文章目录
- 一、Numpy
- 二、使用numpy的属性创建数组
- 1. numpy.array()创建数组
- 2. 使用numpy.arange()
- 3. 使用numpy.linspace()
- 4. 使用numpy.logspace() -----> 等比数列
- 5. 使用numpy.zeros() 全0数组
- 6. 使用numpy.ones() ---- 全1数组
- 7. 使用numpy.empty() ---- 创建一个内容随机,并且依赖于内存状态的数组
- 8. 使用numpy.eye()
- 9. 使用 numpy.diag()
- 10. 练习(shape方法和reshape()方法更改数组维度)
- 三、numpy.random的相关方法
- 四、数据类型
- 五、数组元素的访问
- 六、数组的操作(变换,展平,组合)
- 七、order : {'C', 'F'}问题
- 八、数组的arr5[0]的理解
一、Numpy
1. numpy的介绍
NumPy是使用Python进行科学计算的基本软件包。它包含以下内容:
NumPy已获得BSD许可证的许可,从而可以无限制地进行重用。
- 介绍:
一个用python实现的科学计算,
包括:- (1)强大的N维数组对象
- (2)复杂的(广播)功能
- (3)集成C / C ++和Fortran代码的工具
- (4)有用的线性代数,傅立叶变换和随机数功能
- (5)除了其明显的科学用途外,NumPy还可以用作通用数据的高效多维容器。可以定义任意数据类型。这使NumPy可以无缝,快速地与各种数据库集成。
NumPy(Numeric Python)提供了许多高级的数值编程工具,如:矩阵数据类型、矢量处理,以及精密的运算库。专为进行严格的数字处理而产生。多为很多大型金融公司使用,以及核心的科学计算组织如:Lawrence Livermore,NASA用其处理一些本来使用C++,Fortran或Matlab等所做的任务。
-
作用:NumPy系统是Python的一种开源的数值计算扩展。这种工具可用来存储和处理大型矩阵,比Python自身的嵌套列表(nested list structure)结构要高效的多(该结构也可以用来表示矩阵(matrix))。
-
作用对象:numpy的主要对象是同种元素的多维数组
numpy内置了并行运算功能,当系统有多个核心时,做某种计算时,numpy会自动做并行计算。
Numpy底层使用C语言编写,数组中直接存储对象,而不是存储对象指针,所以其运算效率远高于纯Python代码。
2. 数组和列表的区别
-
相同:结构:[元素1,元素2,元素。。。。]
-
不同的是叫法:
数组:C语言、Java
列表:只有python叫列表
python下的列表可以放任何东西:[‘123’,456,True,xiaoming] (存储任何类型的都可以,要多次判断,所以效率慢)
C语言下的数组存储相同类型的数据
int a[10] ------>只能存数值,所以效率快
a[0] = 1
a[1]=‘123’ #报错
3. numpy使用python的原因
python的特点:python这门语言代码执行效率低,编程效率高
但Numpy底层是C语言实现的,执行效率高,解决了这一问题
数组的叫法就是因为底层是C语言写的
4. Numpy的使用(数组中的用法)
① 第一步:导包
import numpy
② 创建一个数组
一维数组:
arr1 = numpy.array([1,2,3])
③ 数组的常用属性
- 轴 (axes) ---- 维度 — 几行几列
- 秩(rank)----- 轴的个数
(1)维度:shape
- 代码:
# 一维数组 arr1 = numpy.array([1,2,3]) # ## 输出轴 --- 维度shape print(arr1.shape) ## 数组的形状 (3,)----》元组,一维,行和列的写法 # # 二维数组 arr2 = numpy.array([[1,2,3],[4,5,6],[7,8,9]]) print(arr2.shape) # (3, 3)
注意:一维数组打印的是列数(每行的元素个数) 我们可以理解为返回的是元素的个数
- 案例演示:

注意:二维数组,元祖中第一个参数是行数,第二个是列数(每行的元素个数)

(2)秩:ndim
- 代码:
# ## 输出秩 --- ndim arr1 = numpy.array([1,2,3]) arr2 = numpy.array([[1,2,3],[4,5,6],[7,8,9]]) print("arr1的秩:",arr1.ndim) # arr1的秩: 1 --- 元组中数的个数,如(3,) print("arr2的秩:",arr2.ndim) # arr2的秩: 2 ## 秩的另一种求法 print(len(arr2.shape))
tip:秩可以用本身的ndim方法来获取,也可以用len(arr.shape)来获取
- 案例演示:

(3)数组元素总个数:size
size方法所存在的意义就是获取数组中元素的总个数
-
代码:
arr3 = numpy.array([[1,2,3],[4,5,6],[7,8,9]]) print(arr3.shape) print(arr3.ndim) print(len(arr3.shape)) # 数组元素总个数:size print("数组元素的总个数:",arr3.size) #数组元素的总个数: 9 -
案例演示:

(4)数组的元素类型:dtype
- 代码:
arr3 = numpy.array([[1,2,3],[4,5,6],[7,8,9]]) # 数组元素的类型:dtype int32 表示整型32位 print("数组元素的类型",arr3.dtype) # 数组元素的类型 int32 - 案例演示:


跟存入的数据有关,数组没有指定的时候默认就用自己的类型
(5)每个元素的字节大小:itemsize
-
代码:
# # 每个元素的字节大小:itemsize # ## 字节(byte)-----位(bit) # # 8bit = 1byte arr3 = numpy.array([[1,2,3],[4,5,6],[7,8,9]]) print(arr3.dtype) # int32 print("arr3每个元素的字节大小",arr3.itemsize) # arr3每个元素的字节大小 4 -
案例演示:

(6)缓冲区:data
-
代码
arr3 = numpy.array([[1,2,3],[4,5,6],[7,8,9]]) print(arr3.data) # <memory at 0x0000000003149C18> -
案例演示:

注意:缓冲区时刻在变化
二、使用numpy的属性创建数组
1. numpy.array()创建数组
使用array()函数
```python
def array(p_object, dtype=None, copy=True, order='K', subok=False, ndmin=0)
# p_object:接收一个array,eg:[1,2,3] ## numpy.array([1,2,3])
# dtype:接收一个data-type类型,表示数组所需要的数据类型;默认为空,如果没有给定,则根据传入元素,指定所需要的一个最小的数据类型;int32,int64
```
-
代码:
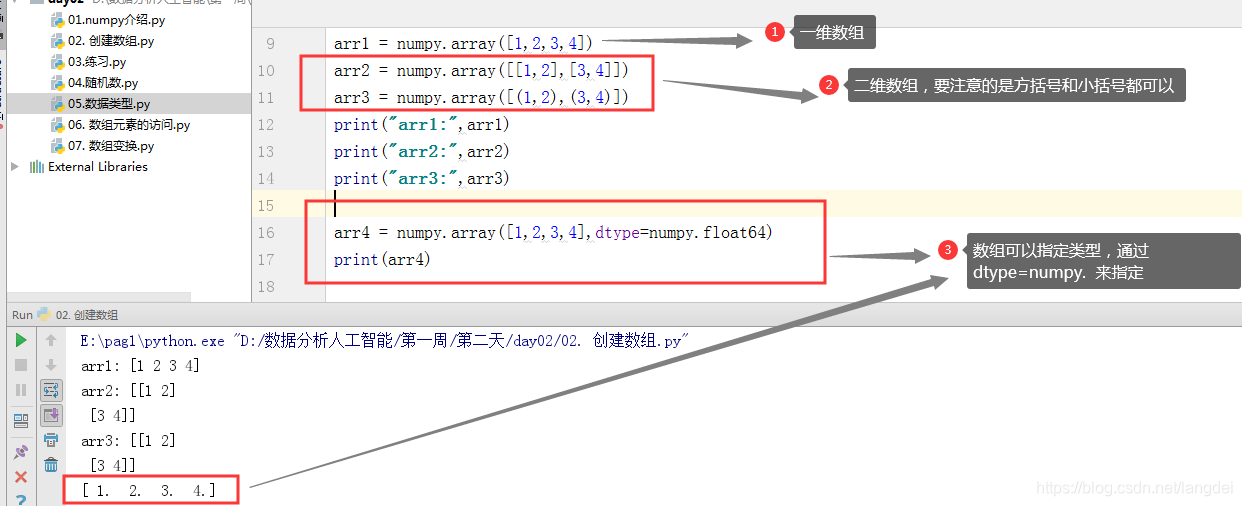
arr1 = numpy.array([1,2,3,4]) arr2 = numpy.array([[1,2],[3,4]]) arr3 = numpy.array([(1,2),(3,4)]) print("arr1:",arr1) print("arr2:",arr2) print("arr3:",arr3) arr4 = numpy.array([1,2,3,4],dtype=numpy.float64) print(arr4) -
案例演示:
2. 使用numpy.arange()
-
代码:
# def arange(start=None, stop=None, step=None, dtype=None) arr5 = numpy.arange(0,1,0.1) ## 区间前闭后开 print(arr5) # [ 0. 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9] -
案例演示:

注意:该区间是前闭后开的
3. 使用numpy.linspace()
-
代码:
# def linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None) arr6 = numpy.linspace(0.1,1,10) # 闭合区间:前后都是闭合的,第一个参数:开始;第二个参数:结束,第三个参数:生成多少个数 print(arr6) # [ 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1. ] -
案例演示:

注意:该区间前后都是闭合的
上面的两种都是等差数列
4. 使用numpy.logspace() -----> 等比数列
-
代码:
## 4. 使用logspace() -----> 等比数列 # logspace(start, stop, num=50, endpoint=True, base=10.0, dtype=None) arr7 = numpy.logspace(1,3,3) # [ 10. 100. 1000.] # 第三个参数为生成几个数 print(arr7) arr8 = numpy.logspace(1,10,10,base=2) # 第一个参数:2的一次方,第二个参数:2的10次方,第三个参数:生成几个数 print(arr8) # [ 2. 4. 8. 16. 32. 64. 128. 256. 512. 1024.] -
案例演示:

5. 使用numpy.zeros() 全0数组
-
代码:
## 5. 使用zeros() 全0数组 # def zeros(shape, dtype=None, order='C') arr9 = numpy.zeros((3,3)) print(arr9) -
案例演示:

注意:shape代表的是数组的维度(通俗来说就是几行几列)
6. 使用numpy.ones() ---- 全1数组
-
代码:
print(numpy.ones((2,3))) -
案例演示:

7. 使用numpy.empty() ---- 创建一个内容随机,并且依赖于内存状态的数组
-
代码:
## 7. 使用empty() ---- 创建一个内容随机,并且依赖于内存状态的数组 # def empty(shape, dtype=None, order='C') print("empty:",numpy.empty((2,3))) -
案例演示:


注意:该方法创建数组要注意内存中是否存留状态,如上面的例子一样,会有不同结果
8. 使用numpy.eye()
关注第一个第三个参数就行了
第一个参数:输出方阵(行数=列数)的规模,即行数或列数,在默认第二个参数为None的情况下
第三个参数:默认情况下输出的是对角线全“1”,其余全“0”的方阵,如果k为正整数,则在右上方第k条对角线全“1”其余全“0”,k为负整数则在左下方第k条对角线全“1”其余全“0”。
-
代码:
## 8. 使用eye() # def eye(N, M=None, k=0, dtype=float) arr10 = numpy.eye(3) print(arr10) ## n阶矩阵 arr10 = numpy.eye(3,k=2) print(arr10) ## n阶矩阵 arr10 = numpy.eye(3,k=-2) print(arr10) ## n阶矩阵 -
案例演示:

9. 使用 numpy.diag()
以一维数组的形式返回方阵的对角线(或非对角线)元素,或将一维数组转换成方阵(非对角线元素为0).两种功能角色转变取决于输入的v。
v : array_like.
如果v是2D数组,返回k位置的对角线。
如果v是1D数组,返回一个v作为k位置对角线的2维数组。
k : int, optional
对角线的位置,大于零位于对角线上面,小于零则在下面。


