前言
目标检测时的多尺度问题一直是一个难题。一种方法是将特征金字塔与anchor相结合,深层的特征图分辨率低,得到的anchor尺寸大数量少;浅层的特征图分辨率高,得到的anchor尺寸小数量多。这是由于深层特征图有更多的语义信息,适合检测较大的instance;浅层特征图的细节更精细,适合检测较小的instance。在匹配时,是根据instance box(ground-truth box)与anchor box之间的IoU来确定instance由哪个anchor负责,其实这隐式的决定了instance由哪个层级的特征图来负责预测。这种方法可以达到很好的检测性能。但是,这种设计存在两种限制:
- 在训练时每个instance根据IoU与最近的anchor匹配;
- 而anchor是由人为设计的规则与特定层级的特征图相关联。
因此每个instance选择的特征层级是完全基于临时启发得到的,换句话说,anchor机制一定程度上受到潜在的启发因素影响。如下图所示,一个汽车instance的大小是50×50像素,另一个相似的汽车instance的大小是60×60像素,它们可能被分配到不同的特征层级中;而另一个40×40的汽车instance可能被分配到 与50×50的instance相同的特征层级中。这就导致了训练instance所选择的特征层级可能不是最优的,因为谁也不能证明这种做法就是最好的。

本文提出FSAF(feature selective anchor-free)模型来解决这个问题,主要思想就是让每个instance自由地选择最佳的特征层级以得到最优化的效果。 因此在FSAF模型中没有anchor来限制特征层级的选择,但同时要以anchor-free的方式对instance进行编码,以进行分类和回归。每个层级的特征图后都有一个anchor-free分支,如下图所示,每个分支都包含有分类子网和回归子网。一个instance可以被分配到任意层级的anchor-free分支中。

- 在training时,基于instance的内容为每个instance动态选择最合适的特征层级,然后由那个特征层级负责对该instance进行检测。
- 在inference时,FASF模块可以独立预测结果,或者与anchor-based分支同时输出预测结果。
FSAF模块与主干网络无关,可以应用在具有特征金字塔的one-stage检测器中。当与anchor-based分支一起工作时,FSAF模块可以大幅改善主干网络的baseline,并且inference的开销几乎可以忽略不计。
FSAF模型
本文将FSAF模型与RetinaNet相结合,从以下几个方面对FSAF的设计进行介绍:
- 如何在网络中构造anchor-free分支;
- 如何产生anchor-free分支的监督信号;
- 如何让每个instance动态地选择特征层级;
- 如何联合训练anchor-free分支和anchor-based分支。
1. 网络结构

上图是RetinaNet + FSAF的网络结构。RetinaNet由一个主干网络和两个子网构成(分类子网和回归子网),特征金字塔
到
是基于主干网络构建的,
表示特征金字塔的层级,
对输入图像进行
倍的降采样。在每个
后面添加一个分类子网和一个回归子网,二者都为全卷积网络。分类子网预测每个位置的
个anchor中的目标属于
个类别的概率,回归子网预测每个anchor与离它最近的instance的偏移值。
在RetinaNet的输出端,如上图所示,FSAF模型只在每个金字塔层级引入两个额外的卷积层。这两个卷积层是在anchor-free分支中分别进行分类和回归预测。
- anchor-free分支中的分类子网:一个3 × 3 × 的卷积层被添加到anchor-based分支中分类子网的特征图后,后接sigmoid函数,与anchor-based分支的部分相互平行。它预测的是每个位置的目标分别属于 个类别的概率;
- anchor-free分支中的回归子网:一个3 × 3 × 4的卷积层被添加到anchor-based分支中回归子网的特征图后,后接ReLU函数,与anchor-based分支的部分相互平行。它负责以anchor-free的方式预测box的偏移值。
anchor-based和anchor-free以多任务的方式共同工作,共享每个金字塔层级的特征。
2. ground-truth and loss
一个instance的类别是
,box坐标是
,其中
是box中心点坐标,
和
分别是box的宽和高。在training阶段,这个instance可以被分配到到任意一个特征层级
中。定义
为
在
上的映射,有效区域
占
的
,忽略区域
占
的
,其中
,
。一个汽车instance生成gt的例子如下图所示:

分类输出
gt针对分类的输出是 个map,每个map对应一个类别。instance通过以下三种方式对第 个gt map造成影响:
- 有效区域 是正样本区域,就是图中的白色区域,由1填充,表示instance的存在;
- 忽略区域 是图中的灰色区域,这个区域中的梯度不会回传到网络中;
- 与忽略区域相邻的特征层级 也是忽略区域。
如果一层有两个instance的有效区域重叠,那么最小的那个instance 有较高的优先级。gt map中剩下的区域就是负样本区域,是图中的黑色部分,由0填充,表示instance没有出现在这个区域中。分类分支用的是focal loss, , 。对于一个输入图像来说,anchor-free分支中总的分类loss是所有非忽略区域的focal loss之和,同时通过所有有效区域中的像素个数进行正则化处理。
框回归输出
gt针对回归的输出是4个与类别无关的offset map,instance只作用于offset map上的有效区域。对于有效区域内的每个点 ,映射框 被表示为一个4维向量 ,分别表示该点距离映射框四条边的距离。然后这个向量要做 归一化处理, 这里等于4.0。忽略区域梯度是忽略不计的。回归分支用的是IoU loss,对于一个输入图像来说,anchor-free分支中总的回归loss是所有有效区域IoU loss的平均值。
inferenc阶段
要对分类分支和回归分支的输出结果进行解码。
假设对于位置
,预测的偏移值为:
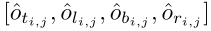
然后可以得到预测的距离为:
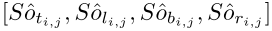
那么预测的映射框的左上角和右下角的坐标分别为:
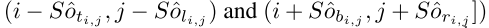
最后乘以
,就得到了在输入图像上的位置坐标。分类输出的map上位置
处的
维向量中的最大值所对应的类别,就是这个映射框的类别。
3. 在线特征选择
anchor-free分支允许任一层级的特征检测一个instance,FSAF模型基于instance的内容来为其找到最合适的特征层级 。
对于一个instance
,将其在
上的分类损失和框回归损失分别定义为
和
,分别通过计算有效区域
的平均focal loss和IoU loss得到:
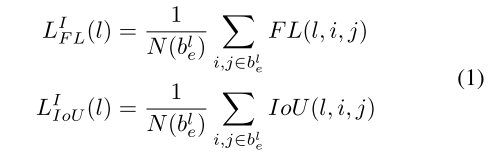
其中
是有效区域中的像素数量。

上图展示了在线特征选择的过程:
- 通过前向传播,经过特征金字塔的所有层级;
- 利用式(1)计算所有anchor-free分支的 和 之和;
- 哪一层的anchor-free分支算出来的和最小,那么这一层就是检测 的最优的特征层级 。
在training阶段,根据遇到的instance动态地调整特征层级的选择,通过上述过程选择的特征对当前instance的建模是最优的。其损失使特征空间的边界更低,通过巡礼啊可进一步降低这个边界。
在inference阶段,不需要进行在线特征选择,这是因为对于一个输入图像,特征金字塔中最合适的层级会自然地输出高的置信度分数。
4. 关于inference和training
initialization:
主干网络首先在ImageNet1k上进行预训练。按照原始参数对RetinaNet中的卷积层进行初始化,对于FSAF模型,分类分支的卷积层的偏差初始化为 ,高斯权重初始化为 ;回归分支的卷积层的偏差初始化为 ,高斯权重初始化为 。初始化可以使网络在开始时保持稳定,防止较大的损失产生。
training:
整个网络的loss是anchor-based分支和anchor-free分支loss的结合。设原始anchor-based RetinaNet的loss为
,anchor-free分支的分类loss和回归loss分别为
和
,那么整个网络的loss为:
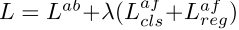
其中
是anchor-free分支的权重,这里
。
整个网络通过SGD在8个GPU上进行训练,每个GPU处理两个输入图像。训练时使用的数据增强方式只有水平图像翻转。
inference:
FSAF模型只在全卷积的RetinaNet上添加了很少的卷积层,对于anchor-free分支来说,通过设定置信度分数的阈值为0.05,只对每个金字塔层级中前1000个位置的box预测进行解码,然后所有层级的box预测与anchor-based分支中的box预测结合起来,通过阈值为0.5的NMS操作得到最终的检测结果。
