本篇文章不是教大家如何搭建和使用模块化,这样的文章网上太多了。主要是和大家探讨下在使用模块的过程有哪些问题、解决方案是什么?以及其他方面的一些思考。
诸如使用模块化有哪些好处等等的客套话我就不说了。直接上我们云收银模块化结构图:
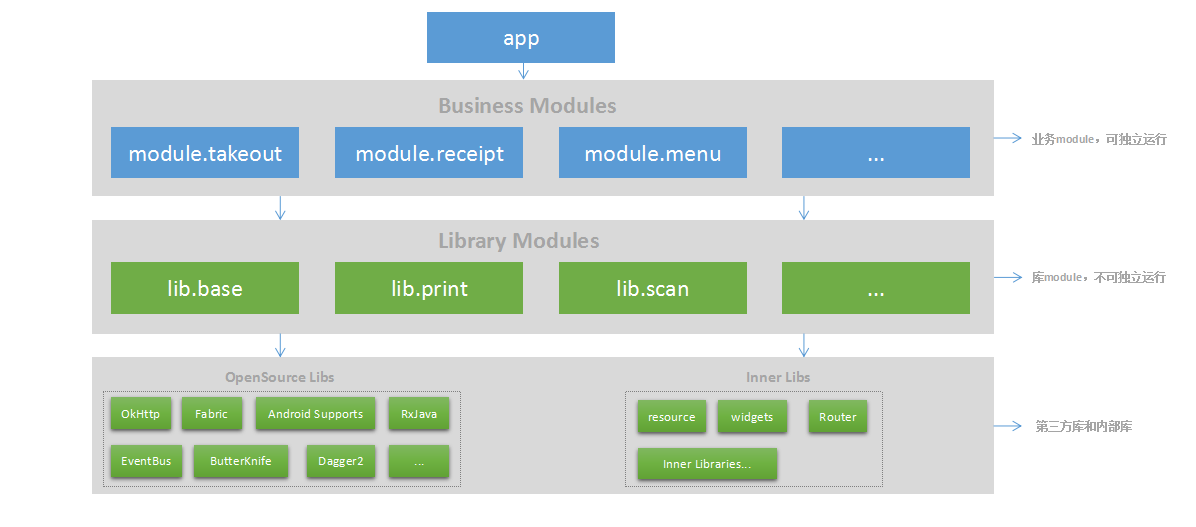
我们把模块定义为两种:一种是可运行的业务module(Business Module)、一种是库module(Library Module)供Business Module使用。
它们之间的依赖关系从上图可以看出来,还有一些细节图上没有体现出来,我通过一段简短的文字描述下:
1,app模块是一个壳,里面依赖了我们打包需要的业务module。
2,业务module,首先要依赖lib.base(lib.base后面会介绍)。
比如module.takeout(外卖)是一个`业务module`,它首先要依赖lib.base(lib.base后面会介绍),
然后根据情况决定是否依赖`库module`,比如你需要打印功能,那就把lib.print依赖进来。
3,库module,提供某种特定功能的module。主要分为两类:
1) lib.base 它是所有`业务module`都需要依赖的,封装了`业务module`公共的功能。
比如:网络、数据库等一些公共库,还有一些基类(BaseActivity、BaseFragment)等
2) 除了lib.base以外其他的`库module`,它们的作用是为业务module提供特定功能,比如:print打印。
lib.print也有可能依赖lib.base,但是我们上面说了,
lib.base是给业务module依赖了,怎么库module(lib.print)也依赖了lib.base,
为什么会这样,以及这样好不好后面会说到。使用过模块化的开发者,我想基本都类似上图一样来划分module。但是随着项目不断的迭代,可能慢慢的就会偏离这样来划分module的初衷。下面就开始正式进入正题吧。
主要遇到以下两个问题:
1,模块化路由的问题
2,业务模块之间功能的依赖问题
模块化路由的问题
关于模块化路由,我们一开始是使用阿里巴巴的ARoute,一开始挺高兴的,这块不用自己做了,省去了一些工作量。后面才发现很多坑。
随着时间的推移,发现ARouter有如下不足:
1,总是出现各种莫名其妙的问题,比如升级库后,参数的传递问题,然后就一直不能运行,查错误查半天。
跳转的过程中出现黑界面问题,一开始确实是使用不当,因为navigation()方法都没有传递参数,框架默认使用application来启动界面,后来全部加上了参数,但是有的界面还是莫名其妙的有这样的问题,体验很不好。
2,不支持Fragment的startActivityForResult功能
3,不支持Intent传递参数支持的所有类型。
4,错误提示不够友好,有的时候可能是使用者用的方式不对,然后就报错,源代码级别的异常,让人不能一下子定位到问题所在,出现问题很影响开发效率。
5,没有Activity的管理功能
所以呢,还是自己写吧。利用周末写了一个雏形,命名为MRouter(Modularization Router模块化路由器),因为非模块化的项目,使用路由器没有多大的意义。
MRouter支持如下功能:
1.支持不同模块之间的页面跳转
支持fragment、activity的startActivityForResult()方法
2.支持Intent传递参数的所有类型
MRouter.getInstance()
.build("user/order/list")
.putSerializable("user", user)
.putParcelable("address", address)
.putParcelableList("addressList", addressList)
.putParcelableArray("addressArray", addressArray)
.putString("param", "chiclaim")
.putStringArray("stringArray", new String[]{"a", "b", "c"})
.putStringList("stringArrayList", stringList)
.putStringList("stringList", stringArrayList)
.putByte("byte", (byte) 2)
.putByteArray("byteArray", new byte[]{1, 2, 3, 4, 5})
.putInt("age", 33)
.putIntArray("intArray", new int[]{10, 11, 12, 13})
.putIntList("intList", intList)
.putIntList("intArrayList", intArrayList)
.putChar("chara", 'c')
