《Inverted Residuals and Linear Bottlenecks: Mobile Networks for Classifification, Detection and Segmentation》
(一)论文地址:
(二)MobileNets_v2 解决的问题:
2017年作者提出了MobileNets_v1,其核心是将常规的卷积层分解成一个 (深度分离卷积层,简称 )和一个 (即 卷积核大小的卷积层,简称 ),从而有更小的参数,并且计算消耗更少;
详细介绍可以看我的这一篇博客:
【论文阅读笔记】MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
常规的卷积操作如图:

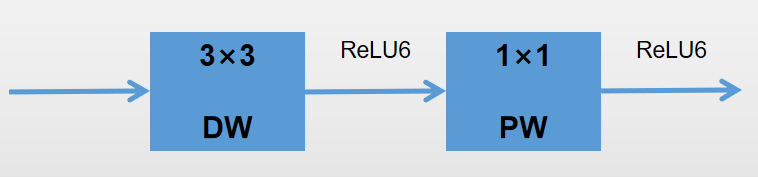
经过MobileNets_v1分解后的结构如图:

即(其中ReLU6表示将特征层的值限制在
区间内):
但是在实际训练时,作者发现
中有许多卷积核是空的(全为
):

这些空卷积核占用了训练和使用时的内存,却不会对特征提取中起到任何作用;
为了解决这个问题,作者提出了 MobileNets_v2;
(三)MobileNets_v2 的核心思想:
MobileNets_v2 的核心思想是:
- 将 中的 ReLU 换成线性变换(Linear),称之为 Linear Bottleneck;
- 使用了反残差结构(Inverted Residuals),即不同于 ResNet 的先收缩在膨胀的残差结构,这里先膨胀后收缩;
(四)ReLU 函数的缺陷:
MobileNets_v2 的作者认为,这些空卷积是由ReLU函数引起的:

在之前的研究中表明,相比于 tanh 和 sigmoid 函数,ReLU 在反向传播过程中计算量更少;
并且, tanh 和 sigmoid 在接近饱和区时,由于导数趋近于 0 ,会导致信息丢失和模型难以收敛;
以及,ReLU 会使一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生(以及一些人的生物解释);
但是,作者提出了两个新的观点:
- 如果特征仍能在 ReLU 转换之后够被保留(即为非零),那么 ReLU 的作用跟线性变换相同;
- ReLU 能够保持输入信息的完整性,但仅限于输入特征位于输入空间的低维子空间中;
第一个观点很好理解;
第二个观点作者给出了图示:

即假设输入是一个低维(2D)的螺线结构的数据:
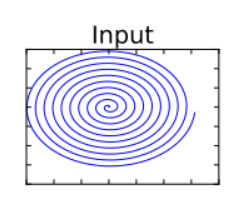
我们使用矩阵 (相当于卷积层)将它转换成高维数据(维度为 ),再用 ReLU 函数转换;
我们再用 矩阵 将高维数据转换成 2D 数据,对于不同的维度 ,结果如图:

可以看到,对于向低维数据变换(维度
),有很大一部分信息已经丢失了;
而当维度 时,大部分信息还是被保留下来了;
因此作者认为,在低维数据转换时应该将 ReLU 函数转换成 Linear 变换,在高维数据转换时可以保留 ReLU 函数,从而增加模型的鲁棒性;
(五)Linear Bottleneck:
基于以上理论,作者提出了 MoblieNets_v2 的基本结构,取消了模块中第二个 的 ReLU 变换,并采取了 扩张->卷积->压缩 的瓶状结构,称之为 Linear Bottleneck:

注意在这些模块相互连接时, 和 是等效的,因此下面默认以 为例;
用图示表述为:

(六)Inverted Residuals:

这里也采用了 ResNet 的残差结构,不过不同于 压缩->卷积->扩张 的结构,MobileNets_v2 采用了扩张->卷积->压缩 的相反结构:

用表格表示为:

其中:
- 和 分别是输入特征图的高和宽;
- 和 分别是输入和输入的 ;
- 是膨胀率,即中间层的 是输入层的 倍,文中取 ;
- 是 的步长;
(七)MoblieNets 的网络结构:

其中:
- 是膨胀率;
- 是输入特征图的 ;
- 是结构单元重复的次数;
- 是步长;
注意步长 为 时结构有所不同:

(八)MobileNets 的应用及实验结果:
1. 图像识别:

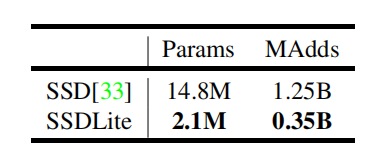
2. 目标检测——SSDLite:

3. 语义分割——MobileNet DeepLabv3:

