题目
给定一个排序链表,删除所有重复的元素,使得每个元素只出现一次。
示例1 :
输入: 1->1->2
输出: 1->2
示例2 :
输入: 1->1->2->3->3
输出: 1->2->3
自己的想法
算法实现
class Solution:
def deleteDuplicates(self, head: ListNode) -> ListNode:
if head is None or head.next is None:
return head
cur = head
while cur.next is not None:
if cur.val != cur.next.val:
cur = cur.next
continue
else:
bef = cur
while cur.next is not None and cur.val == cur.next.val:
cur = cur.next
bef.next = None if cur.next is None else cur.next
return head
执行结果
执行结果 : 通过
执行用时 : 44 ms, 在所有 Python3 提交中击败了72.22%的用户
内存消耗 : 13.5 MB, 在所有 Python3 提交中击败了18.15%的用户

复杂度分析
-
时间复杂度:O(n),我们遍历了包含有 n 个元素的链表一次。
-
空间复杂度:O(1),需要额外的常数级空间。
双指针法
class Solution:
def deleteDuplicates(self, head: ListNode) -> ListNode:
if head is None or head.next is None:
return head
slow = head
fast = head.next
while fast is not None:
if slow.val != fast.val:
slow = slow.next
slow.val = fast.val
fast = fast.next
slow.next = None
return head
执行结果
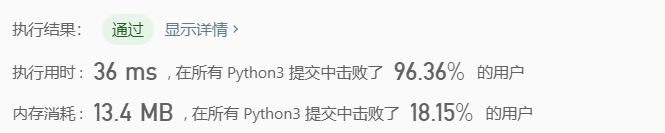
复杂度分析
-
时间复杂度:O(n),
我们只遍历了包含有 n 个元素的链表一次。 -
空间复杂度:O(1)
小结
先按照自己的想法设计,通过去掉重复的节点来实现。
之后看了双指针法,自己按照思路写了出来,算法快了不少。
