d2 = dict(d1)
>>> d1['a'] = 6
>>> sum = d1['a'] + d2['a']
>>> print(sum)
7
d2 = dict(d1)
d1,d2指向是不同的地址
7
>>> from collections import *
>>> m1 = {1 : 'a', 2 : 'b'}
>>> m2 = {2 : 'a', 3 : 'x', 4 : 'y'}
>>> m = ChainMap(m1, m2)
>>> print(m.maps, m.parents, m.new_child())
[{1: 'a', 2: 'b'}, {2: 'a', 3: 'x', 4: 'y'}] ChainMap({2: 'a', 3: 'x', 4: 'y'}) ChainMap({}, {1: 'a', 2: 'b'}, {2: 'a', 3: 'x', 4: 'y'})
>>> print(m[1], m[3])
a x
>>> m[1] = 'A'
>>> m[3] = 'X'
>>> print(m)
ChainMap({1: 'A', 2: 'b', 3: 'X'}, {2: 'a', 3: 'x', 4: 'y'})
m.maps
属性,返回m对象内部包含的map的列表m.parents
属性,返回包含其父map的新的ChainMap对象,即ChainMap( * d.maps[1:])m.new_child()
方法,返回新的ChainMap对象,即ChainMap({}, * d.maps)- 在查询时,首先查询第一个map,如果没有查到,则依次查询其他map
- ChainMap只允许更新第一个map
8
>>> from collections import *
>>> c1 = Counter()
>>> print(c1)
Counter()
>>>
>>> c2 = Counter('banana')
>>> print(c2)
Counter({'a': 3, 'n': 2, 'b': 1})
>>>
>>> c3 = Counter({'R':4, 'B':2})
>>> print(c3)
Counter({'R': 4, 'B': 2})
>>>
>>> c4 = Counter(birds = 2, cats = 4, dog = 8)
>>> print(c4)
Counter({'dog': 8, 'cats': 4, 'birds': 2})
>>>
>>> print(c4['flowers'], c4['cats'])
0 4
>>>
>>> print(list(c3.elements()))
['R', 'R', 'R', 'R', 'B', 'B']
>>>
>>> print(c4.most_common(2))
[('dog', 8), ('cats', 4)]
>>>
>>>> c3.subtract('RGB')
>>> print(c3)
Counter({'R': 3, 'B': 1, 'G': -1})
创建Counter对象:
c = Counter()
创建空的Counter对象c = Counter('banana')
基于序列创建Counter对象c = Counter({'red':4, 'blue':2})
基于字典映射c = Counter(cats = 4, dogs = 8)
基于命名参数
- Counter对象支持字典映射的属性和方法,但查询时如果键不存在将不会报错,而是返回值0
c.elements()
返回元素列表,各元素重复的次数为其计数c.most_common([n])
返回计数值最大的n个元素的元组(元素,计数)列表c.subtract([iterable-or-mapping])
元素的计数值减去序列或字典中对应元素的计数
9
>>> from collections import *
>>> dq = deque()
>>> dq.append('a')
>>> dq.append(2)
>>> dq.append('c')
>>> data = iter(dq)
>>> while True:
try: i = next(data)
except StopIteration: break
print(i, end=' ')
a 2 c
>>> print(dq.pop(), dq.pop(), dq.pop())
c 2 a
dq.append(x)
在右端添加元素xdq.pop()从右端弹出元素。
若队列中无元素,则导致IndexErrordq.popleft()
从左端弹出元素。若队列中无元素,则导致IndexError- 使用内置函数
iter(obj)可以返回一个迭代器 - 使用内置函数
next()可以依次返回迭代器对象的下一个项目值
10
>>> from collections import *
>>> dq = deque()
>>> dq.append('a')
>>> dq.append(2)
>>> dq.append('c')
>>> print(dq.popleft(), dq.popleft(), dq.popleft())
a 2 c
11
>>> from collections import defaultdict
>>> s = [('r', 3), ('g', 2), ('b', 1)]
>>> dd = defaultdict(int, s)
>>> print(dd['b'], dd['w'])
1 0
>>>
>>> s1 = [('r', 3), ('g', 2), ('b', 1), ('r', 5), ('b', 4)]
>>> dd1 = defaultdict(list)
>>> for k,v in s1:
dd1[k].append(v)
>>> print(list(dd1.items()))
[((1, 2), []), ('r', [3, 5]), ('g', [2]), ('b', [1, 4])]
- 与dict的区别是,在创建
defaultdict对象时可以使用构造函数参数function_factory指定其键值对中值的类型 defaultdict实现了__missing__(key),即键不存在时返回值的类型(function_factory)对应的默认值,例如数值为0、字符串为'',list为[]
此处,保有疑问,个人觉的print(list(dd1.items()))的运行结果应该是[ ('r', [3, 5]), ('g', [2]), ('b', [1, 4])],没有弄懂((1, 2), [])从何处来?
