字符串匹配-有限自动机
本文内容与《算法导论》中字符串匹配章节相关并部分摘录。
常用的字符串匹配算法有朴素字符串匹配算法,Rabin-Karp算法,利用有限自动机进行字符串匹配和KMP算法等。前面两种比较简单,重点是后面两种
利用有限自动机进行字符串匹配
假设要对文本字符串T进行扫描,找出模式P的所有出现位置。这个方法可以通过一些办法先对模式P进行预处理,然后只需要对T的每个文本字符检查一次,并且检查每个文本字符所用时间为常数,所以在预处理建好自动机之后进行匹配所需时间只是Θ(n)。
假设文本长度为n,模式长度为m,则自动机将会有0,1,…,m这么多种状态,并且初始状态为0。先抛开自动机是怎样计算出来的细节,只关注自动机的作用。在从文本从左到右扫描时,对于每一个字符a,根据自动机当前的状态还有a的值可以找出自动机的下一个状态,这样一直扫描下去,并且一定自动机状态值变为m的时候我们就可以认为成功进行了一次匹配。先看下面简单的例子:
假设现在文本和模式只有三种字符a,b,c,已经文本T为"abababaca",模式P为"ababaca",根据模式P建立自动机如下图(b)(先不管实现细节):

图为一些状态转化细节:
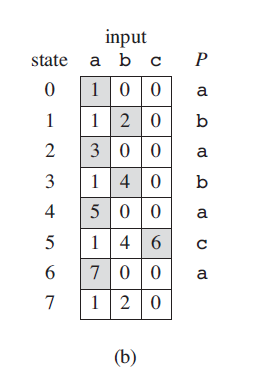

如图©,对照自动机转换图(b),一个个的扫描文本字符,扫描前状态值初始化为0,这样在i = 9的时候状态值刚好变成7 = m,所以完成一个匹配。
现在问题只剩下怎样根据给出的模式P计算出相应的一个自动机了。这个过程实际上并没有那么困难,下面只是介绍自动机的构建,而详细的证明过程可以参考书本。
还是用上面的那里例子,建立模式P = “ababaca"的有限自动机。首先需要明白一点,如果当前的状态值为k,其实说明当前文本的后缀与模式的前缀的最大匹配长度为k,这时读进下一个文本字符,即使该字符匹配,状态值最多变成k + 1.假设当前状态值为5,说明文本当前位置的最后5位为"ababa”,等于模式的前5位。
如果下一位文本字符是"c",则状态值就可以更新为6.如果下一位是"a",这时我们需要重新找到文本后缀与模式前缀的最大匹配长度。简单的寻找方法可以是令k = 6(状态值最大的情况),判断文本后k位与模式前k位是否相等,不等的话就k = k - 1继续找。由于刚才文本后5位"ababa"其实就是模式的前5位,所以实际上构建自动机时不需要用到文本。这样可以找到这种情况状态值将变为1(只有a一位相等)。同理可以算出下一位是"b"时状态值该变为4(模式前4位"abab"等于"ababab"的后缀)
下面是书本伪代码:∑代表字符集,δ(q,a)可以理解为读到加进字符a后的状态值

用上面的方法计算自动机,如果字符种数为k,则建立自动机预处理的时间是O(m ^ 3 * k),有方法可以将时间改进为O(m * k)。预处理完后需要Θ(n)的处理时间。
欢迎各位指正与交流!
