该文从Pandas的数据的读写、数据清洗、数据过滤、数据转换(映射、替换、字符串矢量级运算)、数据合并等都进行了详细的总结和案例说明,是pandas的核心重点知识。
目录
DataFrame调用apply,列级别的转换,df[[0, 1,...]].apply(function)
DtaFrame调用applymap:通过函数实现元素级的映射转换。
一、数据读写处理文档
1.1、pandas数据的加载+写入
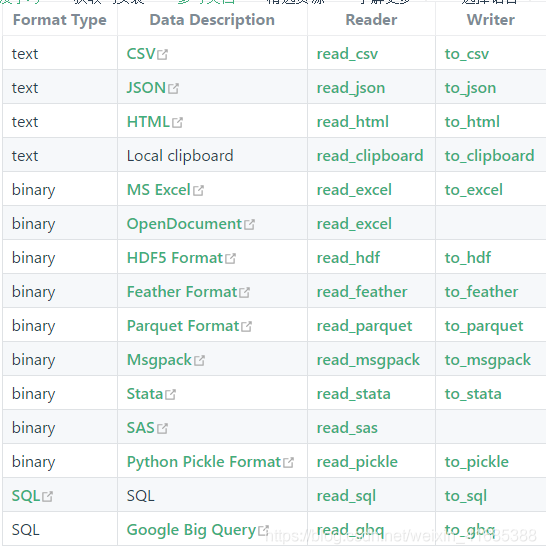
我们常用的数据加载函数为(点击下划线部分跳转到详细文档):
- read_csv :读取普通文件默认","分割,但可以指定为其他分隔符,如.csv 、 .txt文件等
- read_table :读取以‘/t’分割的文件到DataFrame
- read_sql :读取数据库数据,如mysql、oracle数据库等
- read_excel :读取excel文件
- to_csv:写入csv文件
- to_sql: 写入sql数据库
- to_excel: 写入excel文件
- ......
说明:
- read_csv与read_table默认使用的分隔符不同。通常情况下我们直接使用read_csv代替read_table
加载+写入csv/tsv/:https://blog.csdn.net/weixin_41685388/article/details/103768116
加载+写入txt:https://blog.csdn.net/weixin_41685388/article/details/103787971
加载+写入excel:https://blog.csdn.net/weixin_41685388/article/details/103773622
加载+写入mysql:https://blog.csdn.net/weixin_41685388/article/details/103770964
加载+写入oracle:https://blog.csdn.net/weixin_41685388/article/details/103791970
pandas官方手册:https://pandas.pydata.org/pandas-docs/stable/
pandas中文手册:https://www.pypandas.cn/docs/user_guide/io.html#io-sql
1.2、pandas写出数据到内存
# to_csv 不仅可以写入硬盘文件中,也可以写入内存(类文件对象)中。【处理速度更快,性能更好】
# 类文件对象:像文件那样具有read,write等功能的对象。
# StringIO 处理文本类型,如果是文本格式,都是字符串类型可解析
# BytesIO 处理二进制类型,如果是图片,视频,音频等,都是二进制格式。没法使用字符串来解析
from io import StringIO, BytesIO
# 创建一个类文件对象
str_io = StringIO()
df.to_csv(str_io)
# 查看文件指针的位置
display(str_io.tell())
# 调整文件指针的位置。将指针调整到文件的最前端。
str_io.seek(0)
display(str_io.read())
# 可以调用getvalue方法取出StringIO对象中的数据。(不用调整指针,再去读取)
display(str_io.getvalue())
print(str_io.getvalue())二、数据清洗
数据清洗主要包含以下几方面内容:
- 处理缺失值
- 处理重复值
- 处理异常值
准备数据,并读取数据:
import numpy as np import pandas as pd import warnings warnings.filterwarnings("ignore") df = pd.read_csv(r"spider.csv", header=None) display(df.sample(5)) #随机抽样df.head(n)/df.tail(n) #抽取前/后n行 display(df.shape,df.shape[0],df.shape[1]) #查看总的有n行,m列,这里有1369行,5列