12
>>> from collections import *
>>> d = {'red' : 3, 'green' : 4, 'blue' : 1}
>>> print(d.items(), sorted(d.items()))
dict_items([('red', 3), ('green', 4), ('blue', 1)]) [('blue', 1), ('green', 4), ('red', 3)]
>>>
>>> od = OrderedDict(sorted(d.items()))
>>> print(od.popitem(), od.popitem(False))
('red', 3) ('blue', 1)
- 除了继承dict的方法外,OrderedDict对象有一个方法:
popitem(last=True)
弹出最后一个元素;如果last=False,则弹出第一个元素 |
13
>>> from collections import *
>>> p = namedtuple('Point', ['x', 'y'])
>>> p.x = 1
>>> p.y = 2
>>> print(p._fields, p.x, p.y)
('x', 'y') 1 2
>>>
>>> t = [10, 20]
>>> p1 = p._make(t)
>>> print(p1._asdict())
OrderedDict([('x', 10), ('y', 20)])
>>>
>>> print(p1._replace(x=100), p1.x, p1.y)
Point(x=100, y=20) 1 2
- 创建的命名元组的类可以通过
_fields返回其字段属性 - namedtuple创建的类继承自tuple,包含额外的三个方法:
_make(iterable),从指定序列iterable构建命名元组对象 _asdict()
把命名元组对象转换为OrderDict对象_replace(kwargs())
创建新的命名元组对象,替换指定字段
14
>>> import array
>>> arr1 = array.array('i', (1, 2, 3, 4, 5))
>>> arr1[1] = 22
>>> print(arr1, arr1[2:], type(arr1[1]))
array('i', [1, 22, 3, 4, 5]) array('i', [3, 4, 5]) <class 'int'>
>>> del arr1[2:]
>>> print(arr1, arr1.typecode, arr1.itemsize)
array('i', [1, 22]) i 4
15
>>> import array
>>> a = array.array('b', (3, 2))
>>> a.append(3)
>>> a.extend((3, 5))
>>> print(a, a.count(3))
array('b', [3, 2, 3, 3, 5]) 3
>>> a.frombytes(b'A1')
>>> a.fromlist([8, 9])
>>> print(a, a.index(3))
array('b', [3, 2, 3, 3, 5, 65, 49, 8, 9]) 0
>>> a.insert(0, 1)
>>> a.pop()
9
>>> a.remove(2)
>>> a.reverse()
>>> print(a.tolist())
[8, 49, 65, 5, 3, 3, 3, 1]
上机实践:2~13
对于书中给的查找算法和排序算法
- 查找算法:二分排序法
- 排序算法:冒泡,选择,插入,归并,快排
我突发奇想,写了以上算法中是如何玩转下标的
Python 关于下标的运用技巧(二分查找法,冒泡、选择、插入、归并、快速排序算法)
2. 修改例11.3,在列表中顺序查找特定数值的程序,设法从命令行参数中获取要查询的数据
import sys
def sequentialSearch(alist, item):
pos = 0
found = False
while pos < len(alist) and not found:
if alist[pos] == item:
found = True
else:
pos += 1
return found
if __name__ == '__main__':
testlist = [1, 3, 33, 8, 37, 29, 32, 15, 5]
item = float(sys.argv[1])
print(sequentialSearch(testlist, item))
涉及到命令行参数,一般有两种执行方式
- 通过控制台(cmd)
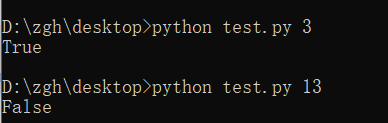
- 通过编辑器(就是你写python代码的工具)
我写这些小玩意,使用的是python自带的IDLE,
以IDLE(使用其他编辑器的,自己百度一下怎么执行时输入命令行参数)为例:

点击Run,然后Run…Customized(有快捷键:shift+F5)
输入命令行参数即可

3. 修改例11.4,在列表中顺序查找最大值和最小值的示例程序,设法从命令行参数中获取测试列表的各元素
