《Attention Is All You Need》是2017年由Google提出的论文,论文重点描述了transformer结构及原理。transformer在机器翻译等众多NLP领域取得了很大的进步,这次学习《Attention Is All You Need目的是为了搞懂transformer,BERT预训练模型原理及细节。
论文链接:https://arxiv.org/abs/1706.03762
摘要
主要的序列转换模型都是基于复杂的卷积神经网络(CNN)和循环神经网络(RNN),也包括编码器和解码器。最好的表现模型也是通过注意力机制链接编码器解码器。论文里提出一个简单的仅基于注意力机制网络结构,Transformer,该结构完全避免了循环和卷积。实验在两个机器翻译任务上表明模型优于其他模型,同时有更高的并行和更少的训练时间。该方法在2014WMT英德翻译任务中完成了BLUE值为28.4,超越了之前最好的结果。同时在英法翻译任务中,该模型在8块GPU上跑了3.5天得到了最好的BLUE值41.8分。在大量的或者受限的数据下,我们也能证明transformer模型可以成功的应用到其他任务当中去。
1. 介绍
循环神经网络(RNN)、长短时记忆网络(LSTM)和门控递归神经网络已经在序列模型和转换问题(预言建模和机器翻译)中取得了很好的成果。之后,大量的努力继续推动着语言模型和编码器-解码器机制不断发展。
递归模型一般是根据输入和输出序列的符号位置来计算因子。将位置与计算时间的步骤对齐,产生一个隐藏层序列,作为隐藏层状态
的一个函数和位置
的输入。这种内在的顺序性,阻碍了训练中的并行操作,在比较长的序列中,并行操作就闲的极为重要,序列过长的内存会限制和形象跨实例的批处理。最近的工作通过分解因子和条件计算使计算效率有了明显的提升,但是基于顺序的问题依然存在。
注意力机制已经成为序列模型和转换模型的一个完整的部分,允许在依赖项上进行建模,而忽略输出和输入序列的距离。然而,除少数情况外,这种注意力机制与循环神经网络(RNN)一起使用。
在论文中,提出Transformer模型,这种模型避免了重复性(与RNN,LSTM相比),取而代之的是完全依赖于注意机制来绘制输入和输出之间的全局依赖关系。Transformer模型允许并行计算并且在8个P100 gpu上接受12小时的培训后翻译质量达到更高的水平。
2. 背景
减少顺序计算也为扩展的神经GPU打下基础,所有这些都使用卷积神经网络作为基本构建块,并行计算所有输入和输出位置的隐藏表示。在这些模型中,在位置之间的距离中,将两个任意的输入和输出关联起来的操作在增加,ConvS2S为线性,ByteNet为对数。这使得学习远距离位置之间的依赖性变得更加困难,在transformer模型中,会减少这样的恒定的操作,尽管这回损失一些有效的分辨率,为了对位置注意力权重取均值,我们使用3.2节中介绍的多头注意力机制。
自注意力机制有时又叫做内注意力机制,它将单个序列的不同位置链接起来,为了计算一个序列的表示。自注意力机制成功应用到各种领域,例如阅读理解、文本摘要、文本蕴涵、学习独立任务的句子表示。
端到端的记忆网络是基于一种循环注意机制而不是序列排列的循环,在简单的语言问答和语言建模任务中表现良好。
然而,据我们所知,Transformer是第一个完全依赖于自注意力来计算输入和输出的表示,而不需要序列对其CNN或者卷积。在下一届我们将会描述Transformer,激励自注意力和模型的优点。
3. 模型结构
最具竞争力的神经序列转换模型都有编码器-解码器结构,在这里,编码器结构将一段输入的符号序列转化成一段连续的表示
。解码器得到
后,一次输出一个的序列
。模型的每一步都是自回归的,在生成下一步时,将先前生成的符号作为输入。Transformer结构如下图所示:

3.1 编码器&解码器堆栈
