一、流程步骤
HelloWorld Scrapy
- 创建一个工程
- scrapy startproject XXX
- 创建一个爬虫
- scrapy genspider YYY domain
- domain 爬取主站地址
- scrapy genspider YYY domain
- 运行爬虫
- scrapy crawl YYY
- 完善爬虫
- 定向获取内容
- parse函数
- 参数 response
- response
- xpath
- 写规则就可以
- 会返回提取好的内容
- Selector
- get 获取内容
- extract
- extract_all
- Selector
- re
- css
二、代码操作:
1下载:
- xpath
pip install scrapy
2.终端创建项目ZhouWu
scrapy startproject ZhouWu
3.pycharm打开项目,配置虚拟环境,生成爬虫文件;爬取http://lab.scrapyd.cn/这个网站,执行命令后会生成lab.py文件;
scrapy genspider lab lab.scrapyd.cn
4.运行此蜘蛛文件
scrapy crawl lab
5.scrapy项目架构原理解析:
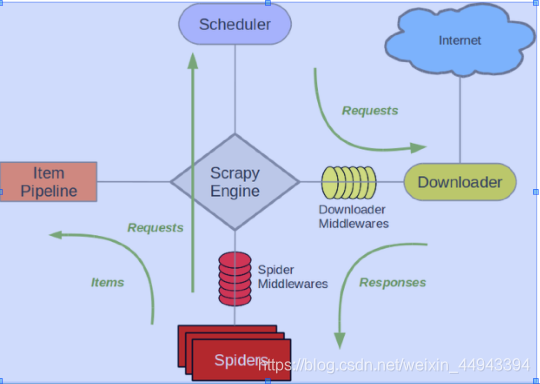
爬取流程:在Spiders中编写爬虫,把开始的地址配置好,会交给Scheduler调度器,Scheduler从请求队列中拿出调度器,把Requests发出去,Requests对应互联网资源,给Downloader下载器把资源变成Response,回到Spiders中,Spiders想存,可以通过ItemPipeline;
6.lab.py爬取下一页:
# -*- coding: utf-8 -*-
import scrapy
class LabSpider(scrapy.Spider):
name = 'lab'
allowed_domains = ['lab.scrapyd.cn']
start_urls = ['http://lab.scrapyd.cn/']
def parse(self, response):
#写xpth规则,选择你要的内容,这里是详情、作者、标题那一整块内容;
quote_posts = response.xpath('//div[contains(@class, "quote post")]')
#把整块div里遍历,取出来标题、作者、和详情
for quote_post in quote_posts:
text = quote_post.xpath('./span[contains(@class, "text")]/text()').get()
author = quote_post.xpath('./span/small[contains(@class, "author")]/text()').get()
detail = quote_post.xpath('./span/a/@href').get()
print(text,author,detail)
next_url = response.xpath('//li[contains(@class, "next")]/a/@href').get()
print(next_url)
if next_url:
# # 构建一个请求 # url 是爬取的链接, callback是回调函数,请求结束后将结果通过parse函数传递回来
yield scrapy.Request(url=next_url, callback=self.parse)
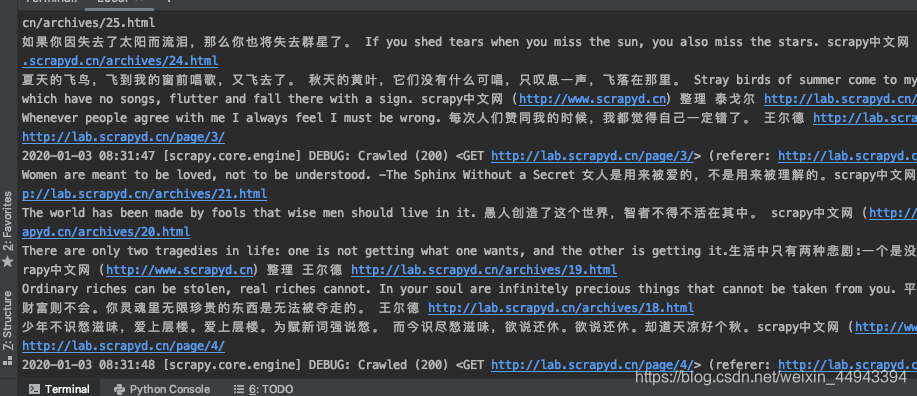
