1. 问题场景
同时遍历两个长度为length的列表
2. 可选方案
- 双层循环
- 利用index单层循环访问
- 利用zip单层循环访问
3. 实现代码
注意,这里对方法一是不公平的,因为后两个方法其实只对tmp赋值了length次,而方法一赋值了length^2次,并不严格符合题意,这里只是写出来做个对比,也为5.1部分做个铺垫
length = 100000
a = list(np.random.rand(length))
b = list(np.random.rand(length))
time1 = time()
# 方法一
for i in a:
for j in b:
tmp = i + j
time2 = time()
# 方法二
for i in range(length):
tmp = a[i]+b[i]
time3 = time()
# 方法三
for i, j in zip(a,b):
tmp = i + j
time4 = time()
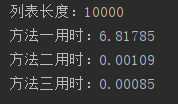
print("列表长度:"+str(length))
print("方法一用时:"+str(round(time2-time1, 5)))
print("方法二用时:"+str(round(time3-time2, 5)))
print("方法三用时:"+str(round(time4-time3, 5)))
4. 性能分析



5. 额外说明
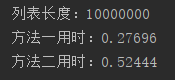
5.1 方法一vs方法二
上述方法一与方法二的性能差距主要是因为前者双层循环,后者单层循环;
而如果同样单层循环下,for … in list_name 是比 for i in range(length) 方法更快的;
个人认为是由于方法一是直接访问元素,方法二需要先访问index,再用index访问元素,较麻烦
length = 10000000
a = list(np.random.rand(length))
time1 = time()
for i in a:
b = i
time2 = time()
for i in range(length):
b = a[i]
time3 = time()
print("列表长度:"+str(length))
print("方法一用时:"+str(round(time2-time1, 5)))
print("方法二用时:"+str(round(time3-time2, 5)))
5.2 方法二vs方法三
方法二和方法三性能差距不大,而方法二略逊于方法三的原因应该和5.1所述类似,其通过index进行访问较为繁琐~
