二级索引实现方式:Hbase + Key-Value Store Indexer + Solr
同步int数据时提示异常
异常如下
2019-12-16 17:39:18,346 WARN com.ngdata.hbaseindexer.parse.ByteArrayValueMappers: Error mapping byte value 101 to int
java.lang.IllegalArgumentException: offset (0) + length (4) exceed the capacity of the array: 3
at org.apache.hadoop.hbase.util.Bytes.explainWrongLengthOrOffset(Bytes.java:838)
at org.apache.hadoop.hbase.util.Bytes.toInt(Bytes.java:1004)
at org.apache.hadoop.hbase.util.Bytes.toInt(Bytes.java:980)
at com.ngdata.hbaseindexer.parse.ByteArrayValueMappers$1.mapInternal(ByteArrayValueMappers.java:37)
at com.ngdata.hbaseindexer.parse.ByteArrayValueMappers$AbstractByteValueMapper.map(ByteArrayValueMappers.java:157)
at com.ngdata.hbaseindexer.morphline.ExtractHBaseCellsBuilder$Mapping.extractWithSingleOutputField(ExtractHBaseCellsBuilder.java:204)
at com.ngdata.hbaseindexer.morphline.ExtractHBaseCellsBuilder$Mapping.apply(ExtractHBaseCellsBuilder.java:197)
at com.ngdata.hbaseindexer.morphline.ExtractHBaseCellsBuilder$ExtractHBaseCells.doProcess(ExtractHBaseCellsBuilder.java:83)
at org.kitesdk.morphline.base.AbstractCommand.process(AbstractCommand.java:161)
at org.kitesdk.morphline.base.AbstractCommand.doProcess(AbstractCommand.java:186)
at org.kitesdk.morphline.base.AbstractCommand.process(AbstractCommand.java:161)
at com.ngdata.hbaseindexer.morphline.LocalMorphlineResultToSolrMapper.map(LocalMorphlineResultToSolrMapper.java:230)
at com.ngdata.hbaseindexer.morphline.MorphlineResultToSolrMapper.map(MorphlineResultToSolrMapper.java:145)
at com.ngdata.hbaseindexer.indexer.Indexer$RowBasedIndexer.calculateIndexUpdates(Indexer.java:289)
at com.ngdata.hbaseindexer.indexer.Indexer.indexRowData(Indexer.java:144)
at com.ngdata.hbaseindexer.indexer.IndexingEventListener.processEvents(IndexingEventListener.java:98)
at com.ngdata.sep.impl.SepEventExecutor$1.run(SepEventExecutor.java:97)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)服务调用的是Hbase jar包下的 Bytes.toInt方法,我们再idea中调用验证一下,提示异常和hbase-solr提示异常相同
int a = Bytes.toInt(Bytes.toBytes(111));
System.out.println(a);
System.out.println("-------------------");
int b = Bytes.toInt(Bytes.toBytes("101"));
System.out.println(b);
输出如下:
111
-------------------
Exception in thread "main" java.lang.IllegalArgumentException: offset (0) + length (4) exceed the capacity of the array: 3
at org.apache.hadoop.hbase.util.Bytes.explainWrongLengthOrOffset(Bytes.java:838)
at org.apache.hadoop.hbase.util.Bytes.toInt(Bytes.java:1004)
at org.apache.hadoop.hbase.util.Bytes.toInt(Bytes.java:980)
at com.example.demo.Test.main(Test.java:23)
查看调用的方法 Bytes.toInt 中 , 我们发现方法会判断如果 offset + length > bytes.length 抛出异常,也就是我们传入数据的字节数小于 4 则会抛出 explainWrongLengthOrOffset 异常
public static final int SIZEOF_INT = Integer.SIZE / Byte.SIZE; //SIZEOF_INT = 4
/**
* Converts a byte array to an int value
* @param bytes byte array
* @return the int value
*/
public static int toInt(byte[] bytes) {
return toInt(bytes, 0, SIZEOF_INT);
}
public static int toInt(byte[] bytes, int offset, final int length) {
if (length != SIZEOF_INT || offset + length > bytes.length) {
throw explainWrongLengthOrOffset(bytes, offset, length, SIZEOF_INT);
}
