1. 为什么需要Spring Cloud Sleuth
微服务架构是一个分布式架构,它按业务划分服务单元,一个分布式系统往往有很多个服务单元。由于服务单元数量众多,业务的复杂性,如果出现了错误和异常,很难去定位。主要体现在,一个请求可能需要调用很多个服务,而内部服务的调用复杂性,决定了问题难以定位。所以微服务架构中,必须实现分布式链路追踪,去跟进一个请求到底有哪些服务参与,参与的顺序又是怎样的,从而达到每个请求的步骤清晰可见,出了问题,很快定位。
简言之对于一个大型的微服务架构系统的常见问题如下:如何串联调用链,快速定位问题;如何厘清微服务之间的依赖关系;如何进行各个服务接口的性能分折;如何跟踪业务流的处理。
2. spring Cloud Sleuth简介
来源官网术语翻译:https://cloud.spring.io/spring-cloud-static/spring-cloud-sleuth/2.2.2.RELEASE/reference/html/#terminology
spring Cloud Sleuth为 spring Cloud提供了分布式跟踪的解决方案,它大量借用了Google Dapper、 Twitter Zipkin和 Apache HTrace的设计,先来了解一下 Sleuth的术语, Sleuth借用了 Dapper的术语。
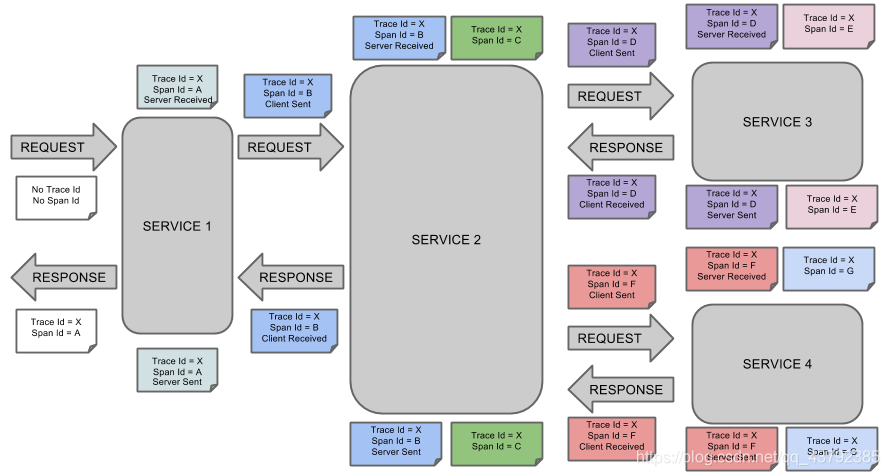
- span(跨度):基本工作单元。 span用一个64位的id唯一标识。除ID外,span还包含其他数据,例如描述、时间戳事件、键值对的注解(标签), spanID、span父 ID等。 span被启动和停止时,记录了时间信息。初始化 span被称为"rootspan",该 span的 id和 trace的 ID相等。
- trace(跟踪):一组共享"rootspan"的 span组成的树状结构称为 traceo trac也用一个64位的 ID唯一标识, trace中的所有 span都共享该 trace的 ID
- annotation(标注): annotation用来记录事件的存在,其中,核心annotation用来定义请求的开始和结束。
CS( Client sent客户端发送):客户端发起一个请求,该 annotation描述了span的开 始。
SR( server Received服务器端接收):服务器端获得请求并准备处理它。如果用 SR减去 CS时间戳,就能得到网络延迟。c)
SS( server sent服务器端发送):该 annotation表明完成请求处理(当响应发回客户端时)。如果用 SS减去 SR时间戳,就能得到服务器端处理请求所需的时间。
CR( Client Received客户端接收): span结束的标识。客户端成功接收到服务器端的响应。如果 CR减去 CS时间戳,就能得到从客户端发送请求到服务器响应的所需的时间
Spring Cloud Sleuth可以追踪10多种类型的组件:async、Hystrix,messaging,websocket,rxjava,scheduling,web(Spring MVC Controller,Servlet),webclient(Spring RestTemplate)、Feign、Zuul.官网介绍:https://cloud.spring.io/spring-cloud-static/spring-cloud-sleuth/2.2.2.RELEASE/reference/html/#integrations
下面是官方给的一个简单的微服务调用链示例图:
3. 搭建ZIPkin Server环境
因为sleuth对于分布式链路的跟踪仅仅是一些数据的记录, 这些数据我们人为来读取和处理难免会太麻烦了,所以我们一般吧这种数据上交给Zipkin Server 来统一处理.