2.1、缺失值处理
发现缺失值
Pandas中,会将float类型的nan与None视为缺失值,我们可以通过如下方法来检测缺失值:
- info()
- isnull()
- notnull()
说明:
- 判断是否存在空值,可以将isnull与any或all结合使用。
检测整体缺失值情况 df.info()
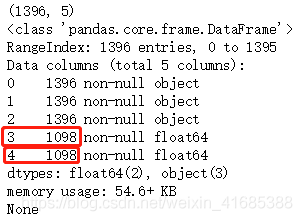
print(df.shape)
# 按照列来检测缺失值,首先可以调用info方法进行整体查看。
# info方法可以显示DataFrame中每列的相关信息。
print(df.info())
判断空值的情况
print(df.isnull().any()) #按列检查每列是否有至少一个空
print(df[[3,4]].isnull().any()) #检查指定列是否有至少一个空print(df.notnull().all()) #按列检查每列是否全部不为空
print(df[[3,4]].notnull().all()) #按列检查指定列是否全部不为空


丢弃缺失值
df.dropna(axis=0/1,inplace=True/False,how='any' / how='all' / thresh=n)
说明:
- axis:指定丢弃行或者丢弃列(默认为丢弃行axis = 0)。axis = 0 / axis = 1
- inplace:指定是否就地修改,默认为False。 是否就地操作
- how:指定dropna丢弃缺失值的行为,默认为any(只要存在就删除)。all (该行(列)全部为空才删除)/ any
- thresh:当非空数值达到该值时,保留数据,否则删除。如 thresh = 3,弥补how的不足(与how不同时使用)
df = pd.read_csv("spider.csv", header=None)
display(df.head())# 处理空值。丢弃空值,使用dropna。
df1 = df.dropna() #默认<=>df2,# 这个行为表示: 把df中的 有缺失字段值的任意一行都删掉,但不使用就地删除
# <=> df2 = df.dropna(axis=0,inplace=False,how='any')
df1.info() #处理后df1已经删除了有空值的行
df.info() #由于inplace=False,所以df不变,后续继续处理和运算使用df1
df = pd.read_csv("spider.csv", header=None)
#display(df.head())df1 = df.dropna(axis=0,inplace=False,thresh=4) #4个及以上字段不为空,则保留,否则删除
print(df.info())
print(df1.shape)
print(df1.info())


填充缺失值
df.fillna(value / method ='ffill' [,limit=n] / method='bfill' [,limit=n] ,[inplace=True/False])
说明:
- value:填充所使用的值。固定值填充,支持直接输入值,支持字典,支持Series,需要注意的是字典的key值,Series的index要与df的列名称对应。
- method:指定前值(上一个有效值)填充(pad / ffill),还是后值(下一个有效值)填充(backfill / bfill)。
- limit:如果指定method,表示最大连续NaN的填充数量,如果没有指定method,则表示最大的NaN填充数量。
- inplace:指定是否就地修改,默认为False。
这些参数都很常用,联合起来控制进行替换的规则
df = pd.read_csv("spider.csv", header=None)
display(df.head())
df_mean = round(df.mean(),2) #计算每列的均值
display(df_mean,type(df_mean))
#固定值填充,支持直接输入值,支持字典,支持Series,
#需要注意的是字典的key值,Series的index要与df的列名称对应
df1 = df.fillna(df_mean)
display(df1.head())



df = pd.read_csv("spider.csv", header=None)
display(df[18:22])
#向下填充
df1 = df.fillna(method="ffill",inplace=False)
display(df1[18:22])
#向上填充
df2 = df.fillna(method='bfill',inplace=False)
display(df2[18:22])# limit参数。如果指定method,则表示最多连续填充。
# 如果没有指定method,则表示总共填充。
df3 = df.fillna(method="bfill", limit=1)
display(df3[18:22])




