Hadoop-MapReduce的shuffle过程及其他
本篇文章将介绍shuffle的过程以及MapReduce中的其他一些组件。
一、Shuffle
Shuffle其实是一个过程,并不是MapperReducer的一个组件,这个过程是从map输出数据,到reduce接收处理数据之前,横跨Mapper和Reducer两端的,如下图:
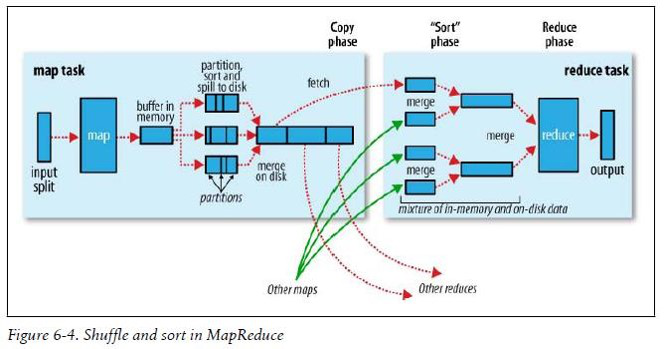
shuffle分为Mapper阶段和Reducer阶段,下面就两个阶段做具体分析。
1.Mapper阶段
每个MapperTask有一个环形内存缓冲区,用于存储map任务的输出。默认大小100MB(io.sort.mb属性),一旦达到阀值默认0.8(io.sort.spill.percent),就会启动一个后台线程把环形缓冲区中的内容写到(spill)磁盘的指定目录(mapred.local.dir)下的新建的一个溢出写文件。
这里有一个map()方法(简称m)写入的速度和spill溢出(简称s)的速度,m的数据在内存中移动,s是数据由内存到磁盘,虽然s是磁盘的连续写,但是也比不上m的内存速度,产生的现象是s在前面跑,m在后面追,m的速度>s的速度,那么m肯定在一个时间节点上会追上s,那么当m追上s的时候,m写入环形缓冲区的线程就会被阻塞暂停,直到s将环形缓冲区中的数据全部写入到磁盘中,m的写入线程才会被启动。所以环形缓冲区大小和阀值的大小是可以根据业务进行调优的点。
写磁盘前,要partition、sort、Combiner。如果有后续的数据,将会继续写入环形缓冲区中,最终写入下一个溢出文件中。
等最后记录写完,合并全部溢出写文件为一个分区且排序的文件。
如果在最终合并时,被合并的文件大于等于3个,则合并完会再执行一次Combiner,否则不会。
整体Mapper阶段的流程如下:
input->map->buffer->split(partition-sort-combiner)->merge(partition-sort-combiner(file>=3))->数据落地。
2.Reducer阶段
Reducer主动找Mapper获取自己负责的分区的数据,并不需要所有的Mapper都执行完成后再获取,哪个Mapper执行完,立即就去复制。
复制后,来自多个Mapper的数据要进行merge合并操作。合并后进行分组、排序,形成k3v3,进入reduce处理,处理后产生的结果输出到目的地。
整体Reducer阶段流程如下:
fetch->merge(combiner)->grouping->sort->reduce->output。
2、Mapper数量
Mapper的数量在默认情况下不可直接控制干预,Mapper的数量由输入的大小和个数决定。在默认情况下,最终input占据了多少block,就应该启动多少个Mapper。
此种情况下,如果有大量的小文件需要处理,则会造成Hadoop集群崩溃。大量的小文件,每个小文件都独占一个Mapper处理线程,这样启动线程和关闭线程消耗的资源会很庞大,文件数量到达一个量级会直接导致集群崩溃。
鉴于以上情况,可以通过配置mapred.min.split.size来控制split的size的最小值。当每个split的大小达不到设置的最小值,Hadoop会将这些达不到最小值的split拼接到一起,使用一个Mapper来处理这些文件,当大小超过最小值,才启动一个新Mapper进行处理。这样就可以避免Mapper线程过多导致集群崩溃的结果。
案例
1.求最大/小值
求一组数据的最大值或者最小值。
数据样例:
123
235345
234
654768
234
4545
3241>MaxMapper
public class MaxMapper extends Mapper<LongWritable, Text, IntWritable, NullWritable> {
private int max = Integer.MIN_VALUE;
@Override
protected void map(LongWritable key, Text value,
Mapper<LongWritable, Text, IntWritable, NullWritable>.Context context)
throws IOException, InterruptedException {
int num = Integer.parseInt(value.toString());
max = max < num ? num : max;
}
@Override
protected void cleanup(Mapper<LongWritable, Text, IntWritable, NullWritable>.Context context)
throws IOException, InterruptedException {
context.write(new IntWritable(max), NullWritable.get());
}
}2>MaxReducer
public class MaxReducer extends Reducer<IntWritable, NullWritable, IntWritable, NullWritable> {
private int max=Integer.MIN_VALUE;
@Override
protected void reduce(IntWritable k3, Iterable<NullWritable> v3s,
Reducer<IntWritable, NullWritable, IntWritable, NullWritable>.Context context)
throws IOException, InterruptedException {
int num=Integer.parseInt(k3.toString());
max=max>num?max:num;
}
@Override
protected void cleanup(Reducer<IntWritable, NullWritable, IntWritable, NullWritable>.Context context)
throws IOException, InterruptedException {
context.write(new IntWritable(max), NullWritable.get());
}
}3>MaxDriver
public class MaxDriver {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "Max_Job");
job.setJarByClass(cn.tedu.max.MaxDriver.class);
job.setMapperClass(cn.tedu.max.MaxMapper.class);
job.setReducerClass(cn.tedu.max.MaxReducer.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(NullWritable.class);
FileInputFormat.setInputPaths(job, new Path("hdfs://hadoop:9000/maxdata"));
FileOutputFormat.setOutputPath(job, new Path("hdfs://hadoop:9000/maxresult"));
if (!job.waitForCompletion(true))
return;
}
}2.统计考试成绩
按月份产生文件,统计每个人的语数外及总分。
数据样例:
math.txt
1 zhang 85
2 zhang 59
3 zhang 95
1 wang 74
2 wang 67
3 wang 96
1 li 45
2 li 76
3 li 67chinese.txt
1 zhang 89
2 zhang 73
3 zhang 67
1 wang 49
2 wang 83
3 wang 27
1 li 77
2 li 66
3 li 89
english.txt)
1 zhang 55
2 zhang 69
3 zhang 75
1 wang 44
2 wang 64
3 wang 86
1 li 76
2 li 84
3 li 93//以下代码涉及到的重要方法
FileSplit inputSplit = (FileSplit) context.getInputSplit();
String fn = inputSplit.getPath().getName();1>ScoreBean
public class ScoreBean implements Writable {
private String name;
private String subject;
private int month;
private int score;
//这里省去了以下方法,记得补上
//……get/set……
//……有参/无参构造……
//……read/write……
}2>Mapper
public class ScoreMapper extends Mapper<LongWritable, Text, Text, ScoreBean> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, ScoreBean>.Context context)
throws IOException, InterruptedException {
String line = value.toString();
String attr[] = line.split(" ");
String name = attr[1];
FileSplit fs = (FileSplit) context.getInputSplit();
String path = fs.getPath().getName();
String subject = path.substring(0, path.lastIndexOf("."));
ScoreBean sb = new ScoreBean(attr[1], subject, Integer.parseInt(attr[0]), Integer.parseInt(attr[2]));
context.write(new Text(name), sb);
}
}3>Reducer
public class ScoreReducer extends Reducer<Text, ScoreBean, Text, NullWritable> {
@Override
protected void reduce(Text k3, Iterable<ScoreBean> v3s,
Reducer<Text, ScoreBean, Text, NullWritable>.Context context) throws IOException, InterruptedException {
String name = k3.toString();
Map<String, Integer> map = new HashMap<String, Integer>();
int count = 0;
Iterator<ScoreBean> it = v3s.iterator();
while (it.hasNext()) {
ScoreBean sb = it.next();
map.put(sb.getSubject(), sb.getScore());
count += sb.getScore();
}
String result = name + " " + map.get("chinese") + " " + map.get("math") + " " + map.get("english") + " "
+ count;
context.write(new Text(result), NullWritable.get());
}
}4>Partitioner
public class ScoreMonthPartitioner extends Partitioner<Text, ScoreBean>{
@Override
public int getPartition(Text key, ScoreBean value, int numPartitions) {
return value.getMonth()-1;
}
}5>Driver
public class ScoreDriver {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "Scorec_Job");
job.setJarByClass(cn.tedu.score.ScoreDriver.class);
job.setMapperClass(cn.tedu.score.ScoreMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(ScoreBean.class);
job.setReducerClass(cn.tedu.score.ScoreReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
job.setPartitionerClass(ScoreMonthPartitioner.class);
job.setNumReduceTasks(3);
FileInputFormat.setInputPaths(job, new Path("hdfs://hadoop:9000/scoredata"));
FileOutputFormat.setOutputPath(job, new Path("hdfs://hadoop:9000/scoresult"));
if (!job.waitForCompletion(true))
return;
}
}二、MapReduce其他功能
1、InputFormat
1.概述
InputFormat:输入格式化器。
MapReduce开始阶段阶段,InputFormat类用来产生InputSplit,并把基于RecordReader它切分成record,形成Mapper的输入。
Hadoop本身提供了若干内置的InputFormat,其中如果不明确指定默认使用TextInputFormat。
2.常见的InputFormat
1>TextInputFormat
作为默认的文件输入格式,用于读取纯文本文件,文件被分为一系列以LF或者CR结束的行,key是每一行的位置偏移量,是LongWritable类型的,value是每一行的内容,为Text类型。
2>KeyValueTextInputFormat
同样用于读取文件,如果行被分隔符(缺省是tab)分割为两部分,第一部分为key,剩下的部分为value;如果没有分隔符,整行作为key,value为空。
3>SequenceFileInputFormat
用于读取sequence file。sequence file是Hadoop用于存储数据自定义格式的binary文件。它有两个子类:SequenceFileAsBinaryInputFormat,将key和value以BytesWritable的类型读出;SequenceFileAsTextInputFormat,将key和value以Text类型读出。
4>SequenceFileInputFilter
根据filter从sequence文件中取得部分满足条件的数据,通过setFilterClass指定Filter,内置了三种Filter,RegexFilter取key值满足指定的正则表达式的记录;PercentFilter通过指定参数f,取记录行数%f==0的记录;MD5Filter通过指定参数f,取MD5(key)%f==0的记录。
5>NLineInputFormat
0.18.x版本新加入,可以将文件以行为单位进行split,比如文件的每一行对应一个mapper。得到的key是每一行的位置偏移量(LongWritable类型),value是每一行的内容,Text类型。适用于行少列多的文件。
6>CompositeInputFormat
用于多个数据源的join。
可以通过job.setInputFormatClass(XxxInputFormat.class);来设定选用哪种InputFormat。
3.自定义InputFormat
如果以上InputFormat不够用,我们也可以自己定义InputFormat。
所有InputFormat都要直接或间接的继承InputFormat抽象类。
1>InputFormat
InputFormat抽象类中主要定义了如下两个方法:
① getSplits(JobContext context)
生产InputSplit集合的方法,此方法接受JobContext接受环境信息,得到要处理的文件信息后,进行逻辑切割,产生InputSplit集合返回。
List<InputSplit> getSplits(JobContext context) throws IOException, InterruptedException;②createRecordReader(InputSplit split,TaskAttemptContext context)
此方法返回RecordReader对象。一个RecordReader包含方法描述如何从InputSplit切分出要送入Mapper的K1、V1对。
public abstract RecordReader<K,V> createRecordReader(InputSplit split,TaskAttemptContext context) throws IOException, InterruptedException;2>FileInputFormat
我们可以直接继承InputFormat,但更多的时候我们会选择继承他的一个实现子类,比如:FileInputFormat。此类是所有来源为文件的InputFormat的基类,默认的TextInputFormat就继承自它。
FileInputFormat实现了InputFormat抽象类,实现了getSplits方法,根据配置去逻辑切割文件,返回FileSplit的集合,并提供了isSplitable()方法,子类可以通过在这个方法中返回boolean类型的值表明是否要对文件进行逻辑切割,如果返回false则无论文件是否超过一个Block大小都不会进行切割,而将这个文件作为一个逻辑块返回。而对createRecordReader方法则没有提供实现,设置为了抽象方法,要求子类实现。
如果想要更精细的改变逻辑切块规则可以覆盖getSplits方法自己编写代码实现。
而更多的时候,我们直接使用父类中的方法而将精力放置在createRecordReader上,决定如何将InputSplit转换为一个个的Recoder。
案例
读取score1.txt文件,从中每4行读取成绩,其中第一行为姓名,后3行为单科成绩,计算总分,最终输出为姓名:总分格式的文件。
文件内容样例:
张三
语文 97
数学 77
英语 69
李四
语文 87
数学 57
英语 63
王五
语文 47
数学 54
英语 39分析:
在此例子中,需要按照每三行一次进行读取称为一个InputSplit,经过比较可以使用NLineInputFormat,但是为了演示,使用自定义InputFormat来做这件事。
/**
* 自定义InputFormat类,来实现每三行作为一个Recorder触发一次Mapper的效果
*/
public class MyFileInputFormat extends FileInputFormat<Text, Text> {
/**
* 因为要每三行读取作为一个Recoder,所以如果切块造成块内数据行数不是3的倍数可能造成处理出问题
* 因此返回false,标识文件不要进行切块
*/
@Override
protected boolean isSplitable(JobContext context, Path filename) {
return false;
}
/**
* 返回自定义的MyRecordReader
*/
@Override
public RecordReader<Text, Text> createRecordReader(InputSplit split, TaskAttemptContext context)
throws IOException, InterruptedException {
return new MyRecordReader();
}
} /**
* 自定义的RecordReader,表明了如何将一个InputSplit切割出一个个的Recorder
*
*/
public class MyRecordReader extends RecordReader<Text, Text> {
private LineReader lineReader = null;
private Text key = null;
private Text value = null;
private boolean hasMore = true;
/**
* 初始化的方法,将在InputSplit被切割前调用
*/
@Override
public void initialize(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException {
//获取文件路径
FileSplit fs = (FileSplit) split;
Path path = fs.getPath();
//获取文件系统
Configuration conf = context.getConfiguration();
FileSystem fileSystem = path.getFileSystem(conf);
//从文件系统中读取文件路径得到文件流
FSDataInputStream fin = fileSystem.open(path);
//将文件流包装为行读取器
lineReader = new LineReader(fin);
}
/**
* 下一个keyvalue方法
* 返回值表当前是否读取到了新的纪录
*/
@Override
public boolean nextKeyValue() throws IOException, InterruptedException {
key = new Text();
value = new Text();
Text temp = new Text();
int count = 0;
for (int i = 0; i < 4; i++) {
int len = lineReader.readLine(temp);
if (len == 0) {
hasMore = false;
break;
} else {
count++;
value.append(temp.getBytes(), 0, temp.getLength());
value.append("\r\n".getBytes(), 0, "\r\n".length());
temp.clear();
}
}
key.set(count+"");
return count != 0;
}
/**
* 获取当前key方法
*/
@Override
public Text getCurrentKey() throws IOException, InterruptedException {
return key;
}
/**
* 获取当前value方法
*/
@Override
public Text getCurrentValue() throws IOException, InterruptedException {
return value;
}
/**
* 获取处理进度的方法,返回0.0f-1.0f之间的值表示进度
*/
@Override
public float getProgress() throws IOException, InterruptedException {
if (hasMore)
return 0.0f;
else
return 1.0f;
}
/**
* 关闭资源的方法
* 当切割InputSplit结束会被调用用来释放资源
*/
@Override
public void close() throws IOException {
lineReader.close();
}
}
/**
* 计算成绩的Mapper
*
*/
public class ScoreMapper extends Mapper<Text, Text, Text, Text> {
public void map(Text key, Text value, Context context) throws IOException, InterruptedException {
String str = value.toString();
String lines [] = str.split("\r\n");
String name = lines[0];
for(int i = 1;i<lines.length;i++){
context.write(new Text(name), new Text(lines[i]));
}
}
}/**
* 计算成绩的Reducer
*/
public class ScoreReducer extends Reducer<Text, Text, Text, IntWritable> {
public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
String name = key.toString();
int countFen = 0;
for(Text v : values){
String line = v.toString();
String subject = line.split(" ")[0];
int fen = Integer.parseInt(line.split(" ")[1]);
countFen += fen;
}
context.write(new Text(name), new IntWritable(countFen));
}
}/**
* ScoreDriver
*/
public class ScoreDriver {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "score_job");
job.setJarByClass(ScoreDriver.class);
job.setMapperClass(ScoreMapper.class);
job.setReducerClass(ScoreReducer.class);
//指定InputFormat为自定义的MyFileInputFormat
job.setInputFormatClass(MyFileInputFormat.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, new Path("hdfs://hadoop01:9000/score/score1.txt"));
FileOutputFormat.setOutputPath(job, new Path("hdfs://hadoop01:9000/score/result"));
if (!job.waitForCompletion(true))
return;
}
}4.MultipleInputs
MultipleInputs可以将多个输入组装起来,同时为Mapper提供数据,当我们希望从多个来源读取数据时可以使用。甚至,在指定来源时可以为不同来源的数据指定不同的InputFormat和Mapper以应对不同格式的输入数据。
此类上提供的静态方法有:
/**
* 指定数据来源及对应的InputFormat
*/
MultipleInputs.addInputPath(job, path, inputFormatClass);
/**
* 指定数据来源及对应的InputFormat 和 Mapper
*/
MultipleInputs.addInputPath(job, path, inputFormatClass, mapperClass);案例
改造上述案例,同时从另一个文件score2.txt中读取数据统计成绩。score2.txt中的数据是一行为一个学生的成绩。
数据样例:
赵六 56 47 69
陈七 73 84 91
刘八 45 56 66代码:
/**
* 计算成绩的Mapper
*/
public class ScoreMapper2 extends Mapper<LongWritable, Text, Text, Text> {
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String attrs [] = line.split(" ");
String name = attrs[0];
for(int i = 1;i<attrs.length;i++){
if(i == 1){
context.write(new Text(name), new Text("语文\t"+attrs[i]));
}else if(i == 2){
context.write(new Text(name), new Text("数学\t"+attrs[i]));
}else if(i == 3){
context.write(new Text(name), new Text("英语\t"+attrs[i]));
}
}
}
}/**
* ScoreDriver
*/
public class ScoreDriver {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "score_job");
job.setJarByClass(ScoreDriver.class);
//job.setMapperClass(ScoreMapper.class);
job.setReducerClass(ScoreReducer.class);
//指定InputFormat为自定义的MyFileInputFormat
job.setInputFormatClass(MyFileInputFormat.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//FileInputFormat.setInputPaths(job, new Path("hdfs://hadoop01:9000/score/score1.txt"));
MultipleInputs.addInputPath(job, new Path("hdfs://hadoop01:9000/score/score1.txt"), MyFileInputFormat.class,ScoreMapper.class);
MultipleInputs.addInputPath(job, new Path("hdfs://hadoop01:9000/score/score2.txt"), TextInputFormat.class,ScoreMapper2.class);
FileOutputFormat.setOutputPath(job, new Path("hdfs://hadoop01:9000/score/result"));
if (!job.waitForCompletion(true))
return;
}
}2、OutputFormat
1.概述
OutputFormat:输出格式化器。
MapReduce结束阶段,OutputFormat类决定了Reducer如何产生输出。
Hadoop本身提供了若干内置的OutputFormat,其中如果不明确指定默认使用TextOutputFormat。
2.常见的OutputFormat
1>FileOutputFormat
(实现OutputFormat接口)- 所有输出到文件的OutputFormats的基类。
2>TextOutputFormat
以行分隔、包含制表符定界的键值对的文本文件格式。
3>SequenceFileOutputFormat
二进制键值数据的压缩格式。
4>SequenceFileAsBinaryOutputFormat
原生二进制数据的压缩格式。
5>MapFileOutputFormat
一种使用部分索引键的格式。
6>MultipleOutputFormat
使用键值对参数写入文件的抽象类。
7>MultipleTextOutputFormat
输出多个以标准行分割、制表符定界格式的文件。
8>MultipleSequenceFileOutputFormat
输出多个压缩格式的文件。
可以通过job.setOutputFormatClass(XxxoutputFormat.class);来设定选用哪种OutputFormat。
3.自定义OutputFormat
如果以上OutputFormat不够用,同样也可以自己定义OutputFormat。
1>OutputFormat
所有的OutputFormat都要直接或间接的继承OutputFormat抽象类
OutputFormat抽象类中定义了如下的抽象方法:
①getRecordWriter(TaskAttemptContext context)
public abstract RecordWriter<K, V> getRecordWriter(TaskAttemptContext context) throws IOException, InterruptedException;
public abstract void checkOutputSpecs(JobContext context ) throws IOException,InterruptedException;
public abstract OutputCommitter getOutputCommitter(TaskAttemptContext context) throws IOException, InterruptedException;2>FileOutputFormat
我们可以直接继承OutputFormat,但更多的时候我们会选择继承他的一个实现子类,比如FileOutputFormat。- 此类是所有目的地为文件的OutputFormat的基类,例如默认的TextOutputFormat就继承自它。
FileOutputFormat实现了OutputFormat接口,默认实现了checkOutputSpecs和getOutputCommitter方法,并将getRecordWriter()设置为抽象方法要求我们去实现。
如果想要更精细的改变逻辑可以自己去编写getOutputCommitter和checkOutputSpecs方法。
而更多的时候,我们直接使用父类中的方法而将精力放置在getRecordWriter上,决定如何产生输出。
案例
编写wordcount案例,并将输出按照'#'进行分割,输出为一行。
数据样例:
hello tom
hello joy
hello rose
hello joy
hello jerry
hello tom
hello rose
hello joy代码如下:
public class MyRecordWriter<K,V> extends RecordWriter<K,V> {
protected DataOutputStream out = null;
private final byte[] keyValueSeparator;
//public static final String NEW_LINE = System.getProperty("line.separator");
public static final String NEW_LINE = "#";
public MyRecordWriter(DataOutputStream out,String keyValueSeparator) {
this.out = out;
this.keyValueSeparator = keyValueSeparator.getBytes();
}
@Override
public void write(K key, V value) throws IOException, InterruptedException {
if(key!=null){
out.write(key.toString().getBytes());
out.write(keyValueSeparator);
}
out.write(value.toString().getBytes());
out.write(NEW_LINE.getBytes());
}
@Override
public void close(TaskAttemptContext context) throws IOException, InterruptedException {
out.close();
}
}public class MyFileOutputFormat<K,V> extends FileOutputFormat<K,V> {
@Override
public RecordWriter<K,V> getRecordWriter(TaskAttemptContext context) throws IOException, InterruptedException {
Configuration conf = context.getConfiguration();
Path file = getDefaultWorkFile(context, "");
FileSystem fs = file.getFileSystem(conf);
FSDataOutputStream fileOut = fs.create(file, false);
return new MyRecordWriter<K,V>(fileOut, " ");
}
}public class WCMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String words [] = line.split(" ");
for(String word : words){
context.write(new Text(word), new LongWritable(1));
}
}
}public class WCReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
public void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
Iterator<LongWritable> it = values.iterator();
long count = 0;
while(it.hasNext()){
long c = it.next().get();
count += c;
}
context.write(key, new LongWritable(count));
}
}public class WCDriver {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "WCJob");
job.setJarByClass(cn.tedu.wc.WCDriver.class);
job.setMapperClass(cn.tedu.wc.WCMapper.class);
job.setReducerClass(cn.tedu.wc.WCReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
job.setOutputFormatClass(MyFileOutputFormat.class);
FileInputFormat.setInputPaths(job, new Path("hdfs://yun01:9000/park/words.txt"));
