打卡学习JVM,第十天
本人学习过程中所整理的代码,源码地址
内存分配

- 堆上分配
- 大多数情况在Eden上分配,偶尔会直接在old上分配
- 细节取决于GC的实现
- 栈上分配
- 原子类型的局部变量
内存回收
GC要做的就是将那些dead的对象所占用的内存回收掉
- Hotspot认为没有引用的对象是dead的
- Hotspot将引用分为四种:Strong(默认通过Object obj = new Object()这种方式赋值的引用)和Soft、Weak、Phantom(都继承了Reference)
在Full GC时会对Reference类型的引用进行特殊处理
- Soft:内存不够时或者长期不用时一定会被GC
- Weak:一定会被GC,当被mark为dead,会在ReferenceQueue中通知
- Phantom:本来就没引用,当从JVM堆中释放时会通知
GC的时机
在分代模型的基础上,GC从时机上 分为两种:MinorGC和Full GC
- Minor GC
- 触发时机:新对象生产时,Eden空间满了
- 理论上Eden区大多数对象会在Minor GC回收,复制算法的执行效率会很高,Minor GC时间比较短
- Full GC
- 对整个JVM进行整理,包括新生代,老年代,永久代
- 主要触发时机:1)老年代满了 2)永久代满了 3)System.gc()
- 效率很低,尽量减少Full GC
GC要做的就是将那些dead的对象所占用的内存回收掉
- Hotspot认为没有引用的对象是dead的
- Hotspot将引用分为四种:Strong(默认通过Object obj = new Object()这种方式赋值的引用)和Soft、Weak、Phantom(都继承了Reference)
在Full GC时会对Reference类型的引用进行特殊处理
- Soft:内存不够时或者长期不用时一定会被GC
- Weak:一定会被GC,当被mark为dead,会在ReferenceQueue中通知
- Phantom:本来就没引用,当从JVM堆中释放时会通知
垃圾回收器
- 分代模型:GC的宏观愿景
- 垃圾回收器:GC的具体实现
- Hotspot JVM提供多种垃圾回收器,需要根据具体应用的需要采用不同的垃圾回收器
- 没有万能的垃圾回收器
- 垃圾回收器的“并行”和“并发”
- 并行(Parallel):指多个收集器的线程同时工作,但是用户线程处于等待状态
- 并发(Concurrent):指收集器在工作的同时可以允许用户线程工作
并发不代表解决了GC停顿的问题,在关键的步骤还是要停顿。比如在收集器标记垃圾的时候。但在清理垃圾的时候,用户线程可以和GC线程并发执行
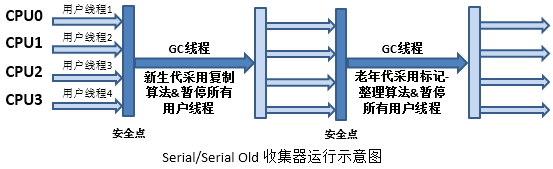
- Serial收集器
- 最早的收集器单线程收集器,没有多线程切换的额外开销,简单实用,收集时会暂停所有工作线程(Stop The World,STW),虚拟机运行在Client模式时的默认新生代收集器
- 在新生代采用复制算法,在老年代采用标记-整理算法
- Hotspot Client模式缺省的收集器
- ParNew收集器
- Serial的多线程版本
- 对应的这种收集器是虚拟机运行在Server模式的默认新生代收集器,在单CPU的环境中性能和Serial收集器差不多
- 使用复制算法
- 可以通过-XX:ParallelGCThreads来控制GC线程数的多少,需要结合具体CPU的个数
- Server模式下新生代的缺省收集器

- Parallel Scavenge收集器
Parallel Scavenge 收集器是以吞吐量最大化(即GC时间占总运行时间最小)为目标的收集器实现,它允许较长时间的STW换取总吞吐量最大化
- Serial Old收集器
Serial Old是单线程收集器,使用标记-整理算法,是老年代的收集器
- Parallel Old收集器
老年代版本吞吐量优先收集器,使用多线程和标记-整理算法
- Parallel Scavenge在老年代的实现
- 在JVM1.6才出现
- 采用多线程,标记-整理算法
- 更注重吞吐量
- Parallel Scavenge + Parallel Old = 高吞吐量,但GC停顿可能不理想

- CMS(Concurrent Mark Sweep)收集器
CMS是一种以最短停顿时间为目标的收集器,使用CMS并不能达到GC效率最高(总体GC时间最小),但它能尽可能降低GC时服务的停顿时间,CMS收集器使用的是标记-清除算法
- 追求最短停顿时间,非常适合Web应用
- 只针对老年代,一般结合ParNew使用
- GC线程与用户线程尽量并发工作
- 标记-清除算法
- 多CPU环境下才有意义
- 使用-XX:+UseConcMarkSweepGC打开
- 缺点:以牺牲CPU资源的代价来减少用户线程的停顿;CMS并发清理过程中,由于用户线程还在允许,因此需要预留一部分空间给用户线程;碎片化问题

Java内存泄漏的经典原因
- 对象定义在错误的范围(Wrong Scope)
- 如果Foo实例对象的生命较长,会导致临时性内存泄漏(这里的names变量其实只有临时作用)
class Foo {
private String[] names;
public void doIt(int length) {
if (names == null || names.length < length) {
names = new String[length];
populate(names);
System.out.println(names);
}
}
}
- JVM喜欢生命周期短的对象,这样做已经足够高效
class Foo {
public void doIt(int length) {
String[] names = new String[length];
populate(names);
System.out.println(names);
}
}
- 异常(Exception)处理不当
Connection conn = DriverManager.getConnection(url,name,pwd);
try {
String sql = "do a query sql";
PreparedStatement stmt = conn.prepareStatement(sql);
ResultSet rs = stmt.executeQuery();
while (rs.next()){
doSomeStuff();
}
rs.close();
conn.close();
}catch (Exception e){
}
如果doSomeStuff()方法抛出异常,rs.close()和conn.close()不会被调用,因此会导致内存泄漏和数据库连接泄漏
- 集合数据管理不当
- 当使用基于数组的数据结构(ArrayList,HashMap等)时,尽量减少resize
- 如果一个List只需要顺序访问,不需要随机访问,用LinkedList代替ArrayList,前者本质是链表,不需要resize
GC垃圾收集器的JVM参数定义


