一、公式
Fisher判别法师最早提出的判别方法之一,是将n类m维数据集尽可能投影到一个方向直线上,使得类和类之间尽可能分开.
定义
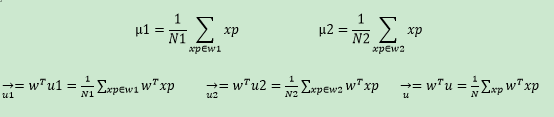

u1是第一类点的均值向量,u2是第二类点的均值向量,u是所有点的均值向量, 带箭头的是向量投影后的表示
SSB是类间散度,有两种表示方式. SSW是类内散度,也有两种表示方式。两种方式类似,可能相差一个常数.


依据一般经验 theta取值为theta=w'(u1+u2)/2; 或者theta=w'(N1*u1+N2*u2)/N; 或者 theta=w'(N2*u1+N1*u2)/N
这样当w'*x的值超过或者小于theta的时候就能分类.
二、应用
数据 ss.txt
6.6 39 1.0 6.0 6.0 0.12 20 1 1 6.6 39 1.0 6.0 12 0.12 20 1 2 6.1 47 1.0 6.0 6.0 0.08 12 1 3 6.1 47 1.0 6.0 12 0.08 12 1 4 8.4 32 2.0 7.5 19 0.35 75 1 5 7.2 6.0 1.0 7.0 28 0.30 30 1 6 8.4 113 3.5 6.0 18 0.15 75 1 7 7.5 52 1.0 6.0 12 0.16 40 1 8 7.5 52 3.5 7.5 6.0 0.16 40 1 9 8.3 113 0.0 7.5 35 0.12 180 1 10 7.8 172 1.0 3.5 14 0.21 45 1 11 7.8 172 1.5 3.0 15 0.21 45 1 12 8.4 32 1.0 5.0 4.0 0.35 75 2 13 8.4 32 2.0 9.0 10 0.35 75 2 14 8.4 32 2.5 4.0 10 0.35 75 2 15 6.3 11 4.5 7.5 3.0 0.20 15 2 16 7.0 8.0 4.5 4.5 9.0 0.25 30 2 17 7.0 8.0 6.0 7.5 4.0 0.25 30 2 18 7.0 8.0 1.5 6.0 1.0 0.25 30 2 19 8.3 161 1.5 4.0 4.0 0.08 70 2 20 8.3 161 0.5 2.5 1.0 0.08 70 2 21 7.2 6.0 3.5 4.0 12 0.30 30 2 22 7.2 6.0 1.0 3.0 3.0 0.30 30 2 23 7.2 6.0 1.0 6.0 5.0 0.30 30 2 24 5.5 6.0 2.5 3.0 7.0 0.18 18 2 25 8.4 113 3.5 4.5 6.0 0.15 75 2 26 8.4 113 3.5 4.5 8.0 0.15 75 2 27 7.5 52 1.0 6.0 6.0 0.16 40 2 28 7.5 52 1.0 7.5 8.0 0.16 40 2 29 8.3 97 0.0 6.0 5.0 0.15 180 2 30 8.3 97 2.5 6.0 5.0 0.15 180 2 31 8.3 89 0.0 6.0 10 0.16 180 2 32 8.3 56 1.5 6.0 13 0.25 180 2 33 7.8 172 1.0 3.5 6.0 0.21 45 2 34 7.8 283 1.0 4.5 6.0 0.18 45 2 35
fisherExample.m
%fisher判别
load A:\Data\ss.txt
a=ss(:,1:7); %取前7个特征
m=mean(a(1:12,:)); %取得第一类点的均值向量
m(2,:)=mean(a(13:35,:)); %取得第二类点的均值向量
ssw=zeros(7,7); %类内散度
for i=1:12 %按照第二种定义的类内散度
ssw=ssw+(a(i,:)-m(1,:))'*(a(i,:)-m(1,:));
end
for i=13:35
ssw=ssw+(a(i,:)-m(2,:))'*(a(i,:)-m(2,:));
end
w=inv(ssw)*(m(1,:)-m(2,:))';%按照公式得出w
result=a*w;
theta=w'*(m(1,:)-m(2,:))'/2; %按照theta第一种方式来确定theta
for i=1:35 %用于对比
result(i,2)=theta;
result(i,3)=i;
end
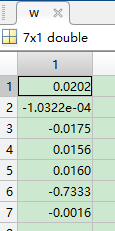
经比较,只有第28和29的两个数据分类错误,正确率为94.29%