2.2、重复值处理
在处理数据中,可能会出现重复的数据,我们通常需要将重复的记录删除。
df = pd.read_csv("spider.csv", header=None) #导入数据
display(df.head())
发现重复值
我们可以通过duplicated方法来发现重复值。该方法返回Series类型的对象,值为布尔类型,表示是否与上一行重复。
r = df[df.duplicated( [subset=[0,1,...],keep='first'/'last'/False)] )]
display(r.sort_values([1,0,...], axis=0))
参数说明:
- subset:指定依据哪些列判断是否重复,默认为所有列。
- keep:指定记录被标记为重复(True)的规则。默认为first。
#默认不加参数的情况
# 检测重复值,, 这个函数的作用个,就是把每一行都映射成一个True或者false的结果
# 如果结果为True 表示: 这一行跟某一行重复了。默认全部字段重复才算重复
display(df.duplicated().sample(5))
display(df[df.duplicated()]) #这样输出的只是判断为True行


#指定标记重复记录的规则
# 如果需要查看所有重复的记录,可以使用keep参数。
# keep:
# first:前面的记录标记为True。
# last: 后面的记录标记为True。
# False:所有记录都标记为True。
# 假如 1 3 4 这三行重复了
# first last false
# 1 true false true
# 2 true true true
# 3 false true true
result = df[df.duplicated(keep=False)]
display(result.sort_values([2,0], axis=0)) #排序,按照第2列,第0列排序

#自定义判断重复的规则
# 可以使用subset参数来指定重复的规则。默认为所有列一致才认为是重复的。
# 规则改为:只要第0,与第1列相同,则认为是重复的。
r = df[df.duplicated(subset=[0,1],keep=False)] #自定义用于判断重复的列
display(r.sort_values([1,0], axis=0))

删除重复值
通过drop_duplicates可以删除重复值。
df.drop_duplicates([subset=[0,1,...], keep='first'/'last', inplace=Ture/False])
参数说明:
- subset:指定依据哪些列判断是否重复,默认为所有列。
- keep:指定记录删除(或保留)的规则。默认为first,所以一般不要再自行指定keep啦。
- inplace:指定是否就地修改,默认为False。
- #如果想了解关于当前这个方法的更多参数。怎么办?
df.drop_duplicates
# 按组合键:shift + tab 建 4次
df = pd.read_csv("spider.csv", header=None)
display(df.shape) #导入数据r = df[df.duplicated(subset=[0,1,2],keep='first')]
display(r.shape) #获取重复值
df1 = df.drop_duplicates(subset=[0,1,2],keep='first',inplace=False)
display(df1.shape) #删除重复制后的结果#结果:(1396, 5) (18, 5) (1378, 5)
2.3、无效值处理
检测无效值
可以通过DataFrame对象的describe方法查看数据的统计信息。不同类型的列,统计信息也不太相同。
无效值,跟缺失值的意思大致差不多,但是包含的范围更广泛 如:男 女 男 女 0
(1)、获取统计信息
df.describe() 获取数值列统计信息、df[[0,1,2]].describe() 获取指定的非数值列统计信息、
df.shape 获取行列数量 、df.info() 获取缺失值信息
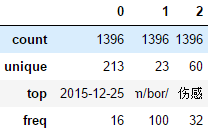
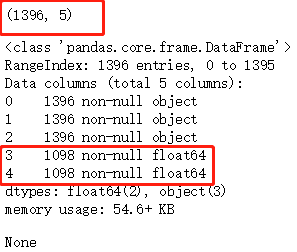
df = pd.read_csv("spider.csv", header=None) display(df.head()) display(df.describe()) #如果DataFrame当中存在数值列,则describe值显示数值列。 # describe()默认的规则:只针对数值列进行统计 describe() 描述 把数据的整体情况进行汇总汇报 # 数值列的统计与非数值列的统计,结果不同。 display(df[[0, 1, 2]].describe()) # 数值列 和 非数值列 的统计结果不一样! display(df.shape) #行列个数 display(df.info()) #查看各列元素缺失值情况