FileOutputFormat.setOutputPath(job, new Path("hdfs://yun01:9000/park/result2"));
if (!job.waitForCompletion(true))
return;
}
}4.MultipleOutputs
MultipleOutputs可以令一个Reducer产生多个输出文件。
为特定kv打上指定标记
MultipleOutputs<Text,LongWritable> mos = new MultipleOutputs<Text,LongWritable>(context);
mos.write("flag", key, value);
/**
为指定标记内容指定输出方式
可以指定多个
*/
MultipleOutputs.addNamedOutput(job, "flag", XxxOutputFormat.class, Key.class, Value.class);案例
改造上面的wordcount案例,将首字母为a-j的输出到"small"中。其他输出到"big"中。
代码如下:
public class WCMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String words [] = line.split(" ");
for(String word : words){
context.write(new Text(word), new LongWritable(1));
}
}
}public class WCReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
MultipleOutputs<Text,LongWritable> mos = null;
@Override
protected void setup(Reducer<Text, LongWritable, Text, LongWritable>.Context context)
throws IOException, InterruptedException {
this.mos = new MultipleOutputs<Text,LongWritable>(context);
}
public void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
Iterator<LongWritable> it = values.iterator();
long count = 0;
while(it.hasNext()){
long c = it.next().get();
count += c;
}
if(key.toString().matches("[a-j][a-z]*")){
mos.write("small", key, new LongWritable(count));
}else{
mos.write("big", key, new LongWritable(count));
}
}
}public class WCDriver {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "WCJob");
job.setJarByClass(cn.tedu.wc.WCDriver.class);
job.setMapperClass(cn.tedu.wc.WCMapper.class);
job.setReducerClass(cn.tedu.wc.WCReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
MultipleOutputs.addNamedOutput(job, "small", MyFileOutputFormat.class, Text.class, IntWritable.class);
MultipleOutputs.addNamedOutput(job, "big", MyFileOutputFormat.class, Text.class, IntWritable.class);
FileInputFormat.setInputPaths(job, new Path("hdfs://192.168.242.101:9000/park/words.txt"));
FileOutputFormat.setOutputPath(job, new Path("hdfs://192.168.242.101:9000/park/result2"));
if (!job.waitForCompletion(true))
return;
}
}3、GroupingComparator
在reduce阶段进行,对mapper发送过来的数据会进行分组的操作,这个过程称为为Grouping。默认情况下会将k2相同的内容作为一组。
我们可以通过job.setGroupingComparatorClass(MyGroupingComparator.class);方法自己指定Grouping规则。
1.WritableComparator
案例
改造WordCount案例,实现统计a-h 和 i-z开头的单词数量统计。
public class WCComparator extends WritableComparator {
@Override
public int compare(byte[] b1, int begin1, int len1, byte[] b2, int begin2, int len2) {
try {
DataInput in = new DataInputStream(new ByteArrayInputStream(b1,begin1,len1));
Text ta = new Text();
ta.readFields(in);
in = new DataInputStream(new ByteArrayInputStream(b2,begin2,len2));
Text tb = new Text();
tb.readFields(in);
if(ta.toString().matches("^[a-n][a-z]*$") && tb.toString().matches("^[a-n][a-z]*$")){
return 0;
}else if(ta.toString().matches("^[o-z][a-z]*$") && tb.toString().matches("^[o-z][a-z]*$")){
return 0;
}else{
return 1;
}
} catch (IOException e) {
e.printStackTrace();
throw new RuntimeException(e);
}
}
}4、二次排序
所谓二次排序就是首先按照第一字段排序,然后再对第一字段相同的行按照第二字段排序,注意不能破坏第一个字段的排序顺序。
/**
* 开发bean封装数据
*/
public class NumBean implements WritableComparable<NumBean> {
private int lnum;
private int rnum;
public NumBean() {
}
public NumBean(int lnum, int rnum) {
this.lnum = lnum;
this.rnum = rnum;
}
public int getLnum() {
return lnum;
}
public void setLnum(int lnum) {
this.lnum = lnum;
}
public int getRnum() {
return rnum;
}
public void setRnum(int rnum) {
this.rnum = rnum;
}
@Override
public void readFields(DataInput in) throws IOException {
this.lnum = in.readInt();