import sys
def max1(alist):
pos = 0
iMax = alist[0]
while pos < len(alist):
if alist[pos] > iMax:
iMax = alist[pos]
pos += 1
return iMax
def min1(alist):
pos = 0
iMin = alist[0]
while pos < len(alist):
if alist[pos] < iMin:
iMin = alist[pos]
pos += 1
return iMin
if __name__ == '__main__':
alist = []
for i in range(1, len(sys.argv)):
alist.append(float(sys.argv[i]))
print("最大值 = ", max1(alist))
print("最小值 = ", min1(alist))
涉及到命令行参数,一般有两种执行方式
- 通过控制台(cmd)

- 通过编辑器(就是你写python代码的工具)
我写这些小玩意,使用的是python自带的IDLE,
以IDLE(使用其他编辑器的,自己百度一下怎么执行时输入命令行参数)为例:
点击Run,然后Run…Customized(有快捷键:shift+F5)
输入命令行参数即可
4. 修改例11.5,二分查找法的递归程序,设法从命令行参数中获取测试列表的各元素以及所要查找的关键字
怎么理解二分查找法的递归实现和非递归实现等算法,可以看一我的这篇文章
Python 关于下标的运用技巧(二分查找法,冒泡、选择、插入、归并、快速排序算法)
import sys
def _binarySearch(key, a, lo, hi):
if lo >= hi:
return -1
mid = (lo + hi) // 2
if(key < a[mid]):
return _binarySearch(key, a, lo, mid)
elif(key > a[mid]):
return _binarySearch(key, a, mid+1, hi)
else:
return mid
def binarySearch(key, a):
return _binarySearch(key, a, 0, len(a))
if __name__ == '__main__':
a = []
key = float(sys.argv[1])
for i in range(2, len(sys.argv)):
a.append(float(sys.argv[i]))
print("关键字{0}位于列表索引(-1表示不存在):{1}".format(key, binarySearch(key, a)))
涉及到命令行参数,一般有两种执行方式
- 通过控制台(cmd)
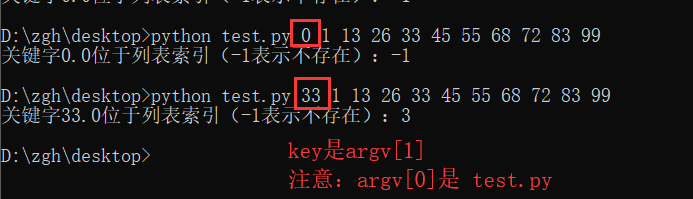
- 通过编辑器(就是你写python代码的工具)
我写这些小玩意,使用的是python自带的IDLE,
以IDLE(使用其他编辑器的,自己百度一下怎么执行时输入命令行参数)为例:
点击Run,然后Run…Customized(有快捷键:shift+F5)
输入命令行参数即可
5. 修改例11.6,二分查找法的非递归程序,设法从命令行参数中获取测试列表的各元素以及所要查找的关键字
import sys
def binarySearch(key, a):
low = 0
high = len(a) -1
while low <= high:
mid = (low + high)//2
if(key > a[mid]):
low = mid +1
elif(key < a[mid]):
high = mid -1
else:
return mid
return -1
if __name__ == '__main__':
a = []
key = float(sys.argv[1])
for i in range(2, len(sys.argv)):
a.append(float(sys.argv[i]))
print("关键字{0}位于列表索引(-1表示不存在):{1}".format(key, binarySearch(key, a)))
涉及到命令行参数,一般有两种执行方式
- 通过控制台(cmd)

- 通过编辑器(就是你写python代码的工具)
我写这些小玩意,使用的是python自带的IDLE,
以IDLE(使用其他编辑器的,自己百度一下怎么执行时输入命令行参数)为例:
点击Run,然后Run…Customized(有快捷键:shift+F5)
输入命令行参数即可
6. 修改例11.8,冒泡排序算法程序,设法从命令行参数中获取测试列表的各元素
import sys
def bubbleSort(a):
for i in range(len(a)-1, -1, -1):
for j in range(i):
if a[j] > a[j+1]:
a[j],a[j+1] = a[j+1],a[j]
def main():
a = []
for i in range(1, len(sys.argv)):
