文章目录
RANSAC在估计基础矩阵中的实际应用实例——它作为一种安全机制,保证了在有噪声的数据中可以提取到正确的模型。
RANSAC本质上就是Majority Voting的思想。如下图所示是没有经过筛选的匹配点对:

而求解基础矩阵需要至少8对点,所以我们可以随机挑选8对点,如下所示,并统计内点个数。在实际中RANSAC一般要运行很多次,才会得到比较好的结果。

基础矩阵
- 链接:https://blog.csdn.net/qq_38898129/article/details/93982154
X1与X2 是两幅图像的一对匹配点,F 为基础矩阵,基础矩阵为一幅图像上像 p_1点到另一幅图像上对极线L2 的一种映射。所以有如下公式:

特点
以后用到最小二乘就要想到RANSAC,它作为一种安全机制,保证了在有噪声的数据中可以提取到正确的模型。
RANSAC的优点
能鲁棒的估计模型参数。例如,它能从包含大量局外点的数据集中估计出高精度的参数。
RANSAC的缺点:
计算参数的迭代次数没有上限;如果设置迭代次数的上限,得到的结果可能不是最优的结果,甚至可能得到错误的结果。RANSAC只有一定的概率得到可信的模型,概率与迭代次数成正比。
要求设置跟问题相关的阀值。而且RANSAC只能从特定的数据集中估计出一个模型,如果存在两个(或多个)模型,RANSAC不能找到别的模型。
8点法求F
假设在两幅图像对应匹配点的坐标分别为:
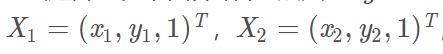
那么有:
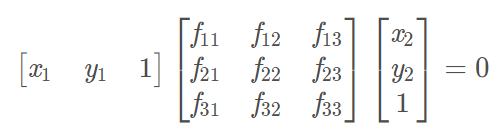
公式改写
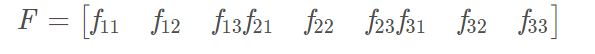
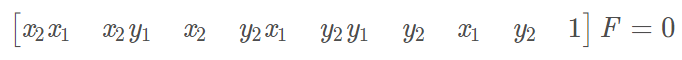
#8点法
def compute_fundamental(x1, x2):
n = x1.shape[1]
if x2.shape[1] != n:
raise ValueError("Number of points don't match.")
A = np.zeros((n, 9))
for i in range(n):
A[i] = [x1[0, i] * x2[0, i], x1[0, i] * x2[1, i], x1[0, i] * x2[2, i],
x1[1, i] * x2[0, i], x1[1, i] * x2[1, i], x1[1, i] * x2[2, i],
x1[2, i] * x2[0, i], x1[2, i] * x2[1, i], x1[2, i] * x2[2, i]]
U, S, V = np.linalg.svd(A)
F = V[-1].reshape(3, 3)
U, S, V = np.linalg.svd(F)
S[2] = 0
F = np.dot(U, np.dot(np.diag(S), V))
return F / F[2, 2]
# 归一化
def compute_fundamental_normalized(x1, x2):
n = x1.shape[1]
if x2.shape[1] != n:
raise ValueError("Number of points don't match.")
# normalize image coordinates
x1 = x1 / x1[2]
mean_1 = np.mean(x1[:2], axis=1)
S1 = np.sqrt(2) / np.std(x1[:2])
T1 = np.array([[S1, 0, -S1 * mean_1[0]], [0, S1, -S1 * mean_1[1]], [0, 0, 1]])
x1 = np.dot(T1, x1)
x2 = x2 / x2[2]
mean_2 = np.mean(x2[:2], axis=1)
S2 = np.sqrt(2) / np.std(x2[:2])
T2 = np.array([[S2, 0, -S2 * mean_2[0]], [0, S2, -S2 * mean_2[1]], [0, 0, 1]])
x2 = np.dot(T2, x2)
# compute F with the normalized coordinates
F = compute_fundamental(x1, x2)
# print (F)
# reverse normalization
F = np.dot(T1.T, np.dot(F, T2))
return F / F[2, 2]
给定8组点的集合,求解上述方程的就可以解矩阵F的各个系数,这里选择用SVD 算法求解,但是由于噪声、错误匹配点等因素影响,可能导致 求解得到的基础矩阵不稳定,所以基于此选择ransac 算法对其进行改进得到最优的F矩阵。
RANSAC用于剔除错误匹配的算法流程:
- 从匹配的点对中选择8个点,使用归一化8点法估算出基础矩阵F
- 计算其余的点对到其对应对极线的距离 ,如果 则该点为内点,否则为外点。记下符合该条件的内点的个数为num
- 迭代k次,或者某次得到内点的数目num 占有的比例大于等于95%,则停止。选择num 最大的基础矩阵作为最终的结果。
这里面涉及到的一个问题就是如何评价一个点是不是内点,误差度量指标是什么。简单来说就是在第一张影像中给定一个点,利用基础矩阵F可以算出其在第二张影像中的极线,理论上来说第二张影像中的对应点应该在这条极线上,所以检查第二张影像中的对应点是否在极线或指定阈值范围(一般而言阈值取1到2个像素)内即可判断是否是内点。当然按照“重投影误差”的思路也是可以的,有了F和第一张影像中的像素坐标,解算第二张影像中的对应坐标,并计算它与提取的对应点之间的欧氏距离,小于阈值即认为是内点。
随机选择8对匹配点,用于计算基础矩阵。
def randSeed(good, num = 8):
'''
:param good: 初始的匹配点对
:param num: 选择随机选取的点对数量
:return: 8个点对list
'''
eight_point = random.sample(good, num)
return eight_point
计算点到极线的举例
其中L=[a,b,c] 对极线的方向向量为[-b,a],所以此处计算距离利用的是点到向量的距离计算公式
def inlier(F,good, keypoints1,keypoints2,confidence):
num = 0
ransac_good = []
x1, x2 = PointCoordinates(good, keypoints1, keypoints2)
for i in range(len(x2)):
line = F.dot(x1[i].T)
#在对极几何中极线表达式为[A B C],Ax+By+C=0, 方向向量可以表示为[-B,A]
line_v = np.array([-line[1], line[0]])
err = h = np.linalg.norm(np.cross(x2[i,:2], line_v)/np.linalg.norm(line_v))
# err = computeReprojError(x1[i], x2[i], F)
if abs(err) < confidence:
ransac_good.append(good[i])
num += 1
return num, ransac_good
代码实践
sift错误较多

利用ransac算法剔除错误匹配点

之前学习过KL
- 2月25日 ,https://blog.csdn.net/djfjkj52/article/details/104433936
- 2月26日 ,https://blog.csdn.net/djfjkj52/article/details/104504644
- https://github.com/Ewenwan/MVision/tree/master/3D_Object_Detection/Object_Tracking
当人的眼睛观察运动物体时,物体的景象在人眼的视网膜上形成一系列连续变化的图像,
这一系列连续变化的信息不断“流过”视网膜(即图像平面),好像一种光的“流”,
故称之为光流(optical flow)。光流表达了图像的变化,由于它包含了目标运动的信息,
因此可被观察者用来确定目标的运动情况。
研究光流场的目的就是为了从图片序列中近似得到不能直接得到的运动场。运动场,
其实就是物体在三维真实世界中的运动;光流场,是运动场在二维图像平面上(人的眼睛或者摄像头)的投影。
效果展示:

光流法
通俗的讲就是通过一个图片序列,把每张图像中每个像素的运动速度和运动方向找出来就是光流场。
那怎么找呢?咱们直观理解肯定是:第t帧的时候A点的位置是(x1, y1),那么我们在第t+1帧的时候再找到A点,
假如它的位置是(x2,y2),那么我们就可以确定A点的运动了:
(Vx, Vy) = (x2, y2) - (x1,y1)。
Barron等人对多种光流计算技术进行了总结,按照理论基础与数学方法的区别把它们分成四种:
基于梯度的方法、
基于匹配的方法、
基于能量的方法、
基于相位的方法。
近年来神经动力学方法也颇受学者重视。
OpenCV中实现了不少的光流算法。
1)calcOpticalFlowPyrLK
通过金字塔Lucas-Kanade 光流方法计算某些点集的光流(稀疏光流)。
理解的话,可以参考这篇论文:
”Pyramidal Implementation of
the Lucas Kanade Feature TrackerDescription of the algorithm”
2)calcOpticalFlowFarneback
用Gunnar Farneback 的算法计算稠密光流(即图像上所有像素点的光流都计算出来)。
它的相关论文是:"Two-Frame Motion Estimation Based on PolynomialExpansion"
3)CalcOpticalFlowBM
通过块匹配的方法来计算光流。
4)CalcOpticalFlowHS
用Horn-Schunck 的算法计算稠密光流。相关论文好像是这篇:”Determining Optical Flow”
5)calcOpticalFlowSF
这一个是2012年欧洲视觉会议的一篇文章的实现:
"SimpleFlow: A Non-iterative, Sublinear Optical FlowAlgorithm",
工程网站是:http://graphics.berkeley.edu/papers/Tao-SAN-2012-05/
在OpenCV新版本中有引入。
Optical Flow:2D Point Correspondences原理
假设:
(1)亮度恒定,前后帧观测到的对应点的灰度值一样。
(2) 时间连续或者运动位移小。
(3) 空间一致性:邻近点有相似运动,同一子图像的像素点具有相同的运动。
常用过程
光流预测通常是从一对时间相关的图像对中,估计出第一张图像中各个像素点在相邻图像中的位置。
首先找去特征点,之后用光流去跟踪的方法。
a. 找到好的特征点,例如 Harris角点、Shi-Tomasi角点、FAST角点等
b. 计算光流。Lucas-Kanade method, LK光流(灰度不变,相邻像素运动相似)
过程:

(1)连续帧的图像

(2)特征点提取

(3)特征点跟踪

输出
问题:假如我们能够准确找到这个平移d,那么就可以找到两个影像的对应关系了
这里的I(x)和J(x)可以看作是以像素位置x为自变量与像素灰度为因变量的映射函数。

我们的优化变量就是平移d,通过不断调整这个二维的平移d,使得J和I相减的差值最小。
非线性最小二乘三步曲:
这个问题显然是一个非线性最小二乘问题。
可以按照以下三步进行求解。
第一步就是对自变量d求导并使导数为0;(对代价函数求导,导数为0的点即为局部极值或全局最优解。对于矩阵函数而言,就是求对应的雅可比矩阵。)

第二步是将非线性的目标函数用泰勒级数展开,变成线性形式;(我们可以对代价函数的导数在x这点进行泰勒展开,将展开结果带回原式(1),化简就可以得到中最后一个式子。这个式子是一个最小二乘问题,可以进行求解,进而获得Δx。)

第三步是迭代求解。


光流法
- https://cloud.tencent.com/developer/article/1500961
如果判断一个视频的相邻两帧I、J在某局部窗口w上是一样的

则在窗口w内有:
即,
 (1)
(1)
用泰勒公式展开右侧 ,有公式(2)
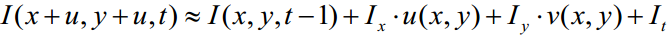
根据公式(1)(2)得到公式(3)
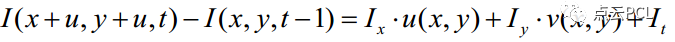
和
就是该点在x轴方向上和y方向的导数。
是该点对时间的求导,在极小时间内图像亮度恒定的条件下
为两帧图像上灰度值之差。因此有公式(4)
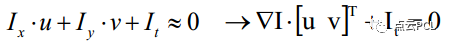
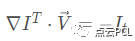
这就就是基本的光流约束条件,Ix,Iy,It均可由图像数据求得,而(u,v)即为所求光流矢量。但是光流的约束方程只有一个,而需要求出x,y方向的速度u和v(两个未知量),一个方程两个未知量是没有办法求解的,所以下文介绍的LK光流法考虑到了像素点的领域,将问题转变成了计算这些点集的光流,联立多个方程,从而解决这个问题。
LK
LK光流
LK( Lucas–Kanade )光流算法是一种两帧差分的光流估计算法。它由Bruce D. Lucas 和 Takeo Kanade提出。
光流分为稠密光流法和稀疏光流法,稀疏光流主要是跟踪特征点,稠密光流是跟踪图像中的每个像素。
LK光流算法加了一个更加严格的条件—空间一致性,一个场景上邻近的点投影到图像上也是邻近点,且邻近点速度一致。这是Lucas-Kanade光流法特有的假定,因为光流法基本方程约束只有一个,而要求x,y方向的速度,有两个未知变量。我们假定特征点邻域内做相似运动,就可以联立n多个方程求取x,y方向的速度(n为特征点邻域总点数,包括该特征点)。
领域内光流一致,一个场景中的同一个表面的局部领域内具有相似的运动,在图像平面上的投影也在邻域区域,且临近点速度一致,认为邻域内所有像素点的运动一致的,这是LK光流特有的假定。
具体到图像中,所以下图所示,Wx,Wy是块区域的大小。