3. 1 Zipkin 简介
Zipkin 是一个开放源代码分布式的跟踪系统,由Twitter公司开源,它致力于收集服务的定时数据,以解决微服务架构中的延迟问题,包括数据的收集、存储、查找和展现。
每个服务向zipkin报告计时数据,zipkin会根据调用关系通过Zipkin UI生成依赖关系图,显示了多少跟踪请求通过每个服务,该系统让开发者可通过一个 Web 前端轻松的收集和分析数据,例如用户每次请求服务的处理时间等,可方便的监测系统中存在的瓶颈。
Zipkin提供了可插拔数据存储方式:In-Memory、MySql、Cassandra以及Elasticsearch。接下来的测试为方便直接采用In-Memory方式进行存储,生产推荐Elasticsearch。
官网地址:https://zipkin.io/
开源代码地址(推荐访问):https://github.com/openzipkin/zipkin
3. 2 Server搭建环境
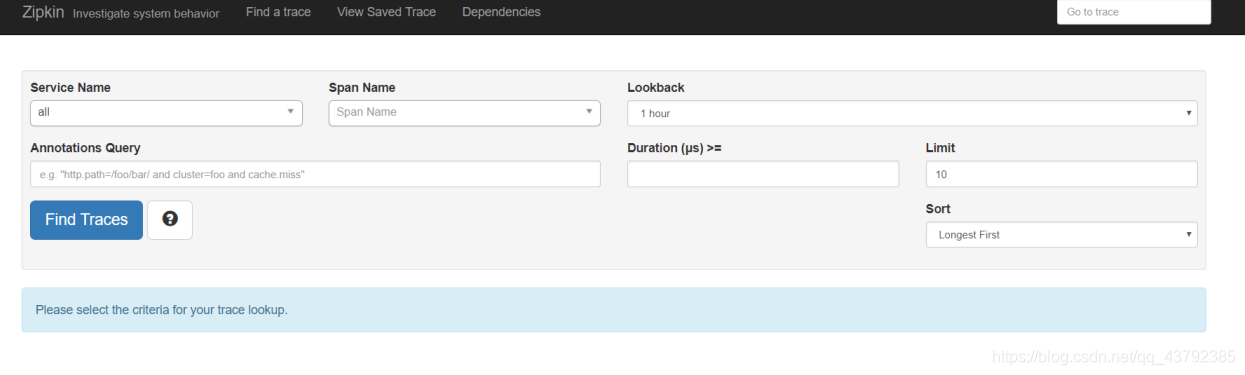
在zipkin2.7.x以后便不支持自定义服务器需要使用官方的版本或者Docker ,所以这里先介绍推荐的两种方式。启动服务之后访问Zipkin UI : http://your_host:9411/zipkin/.