a.append(float(sys.argv[i]))
bubbleSort(a)
print(a)
if __name__ == '__main__':main()
涉及到命令行参数,一般有两种执行方式
- 通过控制台(cmd)

- 通过编辑器(就是你写python代码的工具)
我写这些小玩意,使用的是python自带的IDLE,
以IDLE(使用其他编辑器的,自己百度一下怎么执行时输入命令行参数)为例:
点击Run,然后Run…Customized(有快捷键:shift+F5)
输入命令行参数即可
输出:
[1.0, 3.0, 13.0, 26.0, 33.0, 45.0, 55.0, 68.0, 72.0, 83.0, 99.0]
7. 修改例11.9,选择排序算法程序,设法从命令行参数中获取测试列表的各元素
import sys
def selectionSort(a):
for i in range(0, len(a)-1):
for j in range(i+1, len(a)):
if(a[j] < a[i]):
a[i],a[j] = a[j],a[i]
def main():
a = []
for i in range(1, len(sys.argv)):
a.append(float(sys.argv[i]))
selectionSort(a)
print(a)
if __name__ == '__main__':main()
涉及到命令行参数,一般有两种执行方式
- 通过控制台(cmd)
- 通过编辑器(就是你写python代码的工具)
我写这些小玩意,使用的是python自带的IDLE,
以IDLE(使用其他编辑器的,自己百度一下怎么执行时输入命令行参数)为例:
点击Run,然后Run…Customized(有快捷键:shift+F5)
输入命令行参数即可
输出:
[1.0, 3.0, 13.0, 26.0, 33.0, 45.0, 55.0, 68.0, 72.0, 83.0, 99.0]
8. 修改例11.10,插入排序算法程序,设法从命令行参数中获取测试列表的各元素
import sys
def insertSort(a):
for i in range(1, len(a)):
for j in range(i, 0, -1):
if(a[j-1] > a[j]):
a[j-1],a[j] = a[j],a[j-1]
def main():
a = []
for i in range(1, len(sys.argv)):
a.append(float(sys.argv[i]))
insertSort(a)
print(a)
if __name__ == '__main__':main()
涉及到命令行参数,一般有两种执行方式
- 通过控制台(cmd)
- 通过编辑器(就是你写python代码的工具)
我写这些小玩意,使用的是python自带的IDLE,
以IDLE(使用其他编辑器的,自己百度一下怎么执行时输入命令行参数)为例:
点击Run,然后Run…Customized(有快捷键:shift+F5)
输入命令行参数即可
输出:
[1.0, 3.0, 13.0, 26.0, 33.0, 45.0, 55.0, 68.0, 72.0, 83.0, 99.0]
9. 修改例11.11,归并排序算法程序,设法从命令行参数中获取测试列表的各元素
import sys
def merge(left, right):
merged = []
i, j = 0, 0
left_len, right_len = len(left), len(right)
while i < left_len and j < right_len:
if left[i] <= right[j]:
merged.append(left[i])
i += 1
else:
merged.append(right[j])
j += 1
merged.extend(left[i:])
merged.extend(right[j:])
return merged
def mergeSort(a):
if len(a) <= 1:
return a
mid = len(a) // 2
left = mergeSort(a[:mid])
right = mergeSort(a[mid:])
return merge(left, right)
def main():
a = []
for i in range(1, len(sys.argv)):
a.append(float(sys.argv[i]))
print(mergeSort(a))
if __name__ == '__main__':main()
涉及到命令行参数,一般有两种执行方式
- 通过控制台(cmd)
- 通过编辑器(就是你写python代码的工具)
我写这些小玩意,使用的是python自带的IDLE,
以IDLE(使用其他编辑器的,自己百度一下怎么执行时输入命令行参数)为例:
点击Run,然后Run…Customized(有快捷键:shift+F5)
输入命令行参数即可
输出:
[1.0, 3.0, 13.0, 26.0, 33.0, 45.0, 55.0, 68.0, 72.0, 83.0, 99.0]
