集群方式有三种:Replica Set、Sharding、Master-Slaver三种方式
常用的主要是副本集和主从模式,主从模式比较好理解,即一个master和一个slave节点,master节点负责读写,slave在master宕机的时候可以提供读服务,当然也可以通过配置参数实现在访问量高的时候让slave节点也提供读服务;
而副本集模式比较特殊,但这种模式也是比较稳定,可靠,同时在一定的情况下能够实现自动容错的机制,它主要包括如下几部分,Mongodb(M)表示主节点,Mongodb(S)表示备节点,Mongodb(A)表示仲裁节点。主备节点存储数据,仲裁节点不存储数据。客户端同时连接主节点与备节点,不连接仲裁节点。
默认设置下,主节点提供所有增删查改服务,备节点不提供任何服务。但是可以通过设置使备节点提供查询服务,这样就可以减少主节点的压力,当客户端进行数据查询时,请求自动转到备节点上。这个设置叫做Read Preference Modes,同时Java客户端提供了简单的配置方式,可以不必直接对数据库进行操作。
仲裁节点是一种特殊的节点,它本身并不存储数据,主要的作用是决定哪一个备节点在主节点挂掉之后提升为主节点,所以客户端不需要连接此节点。这里虽然只有一个备节点,但是仍然需要一个仲裁节点来提升备节点级别。
下面我们在三台虚拟机上模式搭建一下mongodb的这种副本集模式的集群:
1、环境准备,提前安装好docker和docker-compose
192.168.81.131(主)、192.168.81.132(备)、192.168.81.131(仲裁)
2、pull下mongo镜像
docker pull mongo
3、编辑mongod.conf配置文件(三个节点配置相同)
dbpath=/data/db logappend=true journal=true port=27017 replSet=test
4、编辑docker-compose.yaml文件(其中第三步的mongd.conf是存放在./configdb目录下的,配置文件内容还可完善)
version: "3" services: mongo: image: mongo container_name: mongo ports: - "27017:27017" volumes: - "./db:/data/db" - "./configdb:/data/configdb" environment: - TZ=Asia/Shanghai command: --bind_ip_all --config /data/configdb/mongod.conf restart: always logging: driver: "json-file" options: max-size: "10m" max-file: "3" networks: - mynet networks: mynet: external: true
5、docker-compose启动三台主机的容器
docker-compose up -d
6、配置集群信息
进入容器,执行mongo命令以进入mongo的shell模式,然后执行:
cfg={ _id:"test", members:[ {_id:0,host:'192.168.81.131:27017',priority:2},{_id:1,host:'192.168.81.132:27017',priority:1}, {_id:2,host:'192.168.81.133:27017',arbiterOnly:true}] };
其中priority为权重,数字越大,权重越大,最大者为主节点
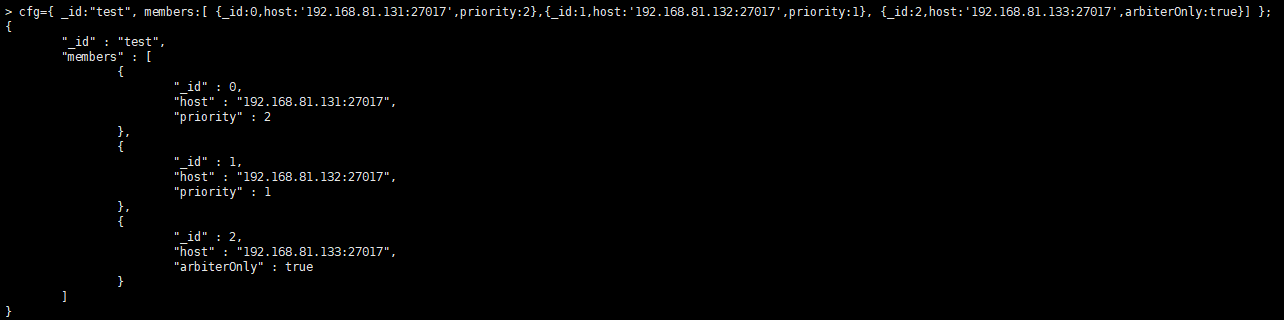
然后加载配置:
rs.initiate(cfg);

然后执行rs.status()命令即可查看当前状态了
当前复制集配置完成了