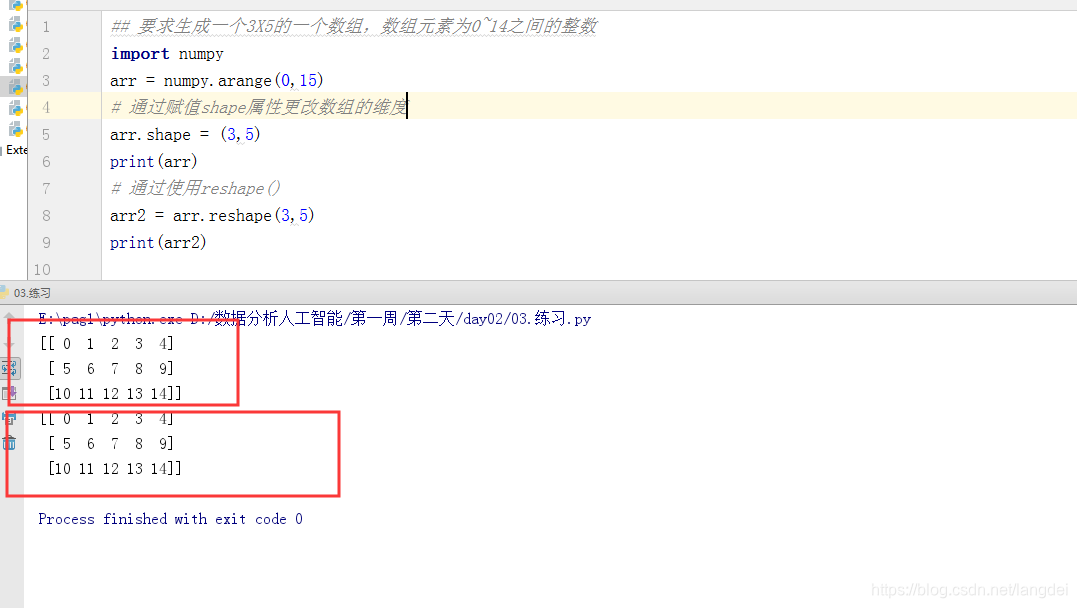
10. 练习(shape方法和reshape()方法更改数组维度)
## 要求生成一个3X5的一个数组,数组元素为0~14之间的整数
import numpy
arr = numpy.arange(0,15)
# 通过赋值shape属性更改数组的维度
arr.shape = (3,5)
print(arr)
# 通过使用reshape()
arr2 = arr.reshape(3,5)
print(arr2)
三、numpy.random的相关方法
import numpy
# 生成随机数组
1. random.random(n) ----- 值域:[0,1) , n表示元素的个数
arr1 = numpy.random.random(3) ## 参数是多少个随机数
print(arr1)
arr2 = numpy.random.random(15).reshape(3,5) ## 生成3行5列的数组
print(arr2)
2. random.rand(m,n) ## 生成一个mXnXp ..... 多维数组;值域:[0,1)
arr3 = numpy.random.rand(2,3)
print(arr3)
3. random.randn() ## 生成正态随机数
arr4 = numpy.random.randn(3) # 参数,生成多少个符合正态分布的数
print(arr4) # [-0.04022466 0.89657514 0.23527142]
常识 ----大数定理
# 画图
import matplotlib.pyplot as plt
plt.hist(arr4)
plt.show()
4. random.randint() # 闭合区间[a,b],eg: a<=value<=b
def randint(low, high=None, size=None, dtype='l') # size 要么整型,要么整型的元组,输出几行几列
arr5 = numpy.random.randint(1,10,size=(2,5))
print(arr5)
5. random模块常用的随机生成函数
# normal:产生正态(高斯)分布的随机数
# beta:产生beta分布的随机数
# chisquare:产生卡方分布的随机数
# gamma:产生gamma分布的随机数

上面的情况是数据太少,所以没显示正态分布
下面是增加后

四、数据类型
注意:所有非零数据转换成bool类型都是True,零转换的都是False
################### 一、基本数据类型####################
## 1. bool
## 2. inti 后面的i 为多少位 如 32,64
################## 二、数据类型的转换###################
print(np.float64(42))
# np.int32(42.0)
########## 所有非零数据转换成bool类型都是True,零转换的都是False
print(np.bool(42))
print(np.bool(0))

要注意的是自定义类型
#################### 三、定义数据类型####################
##eg:创建一个存储餐饮企业库存信息的数据类型
# 规定:
# (1)用一个长度为40的字符串来记录商品的名称
# (2)用一个64位的整数来记录商品的库存
# (3)用一个64位单精度浮点记录商品的价格
## 第一个是字段名,第二个是类型,第三个是多少位
df = np.dtype([('name',np.str_,40),('numitems',np.int64),('price',np.float64)]) ## 是一个方法,可以定义数据类型
print('df数据类型:',df) # df数据类型: [('name', '<U40'), ('numitems', '<i8'), ('price', '<f8')] # <U 小于U,U是unique
table = np.array([('beef',40000,4.14),('chicken',20,1.72)],dtype=df)
print(table)
print(table[0],type(table[0])) # ('beef', 40000, 4.14) <class 'numpy.void'> numpy.void 表明是自己定义的,它不能识别:无效的
print(table[0][1],type(table[0][1])) ## 典型特点:速度快

