2)删除符合条件的文本(d)
因为后面的示例还需要使用测试文件 test.txt,所以在执行删除操作之前需要先将测试文件备份。以下示例分别演示了 sed 命令的几种常用删除用法。
下面命令中 nl 命令用于计算文件的行数,结合该命令可以更加直观地查看到命令执行的结果。
(1)# nl httpd.txt | sed ‘3d’
删除第 3 行

(2)# nl httpd.txt | sed ‘3,5d’
删除第 3~5 行

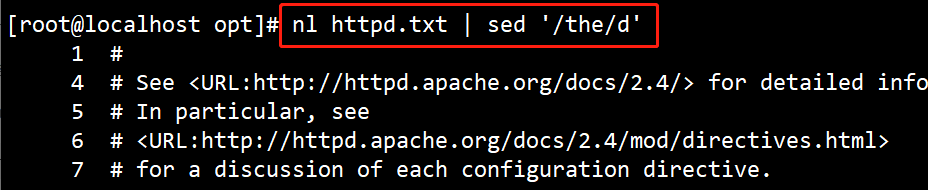
(3)# nl httpd.txt |sed ‘/the/d’
删除包含the 的行,原本的第 8 行被删除
删除不包含the的行,用!符号表示取反操作,如’/the/!d’

(4)# sed ‘/^ [a-z]/d’ httpd.txt
删除以小写字母开头的行

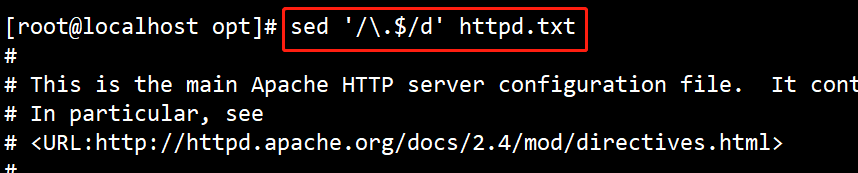
(5)# sed ‘/.$/d’ httpd.txt
删除以"."结尾的行。“.”前要加转义符“\”
(6)# sed ‘/^$/d’ httpd.txt
删除所有空行

注意: 若是删除重复的空行,即连续的空行只保留一个, 执行“ sed –e ‘/^ $/{n;/^ $/d}’ test.txt”命令即可实现。其效果与“cat -s test.txt”相同,n 表示读下一行数据。
3)替换符合条件的文本
在使用 sed 命令进行替换操作时需要用到 s(字符串替换)、c(整行/整块替换)、y(字符转换)命令选项,常见的用法如下所示。
(1)#sed ‘s/the/THE/’ httpd.txt
将每行中的第一个the 替换为 THE

(2)#sed ‘s/the/THE/g’ httpd.txt
将文件中的所有the 替换为THE

(3)#sed ‘s/the//g’ httpd.txt
将文件中的所有the删除(替换为空串)

(4)#sed ‘s/^/#/’ httpd.txt
在每行行首插入#号

(5)#sed ‘/s/the/^/#/’ httpd.txt
在包含the 的每行行首插入#号

(6)#sed ‘s/$/EOF/’ httpd.txt
在每行行尾插入字符串EOF

(7)#sed ‘5,10s/o/OO/g’ httpd.txt
将第 5~10 行中的所有o 替换为OO

(8)#sed ‘/the/s/o/OO/g’ httpd.txt
将包含the 的所有行中的o 都替换为 OO

(9)#sed ‘s/o/LL/2’ httpd.txt
将每行中的第 2 个o替换为L L

4)迁移符合条件的文本
其中,H,复制到剪贴板;g、G,将剪贴板中的数据覆盖/追加至指定行;w,保存为文件;r,读取指定文件;a,追加指定内容。
(1)#sed ‘/the/{H;d};$G’ httpd.txt
将包含the 的行迁移至文件末尾,{;}用于多个操作