.putCharArray("charArray", "chiclaim".toCharArray())
.putShort("short", (short) 1000000)
.putShortArray("shortArray", new short[]{(short) 10.9, (short) 11.9})
.putDouble("double", 1200000)
.putDoubleArray("doubleArray", new double[]{1232, 9999, 8789, 3.1415926})
.putLong("long", 999999999)
.putLongArray("longArray", new long[]{1000, 2000, 3000})
.putFloat("float", 333)
.putFloatArray("floatArray", new float[]{12.9f, 234.9f})
.putBoolean("boolean", true)
.putBooleanArray("booleanArray", new boolean[]{true, false, true})
.putExtras(extras)
.navigation(this);3.自动注入传递过来的参数
支持fragment、activity自动注入参数,避免大量的的 getIntent.getXXX() 和 bundle.getXXX() 重复代码。
通过如下方式就自动注入参数了:
@Autowire(name = "age")
int age;
@Autowire(name = "intArray")
int[] intArray;
@Autowire(name = "intList")
List<Integer> intList;
@Autowire(name = "intArrayList")
ArrayList<Integer> intArrayList;
//省略其他类型...
4.初始化效率更高
阿里的ARouter初始化操作,是通过扫描apk dex某些特定的包名下的类,把包下类的class放到容器里去。
MRouter的方案是依赖开发者告诉MRouter到底有哪些模块使用MRouter生成代码功能。如:
@Components({"app", "modulemenu", "modulereceipt", "moduletakeout"})
public class CcdApplication extends DefaultApplicationLike {
//...
}在初始化方式上看,开发者会觉得阿里的ARouter的方式确实要方便点,开发者不用管哪些模块使用了它。
但是兼容性可能会打折扣,随着Android系统版本的升级,这样的扫描的方式会不会有问题?不得而知。兼容性是Android开发的无法言喻的痛。
我们这个方案需要开发者指定,从某种角度来说对开发者不够友好,但是明白了怎么回事,其实也很简单。这种方式没有兼容性上的问题,也没有效率上的损耗。
最终比较下来还是选择了通过开发者指定的这种方式。
5.更友好的错误提示
用过APT类型框架的开发者都知道,只要生成代码出错,尼玛,控制台报一堆错误,全是类找不到,一脸懵逼。而且排查问题也比较麻烦,刚刚还好好的呢?怎么说不行就不行。特别模块化的情况下,更是让人心累。举个例子:
@Autowired(name = RouterPathConstant.Register.PHONE)
private String mPhone;这是一段自动注入参数的代码,如果开发者使用private来修饰,那么肯定就不能注入参数了,私有变量在其他类里面是无法直接赋值的,框架肯定会报错。
我们会友好的告诉开发者你写的第几行代码是由什么原因导致出错的。如:

双击会自动定位到有问题的代码行。这是访问修饰符的错误,还有其他出错的可能,比如你想注入参数类型是Activity,肯定不行的,因为无法把Activity作为参数进行传递。
6. 支持对Activity的管理
一般我们在程序中会把所有启动的Activity对象放在Stack栈中,便于统一管理(主要用于关闭)。例如启动了A、B、C、D四个界面,想关闭ACD界面只保留B界面,一般遍历栈只要不是B界面全部关掉,
如果想在app模块执行这个操作,且B界面在另一个模块,根本拿不到B的class,从而无法告诉工具类,要保留哪个界面(因为B界面不是在app模块定义的,在app模块拿不到)。所以如果使用到了模块化,
对Activity的管理的功能最好由模块化框架来提供。
业务模块之间依赖的问题
比如订单模块依赖收款模块里的退款功能,但是呢,退款功能在收款模块里,在订单模块是无法直接使用这个功能的,因为两个是完全独立的模块。
一开始我们是这么处理的:把依赖的退款功能放在一个公共的模块(common.business),然后订单模块把这个功能的模块依赖进来。
但是这样的方案存在以下问题:如果订单模块后面还依赖收款模块的其他功能呢?是不是也要把他们放到common.business去呢?
