爬虫精髓:使用.*?进行匹配获取内容
python小技巧: alt加回车键快速导包
文章目录
- 一、json相关方法及用法
- 1. json的概念
- 2. json的操作
- 1. json.dumps()和json.loads()是将python中的list或dict转换成json语句(可以这么理解为操作数据)
- (1) json.dumps()函数是将一个Python数据类型列表进行json格式的编码(可以这么理解,json.dumps()函数是将字典转化为字符串)
- (2) json.loads()函数是将json格式数据转换为字典(可以这么理解,json.loads()函数是将字符串转化为字典)
- 2. json.dump()和json.load()主要用来读写json文件函数(可以理解为操作文件)
- (2)当我们要读取json文件的时候使用到json.load将json文件转换成python的list或dict
- 二、使用正则抓取数据案例
一、json相关方法及用法
1. json的概念
-
定义:JSON 的 全称是 JavaScript Object Notation,即 JavaScript 对象符号,它是一种轻量级、跨平台、跨语言的数据交换格式。
-
设计意图:把所有事情都用设计的字符串来表示,这样既方便在互联网上传递信息,也方便人进行阅读。
-
发展:最早的时候,JSON 是 JavaScript 语言的数据交换格式,后来慢慢发展成一种语言无关的数据交换格式,这一点非常类似于 XML。
-
使用范围:JSON 主要在类似于C 的编程语言中广泛使用,这些语言包括 C、C++、C#、Java、JavaScript、Perl、Python 等。JSON 提供了多种语言之间完成数据交换的能力,因此,JSON 也是一种非常理想的数据交换格式。
-
JSON 主要有如下两种数据结构(语法):
(1)由 key-value 对组成的数据结构(对象)
这种数据结构在不同的语言中有不同的实现。例如,在 JavaScript 中是一个对象;在 Python 中是一种 dict 对象;在 C 语言中是一个 struct;在其他语言中,则可能是 record、dictionary、hash table 等。
(2)有序集合(数组)
这种数据结构在 Python 中对应于列表;在其他语言中,可能对应于 list、vector、数组和序列等。
总结:上面两种数据结构在不同的语言中都有对应的实现,因此这种简便的数据表示方式完全可以实现跨语言。所以,JSON 可以作为程序设计语言中通用的数据交换格式。
可以简洁为以下几点:
- json是一种通用的数据类型
- 一般情况下接口返回的数据类型都是json
- 长得像字典,形式也是key-value
- 其实json是字符串
- 字符串不能用key、value来取值,所以要先转换为字典才可以
2. json的操作
1. json.dumps()和json.loads()是将python中的list或dict转换成json语句(可以这么理解为操作数据)
(1) json.dumps()函数是将一个Python数据类型列表进行json格式的编码(可以这么理解,json.dumps()函数是将字典转化为字符串)
import json
# json.dumps()函数的使用,将字典转化为字符串
dict1 = {"age": "12"}
json_info = json.dumps(dict1)
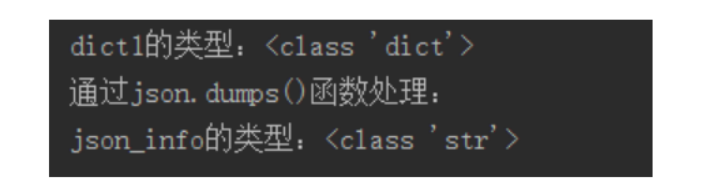
print("dict1的类型:"+str(type(dict1)))
print("通过json.dumps()函数处理:")
print("json_info的类型:"+str(type(json_info)))
运行截图:
(2) json.loads()函数是将json格式数据转换为字典(可以这么理解,json.loads()函数是将字符串转化为字典)
import json
# json.loads函数的使用,将字符串转化为字典
json_info = '{"age": "12"}'
dict1 = json.loads(json_info)
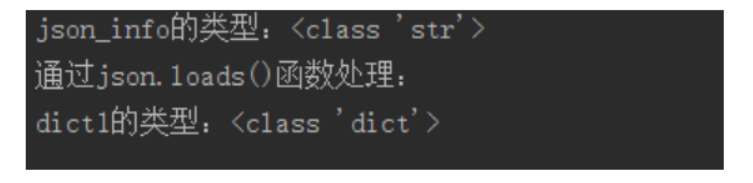
print("json_info的类型:"+str(type(json_info)))
print("通过json.dumps()函数处理:")
print("dict1的类型:"+str(type(dict1)))
运行截图:
2. json.dump()和json.load()主要用来读写json文件函数(可以理解为操作文件)
(1)一般将获取到的内容放在json文件中
这就用到了json.dump将python的list或dict数据放入json文件中
格式:
json.dump(python的dict或list,fp'json文件')
例子:
with open('guba.json','w',encoding='utf-8') as fp:
json.dump(info,fp)
运行截图:

(2)当我们要读取json文件的时候使用到json.load将json文件转换成python的list或dict
格式:
json.load(fp'json文件')
例子:
with open('guba.json','r') as fp:
guba_list = json.load(fp)
for one in guba_list:
print(one)
运行截图:

总结:不管是dump还是load,带s的都是和字符串(数据)相关的,不带s的都是和文件相关的。
二、使用正则抓取数据案例
- 总结:用正则筛选数据,有个原则:不断缩小筛选访问
1. 案例:猫眼电影
- 需求:
- 电影名称
- 主演
- 上映时间
- 评分
- 代码:
import requests,re,json
class Cat_moive():
def __init__(self,url):
self.url = url
self.movie_list=[]
self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36'}
## 调用自己的parse方法
self.parse()
def parse(self):
## 爬取页面的代码
# 1. 发送请求,获取响应
# 分页
for i in range(10):
url = self.url+'?offset={}'.format(i*10)
response = requests.get(url,headers = self.headers)
# print(response.text)
"""
1. 电影名称
2. 主演
3. 上映时间
4. 评分
"""
## 用正则筛选数据,有个原则:不断缩小筛选访问
dl_pattern = re.compile(r'<dl class="board-wrapper">(.*?)</dl>',re.S)
dl_content = dl_pattern.search(response.text).group()
# print(dl_content)
dd_pattern = re.compile(r'<dd>(.*?)</dd>', re.S)
dd_list = dd_pattern.findall(dl_content)
# print(dd_list)
for dd in dd_list:
item = {}
## 拿电影名称
movie_pattern = re.compile(r'title="(.*?)" class=', re.S)
movie_name = movie_pattern.search(dd).group(1)
# print(movie_name)
## 拿演员
actor_pattern = re.compile(r'<p class="star">(.*?)</p>', re.S)
actor = actor_pattern.search(dd).group(1).strip()
# print(actor)
## 上映时间
play_time_pattern = re.compile(r'<p class="releasetime">(.*?):(.*?)</p>')
play_time = play_time_pattern.search(dd).group(2).strip()
# print(play_time)
## 评分
grade_pattern = re.compile(r'<i class="integer">(.*?)</i><i class="fraction">(.*?)</i>',re.S)
grade1 = grade_pattern.search(dd).group(1)
grade2 = grade_pattern.search(dd).group(2)
grade = grade1+grade2
# print(grade)
item["movie_name"]=movie_name
item["actor"]=actor
item["play_time"]=play_time
item["grade"]=grade
self.movie_list.append(item)
# print(self.movie_list)
## 将电影信息保存到json文件中
with open ('movie.json','w',encoding='utf-8') as fp:
json.dump(self.movie_list,fp)
if __name__ == '__main__':
base_url = 'https://maoyan.com/board/4'
Cat_moive(base_url)
with open('movie.json', 'r') as fp:
movie_list = json.load(fp)
# print(movie_list)
for item in movie_list:
print(item)
- 运行结果:

2. 案例:股吧
- 需求:
- 阅读数
- 评论数
- 标题
- 作者
- 更新时间
- 详情页的url
- 代码:
import json
import requests,re
# 确定url
base_url = 'http://guba.eastmoney.com/default,99_%s.html'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36'}
for i in range(1,13):
response = requests.get(base_url %i,headers=headers)
# print(response.text)
"""
阅读数
评论数
标题
作者
更新时间
详情页的url
"""
## 获取ul
ul_pattern = re.compile(r'<ul class="newlist" tracker-eventcode="gb_xgbsy_ lbqy_rmlbdj">(.*?)</ul>',re.S)
ul_content = ul_pattern.search(response.text)
if ul_content:
ul_content = ul_content.group()
## 获取所有li
li_pattern = re.compile(r'<li>(.*?)</li>', re.S)
li_list = li_pattern.findall(ul_content)
# print(ul_content)
info = []
for li in li_list:
item = {}
reader_pattern = re.compile(r'<cite>(.*?)</cite>',re.S)
info_list = reader_pattern.findall(li)
# print(info_list)
read_num = ''
comment_num = ''
## 获取阅读数和评论数
if info_list:
read_num = info_list[0].strip()
comment_num = info_list[1].strip()
# print(read_num,comment_num)
## 获取标题
title_pattern = re.compile(r'title="(.*?)" class="note"',re.S)
title = title_pattern.search(li).group(1)
# print(title)
## 获取作者
author_pattern = re.compile(r'target="_blank"><font>(.*?)</font>',re.S)
author = author_pattern.search(li).group(1)
# print(author)
## 获取时间
time_pattern = re.compile(r'<cite class="last">(.*?)</cite>',re.S)
time = time_pattern.search(li).group(1)
# print(time)
## 获取详情页
datail_pattern = re.compile(r'</em> <a href="(.*?)" title=',re.S)
datail_url = datail_pattern.search(li)
if datail_url:
datail_url ='http://guba.eastmoney.com' + datail_url.group(1)
else:
datail_url=''
# print(datail_url)
##加入字典中
item['title'] = title
item['read_num'] = read_num
item['comment_num'] = comment_num
item['author'] = author
item['time'] = time
item['datail_url'] = datail_url
info.append(item)
# 保存成json文件
with open('guba.json','w',encoding='utf-8') as fp:
json.dump(info,fp)
## 查看json文件中的列表
with open('guba.json','r') as fp:
guba_list = json.load(fp)
for one in guba_list:
print(one)
- 运行结果:

3. 将匹配正则函数封装成面向对象
(1)案例:股吧
- 要求:
“”"
阅读数
评论数
标题
作者
更新时间
详情页的url
“”" - 代码:
import json
import requests,re
class Guba:
def __init__(self,url):
self.url = url
## 存放所有信息
self.info = []
self.parse()
def get_content(self,url):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36'}
response = requests.get(url,headers=headers)
if response.status_code == 200:
return response.text
return None
def parse(self):
for i in range(1, 13):
content = self.get_content(self.url %i)
## 获取ul
ul_pattern = re.compile(r'<ul class="newlist" tracker-eventcode="gb_xgbsy_ lbqy_rmlbdj">(.*?)</ul>', re.S)
ul_content = ul_pattern.search(content)
if ul_content:
ul_content = ul_content.group()
## 获取所有li
li_pattern = re.compile(r'<li>(.*?)</li>', re.S)
li_list = li_pattern.findall(ul_content)
# print(ul_content)
for li in li_list:
item = {}
reader_pattern = re.compile(r'<cite>(.*?)</cite>', re.S)
info_list = reader_pattern.findall(li)
# print(info_list)
read_num = ''
comment_num = ''
## 获取阅读数和评论数
if info_list:
read_num = info_list[0].strip()
comment_num = info_list[1].strip()
# print(read_num,comment_num)
## 获取标题
title_pattern = re.compile(r'title="(.*?)" class="note"', re.S)
title = title_pattern.search(li).group(1)
# print(title)
## 获取作者
author_pattern = re.compile(r'target="_blank"><font>(.*?)</font>', re.S)
author = author_pattern.search(li).group(1)
# print(author)
## 获取时间
time_pattern = re.compile(r'<cite class="last">(.*?)</cite>', re.S)
time = time_pattern.search(li).group(1)
# print(time)
## 获取详情页
datail_pattern = re.compile(r'</em> <a href="(.*?)" title=', re.S)
datail_url = datail_pattern.search(li)
if datail_url:
datail_url = 'http://guba.eastmoney.com' + datail_url.group(1)
else:
datail_url = ''
# print(datail_url)
##加入字典中
item['title'] = title
item['read_num'] = read_num
item['comment_num'] = comment_num
item['author'] = author
item['time'] = time
item['datail_url'] = datail_url
self.info.append(item)
if __name__ == '__main__':
# 确定url
base_url = 'http://guba.eastmoney.com/default,99_%s.html'
g = Guba(base_url)
# 保存成json文件
with open('guba1.json','w',encoding='utf-8') as fp:
json.dump(g.info,fp)
## 查看json文件中的列表
with open('guba1.json','r') as fp:
guba_list = json.load(fp)
for one in guba_list:
print(one)
- 运行结果:

(2)案例:药网
- 需求:
1. 总价
2. 描述
3. 评论数量
4. 详情页链接 - 代码:
import json
import requests,re
class Yaowang:
def __init__(self,url):
self.url = url
self.info = []
self.parse()
def get_content(self,url):
headers={'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36'}
response = requests.get(url,headers=headers)
if response.status_code == 200:
return response.text
return None
def parse(self):
for i in range(1,51):
content = self.get_content(self.url+'/categories/953710-j%s.html' %i)
"""
总价,
描述,
评论数量,
详情页链接
"""
ul_pattern = re.compile(r'<ul id="itemSearchList" class="itemSearchList">(.*?)</ul>',re.S)
ul_content = ul_pattern.search(content).group(1)
li_list_pattern = re.compile(r'<li id="producteg_(.*?)</li>',re.S)
li_list = li_list_pattern.findall(ul_content)
if li_list:
for li in li_list:
item = {}
total_pattern = re.compile(r'<span>(.*?)</span>',re.S)
total = total_pattern.search(li).group(1).strip()
# print(total)
description_pattern = re.compile(r' <span class=" list_lable_self"></span>(.*?)</a>',re.S)
description = description_pattern.search(li)
if description:
description = description.group(1).strip()
else:
description = ''
# print(description)
comment_pattern = re.compile(r'评论 <em>(.*?)</em>条',re.S)
comment = comment_pattern.search(li)
# print(comment)
if comment:
comment = comment.group(1)
else:
comment = ''
detail_pattern = re.compile(r' " href="//www.111.com.cn(.*?)"',re.S)
detail_url = detail_pattern.search(li).group(1)
detail_url = self.url + detail_url
# print(detail_url)
item['total']=total
item['description']=description
item['comment']=comment
item['detail_url']=detail_url
self.info.append(item)
if __name__ == '__main__':
base_url = 'https://www.111.com.cn'
yw = Yaowang(base_url)
with open('yw.json','w',encoding='utf-8') as fp:
json.dump(yw.info,fp)
with open('yw.json','r') as fp:
info_list = json.load(fp)
for one in info_list:
print(one)
- 运行结果:

