Introduction

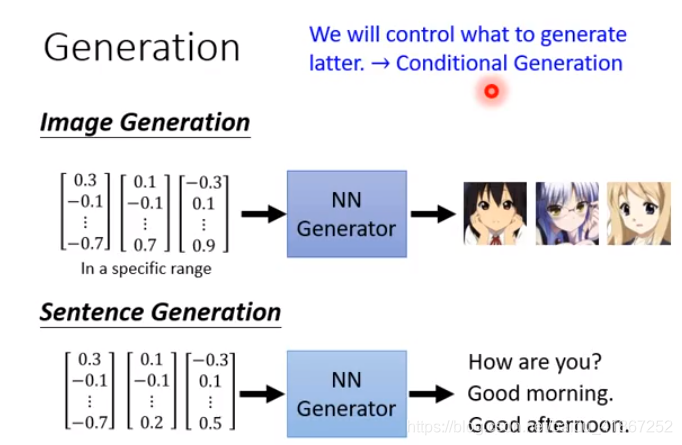
GAN (Generative Adversarial Nets) 的目标,训练出一个generator ,产生某些东西
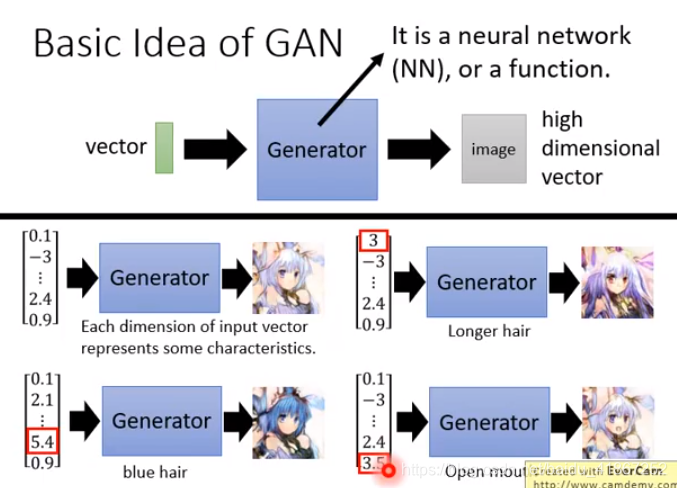
上图,第一维代表头发长短,倒数第二维代表蓝色的深浅…
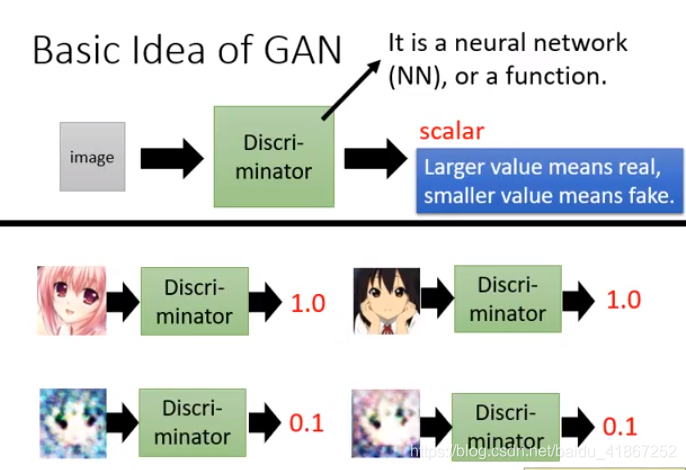
GAN同时训练出一个discriminator ,辨别器
输出的scalar 代表图片的质量
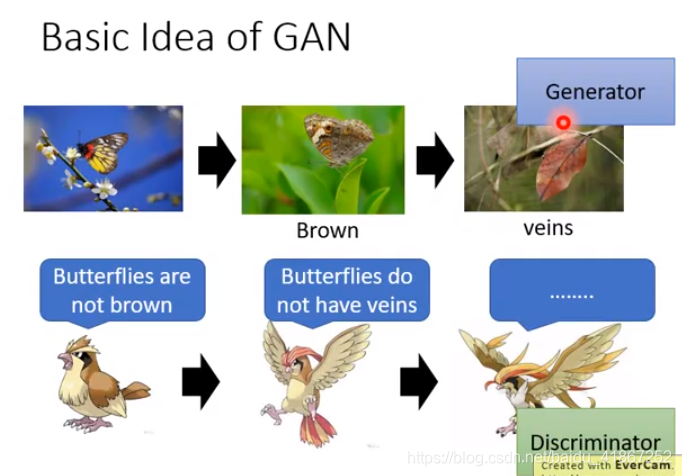
捕食的标准,与 蝴蝶的特征不断进化。
vein 叶脉
generator 与 discriminator 之间也是这种对抗关系
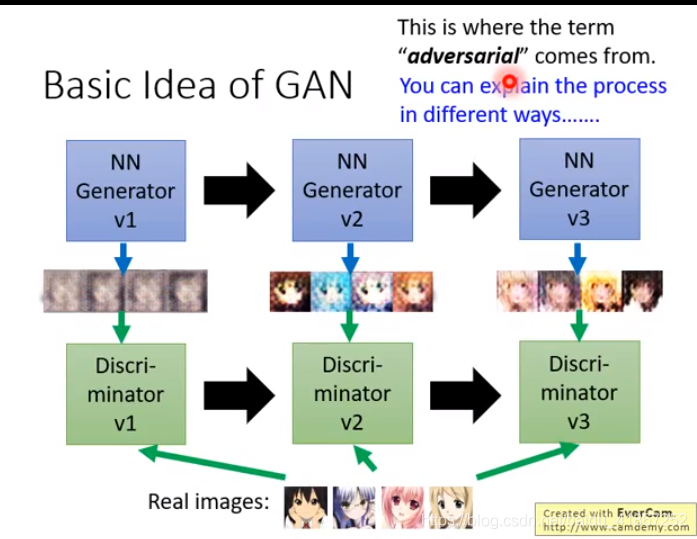
v1: 辨别器根据色彩判断
v2:根据是否有嘴
v2的生成器,能骗过v1的判别器
v3的生成器,能骗过v2的判别器
生成器生成的图片越来越真实
生成器与判别器不断对抗,不断进化,adversarial一词由来。
提出GAN的沦文里,用的例子是假钞与警察
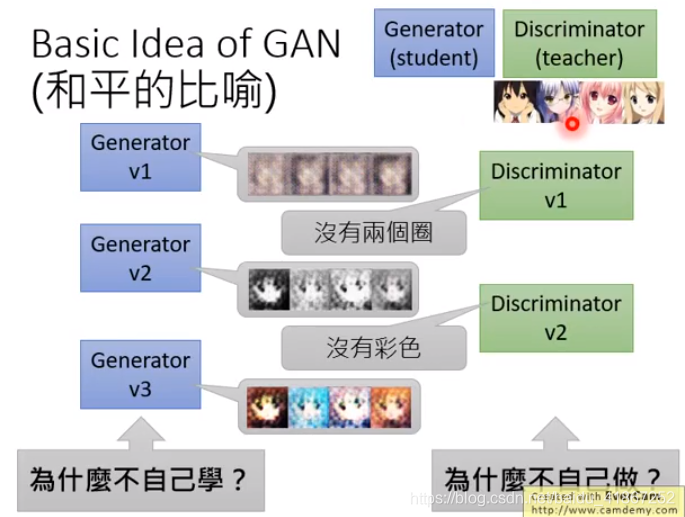
学生画的越来越逼真,老师的要求越来越严格。

两者的关系,可以是朋友,也可以是敌人。
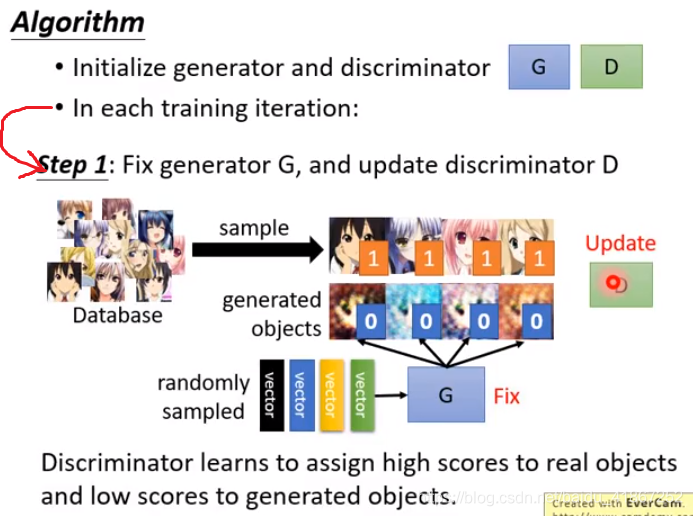
更新D的标准:把真实图放入D,得到的数值大,G生成的图放入D,数值小。
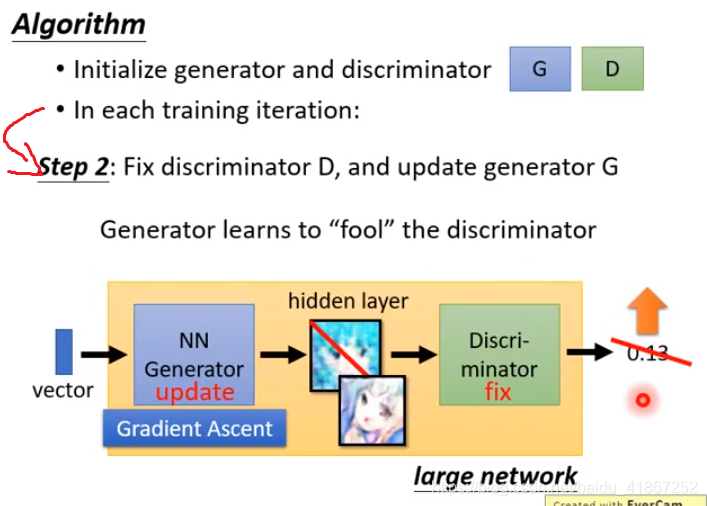
期望得到的数值越来越大,调整G的参数,使其产生的图越来越逼真,来‘骗过’D