this.rnum = in.readInt();
}
@Override
public void write(DataOutput out) throws IOException {
out.writeInt(lnum);
out.writeInt(rnum);
}
@Override
public int compareTo(NumBean o) {
if(this.lnum != o.getLnum()){
return this.lnum - o.getLnum();
}else{
return this.rnum - o.getRnum();
}
}
}
/**
* 开发Mapper 用 NumBean作为k2 由于 NumBean覆盖了compareTo方法 可以实现自动二次排序
*/
public class NumMapper extends Mapper<LongWritable, Text, NumBean, NullWritable> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, NumBean, NullWritable>.Context context)
throws IOException, InterruptedException {
//1.读取行
String line = value.toString();
//2.切分出lnum 和 rnum
String [] attrs = line.split(" ");
int lnum = Integer.parseInt(attrs[0]);
int rnum = Integer.parseInt(attrs[1]);
//3.封装数据到bean
NumBean nb = new NumBean(lnum,rnum);
//4.发送数据
context.write(nb, NullWritable.get());
}
}
/**
* 开发Reducer输出结果 shuffle阶段已经完成了二次排序 此处直接输出即可
*/
public class NumReducer extends Reducer<NumBean, NullWritable, IntWritable, IntWritable> {
@Override
protected void reduce(NumBean key, Iterable<NullWritable> values,
Reducer<NumBean, NullWritable, IntWritable, IntWritable>.Context context)
throws IOException, InterruptedException {
int lnum = key.getLnum();
int rnum = key.getRnum();
context.write(new IntWritable(lnum), new IntWritable(rnum));
}
}/**
* 为了防止重复 数据被grouping成一条数据 造成结果丢失 自定义gourping过程 固定返回-1 表示无论什么情况都不合并数据
*/
public class NumWritableComparator extends WritableComparator {
@Override
public int compare(byte[] arg0, int arg1, int arg2, byte[] arg3, int arg4, int arg5) {
return -1;
}
}/**
* 开发Driver组装程序
*/
public class NumDriver {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "num_job");
job.setJarByClass(cn.tedu.mr.grouping.num.NumDriver.class);
job.setMapperClass(cn.tedu.mr.grouping.num.NumMapper.class);
job.setMapOutputKeyClass(NumBean.class);
job.setMapOutputValueClass(NullWritable.class);
job.setReducerClass(cn.tedu.mr.grouping.num.NumReducer.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(IntWritable.class);
job.setGroupingComparatorClass(NumWritableComparator.class);
FileInputFormat.setInputPaths(job, new Path("hdfs://hadoop01:9000/ndata"));
FileOutputFormat.setOutputPath(job, new Path("hdfs://hadoop01:9000/nresult"));
if (!job.waitForCompletion(true))
return;
}
}5、数据倾斜处理
在开发MR程序时,可能遇到的数据分配不一致,造成程序性能下降的问题,这个问题称之为数据倾斜问题。
解决办法:
如果是因为shuffle分配数据不均匀造成数据倾斜,重写parition均匀分配数据即可。
如果是数据本身带有倾斜的特点无法通过修改parition来解决倾斜问题,那么可以通过以下几个方法尝试解决:
1.利用combiner减轻倾斜的情况。
2.将造成倾斜的数据拿出单独处理。
3.将一个mr拆分成多个mr降低倾斜造成的危害。
6、小文件处理
1.小文件在hadoop中会有什么问题?
每个小文件无论多小都会对应一个block,而每一个block在NameNode中都要有元数据的记录,如果存在大量小文件,则NameNode中的大量空间都用来存放这些小文件的元数据信息,其实是相当浪费的,对于NameNode的性能有比较大的影响。
当使用mapreduce处理大量小文件时,默认情况下mapreduce在进行切片操作时规则是和block切的规则一样,即一个block一个InputSplit,而一个InputSplit就对应一个Mapper,这样会造成开启大量的MapperTask,但是每个MapperTask处理的数据量都很有限。极端情况下开启大量Mapper耗费内存甚至可能造成程序的崩溃。
2.Hadoop Archive
Hadoop Archive或者HAR,是一个高效地将小文件放入HDFS块中的文件存档工具,它能够将多个小文件打包成一个HAR文件,这样在减少namenode内存使用的同时,仍然允许对文件进行透明的访问。
HAR是在Hadoop file system之上的一个文件系统,因此所有fs shell命令对HAR文件均可用,只不过是文件路径格式不一样,HAR的访问路径可以是以下两种格式:
har://scheme-hostname:port/archivepath/fileinarchive
har:///archivepath/fileinarchive(本节点)
1>使用HAR时需要两点
第一,对小文件进行存档后,原文件并不会自动被删除,需要用户自己删除;
第二,创建HAR文件的过程实际上是在运行一个mapreduce作业,因而需要有一个hadoop集群运行此命令。
2>HAR还有一些缺陷
第一,一旦创建,Archives便不可改变。要增加或移除里面的文件,必须重新创建归档文件。
第二,要归档的文件名中不能有空格,否则会抛出异常,可以将空格用其他符号替换(使用-Dhar.space.replacement.enable=true 和-Dhar.space.replacement参数)。
3>命令
hadoop archive -archiveName <NAME>.har -p <parent path>[-r <replication factor>]<src>* <dest>案例:将hdfs:///small中的内容压缩成small.har
