Centos6.5hadoop伪分布式搭建
1.准备工作:
虚拟机(安装linux系统);
JDK:
链接: https://pan.baidu.com/s/1uTasi6Pal8Im2lOtFTzuPw 提取码: b45h
Hadoop:
链接: https://pan.baidu.com/s/1Lz–btjXyA4PfmkWRQTZDg 提取码: s2yd
Xshell软件:
链接:链接: https://pan.baidu.com/s/1QMmuJmy_PIZNJRXx978xJw 提取码: qrg9
Xftp软件:
链接: https://pan.baidu.com/s/1aVzhAdu4BcwTpFDWseUYXw 提取码: qknb
2.配置虚拟机网络IP:
命令: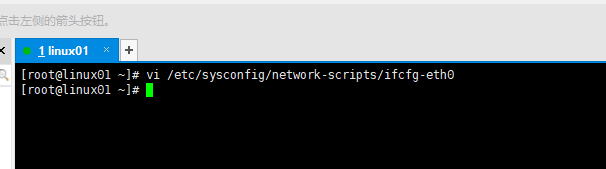
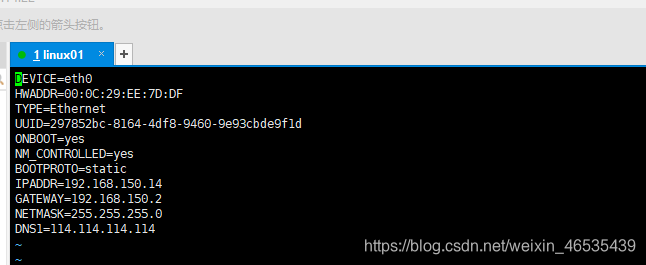
DEVICE=eth0
ONBOOT=yes
BOOTPROTO=static
IPADDR=192.168.150.14(IP)
GATEWAY=192.168.150.2(网关)
NETMASK=255.255.255.0
DNS1=114.114.114.114
3.Wmware软件的网络配置: 看NET模式的网段是否是100的网段;
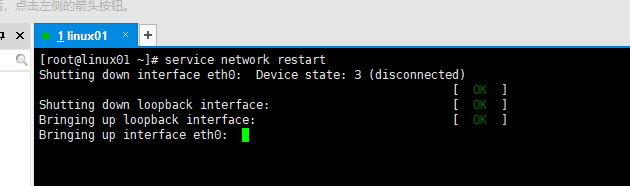
配置完成以后重启网络;
service network restart
4.使用XShell连接虚拟机:新建:
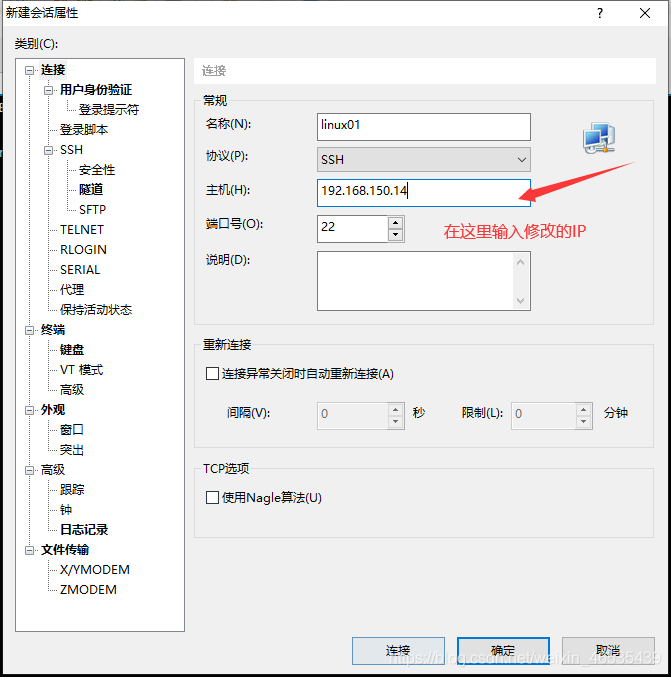
用户名为:root
密码:123456(注意:密码为自己设置的密码)

出现这个表示连接成功!
5关闭防火墙:
目的:让外界可以访问该虚拟机
命令:
- service iptables stop
- chkconfig iptables off
6.JDK:
-
通过xftp软件,从windows系统将JDK安装包上传至Linux系统;
上传到/opt/software/目录下(该目录需要创建) -
解压JDK到/opt/app/目录下(该目录需要创建)
root@node1 tools]# tar -zxvf jdk-8u192-linux-x64.tar.gz -C /opt/app -
查看JDK是否解压成功:切换到/opt/app/目录下,查看是否有JDK目录(该目录需要创建)
7.配置JDK的环境变量:
vim /etc/profile
在文件最下面添加内容:
export JAVA_HOME=/opt/app/jdk
export PATH=$PATH:$JAVA_HOME/bin
生效环境变量:
source /etc/profile
检查是否配置成功:
javac
java
java -version
8.安装Hadoop:
-
通过xftp软件,从windows系统将Hadoop安装包上传至Linux系统;
上传到/opt/software/目录下(该目录需要创建) -
解压Hadoop解压到/opt/app/目录下(该目录需要创建);
[root@linux01 software]# tar -zxvf hadoop-2.8.5.tar.gz -C /opt/app/ -
检查是否解压成功:
切换到/opt/app/目录下,查看是否有hadoop目录
9.配置hadoop的环境变量:
vim /etc/profile
在文件最下面添加内容:
export HADOOP_HOME=/opt/app/hadoop-2.8.5
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
生效环境变量:
source /etc/profile
检查是否配置成功:
hadoop version
10.配置hadoop配置文件:
切换到(/opt/app/hadoop-2.8.5/etc/hadoop : hadoop配置文件所在目录)
-
hadoop-env.sh
export JAVA_HOME=/opt/app/jdk1.8.0_192 -
core-site.xml
<configuration>
<!--配置HDFS访问入口-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:9000</value>
</property>
</configuration>
- hdfs-site.xml
<configuration>
<!--设置datanode上的数据副本数-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
- mapred-site.xml
<configuration>
<!-- 指定mr运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
- yarn-site.xml
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
</property>
11.格式化hdfs集群:
hdfs namenode -format
12.启动集群:
start-all.sh
13.查看进程是否启动:
jps
jps
namenode
datanode
secondarynamenode
resourcemanager
nodemanager
14.通过浏览器访问:8080端口
http://192.168.150.14:8080