(2)、根据统计信息,先处理缺失值(删除dropna,填充fillna)
(3)、处理重复值
- r = df[df.duplicated( [subset=[0,1,...],keep='first'/'last'/False)] )]
- display(r.sort_values([1,0,...], axis=0))
- df1=df.drop_duplicates([subset=[0,1,...], keep='first'/'last', inplace=Ture/False])
(4)、处理其他异常值
三、数据过滤¶
可以使用布尔数组或者索引数组的方式来过滤数据。df[condition]
另外,也可以用DataFrame类的query方法来进行数据过滤 ,df.query()。在query方法中也可以使用外面定义的变量,需要在变量前加上@。
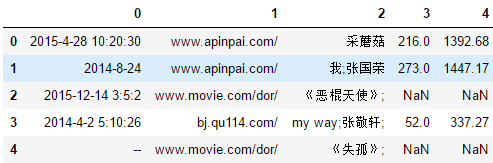
df = pd.read_csv("spider.csv", header=None,encoding='utf-8')
display(df.head())
# 数据过滤通常的方式:
# 通过判断条件生成一个布尔类型的数组,然后,DataFrame使用该布尔数组进行行过滤。
df[0] = pd.to_datetime(df[0],errors='coerce')
condition1 = df[0] < "2015-01-01"
condition2 = df[0].isnull()
display(df[condition1],df[condition2])

# 过滤的第二种方式。
df = pd.read_csv("spider.csv", header=None,encoding='utf-8')
df[0] = pd.to_datetime(df[0],errors='coerce')
df.columns = ["date", "url", "name", "num1", "num2"]
display(df.query("date < '2015-01-01'"))
display(df.query("date == 'NaT'"))
# 如果在query方法中,需要使用外面定义的变量,可以在变量名称前加上@符号,进行引用。
df = pd.read_csv("spider.csv", header=None,encoding='utf-8')
df.columns = ["date", "url", "name", "num1", "num2"]
df["date"] = pd.to_datetime(df["date"],errors='coerce')
s = ["2014-08-24 00:00:00","2014-04-02 05:10:26","NaT"]
display(df.query("date in @s"))
四、数据转换(映射、替换、字符串矢量级运算)
4.1、应用 apply、map、applymap映射转换
Series与DataFrame对象可以进行行(列)或元素级别的映射转换操作。
- 对于Series,可以调用apply或map方法。
- 对于DataFrame,可以调用apply或applymap方法。
- map:对当前Series的值进行映射转换。参数可以是一个Series,一个字典或者是一个函数。
- apply:通过函数实现映射转换。【Series传递元素,DataFrame传递行或列。】
- applymap:通过函数实现元素级的映射转换。
案例:
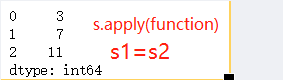
Series的s.apply(function)转换
#对于Series,依次传递每一个元素。函数的参数只能一个,函数的返回值,用来表示处理的结果。
def fx(x): #定义一个函数
return 2*x+3
s = pd.Series([0,2,4])
s1 = s.apply(fx) #将Series中的每一个元素应用到函数中
display(s1)# 对于非常简单的函数,我们可以使用lambda来实现。
s2 = s.apply(lambda x: x * 2 + 3) #应用于匿名函数
display(s2)

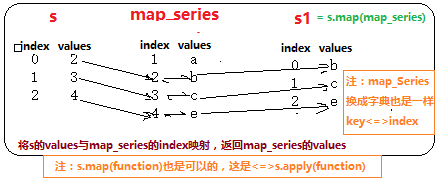
Series的s.map(map_series)
# 参数可以是Series,则根据Series的index来进行映射,获取结果值。
s = pd.Series([2, 3, 4])
map_series = pd.Series(["a", "b", "c", "e"], index=[1,2,3,4])
s1 = s.map(map_series)
display(s1)
关于DataFrame的apply与applymap方法。参数x是就是一列
DataFrame调用apply,列级别的转换,df[[0, 1,...]].apply(function)
df = pd.read_csv(r"DataFrame.txt",header=0,encoding="utf-8")
display(df)
# 自行求均值。
df2 = df[["Sales", "price"]].apply(lambda x: x.mean())
display(df2)def fx(x):
return x.mean()
df3 = df[["Sales", "price"]].apply(fx)
display(df3)


