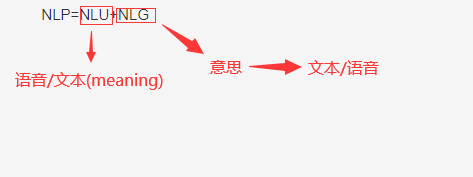
NLP定义:
NLP的challenge(挑战)是:语言有多种意思
解决方法:看句子的context(上下文)
机器翻译系统:
传统方法:构建语料库,输入一句话,想看这句话的意思,一个单词一个单词从语料库找意思,用统计分析方法求概率
传统方法的缺点:
- 可能出现语料库没有这个单词的情况(out of vocabulary)—(oov)
- 有一词多义的情况,不好区分意思
- 输出的语序不一定正确
解决方法:
- Mixed Word/Character Model:
把所有的oov分词,拆成字符,比如比如 Jessica,变成J,e,s,s,i,c,a。其中是Begin,Middle,End的标记。这样处理的好处就是消灭了全部的OOV。坏处就是文本序列变得非常长,对于性能敏感的系统,这是难以接受的维度增长 - UNK处理
在训练数据充足的情况下,RNN模型可以轻松支持30k-80k的词表。在大多数情况下,扩大词表都是首选的方案 - 通过上下文分析一词多义的情况
- 对于输出的语序不对的情况,可以用语言模型进行判定,给定一个句子,判定从语法来看,最正确的概率
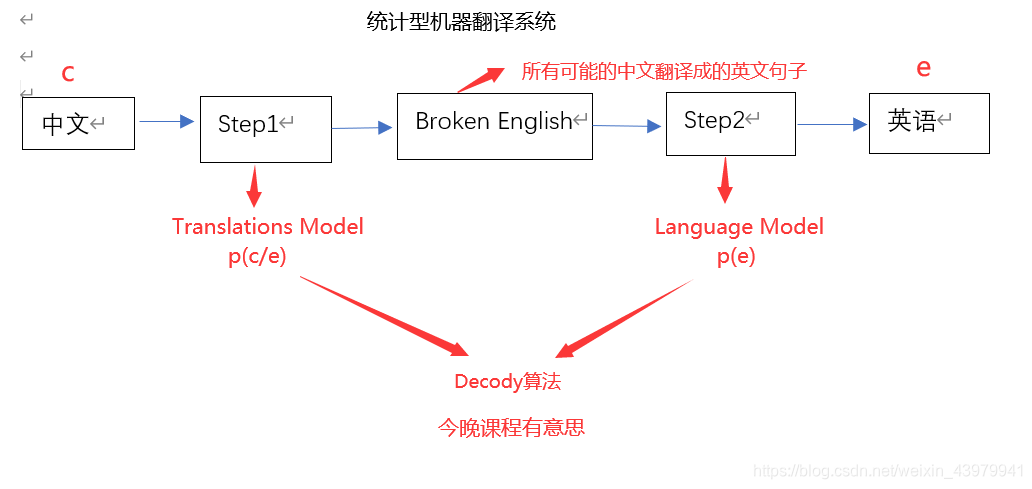
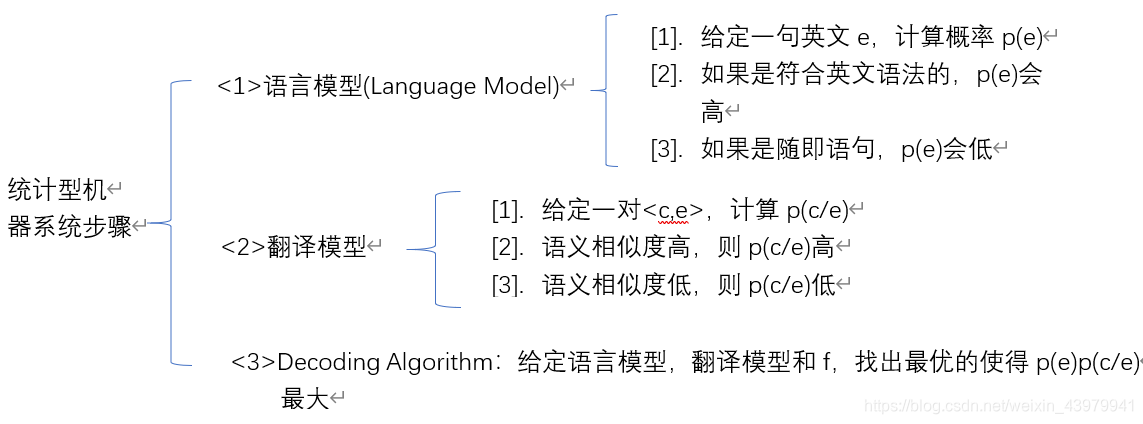
统计型机器翻译步骤

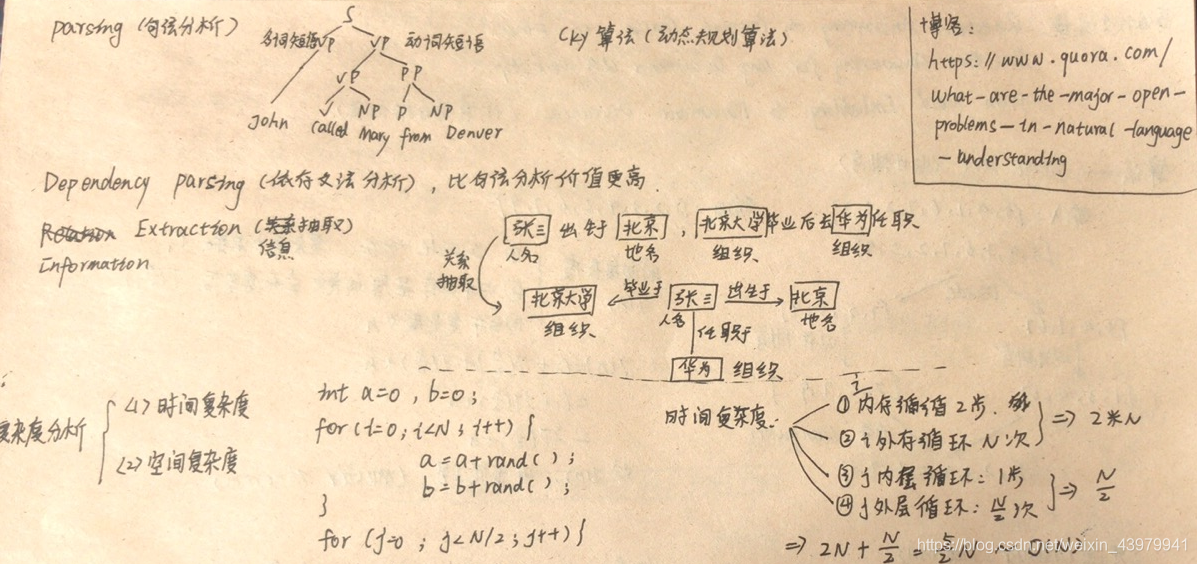
对于句法方面的经典论文推荐:
- Question Answering in Context Coarse -to- Fine
- Question Answering for long Documents QA Workshop
- From Word Embedding To Document Distances(计算语义相似度)
归并排序算法——Merge sort


复杂度等级:
0(1)<0(logn)<0(n)<0(nlogn)<0(n^2)<0(nnlogn)<0(nn*n)<0(n!)