7.现在是可以拿出来,要考虑怎么存储:
items.py:
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class ZhouwuItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
#自己写的如下比着系统给的文件写:
class LabItem(scrapy.Item):
text = scrapy.Field()
author = scrapy.Field()
detail = scrapy.Field()
- lab.py,爬取详情页:
# -*- coding: utf-8 -*-
import scrapy
from ZhouWu.items import LabItem
class LabSpider(scrapy.Spider):
name = 'lab'
allowed_domains = ['lab.scrapyd.cn']
start_urls = ['http://lab.scrapyd.cn/']
def parse(self, response):
#写xpth规则,选择你要的内容,这里是详情、作者、标题那一整块内容;
quote_posts = response.xpath('//div[contains(@class, "quote post")]')
#把整块div里遍历,取出来标题、作者、和详情
for quote_post in quote_posts:
text = quote_post.xpath('./span[contains(@class, "text")]/text()').get()
author = quote_post.xpath('./span/small[contains(@class, "author")]/text()').get()
detail = quote_post.xpath('./span/a/@href').get()
print(text,author,detail)
#在items中写好后,在这里进行存,使用yield;
item = LabItem()
item['text'] = text
item['author'] = author
item['detail'] = detail
yield item
next_url = response.xpath('//li[contains(@class, "next")]/a/@href').get()
print(next_url)
if next_url:
# # 构建一个请求 # url 是爬取的链接, callback是回调函数,请求结束后将结果通过parse函数传递回来
yield scrapy.Request(url=next_url, callback=self.parse)
callback:会将结果封装到函数的参数中;
9.执行命令
scrapy crawl lab -o labs.csv
会发现出现了一个labs.csv文件;我们的内容存放砸这个文件里了;
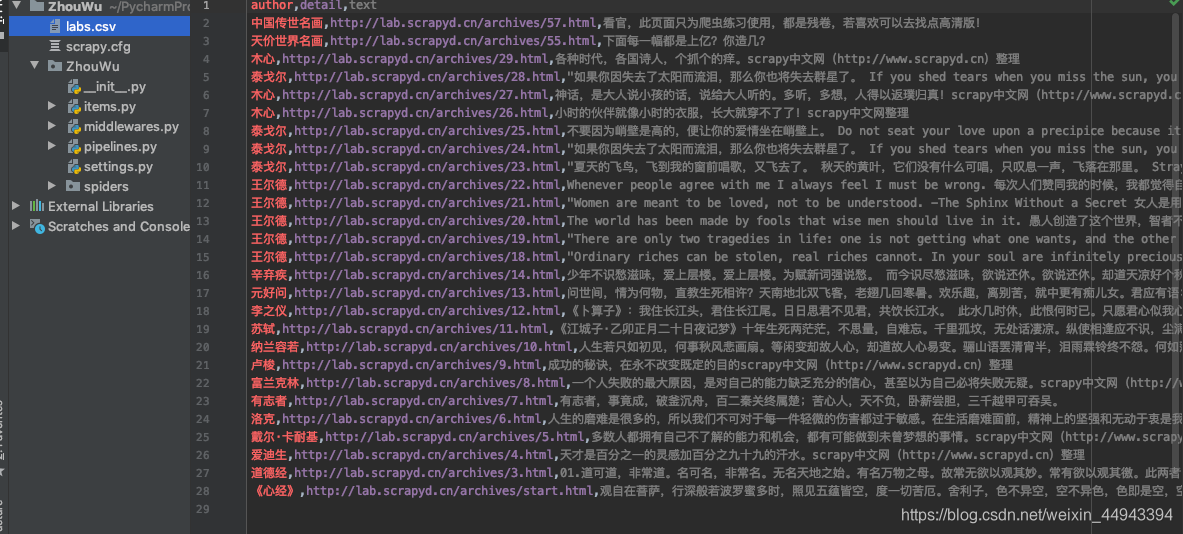
也可以json格式:执行:scrapy crawl lab -o labs.csv
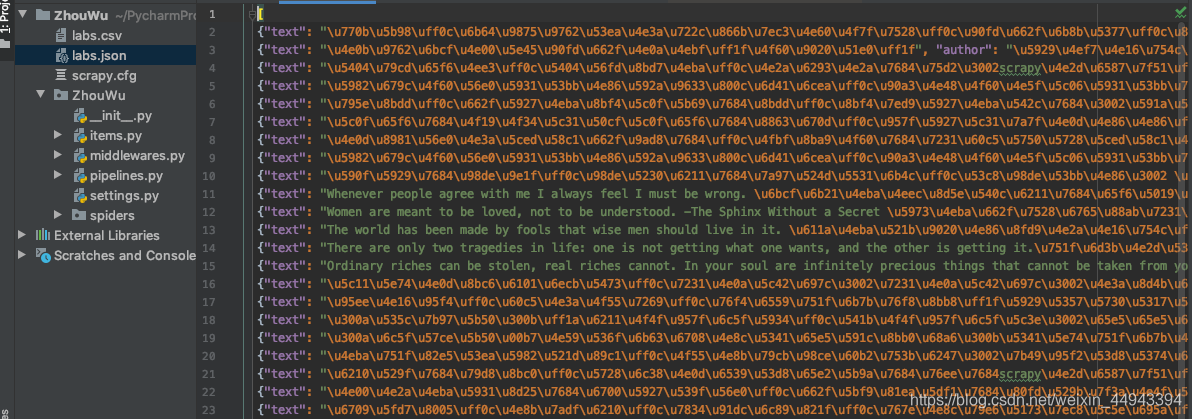
10.我们看到存取的文件是编码格式,如果变成汉字,在settings.py中添加:
FEED_EXPORT_ENCODING = "utf-8"
把原来的labs.json文件删掉,再次运行, scrapy crawl lab -o labs.json,内容会出现中文;

11.数据存储到mysql数据库中:pipelines.py
未完待续