目前只是涉及到两个两个模块,如果菜单模块依赖订单模块的某个功能呢?是不是也要把他们放到common.business去呢?如果有10个模块都互相依赖其中的某个小功能,怎么办?
而且业务变化很快的,模块之间的业务依赖的地方可能会非常多,如果都把要依赖的都“上浮”到common.business,它就成大杂烩了,而且各个模块也不完整了,因为很多功能都分到common.business里去了。这样的话模块化就没有意义了,就失去了模块化的好处了。
我们是把要依赖的功能都放到common.business,这样会导致这个模块越来越臃肿,这个模块会包含其他模块的功能。这样也就慢慢的偏离了一开始我们模块化的初衷。但是不这么做似乎也没有其他办法。
其实可以在common.business的方案的基础上在优化一下,那我们可以只把要依赖该功能接口暴露出去,而不是把实现类暴露出去,这样的话就可以减少耦合了。因为接口是必须暴露的,如果不暴露,其他模块要用的地方就无法调用该业务的方法。接口暴露了,那么接口需要的数据结构(bean)也需要暴露。
大致的方向确定了:如果模块之间需要依赖某个子功能,只暴露它的接口和数据模型。
光有了接口和数据模型还不够,被依赖的业务实现类还在它自己的模块中,其他模块怎么构建需要依赖的业务对象呢?
方案一:反射的方式
这个方案灵感是从Spring上找到的,Spring有个概念叫做“依赖注入”。依赖某个业务,不需要直接new,把这个业务类配置在Xml里,然后框架会通过反射把这个业务实例注入到需要它的地方。
那我们也可以通过注入的方式,虽然“退款”功能在其他模块,但是我们知道它全路径(包名+类名),可以把实现类的全路径通过常量的方式配置在某个类中,然后就可以反射来构建它的实例了。如:
private IReceiptSource mReceiptSource; //业务接口
Object object = ReflectUtil.getInstance("实现类的全路径");
if (null != object && object instanceof IReceiptSource) {
mReceiptSource = (IReceiptSource) object;
}该方式有以下不足:
1) 因为实现类的全路径是通过常量的方式写死的,如果对代码进行重构,可能会把实现类放在另一个包名,或者实现类的类名可能被更改了。这样就无法通过反射实例化了。
2) 如果使用了混淆,类名报名都会被混淆。除非把实现类保留不参与混淆。
方案二:APT的方式
原理和MRoute实现的页面路由是一样的,被跳转的页面也身处在其他模块,只要把它的class放到一个公共的容器里去就可以了。那我们也可以把要被依赖的业务实现类class放在一个公共的容器里,需要的注入的时候就从里面获取它的class然后反射就可以了,
这样的话实现类的全路径怎么变,对我们都不会有影响。使用也很简答,使用方式如下:
@Autowired(name = BusinessConstant.ReceiptSource.RECEIPT_SOURCE)
IReceiptSource mReceiptSource;
MRouter.getInstance().inject(this);//执行注入操作至此,基本上解决了模块之间业务的依赖。其中的思想就是一种高内聚,低耦合表现。
高内聚:把相关的功能内聚在一起。
低耦合:当其他模块需要依赖其他模块的某个功能,只暴露接口让其依赖,把耦合降到最低。
可能会有人问,比如A模块依赖B模块的某个功能,直接让A依赖B不就行了么?这样做也不需要把被依赖的功能接口、实现类、数据模型提取到business.common,这样做有以下不足:
1,如果A模块依赖B模块的某个功能,就把B整个模块暴露在A面前,会导致A和B的关系越来越复杂,因为B对于A来说是完全可见的,可能会导致开发者直接使用B里面的其他资源或者功能,致使A和B关系越来越紧密。
2,无法知道A模块依赖了B模块的哪些功能,特别是A模块很大的情况下,很难知道A模块到底使用了B模块哪些东西。
如果只有A和B两个模块还好,如果A、B、C、D…..Z 26个模块怎么办?