10. 修改例11.12,快速排序算法程序,设法从命令行参数中获取测试列表的各元素
import sys
def quickSort(a, low , high):
i = low
j = high
if i >= j:
return a
key = a[i]
while i < j:
while i < j and a[j] >= key:
j -= 1
a[i] = a[j]
while i < j and a[i] <= key:
i += 1
a[j] = a[i]
a[i] = key
quickSort(a, low, i-1)
quickSort(a, j+1, high)
def main():
a = []
for i in range(1, len(sys.argv)):
a.append(float(sys.argv[i]))
quickSort(a, 0, len(a)-1)
print(a)
if __name__ == '__main__':main()
涉及到命令行参数,一般有两种执行方式
- 通过控制台(cmd)
- 通过编辑器(就是你写python代码的工具)
我写这些小玩意,使用的是python自带的IDLE,
以IDLE(使用其他编辑器的,自己百度一下怎么执行时输入命令行参数)为例:
点击Run,然后Run…Customized(有快捷键:shift+F5)
输入命令行参数即可
输出:
[1.0, 3.0, 13.0, 26.0, 33.0, 45.0, 55.0, 68.0, 72.0, 83.0, 99.0]
11. 参考例11.42,实现namedtuple对象应用程序,读取成绩文件scores.csv的内容(学员、ID、语文、数学、外语和信息),显示学员ID和平均成绩
自己写一个scores.csv文件:
csv文件:推荐以逗号分隔
zgh, 1, 100, 100, 100, 100
xy, 2, 99, 98, 90, 85
hq, 3, 90, 98, 80, 96
lcw, 4, 85, 88, 65, 90
python代码:
from collections import *
import csv
Score = namedtuple('Score', 'name, id, chinese, math, english, computer')
for stu in map(Score._make, csv.reader(open("scores.csv", encoding = 'utf-8'))):
score_average = (float(stu.chinese) + float(stu.math) + float(stu.math) + float(stu.computer)) / 4
print(stu.id, score_average)
运行结果:
1 100.0
2 95.0
3 95.5
4 87.75
12. 创建由‘Monday’~‘Sunday’7个值组成的字典,输出键列表、值列表以及键值列表
d = {1:'Monday', 2:'Tuesday', 3:'Wednesday', 4:'Thursday', 5:'Friday', 6:'Saturday', 7:'Sunday'}
#print(d.keys())
for k in d.keys():
print(k, end=' ')
print()
#print(d.values())
for v in d.keys():
print(v, end=' ')
print()
#print(d.items())
for i in d.items():
print(i, end=' ')
运行结果:
1 2 3 4 5 6 7
1 2 3 4 5 6 7
(1, 'Monday') (2, 'Tuesday') (3, 'Wednesday') (4, 'Thursday') (5, 'Friday') (6, 'Saturday') (7, 'Sunday')
13. 随机生成10个0(包含)~10(包含)的整数,分别组成集合A和集合B,输出A和B的内容、长度、最大值、最小值以及它们的并集、交集和差集
import random
def func():
l = []
for j in range(5):
x = random.randint(1,10)
l.append(x)
return set(l)
A = func()
B = func()
print("集合的内容、长度、最大值、最小值分别为:")
print(A, len(A), max(A), min(A))
print(B, len(B), max(B), min(B))
print("A和B的并集、交集和差集分别为:")
print(A|B, A&B, A-B)
某次运行效果:
集合的内容、长度、最大值、最小值分别为:
{2, 4, 5, 7, 9} 5 9 2
{2, 4, 5, 8, 10} 5 10 2
A和B的并集、交集和差集分别为:
{2, 4, 5, 7, 8, 9, 10} {2, 4, 5} {9, 7}
第十二章 图形用户界面
我对图形用户界面的兴趣不大,先放着吧
第十三章 图形绘制
图形绘制模块:tkinter