DtaFrame调用applymap:通过函数实现元素级的映射转换。
# 参数为一个函数,DataFrame中的每个元素都会调用一次该函数(将元素传递给该函数),获得一个映射的结果(函数的返回值)。
# applymap函数是一个元素级的映射,类似与Series的map函数。
df = pd.read_csv(r"DataFrame.txt",header=0,encoding="utf-8")
display(df)
df1 = df[["Sales", "price"]].applymap(lambda x: x + 1000)
def fx(x):
y = x+1000
return y
df2 = df[["Sales", "price"]].applymap(fx) # <=> df[["Sales", "price"]].apply(fx)
display(df1,df2) #df1 == df2

4.2、替换
Series或DataFrame可以通过replace方法可以实现元素值的替换操作。
- to_replace:被替换值,支持单一值,列表,字典,正则表达式。
- regex:是否使用正则表达式,默认为False。
df = pd.read_csv(r"DataFrame.txt",header=0,encoding="utf-8")
display(df)
# 替换。支持单个值,字典,列表,正则表达式,替换都是拷贝后的替换,原来的df不变
df1 = df.replace("--", "xxx") #单个值的替换
df2 = df.fillna(df["x"].mean()) #对于空值往往使用df.fillna()填充
df3 = df.replace({"500":"xxx","--":"xxx"}) # 字典 替换
df4 = df.replace(['500','--'],['aaa','bbb']) #列表对应替换
df5 = df.replace(['500','--'],'aaa') #列表替换为同一个值
df6 = df.replace('a(.*)', "aa", regex=True) #正则表达式替换
# replace的操作我们也可以通过apply或map来实现。
def fx(item):
if item >= 50:
Z = "合格"
else:
Z = "不合格"
return Z
# replace的操作我们也可以通过apply、map、applymap来实现。
df["Z"] = df["x"].map(fx)
display(df1,df2,df3,df4,df5,df6,df)

