主讲人介绍:
现任北京某大型互联网企业数据科学家,工程师/数据科学家/技术书籍作者,多部数据科学/ML/DM/DL专著的出版者,熟悉Python/R/JAVA/C++/Scala语言。
专注于算法/机器学习/数据挖掘/自然语言处理/计算机视觉/深度学习/分布式系统架构等领域,出版过多本英文技术书籍《LearningData Mining with R》、《R:Mining Spatial, Text, Web, and Social Media Data》以及多部视频教程和论文。
前言
随着数据科学/人工智能/机器学习在各个领域的成功应用,现代人类社会各行业中的智慧化建设需求也逐渐出现,亟待解决。本次培训将从机器学习的工程应用的角度,分别讲述机器学习的算法/常见开源框架/常用开发工具等主题。并从机器学习工程的各环节角度,分别讲述数据预处理/特征工程/数据可视化等主题。在工程中应用最广的场景,例如自然语言处理/推荐系统/计算机视觉,各举了若干典型样例。最后对整个课程做了总结。课程所采用的具体语言为Python,具体机器学习库为Skikit-learn等开发库,具体平台为Tensorflow/Apache Spark等分布式机器学习框架。
目录
1. 机器学习简介
2. 机器学习开源框架:可用框架和库介绍
3. 机器学习工程:关于做机器学习系统的一些经验总结
4. 可视化编辑环境:Jupyter Notebook介绍
5. 集成开发环境:支持Markdown和作图的PythonIDE,例如Rodeo
6. 数据预处理实例
7. 基本统计处理实例
8. 数据可视化实例
9. 特征工程处理实例
10. 机器学习常用算法实例
11. 自然语言处理实例
12. 推荐系统处理实例
13. 计算机视觉处理实例
14. 深度学习实例
15. 总结
机器学习简介



CRISP-DM
数据挖掘的标准过程有两个,其中一个是CRISP-DM,介绍这部分是为了一开始就养成标准的软件工程的思维。
CRISP-DM包括如下部分:
学习基础的数据分析的时间,占据了70%的时间,
_ Sample──数据取样
_ Explore──数据特征探索、分析和予处理
_ Modify──问题明确化、数据调整和技术选择
_ Model──模型的研发、知识的发现
_ Assess──模型和知识的综合解释和评价
机器学习开源框架
——可用框架和库介绍


支持GPU,支持分布式的算法,分布式并行式的算法
TENSORFLOW ON SPARK
挑一种机器学习算法,以分布式、并行的方式实现,就已经是可以硕士毕业了。
选开源框架,要选择有成长性有前途的框架,以上所列的框架是符合这种特征的框架。挑一棵树去爬,PYTHON这颗树可以活很久,放心爬。
机器学习工程
——做机器学习系统的一些经验总结BEFOREMACHINELEARNING
•RULE#1: DON’T BE AFRAID TO LAUNCH A PRODUCT WITHOUT MACHINE LEARNING.
•RULE #2:MAKE METRICS DESIGN AND IMPLEMENTATION A PRIORITY.
•RULE #3:CHOOSE MACHINE LEARNING OVER A COMPLEX HEURISTIC.
•YOURFIRST PIPELINE
•RULE #4: KEEP THE FIRST MODEL SIMPLE ANDGET THE INFRASTRUCTURE RIGHT.
第一个MODEL要简单
•RULE #5: TEST THE INFRASTRUCTURE INDEPENDENTLYFROM THE MACHINE LEARNING.
测试平台
•RULE #6: BE CAREFUL ABOUT DROPPED DATA WHENCOPYING PIPELINES.
•RULE #7: TURN HEURISTICS INTO FEATURES, ORHANDLE THEM EXTERNALLY.
•MONITORING
•RULE #8: KNOW THE FRESHNESS REQUIREMENTSOF YOUR SYSTEM.
•RULE #9: DETECT PROBLEMS BEFORE EXPORTINGMODELS.
•RULE #10: WATCH FOR SILENT FAILURES.
•RULE #11: GIVE FEATURE SETS OWNERS ANDDOCUMENTATION.
指明FEATURE是属于哪个模块
•YOUR FIRSTOBJECTIVE
•RULE #12: DON’T OVERTHINK WHICH OBJECTIVEYOU CHOOSE TO DIRECTLY OPTIMIZE.
•RULE #13: CHOOSE A SIMPLE, OBSERVABLE ANDATTRIBUTABLE METRIC FOR YOUR FIRST OBJECTIVE.
•RULE #14: STARTING WITH AN INTERPRETABLE MODELMAKES DEBUGGING EASIER.
•RULE #15: SEPARATE SPAM FILTERING AND QUALITYRANKING IN A POLICY LAYER.
做好软件设计的划分
•FEATUREENGINEERING
特征过程
•RULE #16: PLAN TO LAUNCH AND ITERATE.
•RULE #17: START WITH DIRECTLY OBSERVED ANDREPORTED FEATURES AS OPPOSED TO LEARNED FEATURES.
•RULE #18: EXPLORE WITH FEATURES OF CONTENTTHAT GENERALIZE ACROSS CONTEXTS.
•RULE #19: USE VERY SPECIFIC FEATURES WHEN YOUCAN.
•RULE #20: COMBINE AND MODIFY EXISTING FEATURESTO CREATE NEW FEATURES IN HUMANUNDERSTANDABLE WAYS.
•RULE #21: THE NUMBER OF FEATURE WEIGHTS YOUCAN LEARN IN A LINEAR MODEL IS ROUGHLY PROPORTIONAL TO THE AMOUNT OF DATA YOUHAVE.
•RULE #22: CLEAN UP FEATURES YOU ARE NO LONGERUSING.
•RULE #23: YOU ARE NOT A TYPICAL END USER.
•RULE #24: MEASURE THE DELTA BETWEEN MODELS.
•RULE #25: WHEN CHOOSING MODELS, UTILITARIANPERFORMANCE TRUMPS PREDICTIVE POWER.
•RULE #26: LOOK FOR PATTERNS IN THE MEASUREDERRORS, AND CREATE NEW
FEATURES.
•RULE #27: TRY TO QUANTIFY OBSERVED UNDESIRABLEBEHAVIOR.
•RULE #28: BE AWARE THAT IDENTICAL SHORT-TERMBEHAVIOR DOES NOT IMPLY IDENTICAL LONG-TERM BEHAVIOR.
•RULE #29: THE BEST WAY TO MAKE SURE THATYOU TRAIN LIKE YOU SERVE IS TO SAVE THE SET OF FEATURES USED AT SERVING TIME,AND THEN PIPE THOSE FEATURES TO A LOG TO USE THEM AT TRAINING TIME.
•RULE #30: IMPORTANCE WEIGHT SAMPLED DATA,DON’T ARBITRARILY DROP IT!
•RULE #31: BEWARE THAT IF YOU JOIN DATA FROM ATABLE AT TRAINING AND SERVING TIME, THE DATA IN THE TABLE MAY CHANGE.
•第27条:尝试量化所观察到的不受欢迎的行为。
•规则# 28:请注意,相同的短期TERMBEHAVIOR并不意味着相同的长项行为。
•第29条:确保你所提供的培训的最佳方式是保存服务时间所使用的功能集合,然后将这些特性连接到日志中,以便在训练时使用它们。
·规则#30:重要的重量采样数据,不要随意丢弃!
•规则#31:要注意,如果你在训练和服务时间中加入了可吃的数据,那么表格中的数据可能会发生变化。
•RULE #32: REUSE CODE BETWEEN YOUR TRAININGPIPELINE AND YOUR SERVING PIPELINE WHENEVER POSSIBLE.
•RULE #33: IF YOU PRODUCE A MODEL BASED ON THEDATA UNTIL JANUARY 5TH, TEST THE MODEL ON THE DATA FROM JANUARY 6TH AND AFTER.
•RULE #34: IN BINARY CLASSIFICATION FORFILTERING (SUCH AS SPAM DETECTION OR DETERMINING INTERESTING EMAILS), MAKESMALL SHORTTERMSACRIFICES IN PERFORMANCE FOR VERY CLEAN DATA.
规则# 32:再保险之间使用代码培训管道和管道尽可能的服务。
规则# 33:如果您在1月5日之前生成一个基于数据的模型,那么在1月6日和之后的数据上测试模型。在二进制分类
规则# 34:过滤(如垃圾邮件检测或确定有趣的E邮件),使小短期牺牲性能非常干净的数据。
•TRAININGSERVINGSKEW
•RULE #35: BEWARE OF THE INHERENT SKEW INRANKING PROBLEMS.
•RULE #36: AVOID FEEDBACK LOOPS WITH POSITIONALFEATURES.
•RULE #37: MEASURE TRAINING/SERVING SKEW.
可视化编辑环境
——JupyterNotebook介绍

集成开发环境
——支持Markdown和作图的PythonIDERodeo
数据预处理和ETL实例

数据探索
- 变量确定
- 单变量分析
- 双变量分析
- 处理缺失值
- 处理离群值
- 变量转换
- 变量创建



基本统计处理实例
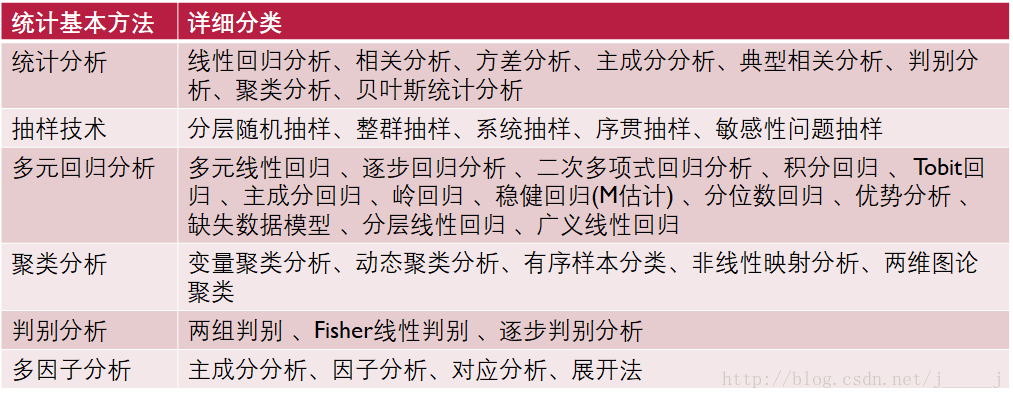


数据可视化实例
可视化
Matpalotlib
Bokeh
Seaborn
特征工程处理实例



特征工程处理实例-线性特征变换
线性特征变换
- 非负矩阵分解 NMF
- 主成份分析 PCA
- 线性判别分析LDA
- 奇异值分解SVD
- 空间填充曲线 SFC
- 小波包分析 WPA
- 因子分析FA
- 多维定标MDS
非线性特征变换
流形学习方法 Manifold Learning机器学习常用算法实例