2. 参考例13.2利用Canvas组件创建绘制矩形的程序,尝试改变矩形边框颜色以及填充颜色
from tkinter import *
root = Tk()
c = Canvas(root, bg = 'white', width = 130, height = 70)
c.pack()
c.create_rectangle(10, 10, 60, 60, fill = 'red')
c.create_rectangle(70, 10, 120, 60, fill = 'green', outline = 'blue', width = 5)
创建画布对象:
root = Tk()
创建一个Tk根窗口组件rootc = Canvas(root, bg = 'white', width = 130, height = 70)
创建大小为200 * 100、背景颜色为白色的画布c.pack()
调用组件pack()方法,调整其显示位置和大小
绘制矩形:
c.create_rectangle(x0, y0, x1, y1, option, ...)
- (x0,y0)是左上角的坐标
- (x1,y1)是右下角的坐标
c.create_rectangle(70, 10, 120, 60, fill = 'green', outline = 'blue', width = 5)
用蓝色边框、绿色填充矩形,边框宽度为5
3. 参考例13.3利用Canvas组件创建绘制椭圆的程序,尝试修改椭圆边框样式、边框颜色以及填充颜色
from tkinter import *
root = Tk()
c = Canvas(root, bg = 'white', width = 280, height = 70)
c.pack()
c.create_oval(10, 10, 60, 60, fill = 'green')
c.create_oval(70, 10, 120, 60, fill = 'green', outline = 'red', width = 5)
c.create_oval(130, 25, 180, 45, dash = (10,))
c.create_oval(190, 10, 270, 50, dash = (1,), width = 2)

绘制椭圆
c.create_oval(x0, y0, x1, y1, option, ...)
- (x0,y0)是左上角的坐标
- (x1,y1)是右下角的坐标
c.create_oval(70, 10, 120, 60, fill = 'green', outline = 'red', width = 5)
绿色填充、红色边框,宽度为5c.create_oval(130, 25, 180, 45, dash = (10,))
虚线椭圆
4. 参考例13.4利用Canvas组件创建绘制圆弧的程序,尝试修改圆弧样式、边框颜色以及填充颜色
from tkinter import *
root = Tk()
c = Canvas(root, bg = 'white', width = 250, height = 70)
c.pack()
c.create_arc(10, 10, 60, 60, style = ARC)
c.create_arc(70, 10, 120, 60, style = CHORD)
c.create_arc(130, 10, 180, 60, style = PIESLICE)
for i in range(0, 360, 60):
c.create_arc(190, 10, 240, 60, fill = 'green', outline = 'red', start = i, extent = 30)
绘制圆弧:
c.create_arc(x0, y0, x1, y1, option, ...)
- (x0,y0)是左上角的坐标
- (x1,y1)是右下角的坐标
- 选项start(开始角度,默认为0)和extend(圆弧角度,从start开始逆时针旋转,默认为90度)决定圆弧的角度范围
- 选项start用于设置圆弧的样式
5. 参考例13.5利用Canvas组件创建绘制线条的程序,尝试修改线条样式和颜色
from tkinter import *
root = Tk()
c = Canvas(root, bg = 'white', width = 250, height = 70)
c.pack()
c.create_line(10, 10, 60, 60, arrow = BOTH, arrowshape = (3, 4, 5))
c.create_line(70, 10, 95, 10, 120, 60, fill = 'red')
c.create_line(130, 10, 180, 10, 130, 60, 180, 60, fill = 'green', width = 10, arrow = BOTH, joinstyle = MITER)
c.create_line(190, 10, 240, 10, 190, 60, 240, 60, width = 10)
绘制线条:
c.create_line(x0, y0, x1, y1, ..., xn, yn, option, ...)
