Pandas文件操作之与mysql数据库的交互
先导入必要的模块
- panads
- pymysql
- sqlalchemy
如果没有安装的pymysql和sqlalchemy可以直接pip install pymysql即可。
然后你必须有自己的数据库并且要运行起来才能链接成功。
windows下载mysql的安装:https://blog.csdn.net/qq_20788055/article/details/80372577
连入数据库:
# 导入必要模块
import pandas as pd
import pymysql
from sqlalchemy import create_engine
#初始化数据库连接
#用户名root 密码 端口 3306 数据库 test 这里是你自己的数据名称
engine = create_engine('mysql+pymysql://root:123456@localhost:3306/test')
#查询语句
sql = '''
select * from jianlai;
'''
# 这里我的test数据库下有一个jianlai的表
#两个参数 sql语句 数据库连接
df = pd.read_sql(sql,engine)
df
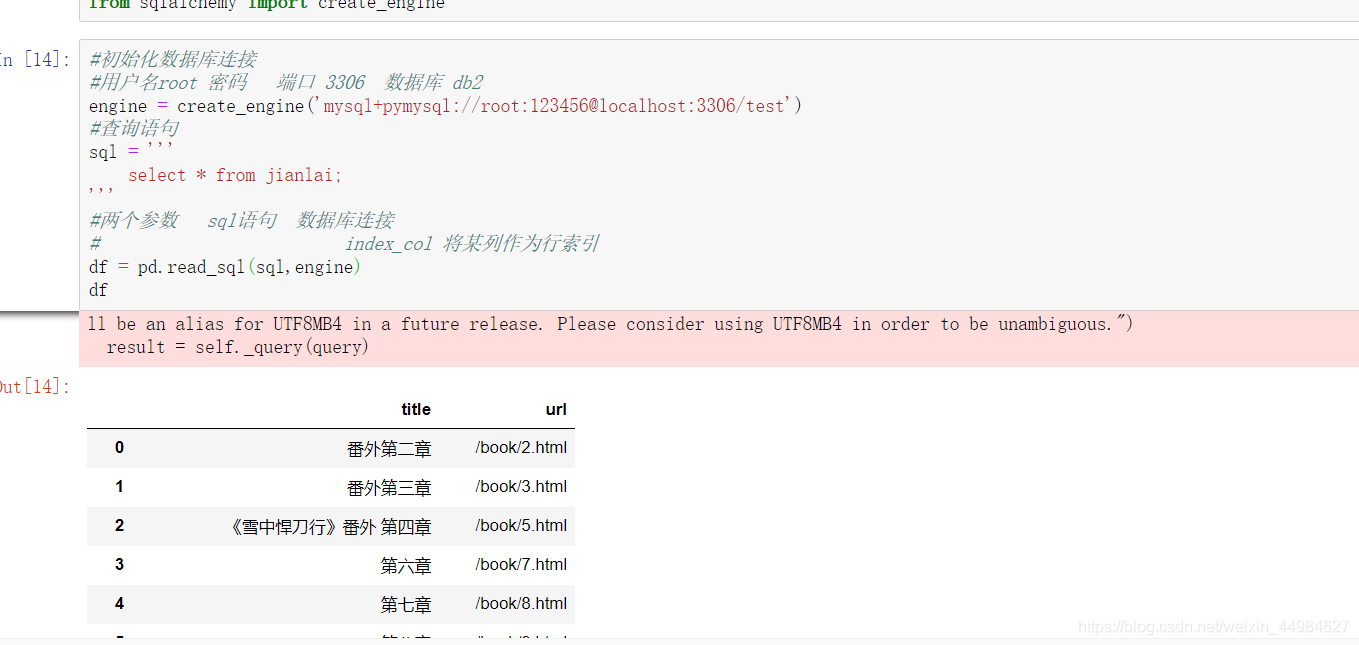
以上为演示连入数据库,并在jupyter notebook 中读入数据库中的表中的数据以dataframe显示。
下面我们进行把dataframe写入到数据库中的演示:
#新建
df = pd.DataFrame({'id':[1,2,3,4],'num':[34,56,78,90]})
df
id num
0 1 34
1 2 56
2 3 78
3 4 90
# #写入到数据库
# 写入到数据库中的test数据库种 并创建一个df4的表 把df写入
# index默认为True 会将索引也一并写入 如果我们不想写入索引可以设置
# 其为Fales
df.to_sql('df4',engine,index=False)
# 如果数据库写入成功则运行下代码
# 主要是为了测试上方代码是否报错
print("ok")

以上:我们就对数据库进行了操作,python提供了很简单方便的操作方法与方式。