编码器: 编码器中N=6,即有个图中左侧的结构组成。每一层有两个子层,首先第一层是多头注意力机制层,第二层是简单的位置全连接的前馈网络。我们在两个子层的周围进行残差链接,并且进行层的规则化(图中Add&Norm)。每一个子层的输出可以表示为,这里
是子层自身实现的输出,为了方便剩余链接,所有子层产生的输出纬度都为521。
解码器:解码器也是有N=6个图中右侧结构构成的,除了上面提到的两个子层,又加入了一个第三子层,添加在编码器多头注意力机制子层输出之上。类似于编码器,我们也在各个子层的周围进行残差链接,然后进行规则化。我们改变了解码器自注意力子层来阻止位置关注后序的位置信息。这种屏蔽,加上输出被嵌入一个位置偏值,来确保位置i的预测只能依赖位置i之前的已知输出。
3.2 注意力
注意力函数可以描述为将询问和键-值对映射到一输出,询问(query),键(key),值(value)均为向量。输出为值(value)在乘权重之后的和,这个权重是键(key)和查询(query)做相应的复杂运算得来的。
3.2.1 Scaled Dot-Product Attention(DA):
称文中这种特殊的注意力机制为DA,运算过程如下图所示:
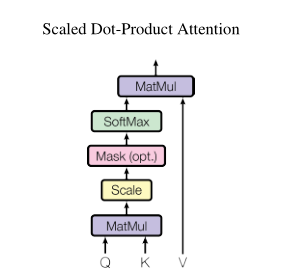
如上图所示,输入的Q(query)维度为,K(key)输入维度也为
,Q与K做点击操作,再经过一个softmax操作,得到权重矩阵,然后除以
,最后于V(value)相乘,V的维度为
。计算公式如下:
两个最常用的Attention机制为:Additive attention(AA)和Scaled Dot-Product Attention(DA)。除了比例因子之外,DA与我们的算法相同。AA用带有一个简单隐藏层的前馈网络来计算兼容函数(计算权重矩阵?)。虽然两者在理论上较为相似,但是DA在在实践中运用的比较多,因为点成可以更轻松的用代码实现。
当较小时,两种机制表现的相似,当
较大时,AA表现要强于DA,我们怀疑当
很大时,点积操作值会变得很大,在softmax后这个数就会变得很小(因为softmax函数计算),为了排除这一影响,我们要除一个比例即
。
3.2.2 多头注意力机制:
我们发现将查询(querys)、键(keys)和值(values)线性的投射h次,分别是维度分别是是有益的,而不是
维度模型将查询、键、值单一的使用注意力函数。在查询、键和值的投影上,都是并行的执行注意力函数,生成
维的输出。如下图所示他们被链接起来,并在此投影,从而产生最终值。
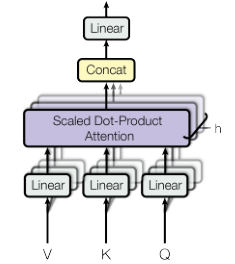
多头注意力机制允许模型关注来自不同位置的不同子空间表示信息。只使用一个注意力头和平均化操作会约束这种关注。
这里投影是参数矩阵,
,
,
在这项工作中,我们使用了h=8个平行的注意层,或者说头部。每一个注意力层我们使用,由于每个头部的维数减少,总的计算成本与全维度的单头部注意的计算成本相似。
3.2.3 注意力在模型中的应用
多头注意力机制在Transformer中的三种应用:
- 在编码-解码器注意力层中,查询来自上一个解码器层,而内存键和值来自编码器的输出,这使得解码器中的每个位置都可以参与输入序列中的所有位置。这模仿了典型的编码器-解码器注意机制的序列到序列模型。
- 编码器包含自关注层。在自注意力层中,所有键、值和查询都来自同一个位置,在本例中,是编码器中前一层的输出。编码器中的每个位置都可以处理编码器前一层中的所有位置。
- 类似地,解码器中的自注意力层允许解码器中的每个位置关注解码器中直到并包括该位置的所有位置。为了保持解码器的自回归特性,需要防止解码器中的信息向左流动。我们通过屏蔽输入中的所有值(设置为负无穷)来实现这个在标度点积注意范围内的功能。
3.3位置前馈网络
除了注意力子层之外,在我们的编码-解码器模型的每一层中包含一个全连接的前馈网络层,该网络分别相同的应用于每一个位置。这个前馈网络层由两个线性转换和中间的的一个ReLU激活函数组成。