如果都是这样处理依赖的话,26个模块之间都可以能会产生关系。假设有这样一个需求,需要把整个A模块的功能给其他项目组使用个,因为他们也需要集成这个功能。
现在A是直接依赖整个B模块了,然后B有可能依赖C了,C又依赖整个D了,此处省略一万个字,还有可能26个模块相互依赖。现在你要把A单独拎出来,给其他项目组使用个,现在怎么办?
如果花了一个星期终于知道A依赖了B哪些东西,再花一个星期理清楚A和C什么关系?内心肯定是崩溃的。
其实这个问题在开发的过程中,很容易犯的错误,特别是随着业务的增长,这个错误又是比较致命的。
比如我们公司的二维火云收银需要接入开店功能,这个开店功能在掌柜项目组,我清晰的记得为了给个开店的功能,他们给了我们16个module,比我们项目的module还多,真的很崩溃,但是也没有办法,短期开发个开店的功能肯定不现实。他们那边可能是”6代单传”的代码,多少年的代码了,然后任务也多,短期内把错综复杂的module依赖关系理出来,也是不现实。
所以说处理好模块之间的依赖,是相当重要的。
二维火云收银的定位是全行业版云收银,随着不断的迭代,module会越来越庞大。所以说在模块化的过程中,一定要处理好模块之间的关系,要把模块进行有效的隔离,最好不要产生直接的关系。不要把代码搞得“如胶似漆”,“水乳交融”,“你中有我,我中有你” ,到时候想分开,分都分不开了,要处理好代码之间边界。俗话说距离产生美,代码也需要有距离。
关于业务module的依赖问题就讲完了。
接下来,说下开篇留下的库module之间依赖的问题(lib.print依赖lib.base),现在我们功能性的库module(如打印)都会依赖lib.base,
首先说下为什么要依赖呢?因为lib.base包含网络、数据库、开源库等封装,因为lib.print需要网络操作,还需要其他开源库等,这些东西刚好又在lib.base,所以自然而然就让lib.print依赖lib.base。这样以后会有什么问题吗?从上面我们对业务module之间依赖的分析,理论上肯定会有问题,但是它又有其特殊性:
1,我们只会让功能性的库module依赖lib.base,不会出现功能性的库module依赖其他功能性的库module,所以他们之间的依赖关系会减轻很多。
2,我们库module lib.base功能是有限的(就是一些开源库和业务module共性封装),除非你人为的把什么东西都往lib.base里扔,导致它非常的臃肿。
3,并且我们日常的迭代是对业务module的迭代,一旦lib.base好了,一般是不会怎么动的。就算把lib.base完全暴露给某个功能性库module使用,也没有什么大不了,因为他提供的就这些东西。
如果不依赖lib.base就比较麻烦,比如功能性库module(lib.print)需要网络请求,难道直接把网络相关的封装单独作成一个module让其依赖?如果它有需要数据库操作难道又把对数据库的封装又抽成一个module让其依赖?要知道一个项目会有需要的用到许多的开源库的。就是因为lib.base的特殊性,以及出于减少module数量的原因,就让别人去依赖lib.base好了。
对业务的思考与展望
首先要明白的是,一切的一切都是围绕业务走的。你的架构、需求分析、测试都是为了这个业务。
一味的写业务需求确实是没有意思,我觉得业务也有有意思的地方,比如这样实现不够优雅,有什么有优雅的方式可以代替。说白了就是写业务的时候回思考出问题来,如何解决这个问题,解决了会有成就感的,这就是它有意思的地方。比如下面是我对业务开发过程中的一些思考:
1,Dagger2的解耦思想是好的,但是我觉得使用起来还是有一些不足:
1>在我们的项目中,每一个依赖都需要新建一个Component和Module两个类,如果是MVP模式,写一个业务需要新建4个这样的模板类。
2>不能跨模块依赖
那么有没有一种方案可以解决上面的两个不足呢(不管有没有方案先把问题抛出来)?或者秉承它的思想自己写一套,然后集成到我们自己的MRouter框架中去?
2,自动化测试相关。比如这次的迭代,对上期的影响有点大,需要把上期的功能进行回归测试。如果上一期有1000个测试用例,工作量岂不是很大?哪怕自动化测试不能100%覆盖,如果能测试60%的测试用例也是很好的。
3,app日志监控。项目上线后,可以对app启动速度、运行效率、网络响应速度、页面路径等指标进行监控。从而一面可以有效的定位上线问题,另一面可以为产品的设计,运营等提供数据指导。