1.XML的学习
1)XML的基本概念
- XML的设计宗旨是传输数据和存储数据,而不是显示数据,与之相对应的是HTML,它被设计来显示数据。
- XML的解析:常见的解析方式有:DOM,DOM4J,SAX
其中:DOM和DOM4J是一次将要解析的XML文件读取到内存中,然后解析,而SAX是边读边解析,适用于解析大的XML文件。
2.使用DOM4J解析XML的过程:
第一步:创建解析器
SAXReader reader = new SAXReader();
第二步:通过解析器read()方法获取Document对象
Document doc = reader.read("student.xml");
第三步:获取xml根节点
Element root = doc.getRootElement();
第四步:遍历解析子节点
第五步:再进行一次遍历,获取每个元素
示例:
<students> <student> <name>吴飞</name> <college>Java学院</college> <telephone>623546666</telephone> <notes>男,1982,硕士,北京邮电</notes> </student> <student> <name>李雪</name> <college>C++学院</college> <telephone>62358888</telephone> <notes>男,1987,硕士,中国农业</notes> </student> <student> <name>Java</name> <college>PHP学院</college> <telephone>6666666</telephone> <notes>澳洲</notes> </student> </students>解析的代码:
public class Dom4jTest {
public static void main(String[] args){
try {
//第一步创建解析器
SAXReader reader = new SAXReader();
//通过解析器都read方法将配置文件读取到内存中,生成一个Document[org.dom4j]对象树
Document document = reader.read("Conf/students.xml");
//获取根节点
Element root = document.getRootElement();
//开始遍历根节点
Iterator<Element> rootIter = root.elementIterator();
while(rootIter.hasNext()){
Element studentElt = rootIter.next();
Iterator<Element> iterator = studentElt.elementIterator();
while(iterator.hasNext()){
Element innerElt = iterator.next();
String innerValue = innerElt.getStringValue();
System.out.println(innerValue);
}
System.out.println("-------------");
}
} catch (DocumentException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}输出:
吴飞 Java学院 623546666 男,1982,硕士,北京邮电 --------------- 李雪 C++学院 62358888 男,1987,硕士,中国农业 --------------- Java PHP学院 6666666 澳洲 ---------------
3.使用SAX解析方式
SAX解析的步骤:
1)创建解析工厂——通过newInstance()方法获取
SAXParserFactory saxParserFactory =SAXParserFactory.newInstance();
2)通过解析工厂创建解析器
SAXParser saxParse =saxParserFactory.newSAXParser();
3)执行parser方法,传入两个参数:xml文件路径和事件处理器
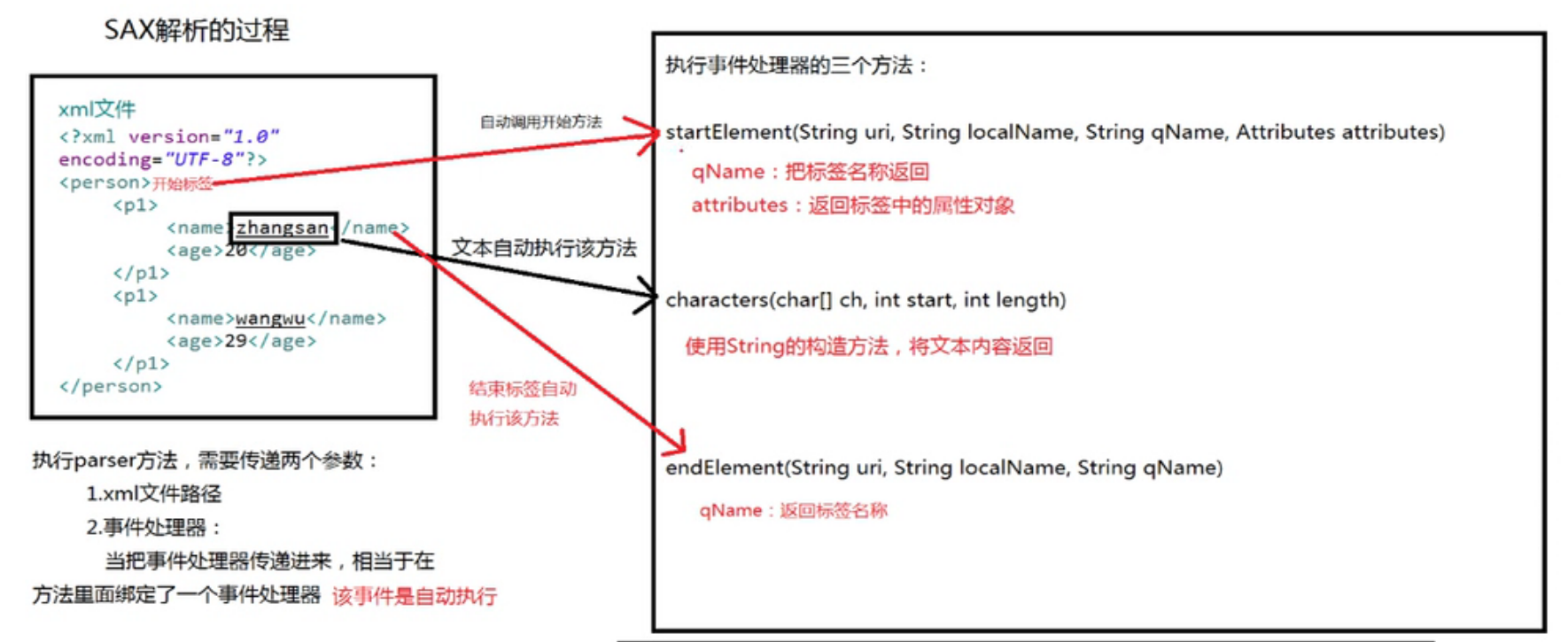
<person> <per> <name>小明</name> <age>20</age> </per> <per> <name>吴飞</name> <age>29</age> </per> </person>测试代码:
public class MySAX {
public static void main(String[] args) throws IOException{
try {
//创建解析工厂
SAXParserFactory saxParserFactory = SAXParserFactory.newInstance();
//创建解析器
SAXParser saxParser = saxParserFactory.newSAXParser();
//通过解析器的parse方法
saxParser.parse("Conf/person.xml", new MyHandler());
} catch (ParserConfigurationException | SAXException e) {
e.printStackTrace();
}
}
}
class MyHandler extends DefaultHandler{
private String nodeName;
private StringBuilder name;
private StringBuilder age;
//接收文档开始时的通知
public void startDocument() throws SAXException{
name = new StringBuilder();
age = new StringBuilder();
}
//接收元素开始的通知
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
nodeName = qName;
}
//接收元素中字符数据的通知
public void characters(char[] ch, int start, int length) throws SAXException {
if("name".equals(nodeName)){
name.append(ch,start,length);
}
else if("age".equals(nodeName)){
age.append(ch,start,length);
}
}
//接收元素结束的通知
public void endElement(String uri, String localName, String qName) throws SAXException {
if("per".equals(qName)){
System.out.println("name: "+name.toString().trim());
System.out.println("age: "+age.toString().trim());
name.setLength(0); //清空StringBuilder
age.setLength(0);
}
}
}
结果输出
name: 小明 age: 20 name: 吴飞 age: 29说明:trim()函数的用法,因为解析过程中一些换行符页被当做内容解析出来。