目录
1:在windows系统中国,打开dos页面,输入chcp,就可以查看当前系统的默认编码。
在项目中,需要传入参数的时候总是避免不了中文乱码的问题,尤其是部署系统的编码不同的时候。
String res = Post.sendPost(url, "corpId=611ddf5cf41c43dbb34dcf9891124ff9×tamp=" + time + "&sign=" + md5
+ "&data=" + URLEncoder.encode(data.toString(),"UTF-8"));在项目中,为了防止编码问题,所以想要在传入的业务参数中利用,URLEncoder.encode方法来对业务参数进行加密。然而切记
URLEncoder.encode(a,b)必须传入两个参数,a为当前传入的字符串,b为编码格式。当没有b参数时,该方法会按照当前系统的默认编码格式进行编译,所以需要加入b参数。切记!!!!(血泪史)
1:在windows系统中国,打开dos页面,输入chcp,就可以查看当前系统的默认编码。
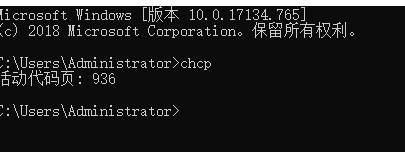
代码页是字符集编码的别名,也有人称"内码表"。早期,代码页是IBM称呼电脑BIOS本身支持的字符集编码的名称。当时通用的操作系统都是命令行界面系统,这些操作系统直接使用BIOS供应的VGA功能来显示字符,操作系统的编码支持也就依靠BIOS的编码。现在这BIOS代码页被称为OEM代码页。图形操作系统解决了此问题,图形操作系统使用自己字符呈现引擎可以支持很多不同的字符集编码。
早期IBM和微软内部使用特别数字来标记这些编码,其实大多的这些编码已经有自己的名称了。虽然图形操作系统可以支持很多编码,很多微软程序还使用这些数字来点名某编码。
下表列出了所有支持的代码页及其国家(地区)或者语言:
代码页 国家(地区)或语言
437 美国
708 阿拉伯文(ASMO 708)
720 阿拉伯文(DOS)
850 多语言(拉丁文 I)
852 中欧(DOS) - 斯拉夫语(拉丁文 II)
855 西里尔文(俄语)
857 土耳其语
860 葡萄牙语
861 冰岛语
862 希伯来文(DOS)
863 加拿大 - 法语
865 日耳曼语
866 俄语 - 西里尔文(DOS)
869 现代希腊语
874 泰文(Windows)
932 日文(Shift-JIS)
936 中国 - 简体中文(GB2312)
949 韩文
950 繁体中文(Big5)
1200 Unicode
1201 Unicode (Big-Endian)
1250 中欧(Windows)
1251 西里尔文(Windows)
1252 西欧(Windows)
1253 希腊文(Windows)
1254 土耳其文(Windows)
1255 希伯来文(Windows)
1256 阿拉伯文(Windows)
1257 波罗的海文(Windows)
1258 越南文(Windows)
20866 西里尔文(KOI8-R)
21866 西里尔文(KOI8-U)
28592 中欧(ISO)
28593 拉丁文 3 (ISO)
28594 波罗的海文(ISO)
28595 西里尔文(ISO)
28596 阿拉伯文(ISO)
28597 希腊文(ISO)
28598 希伯来文(ISO-Visual)
38598 希伯来文(ISO-Logical)
50000 用户定义的
50001 自动选择
50220 日文(JIS)
50221 日文(JIS-允许一个字节的片假名)
50222 日文(JIS-允许一个字节的片假名 - SO/SI)
50225 韩文(ISO)
50932 日文(自动选择)
50949 韩文(自动选择)
51932 日文(EUC)
51949 韩文(EUC)
52936 简体中文(HZ)
65000 Unicode (UTF-7)
65001 Unicode (UTF-8)2:在linux系统下查看系统编码格式

【vi /etc/sysconfig/i18n】打开系统编码文件,修改系统编码为“zh_CN.UTF-8”。