(2)#sed ‘3,6{H;d};2G’ httpd.txt
将第 3~6 行内容转移至第 2行后

(3)#sed ‘/woo/w a.txt’ httpd.txt
将包含woo 的行另存为文件a.txt


(4)# sed ‘/the/r a.txt’ httpd.txt
将文件a.txt 的内容添加到 包含the 的每行以后

(5)#sed ‘5aNew’ httpd.txt
在第 5 行后插入一个新行,内容为 New

(6)#sed ‘/wd/aNew’ httpd.txt
//在包含wd的每行后插入一个新行,内容为 New

(7)#sed ‘3aNew1\nNew2’ httpd.txt
在第 3 行后插入多行内容,中间的\n 表示换行

四:awk 工具
1.awk 常见用法
在使用 awk 命令的过程中,可以使用逻辑操作符“&&”,表示“与”, “||”表示“或”,“!”表示“非”;还可以进行简单的数学运算,如+、-、*、/、%、^分别 表示加、减、乘、除、取余和乘方。
awk 包含几个特殊的内建变量(可直接用)如下所示:
FS:指定每行文本的字段分隔符,默认为空格或制表位(tab)。
NF:当前处理的行的字段个数。
NR:当前处理的行的行号(序数)。
RS:数据记录分隔,默认为\n,即每行为一条记录。
$ 0:当前处理的行的整行内容。
$n:当前处理行的第 n 个字段(第 n 列)。
FILENAME:被处理的文件名。
2.用法示例
1)按行输出文本
(1)#awk -F ‘:’ ‘{print $1,$3,$4}’ /etc/passwd
输出/etc/passwd文件中 第1、3、4列内容

(2)#awk ‘{print}’ test.txt
输出所有内容,等同于 cat test.txt
(3)#awk ‘{print $0}’ test.txt
输出所有内容,等同于 cat test.txt
(4)#awk ‘NR==1,NR==3{print}’ httpd.txt
输出第 1~3 行内容

(5)#awk ‘(NR>=1)&&(NR<=3){print}’ httpd.txt
输出第 1~3 行内容

(6)#awk ‘NR==1||NR==3{print}’ httpd.txt
输出第 1 行、第 3 行内容

(7)#awk ‘NR==1;NR==3{print}’ httpd.txt
输出第 1 行、第 3 行内容
(8)#awk ‘(NR%2)==1{print}’ httpd.txt
输出所有奇数行的内容

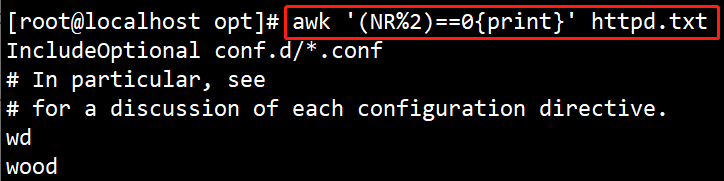
(9)#awk ‘(NR%2)==0{print}’ httpd.txt
输出所有偶数行的内容
(10)#awk ‘/^root/{print}’ /etc/passwd
输出以root 开头的行

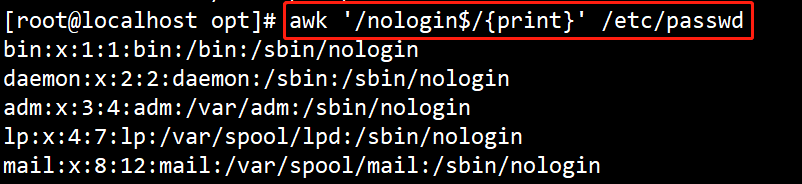
(11)#awk ‘/nologin$/{print}’ /etc/passwd
输出以 nologin 结尾的行
(12)#awk ‘BEGIN {x=0} ;//bin/bash$/{x++};END {print x}’ /etc/passwd
统计以/bin/bash 结尾的行数
等同于 #grep -c “/bin/bash$” /etc/passwd