4.3、字符串矢量级运算
Series含有一个str属性,通过str能够进行字符串的矢量级运算。
使用Series的str属性时,需要Series元素的值是str(字符串)类型s.astype("str")。
| 函数表 | |||
| 矢量化字符串方法 | |||
| No | 方法 | RE | 说明 |
| 0 | 使用方式:s.str.cat() | 返回序列索引或其他 | |
| 1 | capitalize() | no | 字符串转大写 |
| 2 | cat([others, sep, na_rep, join]) | no | 用分隔符连接字符串;返回str或原对象构架 |
| 3 | center(width[, fillchar]) | no | 用附加字符填充字符串的左侧和右侧 |
| 4 | contains(‘'is') | yes | 判断字符串中是否包含子串true; pat str或正则表达式 |
| 5 | count(pat[, flags]) | yes | 子串出现次数 |
| 6 | decode(encoding[, errors]) | no | 字节解码 |
| 7 | encode(encoding[, errors]) | no | 字符串编码 |
| 8 | endswith(pat[, na]) | yes | 字符串结尾是否是特定子串 true |
| 9 | extract(pat[, flags, expand]) | yes | 从正则表达式pat中提取第一个匹配字符;结果为1个字符 |
| 10 | extractall(pat[, flags]) | yes | 从正则表达式pat提取所有匹配的,返回组 |
| 11 | find(sub[, start, end]) | no | 查子串首索引,子串包含在[start:end];无返回-1 |
| 12 | findall(pat[, flags]) | yes | 查找所有符合正则表达式的字符,以数组形式返回 |
| 13 | get(i) | no | 从指定位置提取字符 |
| 14 | get_dummies([sep]) | no | 用sep拆分每个字符串,返回一个虚拟/指示dataFrame |
| 15 | index(sub[, start, end]) | no | 子串最低索引,子串范围[start:end];无抛异常ValueError |
| 16 | isalnum() | no | 检查所有字符是否为字母数字 |
| 17 | isalpha() | no | 检查是否都是字母 |
| 18 | isdecimal() | no | 检查是否都是十进制 |
| 19 | isdigit() | no | 检查是否都是数字 |
| 20 | islower() | no | 检查是否都是小写 |
| 21 | isnumeric() | no | 检查是否都是数字 |
| 22 | isspace() | no | 检查是否都是空格 |
| 23 | istitle() | no | 检查是否都是标题 |
| 24 | isupper() | no | 检查是否都是大写 |
| 25 | join(sep) | no | 用分隔符连接所有字符;同一级有非str返回Na |
| 26 | len() | no | 计算每个字符串的长度 |
| 27 | ljust(width[, fillchar]) | no | 使用附加字符填充字符串的右侧 |
| 28 | lower() | no | 字符串转小写 |
| 29 | lstrip([to_strip]) | no | 左侧删除空格(包括换行符)或其他str |
| 30 | match(pat[, case, flags, na, …]) | yes | 确定每个字符串是否与正则表达式匹配。 |
| 31 | normalize(form) | no | 返回字符串的Unicode普通表单 |
| 32 | pad(width[, side, fillchar]) | no | 指定左或右填充字符补齐字符串 |
| 33 | partition([pat, expand]) | no | 分隔符拆分为3部分,分隔符左,分隔符,分隔符右 |
| 34 | repeat(repeats) | no | 重复每个元素指定的次数 |
| 35 | replace(pat,b) | yes | 将值pat替换为值b。 |
| 36 | rfind(sub[, start, end]) | no | 右边查找子串索引,子串包含在[start:end];无返回-1 |
| 37 | rindex(sub[, start, end]) | no | 返回子串的最高索引,子串范围[start:end];无抛出异常 |
| 38 | rjust(width[, fillchar]) | no | 使用附加字符填充字符串的左侧 |
| 39 | rpartition([pat, expand]) | no | 右拆分成3部分含分隔符 |
| 40 | rsplit([pat, n, expand]) | yes | 分隔符字符串右边拆分字符串 |
| 41 | rstrip([to_strip]) | no | 右侧删除空格(包括换行符) |
| 42 | slice([start, stop, step]) | no | 切片截取字符串 |
| 43 | slice_replace([start, stop, repl]) | no | 用另一个值替换字符串的位置切片;比较复杂看实例 |
| 44 | split([pat=None, n, expand]) | yes | 按分隔符或子串拆分字符串 |
| 45 | startswith('st') | yes | 字符串开头是否匹配子串True |
| 46 | strip('') | no | 删除字符串左右空白(包括换行符)或删除其他左右字符串 |
| 47 | swapcase() | no | 变换字母大小写 |
| 48 | title() | no | 字符串转标题 |
| 49 | translate(table[, deletechars]) | no | 通过映射表映射字符串中的所有字符 |
| 50 | upper() | no | 字符串转大写 |
| 51 | wrap(width, **kwargs) | no | 长字符串换行,#结果插入换行符\n |
| 52 | zfill(width) | no | 用0填充字符串的左侧 |
| 说明:类似Python中str忽略Na;适用于Series / Index | |||
列举几个常用案例:
s = pd.Series(["10 1 ",1001,10001])
s = s.astype("str") #先转换为字符串类型
len_s = s.str.len() #计算每个元素的长度
isdigit_s = s.str.isdigit() #查看每个元素是否只包含数字,返回True/False
cut_s = s.str[0:2] #切片截取字符串
split_s = s.str.split(" ") #指定字符进行切割,返回列表
strip_s = s.str.strip(' ') #删除左右两端的空格,中间部分依然保留
replace_s = s.str.replace(" ","") #将指定的字符替换为其他字符,这里将空格替换删除
display(len_s,isdigit_s,cut_s,split_s,strip_s,replace_s)
五、数据合并
concat()
我们可以通过DataFrame或Series类型的concat方法,来进行连接操作,连接时,会根据索引进行对齐。
- axis:指定连接轴,默认为0(上下)。【axis=0/1】
- join:指定连接方式,默认为外连接。【join='outer':并集,join='inner':交集】
- keys:可以用来区分不同的数据组。形成层级索引【这个稍微难理解一点】
- join_axes:指定连接结果集中保留的索引。默认全部保留【如:join_axes=[df1.columns]】
- ignore_index:忽略原来连接的索引,创建新的整数序列索引,默认为False。【ignore_index=True/False】
- sort:concat之后,是否按照列索引排序,sort=True/False
df1=pd.DataFrame({"date":[2015,2016,2017,2018,2019],"x1":[2000,3000,5000,8000,10000],"x2":[np.nan,"d","d","c","c"]})
df2=pd.DataFrame({'date':[2017,2018,2019,2020],"y1":[1000,2000,3000,2000]})
# display(df1,df2)
df3=pd.concat([df1,df2],keys=["df1","df2"])
display(df3)
#索引层级索引元素时,先外再内
df3.loc["df2",3].loc["y1"]