3. 2.1 使用官方提供版本
要求JRE 8以上,执行如下指令即可:
curl -sSL https://zipkin.io/quickstart.sh | bash -s
java -jar zipkin.jar
3. 2.2 使用docker安装
docker环境安装及基本使用可参考之前的博文:总结 Docker学习(使用centos7-1804)
docker run -d -p 9411:9411 openzipkin/zipkin
3. 2.3 自定义server服务
创建maven工程,引入依赖
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-autoconfigure-ui</artifactId>
<version>2.8.4</version>
</dependency>
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-server</artifactId>
<version>2.8.4</version>
</dependency>
启动类添加注解
package com.qqxhb.zipkin;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import zipkin.server.internal.EnableZipkinServer;
/**
* @author Administrator
* @version 1.0
**/
@EnableZipkinServer
@SpringBootApplication
public class ZIPkinApplication {
public static void main(String[] args) throws Exception {
SpringApplication.run(ZIPkinApplication.class, args);
}
}
配置yml
server:
port: 9411
spring:
application:
name: springcloud-sleuth
management:
metrics:
web:
server:
autoTimeRequests: false
启动成功的界面如下:
4. Sleuth微服务整合Zipkin
在微服务中引入依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
在yml中添加配置
spring:
application:
name: service-provider-course
zipkin:
base-url: http://localhost:9411 #指定Zipkin server地址
sleuth:
sampler:
probability: 1.0 #request采样的数量 默认是0.1 也即是10% 顾名思义 采取10%的请求数据 因为在分布式系统中,数据量可能会非常大,因此采样非常重要。我们示例数据少最好配置为1全采样
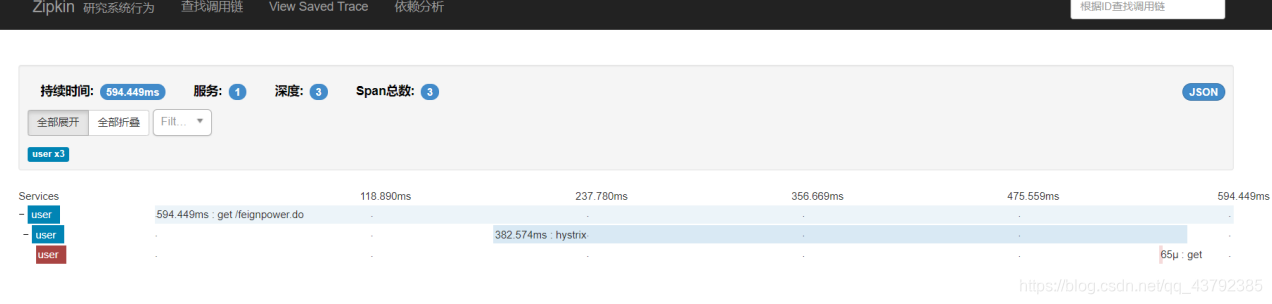
启动微服务,并调用
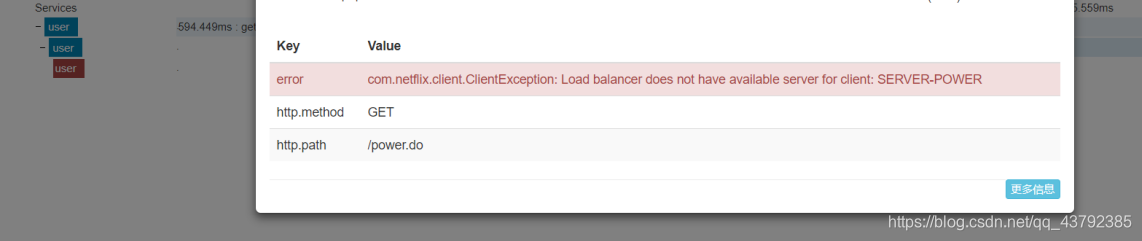
5. Zipkin Server 数据持久化
刚刚我们介绍了如何把分布式链路调用信息上传到 zipkin server 但是 有一个问题:
当zipkin重启后我们的分布式链路数据全部清空了。因为zipkin server 默认数据是存储在内存当中, 所以当你服务重启之后内存自然而然也就清空了。
Zipkin提供了可插拔数据存储方式:In-Memory、MySql、Cassandra以及Elasticsearch。接下来的测试为方便直接采用In-Memory方式进行存储,生产推荐Elasticsearch。
Zipkin 与 Elasticsearch整合关于Elasticsearch的基本概念和入门请参考之前的博文:全文检索-Elasticsearch、Docker搭建Elasticsearch集群、整合Springboot。
首先 我们在我们的zipkin server里面引入依赖:
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-autoconfigure-storage-elasticsearch-http</artifactId>
<version>2.3.1</version>
</dependency>
然后修改server配置文件如下(添加Elasticsearch配置):
server:
port: 9411
spring:
application:
name: springcloud-sleuth
management:
metrics:
web:
server:
autoTimeRequests: false
zipkin:
storage:
type: elasticsearch
elasticsearch:
cluster: springcloud
hosts: http://localhost:9200
index: zipkin
现在再启动Zipkin Server 并且存储的数据就在Elasticsearch中了,即使重启ZIPkin也不会丢失调用链数据。源码地址:https://github.com/qqxhb/springcloud-demo。