(13)#awk ‘BEGIN{RS=""};END{print NR}’ httpd.txt
统计以空行分隔的文本段落数

2)按字段输出文本
(1)#awk ‘{print $3}’ httpd.txt
输出每行中(以空格或制表位分隔)的第 3 个字段

(2)#awk ‘{print $1,$3}’ httpd.txt
输出每行中的第 1、3 个字段

(3)#awk -F “:” ‘$2=="!!"{print}’ /etc/shadow
输出密码为空的用户的shadow 记录
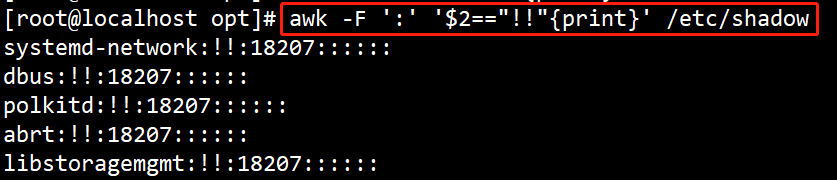
(4)#awk ‘BEGIN {FS=":"}; $2=="!!"{print}’ /etc/shadow
输出密码为空的用户的shadow 记录

(5)#awk -F “:” ‘$7~"/bash"{print $1}’ /etc/passwd
输出以冒号分隔且第 7 个字段中包含/bash 的行的第 1 个字段

(6)awk ‘($1~“nfs”)&&(NF==8){print $1,$2}’ /etc/services
输出包含 8 个字段且第 1 个字段中包含 nfs 的行的第 1、2 个字段

(7)#awk -F “:” ‘($7!="/bin/bash")&&($7!="/sbin/nologin"){print}’ /etc/passwd
输出第 7 个字段既不为/bin/bash 也不为/sbin/nologin 的所有行

3)通过管道、双引号调用 Shell 命令
(1)#awk -F: ‘/bash$/{print | “wc -l”}’ /etc/passwd
调用wc -l 命令统计使用bash 的用户个数,等同于 grep -c “bash$” /etc/passwd

(2)#awk ‘BEGIN {while (“w” | getline) n++ ; {print n-2}}’
调用w 命令,并用来统计在线用户数

(3)#awk ‘BEGIN { “hostname” | getline ; print $0}’
调用hostname,并输出当前的主机名


五:sort 工具
sort 是一个以行为单位对文件内容进行排序的工具,也可以根据不同的数据类型来排序。sort 命令的语法为“sort [选项] 参数”,其中常用的选项包括以下几种。
-f:忽略大小写;
-b:忽略每行前面的空格;
-M:按照月份进行排序;
-n:按照数字进行排序;
-r:反向排序;
-u:等同于 uniq,表示相同的数据仅显示一行;
-t:指定分隔符,默认使用[Tab]键分隔;
-o <输出文件>:将排序后的结果转存至指定文件;
-k:指定排序区域。
(1)# sort /etc/passwd
将/etc/passwd 文件中的账号进行排序。

(2)#sort -t ‘:’ -rk 3 /etc/passwd
将/etc/passwd 文件中第三列进行反向排序。

(3)# sort -t ‘:’ -k 3 /etc/passwd -o user.txt
将/etc/passwd 文件中第三列进行排序,并将输出内容保存至user.txt 文件中。

六:uniq 工具
Uniq 工具在 Linux 系统中通常与 sort 命令结合使用,用于报告或者忽略文件中的重复行。具体的命令语法格式为:uniq [选项] 参数。其中常用选项包括以下几种。
-c:进行计数;
-d:仅显示重复行;
-u:仅显示出现一次的行;
[root@localhost ~]# cat test.txt

(1)#uniq test.txt
删除 test.txt 文件中的重复行。

(2)#uniq -c test.txt
删除 test.txt 文件中的重复行,并在行首显示该行重复出现的次数。

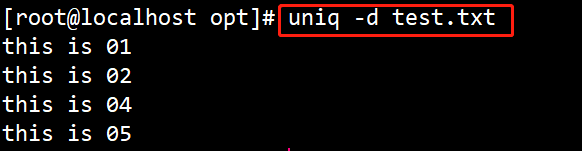
(3)# uniq -d test.txt
查找 test.txt文件中的重复行。