注意:自定义的数组要在后面加自己写好的dtype
五、数组元素的访问
1. 通过索引来访问数组元素
- 一维数组


2. 数组的切片和步长
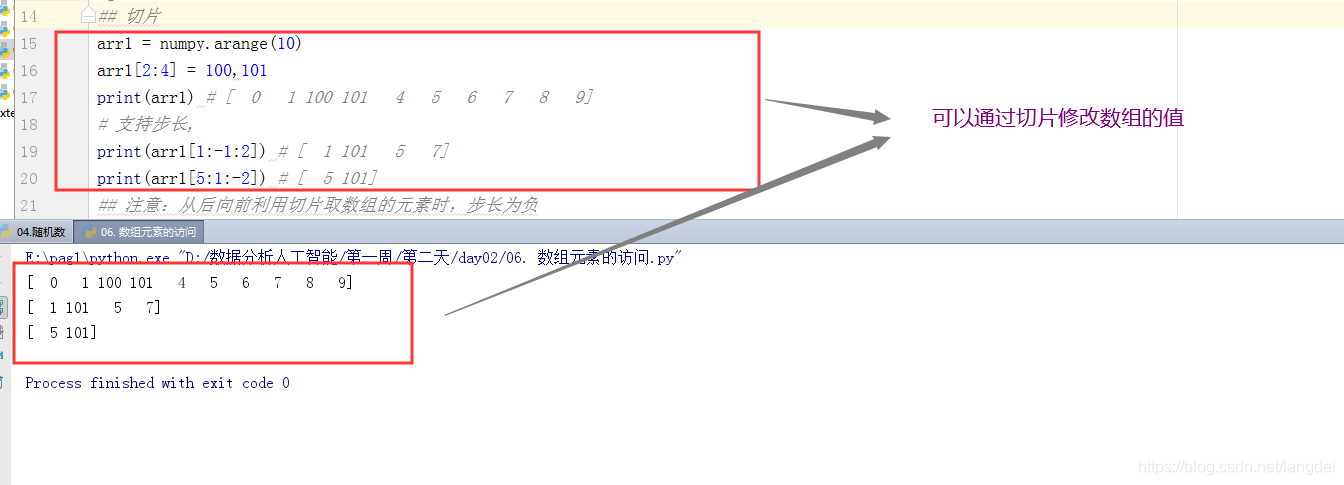
注意:从后向前利用切片取数组的元素时,步长为负
3. 通过格式:数组名[行索引,列索引]访问元素

4. 通过格式:数组名[(行下标),(列下标)]访问元素

注意:行下标可指定,但列下标一定要和行下标一一对应;或者一个行下标对应多个列下标;或者多个行下标,对应:,获取该行所有元素
特例:定义好了结构,直接可以通过结构获取
df = numpy.dtype([('name',numpy.str_,40),('numitems',numpy.int64),('price',numpy.float64)])
table = numpy.array([('beef',40000,4.14),('chicken',20,1.72)],dtype=df)
print(table)
print(table['name'])

5. 遮罩mask
三、遮罩mask
arr3 = numpy.array([[1,2,3,4],[5,6,7,8],[9,10,11,12]])
mask = numpy.array([1,0,1],dtype=numpy.bool) ## bool值代表是否显示
print(mask) # [ True False True] True显示,False不显示
print(arr3[mask,2]) # [ 3 11]
print(arr3[(1,0,1),2]) # [7 3 7]

注意:遮罩其含义就是通过使用bool的True和False来展示我们想要显示的数据
六、数组的操作(变换,展平,组合)
1. shape和reshape()-------数组变化
在上面提到的两种变换数组形态的方法
## 要求生成一个3X5的一个数组,数组元素为0~14之间的整数
import numpy
arr = numpy.arange(0,15)
# 通过赋值shape属性更改数组的维度
arr.shape = (3,5)
print(arr)
# 通过使用reshape()
arr2 = arr.reshape(3,5)
print(arr2)
2. 展平数组
(1)ravel()
- 代码:
# (1) ravel()
# 说明:是reshape函数的逆操作
# 注意:并不修改原数组,而是创建了一个新数组
arr1 = numpy.arange(10000)
arr2 = arr1.reshape((100,100))
print(arr1)
print(arr2)
arr3 = arr2.ravel()
print("arr3:",arr3) # [ 0 1 2 ..., 9997 9998 9999]
- 案例演示:

注意:ravel()是reshape()函数的逆操作,并不修改原数组,而是创建了一个新数组
小知识:将中间省略的部分展开
格式:numpy.set_printoptions(threshold=numpy.NaN)
借用上面的代码来实现:
arr1 = numpy.arange(10000)
arr2 = arr1.reshape((100,100))
# print(arr1)
# print(arr2)
arr3 = arr2.ravel()
print("arr3:",arr3) # [ 0 1 2 ..., 9997 9998 9999]
# # tip1: 如果输出的数组数据量太大,在输出时,numpy自动省略中间部分,而只打印两边元素
# # 如果不需要省略,在打印之前设置如下信息:
numpy.set_printoptions(threshold=numpy.NaN)
print(arr2)
- 案例演示:

(2) flatten()
- 代码:
arr4 = numpy.arange(10).reshape((2,5))
arr5 = arr4.flatten()
print("arr5:",arr5)
- 案例演示:

从上面看来,flatten也是展平数组的效果
(3)ravel()和flatten()的区别
- 对一个数组展平的效果来说无区别

共同点:都是将多维数组降为一维
区别:
- 返回的是拷贝(copy):强调的是数据 ------- 使用flatten返回的是一份拷贝
- 返回的是视图(view):侧重的是展现,而不是数据本身 ------- 使用ravel返回的是一份视图
案例演示:
-
代码:
a1 = numpy.array([[1,2],[3,4]]) f_a = a1.flatten() r_a = a1.ravel() print("a1改动前:",a1) print("f_a",f_a) # f_a [1 2 3 4] print("r_a",r_a) # r_a [1 2 3 4] f_a[2] = 100 print("flatten2:",f_a) # flatten2: [ 1 2 100 4] print("f_a改动后",a1) ## flatten元素变化不影响原数组 # f_a改动后 [[1 2] # [3 4]] r_a[2] = 101 print("r_a改动后",r_a) # r_a改动后 [ 1 2 101 4] print("r_a改动后的a1",a1) # 如果是ravel的数组元素发生更改,原数据同时也会发生改变 -
结果:

总结:flatten()在展平后修改数据,原数组不会改变,其相当于copy了数组;ravel()展平数组后修改数据,原数组会随之改变,其相当于view,数据只是拿数组的数据来展示。
3. 组合/切割数组
① 组合数组
(1)hstask() 和 vstack()
- 代码:
### (1)hstask() 和 vstack()
arr1 = numpy.arange(1,6,2)
arr2 = numpy.arange(7,12,2)
print(arr1,arr2) # [1 3 5] [ 7 9 11]
arr3 = numpy.hstack((arr1,arr2)) ## 横向拼接(按行拼接)
print(arr3) # [ 1 3 5 7 9 11]
arr4 = numpy.vstack((arr1,arr2))
print(arr4) ## 纵向拼接 相当于将两个一维数组拼接成一个新的二维数组
- 案例演示:

注意:横向拼接(按行拼接),两个一维数组的话拼接后还是一维数组;纵向拼接 相当于将两个一维数组拼接成一个新的二维数组
(2)在组合数组时注意项
-
如果两个数组元素个数不相等,横向能够拼接,但纵向将会报错
arr1 = numpy.array([1,2]) arr2 = numpy.array([3,4,5]) arr3 = numpy.hstack((arr1,arr2)) print(arr3) # [1 2 3 4 5] arr4 = numpy.vstack((arr2,arr1)) print(arr4) ## 报错
-
在stack函数(hstack和vstack)中,参数列表和元组都可以
arr1 = numpy.array([1,2]) arr2 = numpy.array([3,4,5]) arr4 = numpy.hstack([arr1,arr2]) print(arr4) # [1 2 3 4 5] arr5 = numpy.hstack([(6,6,6),(8,8,8,8)]) print(arr5)
② 组合数组:concatenate() 接收两个参数:函数和轴
(1)横向
-
方法一:
arr1 = numpy.array([[1,1],[2,2]]) arr2 = numpy.array([[3,3],[4,4]]) print(arr1) # # [[1 1] # # [2 2]] print(arr2) # # [[3 3] # # [4 4]] # ## 横向 ## 方法1: print(numpy.hstack([arr1,arr2]))
-
方法二:
print(numpy.concatenate((arr1,arr2),axis=1))
结论:concatenate方法传参axis=1和hstack方法结果一样
(2)纵向
-
方法一:
print(numpy.vstack([arr1,arr2]))
-
方法二:
print(numpy.concatenate((arr1,arr2),axis=0))
结论:concatenate方法传参axis=0和vstack方法结果一样
七、order : {‘C’, ‘F’}问题
- 首先要了解的是:order参数的C和F是numpy中数组元素存储区域的两种排列格式,即C语言格式和Fortran语言格式。
- 主要区别: 所谓的Row major order和Column-major order 的区别,主要看你拿这数组作什么运算,如果是要依次访问每列的元素,Fortran Order(即Column-major order)下每列在内存中是连续的,这种结构相对更加Cache-friendly。这并不是编程语言自身的特性,在C语言中完全可以使用Column-major order,只不过访问起来计算index不太习惯而已。Fortran大概是因为主要用于科学计算,Column-major order对于一些矩阵运算有性能优势。
简单点来说就是order='C’支持索引;order='F’是顺序访问每列元素
案例:
-
order='C’创建一个3×3的2维数组
import numpy as np a = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]], dtype=np.float32,order='C')数组a在内存中的数据存储区域中存储方式(默认order=“C”,其中一个格子是4bytes):
|1|2|3|4|5|6|7|8|9|在C语言中当第一维数组也就是第0轴的下标增加1时,元素在内存中的地址增加3个元素的字节数,在此例中也就是12bytes,从1的地址增加12bytes到4的地址。此时
a.strides = (12, 4) -
若以F order创建数组:
b = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]], dtype=np.float32, order="F")数组b在内存中的数据存储区域中的存储方式:
|1|4|7|2|5|8|3|6|9|在Fortran语言中,第一维也就是第0轴下标增加1时,元素的地址增加一个元素字节数,在此例子中也就是4 bytes,从1的地址增加4bytes到4的地址。
b.strides = (4, 12)
简洁代码:
# F参数
# 'C'meanstoflatten in row - major(C - style)order. “C”意为按C大调(C调)顺序变平。
# 'F'meanstoflatten in column - major(Fortran -style)order “F”的意思是按列大调(Fortran风格)顺序变平
a2 = numpy.array([[1,2,3],[4,5,6]])
f_a = a2.flatten(order = 'F') # 按列展平
print("F_A",f_a) # F_A [1 4 2 5 3 6]
c_a = a2.flatten(order = 'C') # 按列展平
print("C_A",c_a) # C_A [1 2 3 4 5 6]

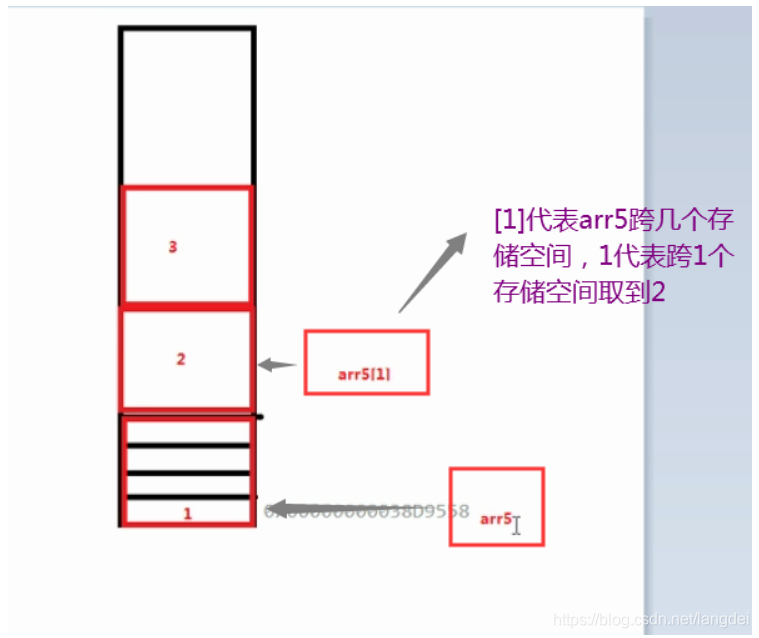
八、数组的arr5[0]的理解
地址:0x0000000003149C18; 别名:arr5
arr5[2]代表跨几个存储空间 ,一开始arr5代表最底层的存储空间,不用跨即可取到所以为[0]