虽然不同位置的线性变换是相同的,但它们在不同的层之间使用不同的参数。或者说用作为两个大小为1的卷积核,输入和输出的维度为512,而里层的纬度为2048(比512大)。
3.4 词嵌入和softmax
与其他的模型相似,我们使用词嵌入将输入标记和输出标记转换为维度为的向量。我们也使用正常的线性变换和softmax函数将解码器的输出转换为预测下一个标记的概率。在我们的模型中,我们在两个词嵌入之间共享同样的权重矩阵和pre-softmax变换。在词嵌入层,我们将将权重与
。
3.5 位置编码
因为我们的模型中不包含递归,也不包含卷积操作,为了能让模型利用序列的顺序,我们必须添加一些位置信息。为此,我们编码-解码器堆栈的底部输入词向量中添加了位置编码,位置编码和输入词嵌入有相同的维度,以便用来求和,同时有很多的位置向量编码方式。这个论文中,使用了正弦和余弦两种不同的位置编码方式,公式如下:
其中,pos是位置,i是维数。也就是说,位置编码的每一个维度对应着正余弦曲线。波长形成的几何级数从2π到1000*2π。我们之所以选择这个函数是因为我们假设模型可以能够轻松的学习相对位置,因为对于任意的固定偏移量k,可以被
的线性函数所表示。(这里应该是说,正弦函数和余弦函数可以表示位置的相对关系)
另外,还测试了通过学习来代替用正余弦函数做位置编码,通过实验验证发现两者并没有明显的区别。选择正弦函数的原因是因为它可以允许模型推断句子的长度比训练时候的更长。(可能与正弦函数是周期函数有关)
4. 为什么自注意力
这节中比较了自注意力层与常用的递归和卷积层在一个可变长序列映射到等长序列
任务中的不同或者说是好处,例如在典型序列转换问题中编码-解码器里的隐藏层。出于这个动机,我们考虑一下三个问题。
第一个是每一层计算的总复杂度,第二是可并行计算的数量,这个通过所需的最小顺序操作数量来衡量。第三是网络中远距离监督项的路径长度,学习远程依赖是很多序列转换任务中的关键。影响学习这种依赖关系的能力的一个关键因素是网络中向前和向后信号必须经过的路径的长度。输入和输出序列中任意位置组合之间的这些路径越短,就越容易学习远距离依赖关系。因此,我们还比较了由不同层类型组成的网络中任意两个输入和输出位置之间的最大路径长度。

这个表格主要体现的是自注意力机制在远距离学习的问题上,最大路径的长度为1,与此同时,递归和卷积在这类问题上的距离都要比自注意力机制的最大路径要长,所以,自注意力更加容易学习远距离依赖的关系。另外文中提到,如果在特别长的序列中,自注意力要受到限制,只考虑以r为半径的领域信息,这个算法,还处于研究阶段。
如果用卷积层来链接每一个输入和输出,由于卷积核k<n,所以单个卷积层不能连接所有的输入和输出,使用堆栈的卷积核代价比递归还有昂贵。可分离的卷积就大大降低了复杂性,也就是k=n,然而这个可分离的卷积操作就等于自注意力和逐点前馈层的组合,即模型中用到的方法。
另外,自注意力还能衍生出更多的解释模型, 我们从我们的模型中检查注意力分布,并在附录中给出和讨论例子。 不仅个体的注意头清楚地学会执行不同的任务,许多注意头似乎表现出与句子的句法和语义结构相关的行为。
5.总结
论文里Training的部分介绍了在做机器翻译训练时,训练的数据量、batch数、一些参数的设置。另外呢,在结果比较部分,也可以看出,运用self-Attention机制后,在机器翻译任务中或者序列到序列的任务中,有明显的提升。
这篇论文提出了transformer,第一个将基于attention的序列转换模型,在编码-解码器框架中的最常用的递归层代替位多头自注意力。在翻译任务中,也要比递归或者卷积网络执行快的多,效率更高。在英-德、英-法翻译任务中,达到了新的境界。
本篇文章就是对《Attetion Is All You Need》这篇文章内容的大致阐述,对于Attention,self-Attention,transformer执行操作的原理,请参考下面文章,我认为是写的最详细的。