将某个文件打成har:
hadoop archive -archiveName small.har -p /small/small1.txt /small将多个small开头的文件打成har:
hadoop archive -archiveName small.har -p /small/small* /small将某个文件夹下所有文件打成har:
hadoop archive -archiveName small.har -p /small /small查看HAR文件存档中的文件
hadoop fs -ls har:///small/small.har输出har文件内容到本地系统
hadoop fs -get har:///small/small.har/smallx3.SequenceFile
SequenceFile文件是Hadoop用来存储二进制形式的key-value对而设计的一种平面文件(Flat File)。目前,也有不少人在该文件的基础之上提出了一些HDFS中小文件存储的解决方案,他们的基本思路就是将小文件进行合并成一个大文件,同时对这些小文件的位置信息构建索引。
文件不支持复写操作,不能向已存在的SequenceFile(MapFile)追加存储记录。
当write流不关闭的时候,没有办法构造read流。也就是在执行文件写操作的时候,该文件是不可读取的。
@Test
/**
* SequenceFile 写操作
*/
public void SequenceWriter() throws Exception{
final String INPUT_PATH= "hdfs://192.168.242.101:9000/big";
final String OUTPUT_PATH= "hdfs://192.168.242.101:9000/big2";
//获取文件系统
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.242.101:9000");
FileSystem fileSystem = FileSystem.get(new URI(INPUT_PATH), conf);
//创建seq的输出流
Text key = new Text();
Text value = new Text();
SequenceFile.Writer writer = SequenceFile.createWriter(fileSystem, conf, new Path(OUTPUT_PATH), key.getClass(), value.getClass());
//写新的数据
System.out.println(writer.getLength());
key.set("small4.txt".getBytes());
value.set("ddddddd".getBytes());
writer.append(key, value);
//关闭流
IOUtils.closeStream(writer);
}
@Test
/**
* SequenceFile 读操作
*/
public void sequenceRead() throws Exception {
final String INPUT_PATH= "hdfs://192.168.242.101:9000/big/big.seq";
//获取文件系统
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.242.101:9000");
FileSystem fileSystem = FileSystem.get(new URI(INPUT_PATH), conf);
//准备读取seq的流
Path path = new Path(INPUT_PATH);
SequenceFile.Reader reader = new SequenceFile.Reader(fileSystem, path, conf);
//通过seq流获得key和value准备承载数据
Writable key = (Writable) ReflectionUtils.newInstance(reader.getKeyClass(), conf);
Writable value = (Writable) ReflectionUtils.newInstance(reader.getValueClass(), conf);
//循环从流中读取key和value
long position = reader.getPosition();
while(reader.next(key, value)){
//打印当前key value
System.out.println(key+":"+value);
//移动游标指向下一个key value
position=reader.getPosition();
}
//关闭流
IOUtils.closeStream(reader);
}
@Test
/**
* 多个小文件合并成大seq文件
* @throws Exception
*/
public void small2Big() throws Exception{
final String INPUT_PATH= "hdfs://192.168.242.101:9000/small";
final String OUTPUT_PATH= "hdfs://192.168.242.101:9000/big/big.seq";
//获取文件系统
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.242.101:9000");
FileSystem fs = FileSystem.get(conf);
//通过文件系统获取所有要处理的文件
FileStatus[] files = fs.listStatus(new Path(INPUT_PATH));
//创建可以输出seq文件的输出流
Text key = new Text();
Text value = new Text();
SequenceFile.Writer writer = SequenceFile.createWriter(fs, conf, new Path(OUTPUT_PATH), key.getClass(),value.getClass());
//循环处理每个文件
for (int i = 0; i < files.length; i++) {
//key设置为文件名
key.set(files[i].getPath().getName());
//读取文件内容
InputStream in = fs.open(files[i].getPath());
byte[] buffer = new byte[(int) files[i].getLen()];
IOUtils.readFully(in, buffer, 0, buffer.length);
//值设置为文件内容
value.set(buffer);
//关闭输入流
IOUtils.closeStream(in);
//将key文件名value文件内容写入seq流中
writer.append(key, value);
}
//关闭seq流
IOUtils.closeStream(writer);
}4.CompositeInputFormat
用于多个数据源的join。
此类可以解决多个小文件在进行mr操作时map创建过多的问题。
此类的原理在于,它本质上市一个InputFormat,在其中的getSplits方法中,将他能读到的所有的文件生成一个InputSplit
使用此类需要配合自定义的RecordReader,需要自己开发一个RecordReader指定如何从InputSplit中读取数据。
也可以通过参数控制最大的InputSplit大小。
CombineTextInputFormat.setMaxInputSplitSize(job, 256*1024*1024);