文章目录
Scala函数
函数的类型和值
函数字面量:literal
函数字面量可以体现函数是编程的核心理念,在函数式编程中,函数是“头等公民”,可以向其他数据类型一样被传递和操作,也就是说,函数的使用方式和其他数据类型的使用方式完全一致。
这是,我们就可以像定义变量那样去定义一个函数,由此导致的结果是,函数也会和其他变量一样,可以有“值”。就像变量的“类型”和“值”是分开的两个概念一样,函数式编程中,函数的“类型”和“值”也成为了两个分开的概念,函数的“值”,就是“函数字面量”
def counter(value: Int): Int = { value+=1}
函数的类型:
(Int) => Int //若输入值只有一个,则可省略括号
函数的值
(value) => {value+=1} //只有一条语句时,大括号可以省略
按照上面类似的形式来定义Scala中的函数
无法执行,value不可被赋值。参考匿名函数。
val counter: Int => Int = { (value) => value += 1}
占位符语法
为了让函数字面量更加简洁,我们可以使用下划线作为一个或多个参数的占位符,只要每个参数在函数字面量内仅出现一次。
x => x > 0 与 _ > 0等价
可以通过冒号指定占位符的类型
val f = (_: Int) + (_: Int)
Scala函数传名调用
scala的解释器在解析函数参数时有两种方式:
- 传值调用:先计算参数表达式的值,在应用到函数内部
- 传名调用:将为计算的参数表达式直接应用到函数内部,每次使用传名调用时,解释器都会计算一次表达式的值。
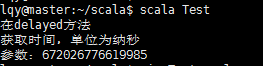
object Test {
def main(args: Array[String]) {
delayed(time());
}
def time() = {
println("获取时间,单位为纳秒")
System.nanoTime
}
def delayed( t: => Long ) = {
println("在 delayed 方法内")
println("参数: " + t)
}
}
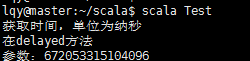
def deplayed(t: => Long) 改为 def deplayed(t: Long)
1.2 Scala指定函数参数名
一般情况下函数调用参数,就按照函数定义时的参数顺序一个个传递。但是我们可以通过指定函数参数名,并且不需要按照顺序向函数传递参数。
1.3 Scala函数-可变参数
Scala允许知名函数的最后一个参数时可以重复的,即我们不需要指定函数参数的个数,可以向函数传入可变长度参数列表。
Scala通过在参数的类型之后放一个星号来设置可变参数。
object Test {
def main(args: Array[String]) {
printStrings("Runoob", "Scala", "Python");
}
def printStrings( args:String* ) = {
var i : Int = 0;
for( arg <- args ){
println("Arg value[" + i + "] = " + arg );
i = i + 1;
}
}
}
1.4 Scala函数-默认参数值
Scala可以为函数参数指定more参数值,使用了默认参数,在调用函数的过程中可以不需要传递参数,这时函数就会调用它的默认参数值,如果传递了参数,则传递值会取代默认值。

object Test {
def main(args: Array[String]) {
println( "返回值 : " + addInt() );
}
def addInt( a:Int=5, b:Int=7 ) : Int = {
var sum:Int = 0
sum = a + b
return sum
}
}
1.5 Scala高阶函数
高阶函数就是操作其他函数的函数。
Scala中允许使用高阶函数,高阶函数可以使用其他函数作为参数,或者使用函数作为输出结果。
object Test {
def main(args: Array[String]) {
println( apply( layout, 10) )
}
// 函数 f 和 值 v 作为参数,而函数 f 又调用了参数 v
def apply(f: Int => String, v: Int) = f(v)
def layout[A](x: A) = "[" + x.toString() + "]"
}
1.6 Scala函数嵌套
我们可以在 Scala 函数内定义函数,定义在函数内的函数称之为局部函数。
以下实例我们实现阶乘运算,并使用内嵌函数:
object Test {
def main(args: Array[String]) {
println( factorial(0) )
println( factorial(1) )
println( factorial(2) )
println( factorial(3) )
}
def factorial(i: Int): Int = {
def fact(i: Int, accumulator: Int): Int = {
if (i <= 1)
accumulator
else
fact(i - 1, i * accumulator)
}
fact(i, 1)
}
}
1.7 Scala匿名函数
Scala 中定义匿名函数的语法很简单,箭头左边是参数列表,右边是函数体。
使用匿名函数后,我们的代码变得更简洁了。
var inc = (x:Int) => x+1
是以下这种写法的简写:
def add2 = new Function1[Int,Int]{
def apply(x:Int):Int = x+1;
}
使用方式:
var x = inc(7)-1
直接将匿名函数作为函数字面量
//可以将Int=>Int 省略,或者将num: Int的Int省略,只要系统能推断出值的类型
scala> val myNumFunc : Int=>Int = (num: Int) => num * 2
myNumFunc: Int => Int = $$Lambda$1080/1037793103@2582b0ef
scala> println(myNumFunc(3))
6
1.8 Scala偏应用函数
Scala 偏应用函数是一种表达式,你不需要提供函数需要的所有参数,只需要提供部分,或不提供所需参数。
import java.util.Date
object Test {
def main(args: Array[String]) {
val date = new Date
val logWithDateBound = log(date, _ : String)
logWithDateBound("message1" )
Thread.sleep(1000)
logWithDateBound("message2" )
Thread.sleep(1000)
logWithDateBound("message3" )
}
def log(date: Date, message: String) = {
println(date + "----" + message)
}
}
1.9 Scala 函数柯里化(Currying)
柯里化(Currying)指的是将原来接受两个参数的函数变成新的接受一个参数的函数的过程。新的函数返回一个以原有第二个参数为参数的函数。
object Test {
def main(args: Array[String]) {
val str1:String = "Hello, "
val str2:String = "Scala!"