根据以上的区域灰度值不变且邻域内的所有像素点运动一致的。可以得出以下

该方程中只有两个未知数,u和v,却有n个方程也是不合理的,说明这个方程中也有多余的,怎么样才能得到最优解呢?可以将上式整理为

简单写为,其中A是在x,y方向上导数,x为要求的u和v向量
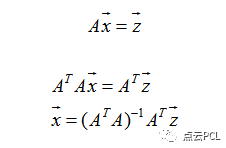
最终得出
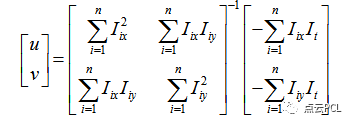
所以这里我们列出了这些方程的残差函数
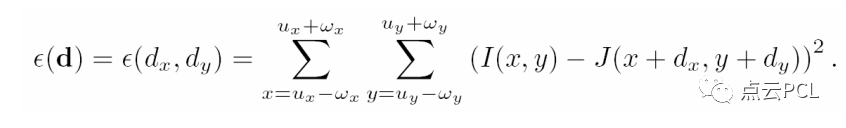
那么最终只需要求得到该残差方程的偏移量最小,也就是使用了最小二乘法求出这个方程组的最优解。
加入图像金字塔光流的计算LK
上面提到了LK光流的假定是小运动,可是运动较快的时候应该怎么办呢?考虑到两帧之间的物体的位移比较大,且运动快速时,算法会出现较大的误差,那么就希望减少图像中物体的运动位移,怎么做的?那就要缩小图像的尺寸,假设当图像为400400,物体的位移为【16,16】那么当图像缩小为200200位移就变成了[8,8] 缩小为100*100 位移缩小为[4,4],所以在原图像缩放了很多以后,LK光流法又变得适用了。所以LK光流引入了图像金字塔,上层金字塔(低分辨率)中的一个像素可以代表下层的两个像素,这样利用金字塔的结构,将图像逐层的分解,自上而下修正的运动量。
(1)图像金字塔,首先对每一帧图像建立一个高斯金字塔,最低分辨率图像在最顶层,原始图像在底层。
(2)计算光流使用顶层(Lm)层开始,通过最小化每个点领域范围内的匹配误差和,得到每个顶层图像中每个点的光流。该步骤主要是求解上述的残差函数,不再赘述。
假设图像的尺寸每次缩放为原来的一半,一共缩放了Lm层,则第0层为原始图像。
设已知原图的位移为d,则每一层的位移可以表示为
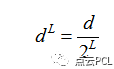
所以顶层的光流计算结果,也就是位移,反应到Lm-1层,作为该层初始时的光流值的估计g表示为:
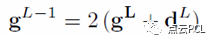
可以理解为 准确值=估计值+残差,对于每一层L,每个点的光流的计算都是基于邻域内所有点的匹配误差和最小化
设顶层图像中的光流的估计值设置为0
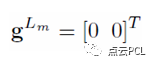
最小化上文提到的残差方程——》对该方程求导——》使用一阶泰勒展开B(x+vx,y+vy),并替换上式(方程求导)——》
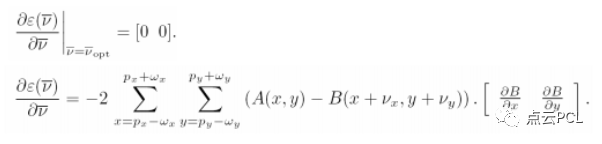

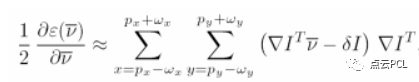

2.0 Velocities from Optical Flow——利用光流来估计3D速度



对于光流场向量可以分为平移部分和选择部分。
如果有3个不共线的光流向量和深度,就可以基于6个式子解算3D速度

平移不会将移动无穷远处的点。
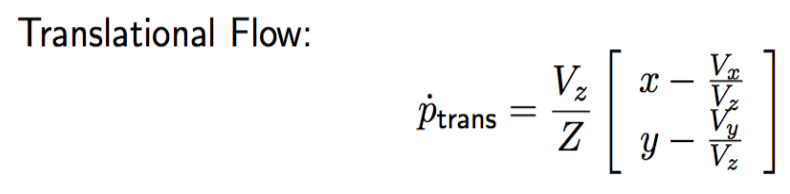

如果我们看水平面的无穷远点仍然旋转