结构化学习的输出比较复杂,GAN就属于结构化学习
结构化学习的例子:



structured learning 需要有全局观


vector 与 输出图片的特征有关系


希望 input 和 output 越接近越好


a和b的结合不一定得到数字1,因为generator不是线性的。

VAE 相当于在 code中加入噪声
variational :变化的
VAE 把decoder 训练得更加稳定

output和target不一定完全一样,即存在误差。

错了6个pixel的只是把笔画延长,可以接受。
所以,不能单纯的让output与target越像越好

多加几层,就可以影响临近的神经元的关系

discriminator在不同的领域有不同的名称:evaluation function…


discriminator可以生成,列举所有的 x(图片),带入D(x),使其最大的x作为生成的图。


左侧的负样本,效果太差
需要好的example才能训练出好的discriminator,只有好的discriminator才能找出好的example

arg max D(x)解出的作为下一轮的负样本


红线代表D(x)
在右侧,用第一轮得到的D(x)产生样本,作为负样本


当正负样本的分布重合时,训练结束

generator学到的是表象(pixel之间的相似程度,不能考虑大局)
discriminator的一个弊端是,arg max D(x)不好解(非线性)

用G来代替arg max D(x),可以理解为:G就是在学,怎么解arg max D(x)


GAN(有discriminator)的generator 的效果比 VAE的generator的好

得分越低越好,柱状的长度代表不同参数导致的得分,可以看出GAN的效果好,不过VAE比较稳定(柱状很短)
Conditional Generation

给出文字描述,输出相应的图片
使用传统的监督学习方法,效果不好。
如文字“火车”,多张图片,网络结构对所有的图片都要有较小的误差,最终导致产生的图片是其他图片的平均效果,得到模糊的图。

generator 为了骗过 discriminator 而仅生成高质量的图,而忽视了条件。

scalar 反应两点:图片是否高质量;图和条件是否匹配


上方的结构仅一个输出,如果值小的话,不能确定是图片质量差,还是图与文字不匹配。
下方的结构,给了两个输出,更合理一些

先产生一张小图,再产生大图,效果会更好




patch 小块区域

speech enhancement 语音增强(去除噪音)


Unsupervised Conditional Generation


texture 纹理
法1,输入输出的差距不大

无监督学习,X,Y之间没有联系
解决方法:
其一

简单的generator ,input output 差距不会太大
即一个风景画不可能生成人物字画像
其二

Encoder Network 已训练好

为了让左右两边的图经可能接近,中间的复古图就不会太奇怪
双向形式:


cycle GAN存在问题
左右两图屋顶都有黑点,中间确没有,即有信息被隐藏了。这样input 和 output 就不是特别接近,这样 cycle consistency 就失去意义(input 和 output 不要差距太大)

多个domain间转换,使用 starGAN

target domain 欲转换成的类别
第一个G的输入 image 与第二个G 的output 应尽可能接近



latent space 隐空间
上图问题的的解决办法:
 encoder 的后几层 decoder 的前几层共享参数
encoder 的后几层 decoder 的前几层共享参数
这样可以保证 latent space 具有相同维度

discriminator 用来判断 latent vector 是来源于 X domain image 还是 Y domain image