println( "str1 + str2 = " + strcat(str1)(str2) )
}
def strcat(s1: String)(s2: String) = {
s1 + s2
}
}
1. 10Scala闭包
闭包是一个函数,返回值依赖于声明在函数外部的一个或多个变量。
闭包通常来讲可以简单的认为是可以访问一个函数里面局部变量的另外一个函数。
闭包反应了一个开放到封闭的过程。
每个调用闭包函数都会创建一个新的闭包。
object Test {
def main(args: Array[String]) {
println( "muliplier(1) value = " + multiplier(1) )
println( "muliplier(2) value = " + multiplier(2) )
}
var factor = 3
val multiplier = (i:Int) => i * factor
}
在 multiplier 中有两个变量:i 和 factor。其中的一个 i 是函数的形式参数,在 multiplier 函数被调用时,i 被赋予一个新的值。然而,factor不是形式参数,而是自由变量。
这样定义的函数变量 multiplier 成为一个"闭包",因为它引用到函数外面定义的变量,定义这个函数的过程是将这个自由变量捕获而构成一个封闭的函数。
针对集合的操作
遍历操作
列表的遍历
for循环遍历
for (elem <- list) println(elem)
foreach遍历
list.foreach(elem => println(elem)) // list.foreach(println)
映射的遍历
for循环遍历
for ((k,v) <- map) 语句块
foreach遍历
map foreach {[case(k,v) => println(k+":"+v)} // map.foreach({...})
map foreach {kv => println(kv._1+":"kv._2)} //以元组形式遍历。
map操作和flatMap操作
map操作:
map操作时针对集合的典型变换操作,它将某个应用到集合中的每个元素并产生一个结果集合。
flatMap操作:
flatMap是map的一种扩展,在flatMap中,我们会传入一个参数,该参数对每个输入都会返回一个集合(而不是一个元素),然后,flatMap把生成的多个集合“拍扁”成为一个集合。
scala> val books = List("Hadoop", "Hive", "HDFS")
books: List[String] = List(Hadoop, Hive, HDFS)
scala> books flatMap(s => s.toList)
res9: List[Char] = List(H, a, d, o, o, p, H, i, v, e, H, D, F, S)
flatMap执行时,会把books中的每个元素都调用toList, 生成List[Char],最终,多个Char的集合被“拍扁”成一个集合。
filter操作
遍历一个集合并从中获取满足条件的元素组成一个新的集合
学校名称中包含Xiamen的元素
val universityOfXiamen = university filter {kv => kv._2 contains "Xiamen"}
reduce操作
对元素进行归约
reduce包含reduceLeft和reduceRight两种操作。reduce默认为reduceLeft
scala> val list = List(1,2,3,4,5)
list: List[Int] = List(1, 2, 3, 4, 5)
scala> list.reduceLeft(_+_)
res0: Int = 15
归约顺序
1 + 2 = 3
3 + 3 = 6
6 + 4 = 10
10 + 5 = 15
fold操作
fold操作与reduce操作比较类似,fold提供种子值。为计算提供上下文。
scala> list.fold(10)(_*_)
res1: Int = 1200
函数式编程实例WordCount
import java.io.File
import scala.io.Source
object WordCount {
def main(args: Array[String]): Unit = {
val dirfile = new File("wordcount")
val files = dirfile.listFiles
for(file <- files) println(file)
val listFiles = files.toList
val wordsMap = scala.collection.mutable.Map[String, Int]()
listFiles.foreach( file => Source.fromFile(file).getLines().foreach(line=>line.split(" ").
foreach(
word=>{
if (wordsMap.contains(word)) {
wordsMap(word) += 1
}else{
wordsMap += (word -> 1)
}
}
)
)
)
println(wordsMap)
for((key, value)<-wordsMap) println(key+":"+value)
}
}