append()
在对行进行连接时,也可以使用Series或DataFrame的append方法。
append是concat的简略形式,只不过只能在axis=0上进行合并
df1=pd.DataFrame({"date":[2015,2016,2017,2018,2019],"x1":[2000,3000,5000,8000,10000],"x2":[np.nan,"d","d","c","c"]})
df2=pd.DataFrame({'date':[2017,2018,2019,2020],"y1":[1000,2000,3000,2000]})
# display(df1,df2)
df3=df1.append(df2)
display(df3)
merge()
通过pandas或DataFrame的merge方法,可以进行两个DataFrame的连接,这种连接类似于SQL中对两张表进行的join连接。
- how:指定连接方式。可以是inner, outer, left, right,默认为inner。
- on 指定连接使用的列(该列必须同时出现在两个DataFrame中),默认使用两个DataFrame中的所有同名列进行连接。
- left_on / right_on:指定左右DataFrame中连接所使用的列。
- left_index / right_index:是否将左边(右边)DataFrame中的索引作为连接列,默认为False。
- suffixes:当两个DataFrame列名相同时,指定每个列名的后缀(用来区分),默认为x与y。
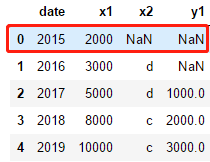
df1=pd.DataFrame({"date":[2015,2016,2017,2018,2019],"x1":[2000,3000,5000,8000,10000],"x2":[np.nan,"d","d","c","c"]})
df2=pd.DataFrame({'date':[2017,2018,2019,2020],"y1":[1000,2000,3000,2000]})
# display(df1,df2)
df3=df1.merge(df2,how='left',on="date")
display(df3)
join()
与merge方法类似,但是默认使用索引进行连接。
- how:指定连接方式。可以是inner, outer, left, right,默认为left。
- on:设置当前DataFrame对象使用哪个列与参数对象的索引进行连接。
- lsuffix / rsuffix:当两个DataFrame列名相同时,指定每个列名的后缀(用来区分),如果不指定,列名相同会产生错误。
join与merge类似,都是进行两张表的连接。
不同点:
- merge默认进行的内连接(inner),join默认进行的左外连接(left)。
- 当出现同名字段(列索引)时,merge可以自动补后缀(_x, _y),但是join不会自动补后缀,而是会产生错误。
- merge默认使用同名的列进行等值连接。join默认使用左右两表的索引进行连接。
- merge中on参数,指定两张表中共同的字段,而join中on参数,仅指定左表中的字段(右表依然使用索引)。
merge与join侧重点不同,merge侧重的是使用字段进行连接,而join侧重的是使用索引进行连接。
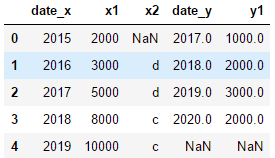
df1=pd.DataFrame({"date":[2015,2016,2017,2018,2019],"x1":[2000,3000,5000,8000,10000],"x2":[np.nan,"d","d","c","c"]})
df2=pd.DataFrame({'date':[2017,2018,2019,2020],"y1":[1000,2000,3000,2000]})
# display(df1,df2)
df3=df1.join(df2,how='left',lsuffix='_x',rsuffix='_y')#根据索引对齐
display(df3)
数据分析更多知识点关注博客,共同分享交流学习。