- (x0,y0),(x1,y1),…,(xn,yn)是线条上各个点的坐标
6. 参考例13.6利用Canvas组件创建绘制多边形的程序,尝试修改多边形的形状、线条样式和填充颜色
from tkinter import *
root = Tk()
c = Canvas(root, bg = 'white', width = 250, height = 70)
c.pack()
c.create_polygon(35, 10, 10, 60, 60, 60, fill = 'red', outline = 'green')
c.create_polygon(70, 10, 120, 10, 120, 60, fill = 'white', outline = 'blue')
c.create_polygon(130, 10, 180, 10, 180, 60, 130, 60, outline = 'blue')
c.create_polygon(190, 10, 240, 10, 190, 60, 240, 60, fill = 'white', outline = 'black')
绘制多边形:
c.create_polygon(x0, y0, x1, y1, ..., option, ...)
- (x0,y0),(x1,y1),…,(xn,yn)是多边形上各个顶点的坐标
7. 参考例13.7利用Canvas组件创建绘制字符串和图形的程序,绘制y = cos(x) 的图形
绘制字符串:
c.create_text(x, y, option, ...)
- (x,y)是字符串放置的中心位置
y = sin(x)
from tkinter import *
import math
WIDTH, HEIGHT = 510, 210
ORIGIN_X, ORIGIN_Y = 2, HEIGHT/2 #原点
SCALE_X, SCALE_Y = 40, 100 #x轴、y轴缩放倍数
ox, oy = 0, 0
x, y = 0, 0
arc = 0 #弧度
END_ARC = 360 * 2 #函数图形画两个周期
root = Tk()
c = Canvas(root, bg = 'white', width = WIDTH, height = HEIGHT)
c.pack()
c.create_text(200, 20, text = 'y = sin(x)')
c.create_line(0, ORIGIN_Y, WIDTH, ORIGIN_Y)
c.create_line(ORIGIN_X, 0, ORIGIN_X, HEIGHT) #绘制x轴,y轴
for i in range(0, END_ARC+1, 10):
arc = math.pi * i / 180
x = ORIGIN_X + arc * SCALE_X
y = ORIGIN_Y - math.sin(arc) * SCALE_Y
c.create_line(ox, oy, x, y)
ox, oy = x, y
y = cos(x)
from tkinter import *
import math
WIDTH, HEIGHT = 510, 210
ORIGIN_X, ORIGIN_Y = 2, HEIGHT/2 #原点
SCALE_X, SCALE_Y = 40, 100 #x轴、y轴缩放倍数
ox, oy = 0, 0
x, y = 0, 0
arc = 0 #弧度
END_ARC = 360 * 2 #函数图形画两个周期
root = Tk()
c = Canvas(root, bg = 'white', width = WIDTH, height = HEIGHT)
c.pack()
c.create_text(200, 20, text = 'y = cos(x)')
c.create_line(0, ORIGIN_Y, WIDTH, ORIGIN_Y)
c.create_line(ORIGIN_X, 0, ORIGIN_X, HEIGHT)
for i in range(0, END_ARC+1, 10):
arc = math.pi * i / 180
x = ORIGIN_X + arc * SCALE_X
y = ORIGIN_Y - math.cos(arc) * SCALE_Y
c.create_line(ox, oy, x, y)
ox, oy = x, y
图形绘制模块:turtle
第十四章 数值日期和时间处理
第十五章 字符串和文本处理
第十六章 文件和数据交换
第十七章 数据访问
第十八章 网络编程和通信
第十九章 并行计算:进程、线程和协程
第二十章 系统管理
未完待续…

