PTA 社交集群 Java

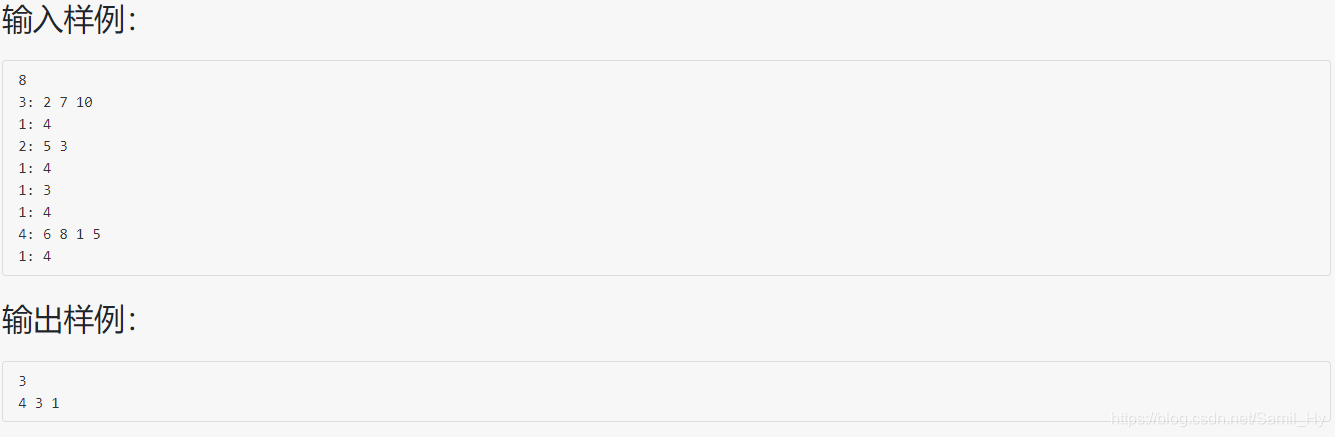
查找有多少个没有交集圈子(集群),直接使用并查集来做
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Iterator;
import java.util.LinkedList;
import java.util.Queue;
import java.util.StringTokenizer;
public class Main {
public static void main(String[] args) throws IOException {
Reader.init(System.in);
int N = Reader.nextInt();
nums = new int[N];
init();
int[] datas = new int[N];
for (int i = 0; i < N; i++) {
String[] s = Reader.nextLine().split(" ");
int first = Integer.valueOf(s[1]);
// datas[]记录当前用户的第一个兴趣编号
// 用于判断用户所属的集群
datas[i] = first;
map[first][1] = 1;
for (int j = 1; j < s.length; j++) {
int item = Integer.valueOf(s[j]);
union(item, first);
map[item][1] = 1;
}
}
// 将每个集群的人数都放到root中
for (int i = 0; i < datas.length; i++) {
map[find(datas[i])][2]++;
}
// 计算有多少个集群,同时处理nums数组
int num = getNum();
System.out.println(num);
// 对nums数组进行排序
Arrays.sort(nums);
// 倒序输出nums数组(每个集群的人数)
for (int i = nums.length - 1; i > nums.length - num; i--) {
System.out.print(nums[i] + " ");
}
System.out.print(nums[nums.length - num]);
}
// 并查集
static int[][] map;
// 记录集群的人数
static int[] nums;
static void init() {
// 0 用来做并查集操作
// 1 标记此兴趣编号是否出现过,1表示出现过,0表示没有出现过
// 2 此兴趣爱好的人数
map = new int[1001][3];
for (int i = 0; i < map.length; i++) {
map[i][0] = i;
}
}
static int find(int val) {
// 查找root,同时压缩路径
if (val == map[val][0])
return val;
map[val][0] = find(map[val][0]);
return map[val][0];
}
static void union(int p1, int p2) {
// 将p1和p2联系起来
map[find(p1)][0] = find(p2);
}
static int getNum() {
// 计算有多少个集群
int count = 0;
for (int i = 1; i < map.length; i++) {
if (map[i][1] != 0 && map[i][0] == i) {
// 找到一个集群的根,将人数放到nums中
nums[count++] = map[i][2]
}
}
return count;
}
}
// Class for buffered reading int and double values *//*
class Reader {
static BufferedReader reader;
static StringTokenizer tokenizer;
// ** call this method to initialize reader for InputStream *//*
static void init(InputStream input) {
reader = new BufferedReader(new InputStreamReader(input));
tokenizer = new StringTokenizer("");
}
static void init(File file) {
try {
reader = new BufferedReader(new FileReader(file));
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
tokenizer = new StringTokenizer("");
}
// ** get next word *//*
static String next() throws IOException {
while (!tokenizer.hasMoreTokens()) {
// TODO add check for eof if necessary
tokenizer = new StringTokenizer(reader.readLine());
}
return tokenizer.nextToken();
}
static String nextLine() throws IOException {
return reader.readLine();
}
static int nextInt() throws IOException {
return Integer.parseInt(next());
}
static char nextChar() throws IOException {
return next().toCharArray()[0];
}
static float nextFloat() throws IOException {
return Float.parseFloat(next());
}
static Double nextDouble() throws IOException {
return Double.parseDouble(next());
}
}
