存储层级
当代计算机一般有如下存储层级:
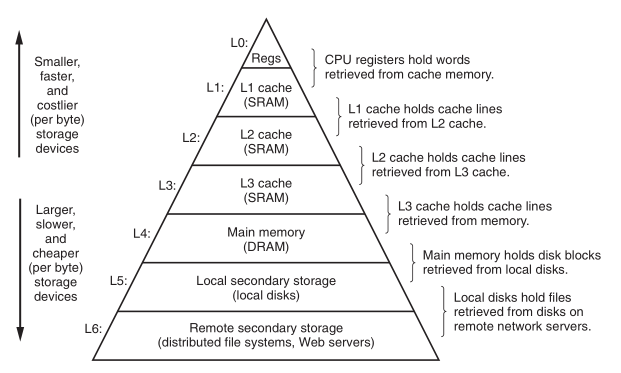
缓存主要是为了兼顾性能与价钱.一般来说,速度越快,价格越贵,因此使用小容量但速度更快的存储器作为速度低一级的存储器的缓存,可以提升性能同时不必花费太多的成本.存储层级中的每一级都可以作为下一级的缓存
缓存原理
考虑一个只有CPU、L1 cache、Main memory和Disk磁盘组成的系统, 当CPU想要访问内存时, 首先从L1 cache中查找,看是否有需要的数据,如果有则直接取回,就不用访问内存了,这称为一次缓存命中(cache hit);如果缓存中没有数据,那么再去内存中访问,这称为缓存缺失(cache miss). 那么cpu如何知道缓存中是否有需要的数据呢?
我们知道CPU需要访问内存时,指令中得到的是内存的虚拟地址,CPU首先查页表把虚拟地址转化为物理地址, 然后再去内存中相应的地址处把数据读回来.因此查找缓存有两种方式:
- 使用虚拟地址查找缓存
- 使用物理地址查找级存
为简化模型,我们假设CPU拿到的是内存的物理地址,并且地址位宽为4bit,这样可以访问16字节的空间.
假设L1 cache有4行, 每行可以存储2个字节, 如下图:
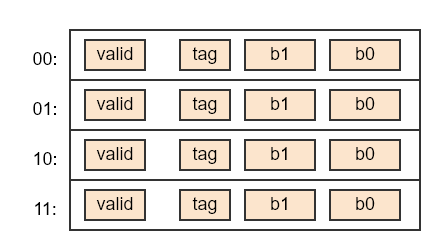
- offset: 因为每行缓存可以存2个字节,因此需要1个bit来区分,称为offset区
- index: 缓存有4行,需要2bit来索引,称为index
- tag: 由于缓存只有4行,每行2个字节,最多存储8个字节, 但我们的位宽是4bit, 最大可访问16字节的内存, 这样必然存在不同的地址在缓存中可能占用同一行的情况,因此需要能区分这种情况,可以用剩下的1bit来区分, 称为tag
- valid: 在系统刚开始运行时,缓存是空的, 里面的数据无效, 因此需要一个valid位来区分这种情况
我们4位的地址可以作如下划分:最低位用作offset, 中间的2位用来作索引,最高位用作tag.
tag:index:offset
0 00 0
模拟访问
- 初始化状态:
set valid tag b1 b0
0 0
1 0
2 0
3 0 - 访问0000b, valid为0, cache miss, 一次性读m[0]m[1]并存入cache中
set valid tag b1 b0
0 1 0 m[1] m[0]
1 0
2 0
3 0 - 访问0100b, valid为0, cache miss, 一次性读m[5]m[4]并存入cache中
set valid tag b1 b0
0 1 0 m[1] m[0]
1 0
2 1 0 m[5] m[4]
3 0 - 访问1000b, valid为1, 但 tag=0, 但1000b的最高位为1,不相等, 因此cache miss, 一次性读入m[9]m[8]替行第一行
set valid tag b1 b0
0 1 1 m[9] m[8]
1 0
2 1 0 m[5] m[4]
3 0
- 访问0101b, valid为1, 且tag相等, cache hit. 因为offset为1, 因此取出m[5]返回.
缓存的组织方式
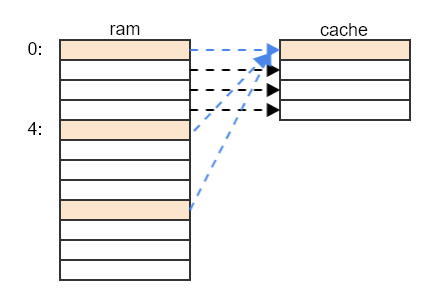
直接映射(Direct-Mapped Caches)
上节的例子便是直接映射的方式, 其特点是内存中的每一行都映射到缓存中固定的行, 如图:
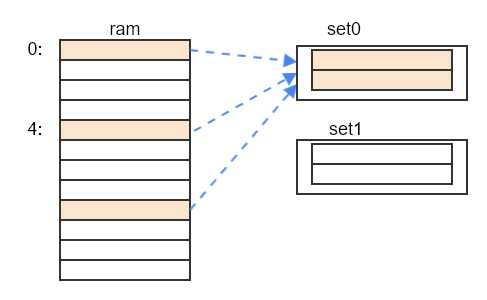
组相联(Set Associative Caches)
直接映射由于只映射到缓存中固定的一行, 因此如果程序访问的地址刚好映射到相同的一行, 缓存频繁发生cache miss, 会极大影响性能, 如果将缓存分为不同的set, 每个set不只一行, 映射方式由映射到固定的行改为映射到不同的set, 由索引找到set后, 再顺序对比里面的每一行来查找数据. 如图:
全相联(Fully Associative Caches)
全相联的意思是, 缓存只有一个set, 内存行可以映射到set中任意的一行, 而不是固定的行
缓存替换策略
使用直接映射方式时, 由于只映射到固定的一行, 因此当发生cache miss, 直接替换新数据到缓存中即可.
但对于映射的行数不只一行时, 当缓存满后且发生cache miss时,新数据应该放在哪个缓存行里呢?
随机法
随机找一个位置替换
先进先出法
替换时间久的那位
LRU
替换最近最少使用的那位