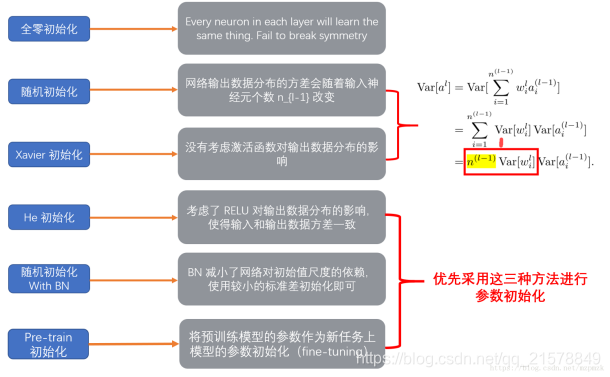
模型权重的初始化对于网络的训练很重要, 不好的初始化参数会导致梯度传播问题, 降低训练速度; 而好的初始化参数, 能够加速收敛, 并且更可能找到较优解。
- 六种权重初始化
一、W初始化为0
在线性回归和logistics回归中可以使用,因为隐藏层只有一层。在超过一层的神经网络中就不能够使用了。因此如果所有的权重参数都为0,那么所有的神经元输出都是一样的,在back propagation的时候向后传递的梯度也是一致的,将无法发挥多层的效果,实际上相当于一层隐藏层。
二、W高斯随机初始化
我们来分析一层卷积:
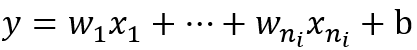
其中ni表示输入个数。
那么方差为下面这个公式:
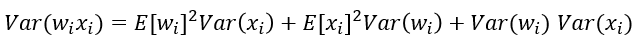
在前向网络中,W*X,如果W初始化为一个小于1的值,在训练过程中会导致会出现梯度弥散的情况,高层的神经元方差和均值趋于0,从而不被激活。但是如果把权重初始成一个比较大的值,大于1。则会造成前向传播时,神经元要么被抑制,要么被饱和。梯度更新时,也会出现梯度弥散。
三、Xavier初始化
- 核心思想:保证每层的权重的方差和均值一致。
- 每层的权重初始化公式如下:
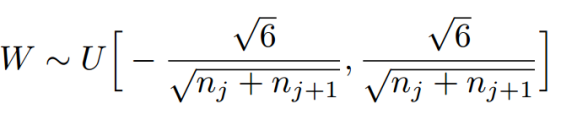
上式为一个均匀分布,n_j为输入层的参数,n_(j+1)为输出层的参数 - 推导环节-前向
该公式的推导是以激活函数为tanh,假设有随机变量x和w,它们都服从均值为0,方差为sigma的分布。
上面介绍了卷积层方差满足的公式为:
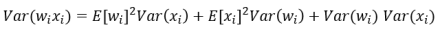
根据x和w的均值为0,可简化为:
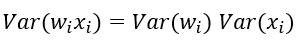
接下来要保证方差一致,则有:
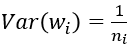
n_i表示输入参数的数量。 - 推导环节-后向
前向的过程可以简化如下:
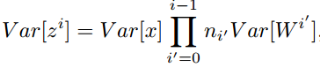
同样的,后向的过程也有类似的表示:
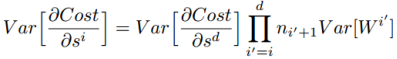
上式可以这样表示,是因为均值为0,tanh在0这里近似为线性的,导数为1。
由上式易知,为了使每一层数据的方差保持一致,则权重也应满足:
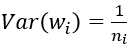
此时n_i表示输出参数的数量。
综上为:
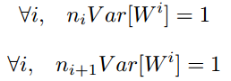
综合考虑,合并在一起为:
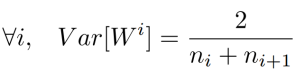
四、MSRA初始化
- 核心思想:Xavier初始化没有考虑激活函数,在某些非线性激活函数上表现不好(大部分激活函数都是有效的),如Relu。因此针对Relu推导了一次,与上面过程类似,只是方差要除以2。
- 每层的权重初始化公式如下:
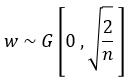
为一个均值为0方差为2/n的高斯分布。 - 推导过程
推导类似,只展示不同的地方:
方差计算时,需要多除以2:

f为relu激活函数
为了使每一层数据的方差保持一致,则权重应满足:
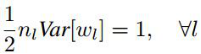
反向传递过程类似,不在重复。反向传递是,会出现初始化参数不一致的情况,如正向是输入参数,反向是输出参数,实验证明中输入或输出参数都是有效的。 - 缺陷:
1、从方差的公式中我们知道,x_i是前一层输出经过激活函数得到的值,而relu将x中原本的负项都置零了,因此均值严格说,不能为0。
2、MSRA方法只考虑一个方向,无法使得正向反向传播时方差变化都很小。
五、高斯随机初始化+BN
- BN归一化输入如下所示:

Batch Normalization中所有的操作都是平滑可导,这使得back propagation可以有效运行并学到相应的参数γ,β。需要注意的一点是Batch Normalization在training和testing时行为有所差别。Training时μβ和σβ由当前batch计算得出;在Testing时μβ和σβ应使用Training时保存的均值或类似的经过处理的值,而不是由当前batch计算。
六、pre-training
在实际训练中,我们可以选择一个backbone网络,在其基础上做改动。该网络如果有一个已经训练好的在任务A上的模型(称为pre-trained model),可以直接将其放在任务B上做模型调整(称为fine-tuning)。
参考来源