if (UNSAFE_UNALIGNED) {
return UnsafeAccess.toInt(bytes, offset);
} else {
int n = 0;
for(int i = offset; i < (offset + length); i++) {
n <<= 8;
n ^= bytes[i] & 0xFF;
}
return n;
}
}
private static IllegalArgumentException
explainWrongLengthOrOffset(final byte[] bytes,
final int offset,
final int length,
final int expectedLength) {
String reason;
if (length != expectedLength) {
reason = "Wrong length: " + length + ", expected " + expectedLength;
} else {
reason = "offset (" + offset + ") + length (" + length + ") exceed the"
+ " capacity of the array: " + bytes.length;
}
return new IllegalArgumentException(reason);
}
我们知道在java中 int 占用字节数为4 ,字符串"101"占用字节为3 ,所以当字符串小于 4 的时候,我们同步数据会报错
System.out.println("占用字节->"+"101".getBytes().length);
输出如下:
占用字节->3这时可以猜想是不是传入字符串长度 >= 4 时候,就正常了
我们通过hbase put进去数据
put 'tableName','test1','fn:comments_count','1111'
put 'tableName','test2','fn:comments_count','11111'我们发现日志中没有报错,并且solr中数据已经成功同步过去;但是发现同步过去的数据不对,并不是我们插入的

Cloudera 文档中提出可以实现 com.ngdata.hbaseindexer.parse.ByteArrayValueMapper 接口自定义类型

实现该接口,自定义类型解决上述问题
com.ngdata.hbaseindexer.parse.ByteArrayValueMapper 接口在jar包 hbase-indexer-engine-1.*-cdh*.*.*.jar 包中
该jar包可以从 /opt/cloudera/parcels/CDH-6.*.*-1.cdh6.*.*.p0.590678/lib/hbase-solr/lib 目录下找到,
> ls hbase-indexer-engine-1.*-cdh*.*.*.jar
hbase-indexer-engine-1.5-cdh6.0.1.jar实现该接口
import com.google.common.collect.ImmutableList;
import com.ngdata.hbaseindexer.parse.ByteArrayValueMapper;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.hadoop.hbase.util.Bytes;
import java.util.Collection;
public class Jastint implements ByteArrayValueMapper {
private static Log log = LogFactory.getLog(Jastint.class);
public Collection<? extends Object> map(byte[] input) {
try {
return ImmutableList.of(mapInternal(Bytes.toString(input)));
} catch (IllegalArgumentException e) {
log.warn(
String.format("Error mapping byte value %s to %s", Bytes.toStringBinary(input),
int.class.getName()), e);
return ImmutableList.of();
}
}
private int mapInternal(String toString) {
return Integer.parseInt(toString);
}
}
打成 jar 包,将jar传到 /opt/cloudera/parcels/CDH-6.*.*-1.cdh*.*.*.p0.590678/lib/hbase-solr/lib/ 目录下,Key-Value Store Indexer 服务启动时会读取该目录下的jar包
修改 Morphlines 配置文件如下,对 hbase_indexer_vt_fn_comments_count 字段 使用我们自定义的 com.jast.hbaseindexer.Jastint 类,注意这里要引用 包名+类名 否则会提示找不到类
SOLR_LOCATOR : {
# Name of solr collection
collection : hbaseindexer
# ZooKeeper ensemble
zkHost : "$ZK_HOST"
}
morphlines : [
{
id : WeiBoTableMap
importCommands : ["org.kitesdk.**", "com.ngdata.**"]
commands : [
{
extractHBaseCells {
mappings : [
{
inputColumn : "fn:name"
outputField : "hbase_indexer_vt_fn_name"
type : string
source : value
},{
inputColumn : "fn:comments_count"
outputField : "hbase_indexer_vt_fn_comments_count"
type : "com.jast.hbaseindexer.Jastint"
source : value
},{
inputColumn : "fn:text"
outputField : "hbase_indexer_vt_fn_text"
type : string
source : value
}
]
}
}
{ logDebug { format : "output record: {}", args : ["@{}"] } }
]
}
]
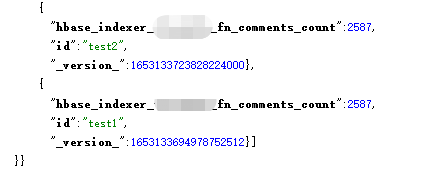
重启 Key-Value Store Indexer 服务,再次插入数据
put 'tableName','test1','fn:comments_count','2587'
put 'tableName','test2','fn:comments_count','2587'插入成功